
 起点课堂会员权益
起点课堂会员权益以图片社区为例,如何利用热度算法做内容质量评估?
以图片社区为例,结合我的实践经验,从待解决问题、输入、计算逻辑、输出四要素,拆解热度算法如何设计。

一、背景
在内容社区中,热度算法是基于实际用户反馈行为,比如内容的点赞、收藏等数据,而实时计算得到的分数。热度算法用于衡量内容的流行度,做对应的质量评估。这里的“质量”,更多代表的是内容受用户欢迎程度。热度高,表示当前内容受更多用户欢迎,十分流行;热度低,表示图片较为冷门。
热度算法为了解决什么问题而存在?
它是为了从庞大的内容库中,简单高效地发现大多数人喜欢的头部内容,推荐给其他用户,从而满足他们的内容需要。《乌合之众》提到,人们在群体生活中,多有从众心理,偏好大多数人的选择。热度算法正是应用了大众心理,热度反映的是社区内部用户大多数的口味偏好。
二、价值
热度算法的价值在哪里?
维持老用户的活跃度。热度算法能够让老用户最高效地获取头部内容,及时感知到当前社区的热点。
以新浪微博为例,热搜榜凭借热度算法,快速挖掘热点新闻,让用户获取实时热点,带动了新浪微博整体的活跃度。吃瓜群众喜欢的娱乐圈八卦,如若干明星出轨事件,在热搜爆出后,让服务器几度宕机。
提高新用户的留存率。热度算法呈现的是社区最流行的内容,这能够让新用户第一时间感知社区作品的优质程度,大概率满足他们的内容需要,增加留下来的可能性。
以摄影社区图虫和视频社区B站为例,热门Tab的优先级很高,把当前最热的内容呈现给新用户,对提升留存是有很大帮助的。
三、算法
以图片社区为例,结合我的实践经验,从待解决问题、输入、计算逻辑、输出四要素,拆解热度算法如何设计。请记住,以下思路是可以复用的,不止是图片,其他形式的内容如文章、视频、音频都适用。需要注意的是,输入及计算逻辑需要结合你的具体产品和业务背景而定。
1. 待解决问题及期望输出
在热度算法中,待解决问题是如何量化图片在社区中的流行度。
期望输出热度排序,用于排行榜或基于一定规则下发至用户端。
2. 输入
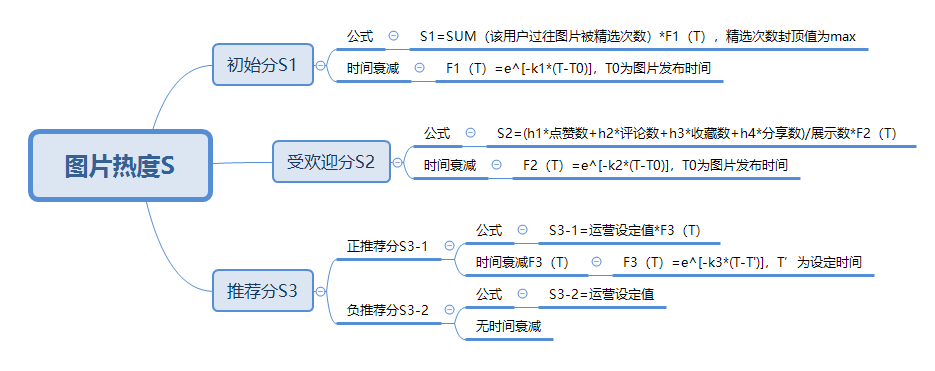
从图片的生命周期来看,一张图片会经过四个阶段:刚发布、被其他用户消费互动、被官方推荐、成为旧图片。依此,我们可以考虑图片热度S拆分为三部分组成:
- S1-初始分,指图片刚发布,没有任何消费互动时,赋予一定的初始分数。
- S2-受欢迎分,指图片发布后,被其他用户消费互动,具备一定的受欢迎分数。
- S3-推荐分,指官方运营可以对图片进行正负推荐,做一定的人工干预。
其中,正推荐可以对分数低但具备潜力的图片给予扶持,负推荐可以对分数高但不符合社区规范的图片进行抑制。
这三个子分数的输入来源,可以结合以下考虑:
- 初始分S1:用过往图片被精选次数或该用户的身份权重。由于我所在的产品,精选是由运营判断的,相对质量较好,而用户的身份如达人等相对缺乏持续运营,所以我选取精选数作为核心指标。
- 受欢迎分S2:在一定展示量下,该图片被点赞、评论、收藏、分享的次数/人数。以上是较为常规的关键指标,如果你的产品有其他更为关键的行为,可以做对应增删。
- 推荐分S3:S1和S2是图片本身自带的数据,而S3则是预留了一个运营干预的口子。这里的分数,可以做对应的运营辅助后台,由运营同事手动设置。正推荐则加分,负推荐则减分。
3. 计算逻辑
3.1 未考虑时效性的热度计算
- 图片热度S=初始分S1+受欢迎S2+正推荐分S3-1+负推荐分S3-2;
- 初始分S1=SUM(该用户过往图片被精选次数),精选次数封顶值为max;
- 受欢迎分S2=(h1*点赞数+h2*评论数+h3*收藏数+h4*分享数)/展示数,h1-h4为该行为的单次得分项,分数越高,表示该行为对内容更重要;
- 正推荐分S3-1=运营设定值,为正数;
- 负推荐分S3-2=运营设定值,为负数。
以上是未考虑时效性的分数计算,当图片成为旧图片时,我们更希望它能够为其他新图片让位。也就是热度降低,热度与时间成负相关关系。这时候我们引入时间衰减函数,对S1、S2和S3分别考虑时间的影响。
3.2 考虑时效性的热度计算
业内通用的时间衰减函数,是牛顿冷却定律。伟大的牛顿发现,物体的温度在冷却到与室温一致时,温度变化并不是线性的,而是指数衰减。这个定律也被互联网的小伙伴跨界应用到热度算法。
公式表示为F(T)=e^[-k*(T-T0)],e是自然常数2.718,k为冷却系数,(T-T0)为时间间隔,T为当前时间,T0为起始时间。k越大,衰减越快;k越小,衰减越慢。
k值如何确定?假设热度从100变成1,用了24小时(全衰期),可以视为基本衰减完毕,即F(T)=0,T-T0=24,依此可以求得k值。计算时需要注意时间单位,统一换算为时间戳。在实际的落地中,难度在于如何确定全衰期。这个应该根据实际的业务需要去判定,比如新闻的全衰期一般为24小时,比较注重实效性;而其他业务,对于时效性要求不高,可以将全衰期适当延长。
加上时间衰减后,我们可以更新S1-S3的公式如下:
- 初始分S1=SUM(该用户过往图片被精选次数)*F1(T),精选次数封顶值为max
- 受欢迎分S2=(h1*点赞数+h2*评论数+h3*收藏数+h4*分享数)/展示数*F2(T)
- 正推荐分S3-1=运营设定值*F3(T),为正数
- 负推荐分S3-2=运营设定值,为负数
其中,F1(T)、F2(T)、F3(T)均为对应的衰减函数:
- F1(T)=e^[-k1*(T-T0)],T0为图片发布时间
- F2(T)=e^[-k2*(T-T0)],T0为图片发布时间
- F3(T)=e^[-k3*(T-T’)],T’为设定时间
3.3 归一化处理
经过以上2个步骤的处理,我们得到的是:图片热度S=初始分S1+受欢迎S2+正推荐分S3-1+负推荐分S3-2。
如果你实际落地中会发现,受欢迎分S2往往很大,无论如何调节S1和S3,对分数影响都很小。这个时候,你会幡然醒悟,缺少了最重要的一步——归一化。
因为我们得到的S1、S2和S3,大小不在同一量级上,如果直接简单相加,S约等于可能约等于某个子分数。
引入归一化系数a,将各部分分数进行适当的放大或缩小。最终得到:图片热度S=a1*初始分S1+a2*受欢迎S2+a3*正推荐分S3-1+a4*负推荐分S3-2。
4.实例
用户小白在2020年3月1日0:00发布一张图片,小白过往图片被精选次数为20次;24小时后,该图片累计展示1000次,获赞数400,评论数100,收藏数50,分享数10。求此时的热度分数。暂无运营推荐操作。
在热度算法中:
- 初始分S1=SUM(该用户过往图片被精选次数)*F1(T),精选次数封顶值为max
- 受欢迎分S2=(h1*点赞数+h2*评论数+h3*收藏数+h4*分享数)/展示数*F2(T)
- 正推荐分S3-1=运营设定值*F3(T),为正数
- 负推荐分S3-2=运营设定值,为负数
若结合业务讨论得到:
- 初始分S1,精选最多按10次计算,时效性3天;T-T0=24小时=1天,对应F1(T)=0.215;
- 受欢迎分S2,点赞一次计1分,评论一次计2分,收藏一次计3分,分享一次计4分,时效性30天;T-T0=1天,对应F2(T)=0.858
- 正推荐S3-1,推荐时效性7天
那么此时可以计算如下:
- S1=10*F1(T)=2.15
- S2=(1*400+2*100+3*50+4*10)/1000*F2(T)=0.68
- S3-1=S3-2=0
- 而热度分S=a1*S1+a2*S2+a3*S3-1+a4*S3-2,其中归一化系数a1=1,a2=10,a3=5,a4=5,则计算出最终S=8.95
四、总结
热度算法实际很难,难就难在如何根据实际业务调参调优,以下我分享几点心得:
(1)第一版本不在乎精度,重点在于跑通流程,确定好整个热度算法的框架
框架必须正确,并且支持后续拓展。第二版本起,才开始调参调优。这是是一个技术活,一定要体现在分数的改变效果上,根据效果来反推调优方向,否则只是无意义的劳动。
(2)无数据不算法,巧妇难为无米之炊
输入涉及的数据指标,都是需要正确埋点的。如果数据不可用,应该优先做数据基建。
小数据+复杂模型=一般效果
大量数据+简单模型=很好效果
大量数据+复杂模型=更好效果
(3)热度S能够让运营或用户简单理解的前提,是需要做对应的可视化
因为直接计算出热度分数只是个绝对数,而相对数才是对业务有参考意义的。比如你可以将热度S做成区间0-10,10分表示满分。要学会将技术语言转化为业务语言。
如果你看完以上内容,觉得热度算法很简单。那么恭喜你,你已经成功入坑,可以去实践了。
如果没看懂,你可以勇敢提出你的疑问。我们一起交流学习,共同进步。
作者:Ln,微信号:scnulhy
本文由 @Ln 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









请问关于受欢迎分的计算
1、如果一个内容已发布60天,之前实例设定有效期30天,前30天的数据是否计入?
2、假设最近30天总共1000赞,情况a:前10天100赞,后20天900赞;情况b前10天900赞,后10天100赞。这2种情况下,在现时计算,按现在公司计算受欢迎分是否相同?情况a热度越来越高,情况b热度越来越低,理论上应该要有区别才对,应如何体现呢?
老师分享的很好,受教了,非常感谢,假如有机会认识您那就更好了,谢谢!
求解,归一化系数是怎么算出来的
感谢作者的详细分享,有一点不是很明白,正向推荐为什么是-1,负向推荐-2? 如果我正向推荐填0-1不就是负数了吗? 负向推荐只是-2那还是朝着正向的方向计算了呀? 求解
你理解错了,这是名字 。推荐分为S3, 其中正推荐叫S3-1 (S3杠1) ,负推荐分叫S3-2 。
F(T)=e^[-k1*(T-T0)],则-k1*(T-T0)=lnF(T),那么F(T)就不可能等于0,文章中是否写错了
感谢指正,F(T)应为0.01
另外两个问题:
1.衰减系数中的时效k值,如何确定?经验估计假设?
2.归一化系数这个数据如何确定?有哪些考虑因素以及其他?楼主可好做个进一步的分享?
1.k值应结合业务,建议同运营同学讨论好内容时效性对用户消费兴趣的影响,也算是经验主义了
2.归一化有挺多方法的。我理解是黑盒子调参,重点关注影响结果即可
对于数学是渣,百度归一化都懵逼了,作者可以分享下吗?
很好的文章,谢谢作者,但有个疑问:
“如果你实际落地中会发现,受欢迎分S2往往很大,无论如何调节S1和S3,对分数影响都很小。这个时候,你会幡然醒悟,缺少了最重要的一步——归一化。”
“其中归一化系数a1=1,a2=10,a3=5,a4=5”
下面这个归一化系数的操作与上面的描述逻辑相悖,写错了还是另有原因?
感谢指正,是写错
“k值如何确定?假设热度从100变成1,用了24小时(全衰期),可以视为基本衰减完毕,即F(T)=0,T-T0=24,依此可以求得k值。”
这里有点没看懂,辛苦楼主解答一下:F(T)是个指数函数,好像不能等于0,这里的k是如何计算的
感谢指正,F(T)应为0.01
有没有文字版
具体是?
不错 期待人人都是产品经理能增加公式编辑器功能
😉
请教作者:现在负责直播/短视频这块的推荐算法产品经理,但是之前没有过这块的经验,请问有哪些书籍或论坛推荐给我,可以让我学习这相关的一些算法的。谢谢了!
你好,书籍的话推荐《推荐算法实践》,算是国内第一本工程实践的书了。
因为推荐算法基本是算法工程师设计的,如果你所在的团队已经有算法工程师,那么你可以更加关注在目标和算法效果评估上哈
你好,我想咨询一下这种效果的评估如何进行评估
您好啊,这边也在参与短视频社交这块的内容,不嫌弃的话,能互相认识一下吗?谢谢了!