
 起点课堂会员权益
起点课堂会员权益如何让对话机器人更优秀?
除却自然语言理解,对话机器人应该如何通过产品设计来变得更加优秀?本文将通过几个核心的产品设计技巧为您介绍如何让对话机器人更加优秀。

话接前文《 机器人是如何实现对话的?》,在上一篇文章中,梳理总结了如何打造一个对话机器人的完整流程,以及给大家介绍了整一个对话机器人设计所涉及的核心功能。
而本文,则将在上文的基础上(如何打造一个对话机器人),与大家分享另一个话题:如何让一个对话机器人设计的更优秀?
一、知识挖掘:解决一个企业没有成体系知识库的难题
对话机器人,有一个很重要的任务就是为各类用户排忧解惑;而要做到排忧解惑,机器人就必须事先掌握相关的知识,即用户可能会问的问题以及这些问题的答案。
对于一些大企业来说,由于多年的规范管理与积累,一般都会有一个成体系的知识库:总结了在服务客户的过程中,客户常问的问题,以及这些问题的答案。
但是,对于一些中小企业,或者管理不规范的大企业(还真别笑,市值千亿的大企业,客服部门都没有成体系的知识库这类事情我碰到了好几回),服务客户的过程是没有成体系的知识库的,都是靠大家口口相传,自我学习。
所以针对这部分企业来说,想要解放人力,引入对话机器人,第一步需要解决的问题就是知识库的问题。
而这个问题又可以分为两类:
- 第一类是有着丰富的人工服务经验,只是一直未把这些经验总结梳理;
- 第二类是从未有过任何的服务经验,一切从零开始。
对于后者,系统无法很好的辅助知识总结;但对于前者,只有客户的服务记录还在,就可以通过系统辅助人工做知识的总结和梳理。
下面将通过一个具体来说明系统是如何帮助企业梳理过往服务记录,并整理成知识库的。
- A企业常年通过企业QQ连接客户和客服人员,多年来的对话记录全部存在QQ后台,可通过后台系统直接导出所有的客户对话记录。
- 有了对话记录后,可通过系统,把所有相似的问题进行分组与整合,并给出这些问题(或者叫问法)分组的关键词——知识挖掘
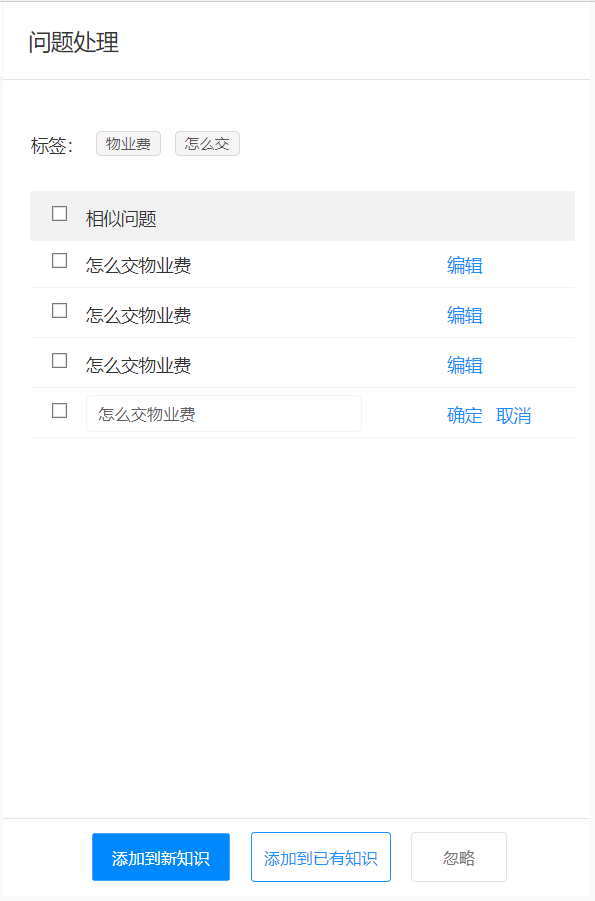
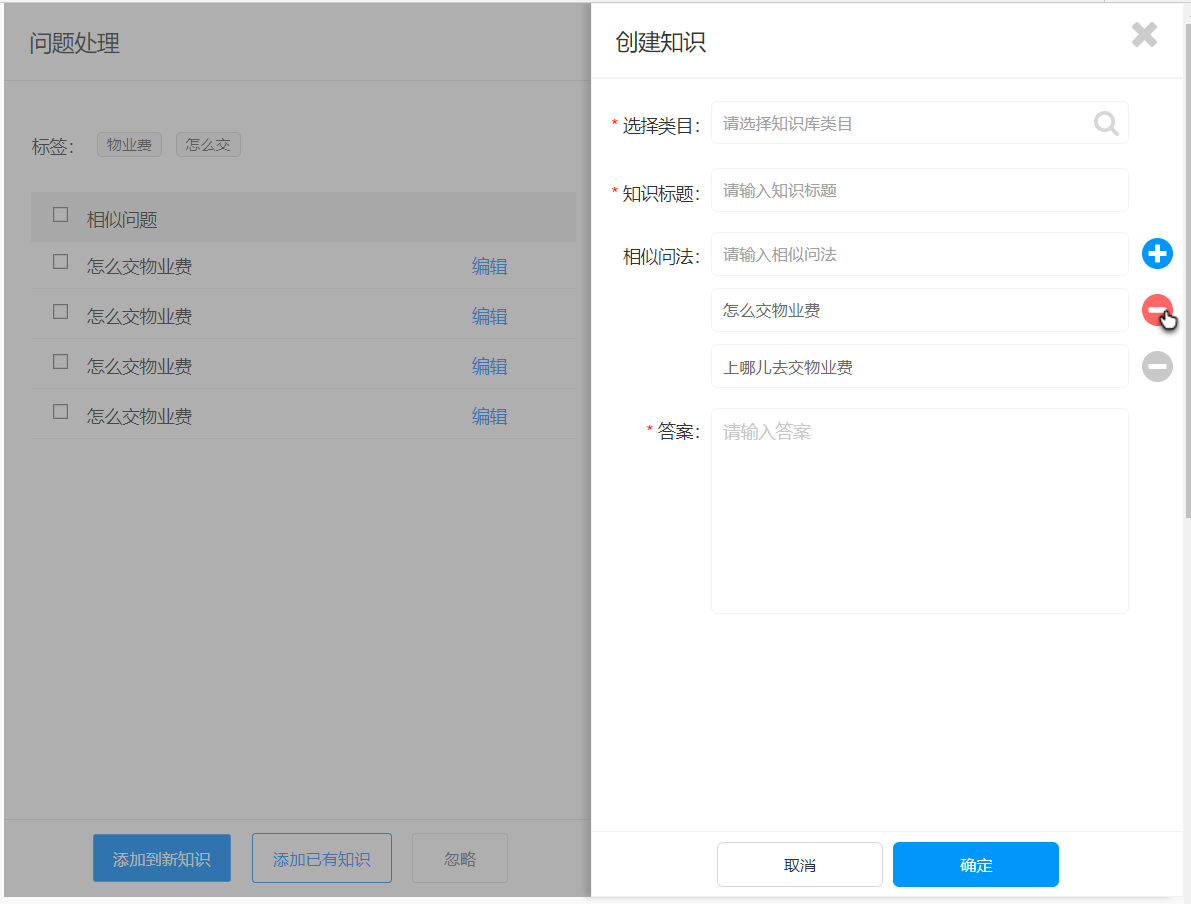
- 通过标注师对这些问题分组进行校验,校验这些分组是否正确,是否需要调整,并在此基础上生成一条条知识——对问题分组建立一条标准问题,并给出该问题的答案。
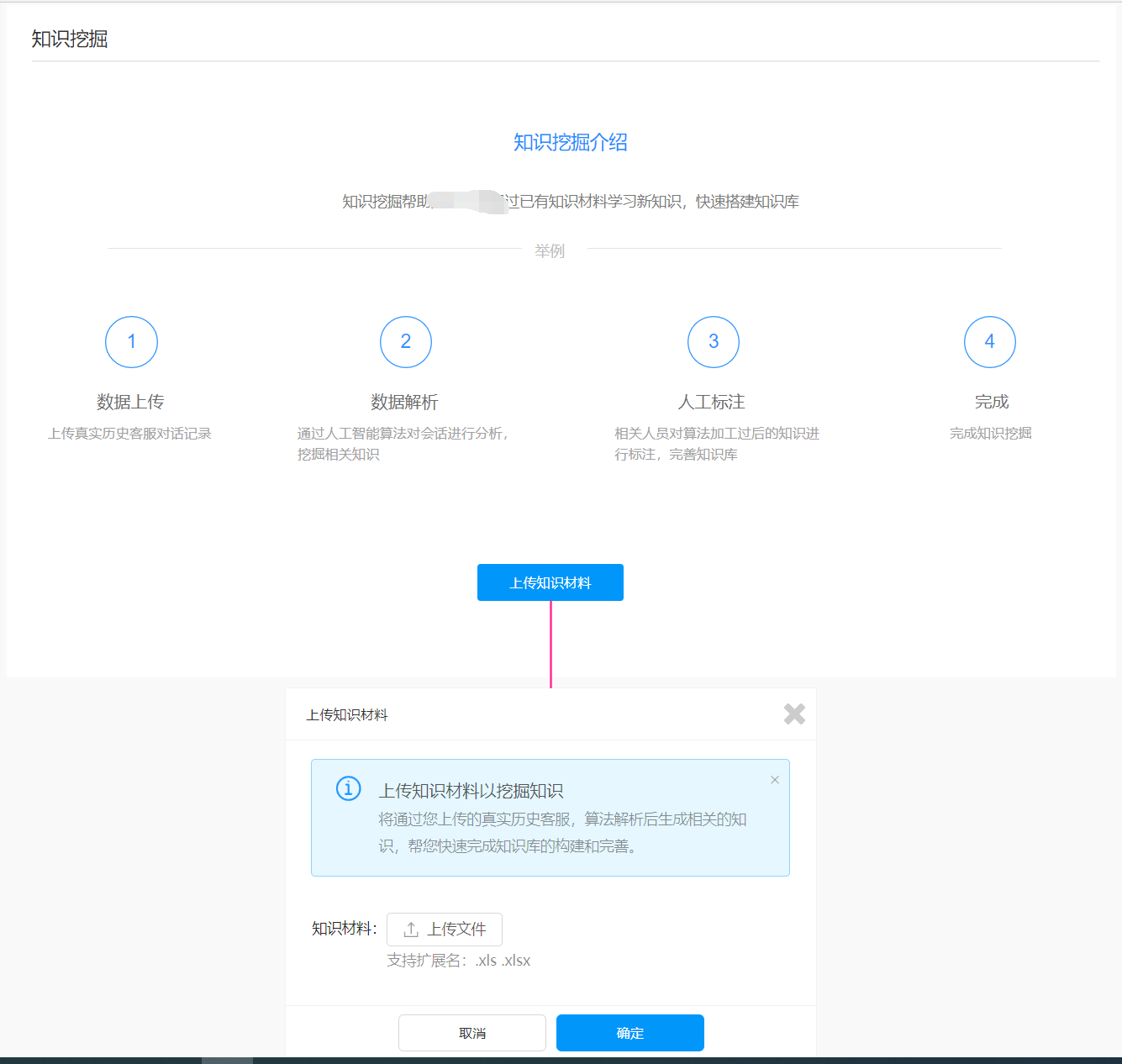
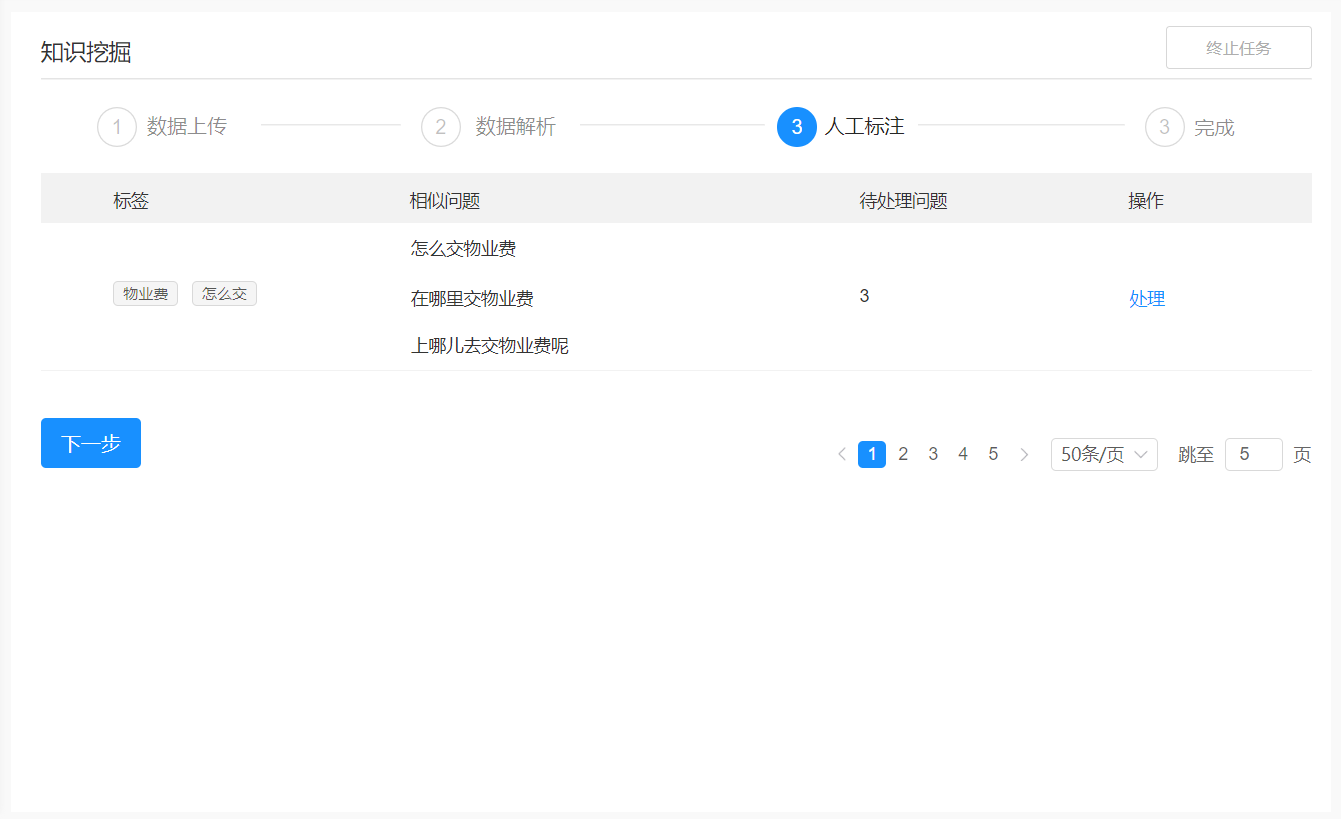
如图,这个是我之前的产品原型,涵盖了从知识材料的上传到算法的解析(相似问题分组),再到人工标注的过程。
整个功能的设计核心思路在于:利用分类算法,把相似的问题进行分组,并提取问题分组的关键词,最后交给标注师做问题的创建与检验。
整个过程对企业来说最大的价值在于系统通过历史数据帮助企业完成过往经验的总结。因此,最核心的部分也正是算法解析的部分,这部分一般使用文本聚类的方法,由于术业有专攻,笔者在此不展开描述。
二、知识发现:解决机器人知识库更新的难题
就像一个孩子去上小学,他所懂得的知识一定是一个逐渐增长的过程,而对话机器人的知识库也是一样的。
我们一开始虽然设置了一版的知识库,但是在服务客户的过程中,他必定会遇到一些无法解答的问题。而承认自己的无知只是求知的第一步,第二步,我们需要对我们的无知进行填充,填补这块知识的空白。这样,在以后遇到相同的问题的时候,我们的机器人就不再哑口无言了。
顺着上面这个思路,我们系统需要补充的一个功能就是知识发现:
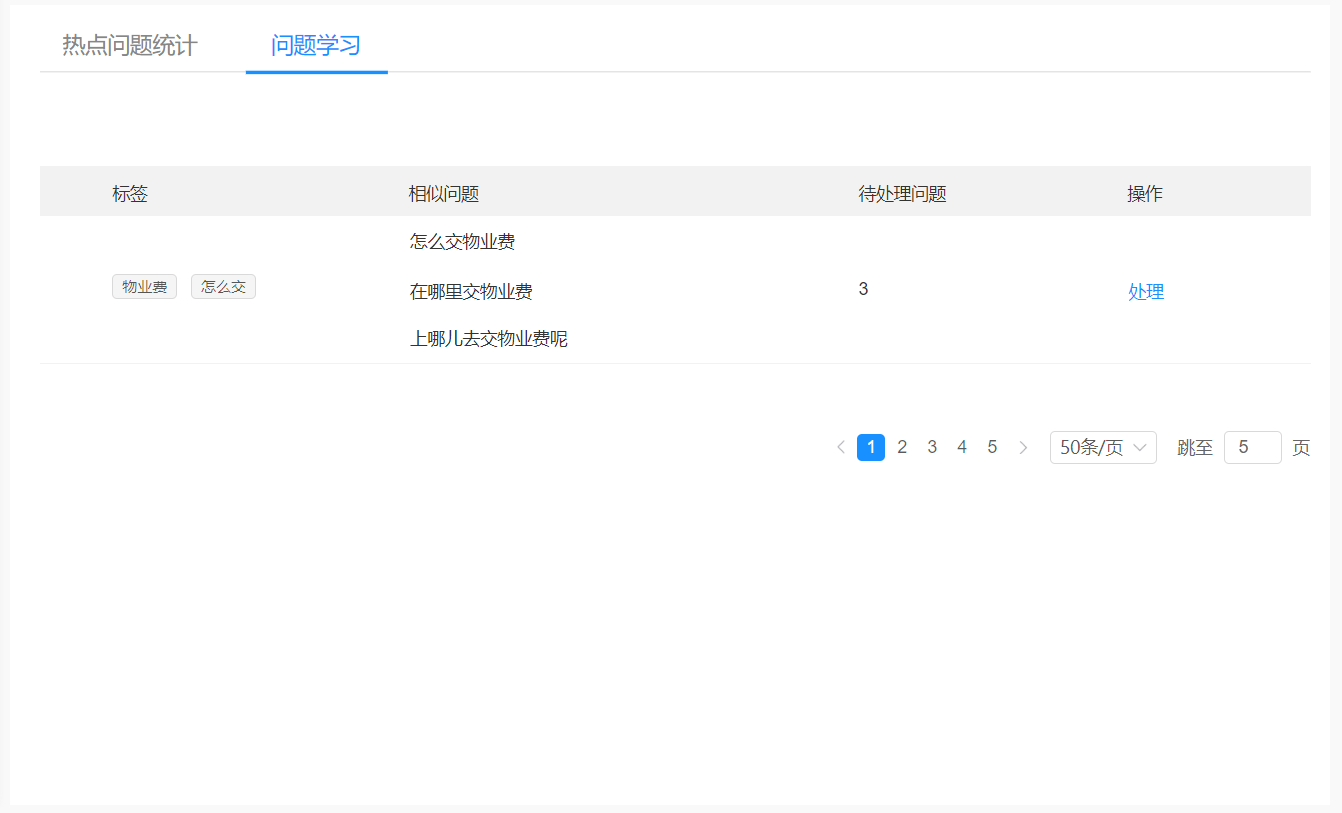
- 系统对所有无法回答的问题进行梳理与整合,而在这里,所谓的系统无法回答的问题,即针对这个问题,系统给出的答案最高的准确率低于某个水平的,我们则视为系统无法回答的问题。
- 系统对这些问题按照相似程度进行分组,然后提取出对应问题分组的关键词。
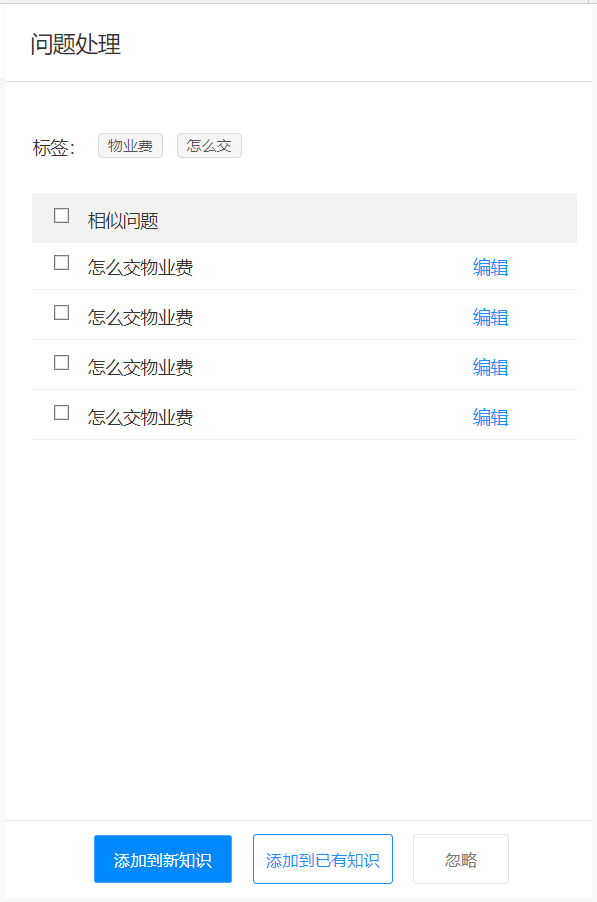
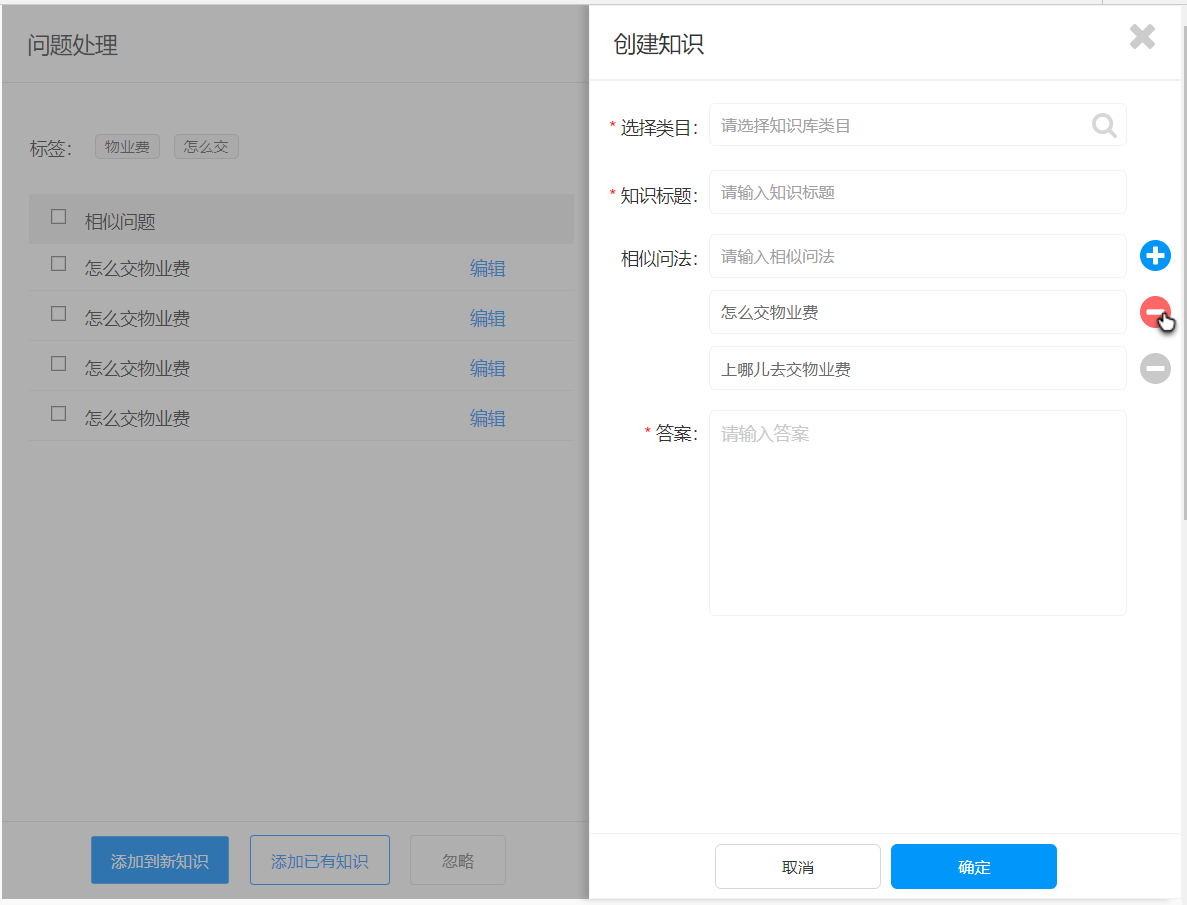
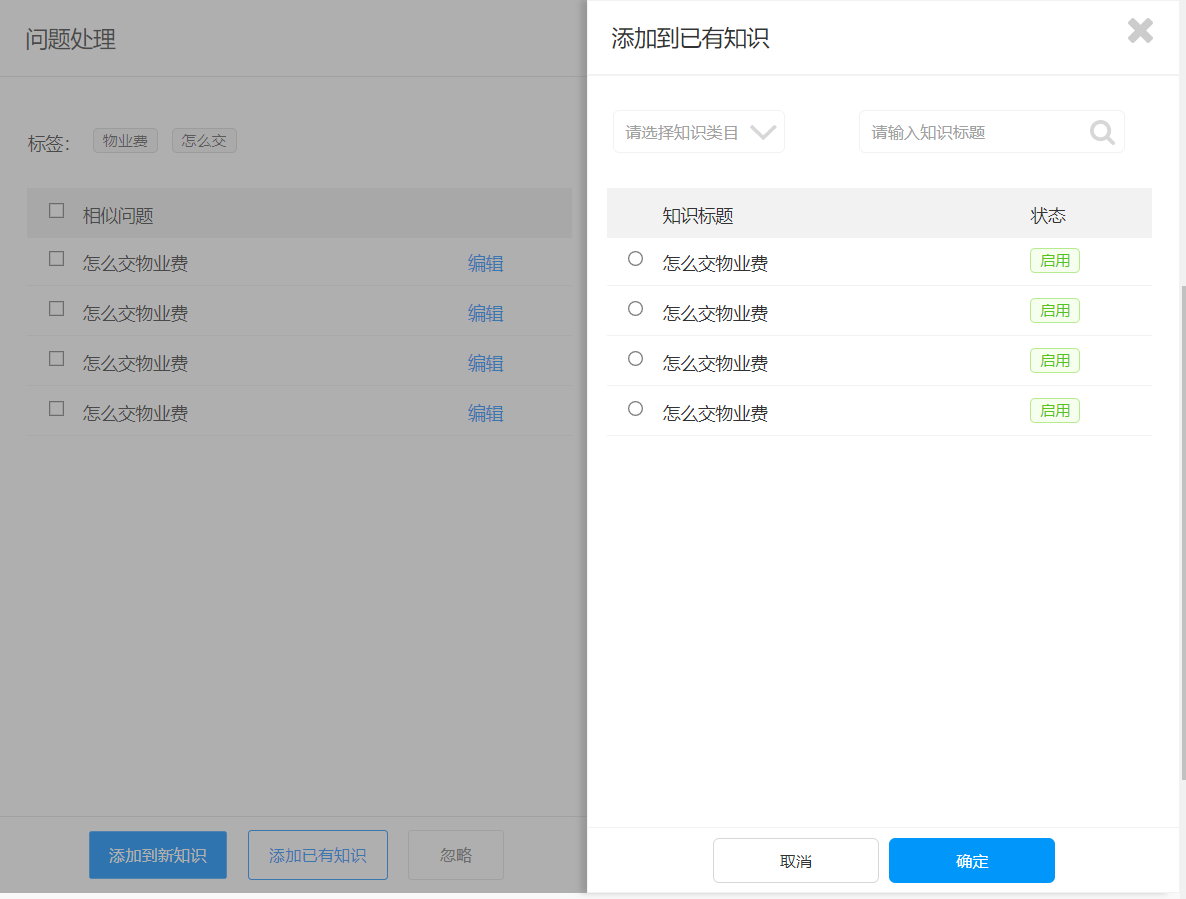
- 标注师对这些系统已经完成了初步整理的“未知问题”进行标注:如果这个问题在知识库中已经存在,只是系统无法识别而已,那我们就把这个问题放到已有的知识中就好;如果这个问题是原来的知识库没有的,那我们就需要新建一条知识来完成这部分空白的填充。
长此以往这样不断的迭代下去,我们的机器人几乎就可以做到在当前领域无所不知,知无不言的地步了(当时是夸张的说法啦>.<)。
但从这样一个解决问题的思路来看,我们也不难发现:利用这种原理的知识库和机器人,无法回答超出自身认知意外的问题,以及无法从自身已有的知识上进行推理,得到新的知识(回答新的问题)——而这个推理与认知能力,也正是我们生而为人所最宝贵的能力。
所以那些担心机器人超越人类智商的小伙伴们,只要现在的人工智能还是在走现有路径,即从历史数据中学习以往的经验(机器学习流派),那它将永远无法达到超越人类的境界。
而当前业内公认的,也许能够让机器实现知识的推理与认知的,被讨论的最多的就是知识图谱了;但是,也只是也许而已。
因为当前知识图谱所谓的知识推理,更多的也只是遵从人的所设定的规则来进行推理罢了,这个以后我们在讲到知识图谱这个领域的时候再讲。
三、对话端的优化:让客户用的更加省心
以上的技巧都属于系统后台端的设计技巧,那接下来我们来讲讲真正和客户进行对话交互的对话端又有哪些设计技巧能够让机器人更加优秀的。
1. 常见问题推荐
对于常见问题推荐这点我们废话不多说,直接上图:
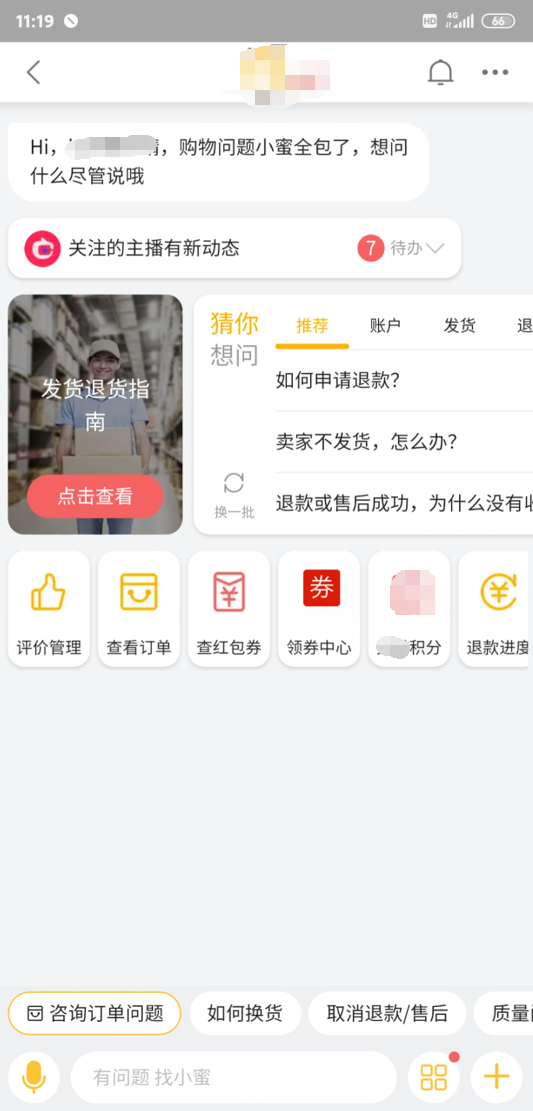
顾名思义,就是在客户打开对话界面的时候,把全网内,用户最常问到的问题摆出来,让用户自己去选择,去点击,省却了输入的繁琐,多给用户节省精力和时间啊~
而这中做法的好处可不止上面这点:
- 一方面更高效帮用户解决问题:能让用户点的就不要让用户输,这点我们不再多说。
- 另一方面减少用户输入导致的识别错误:这点其实也是很重要的一条收益,只要用户输入,天知道用户会输入什么内容?再加上打错字呢?这时候机器人就很容易出错了;而点选这个操作,则大大的降低了这样一个风险。
2. 输入提示
输入提示指的是,在用户输入文字的过程中,提示一些常见的问题。就有点类似用户边输入,系统同时在帮忙搜索对应问题一样,用户只要输入几个关键词,就能找到自己想要询问的问题了。然后直接点击问题就可以看到答案。
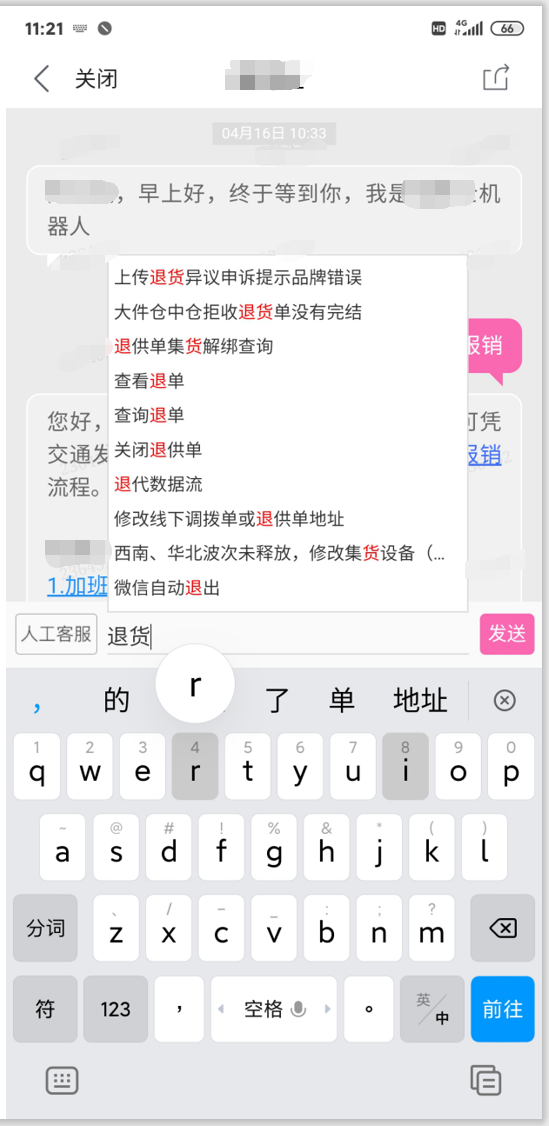
这种做法的好处也是显而易见的:
- 提高用户提问效率:用户不需要输入完整的问题,只需要输入部分关键词,即可找到想要询问的问题
- 减少错误识别率:用户通过这种方法,系统推荐相关问题给用户点选,就大大的减少了用户输入文本时的内容不确定性,以及说错误拼写等文本问题,自然就大大降低了系统的识别错误问题。
3. 低阈值问题推荐
低阈值,指的是系统对于用户的提问,给出答案时的准率较低情况(通俗点说就是对于用户提出的这个问题,系统所给出的答案,正确的把握不高)。
此时,对话机器人不会直接给出答案,而是给出一系列用户可能想要询问的问题供用户选择;而系统给出这些问题也是有讲究的:这些问题可能就是用户想要问的问题,只是系统判断后,用户问这些问题的可能性介于一定的范围之间,而这个准确率的范围刚好不高不低,如40-60%。
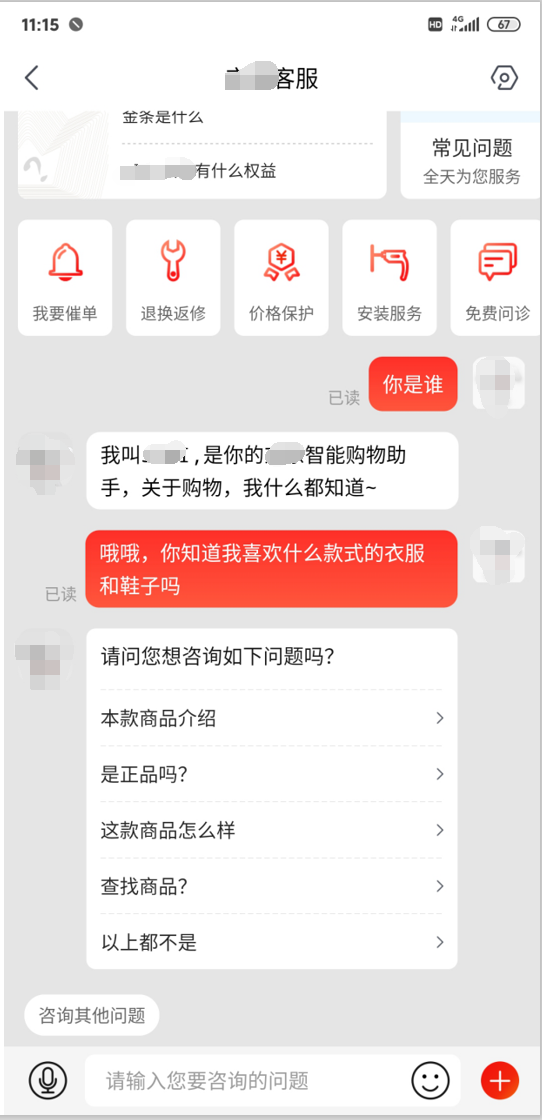
而这里就有一个问题:遇到这种情况为什么系统不能直接就回答了呢?
还需要用户点选,这不是很麻烦吗?非也非也,如果在这种情况下,系统没有很高的正确回答用户问题的把握就冲动的把答案呈现在用户面前,很容易就造成了答非所问的尴尬——通俗点说就是不懂装懂。
但如果是换做上面这种做法,对于没有太大把握的问题,系统承认自己不会,且给用户提供了选择——这就大不一样了,承认自己不会,并尽自己能力给出建议,这样,用户的感受会好很多。
4. 转人工兜底
转人工,顾名思义,就是服务客户的角色从机器人转换成了我们的人工客服:
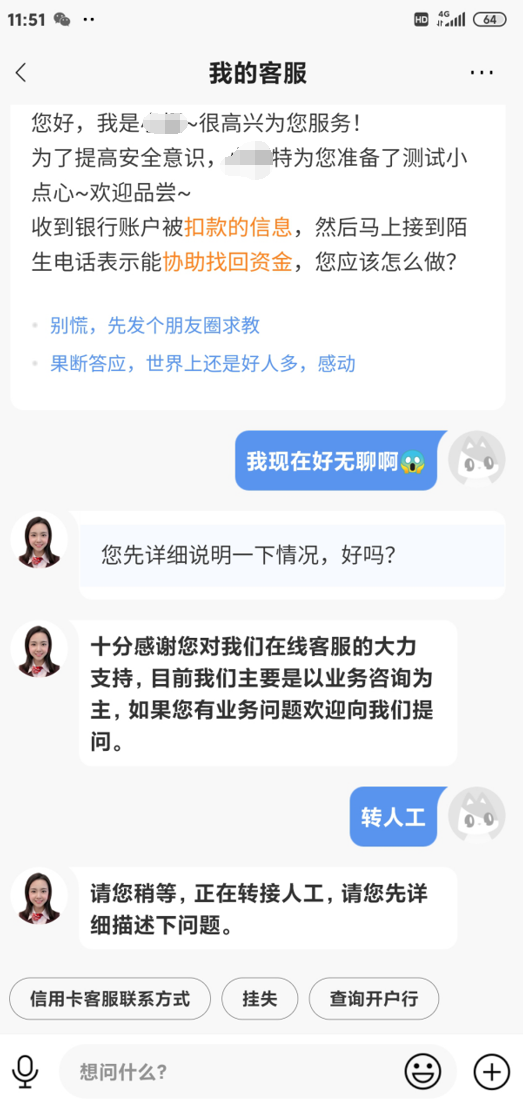
而说到转人工,其实本质上分为了两种不同转接方式的:
- 主动转人工:即客户主动点击转人工按钮,请求真人服务。
- 静默转人工:即机器人识连续多次无法解决用户问题或者检测到用户的愤怒情绪时静默自动转人工
至于说一些大老板们有时会问的一些问题:既然我都用了智能客服,我们能够把这个主动转人工或者这个静默转人工的功能去掉吗?
老实说——不能。
对于一些复杂场景,例如我的信用卡突然间刷不动了。我自己都不知道原因,交给机器人的话,大概率是没法回答的。
此外,对于机器人来说,永远都会有无法回答的问题,而客户也知道他是机器人,问一两次也就不和机器人计较了,心情也还是平静的。
但是,如果现在我手上信用卡莫名其妙被刷了一万块,你一个机器人问啥也不懂,还不退下给我来个人解决下这事情,那真是恨不得那把四十米长刀赶过去银行当面质问——对于无法回答的问题机器人静默转人工,避免了客户的愤怒;或者说机器人识别出来客户的愤怒,静默转人工。
四、小结
好了,对话机器人的设计技巧到这里就先告一段落了,若需更多的小技巧,各位小伙伴可以上网去找更多的资料,这里只是给大家阐明这样一个思路。
以上讲了那么多,我们不难看出:很多都是产品设计上的一些技巧,和我们一听到这个话题(对话机器人)时的第一感觉(大家一听到这个话题必定先想到的时背后的NLP)有点不一样。
是的,这就是我想要在最后讲的内容。
全球范围内,在自然语言理解领域的成就都是有限的,要知道语言就是知识的传递以及认知的外在表现,是我们人类之于全球生物最大的不同点所在,也是我们人类文明的基石。
所以当前的人工智能离真正的语言理解还是很遥远的;但我们也不用过度的沮丧。
算法层面,万里长征我们也已经开始了第一步;而产品设计层面,我们通过一些产品设计的小技巧,让我们当前的技术为人类提供一些基础的服务,享受科技的成果——在智能对话领域,产品人能做的,还有很多。
本文由 @王掌柜 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









能有空跟您聊聊吗
可以呀,firecheney
微信