
 起点课堂会员权益
起点课堂会员权益小白学搜索(上):搜索引擎如何排列搜索结果?
搜索引擎,可以通过关键词使得人们在使用时更加的便利。但关键词是怎确定的呢?不同的用户是怎么在页面中找到他们需要的信息的?本文作者从一个实例出发,对搜索背后的故事进行了梳理阐述,与大家分享。
柳絮纷飞的四组团,一个金色的下午,小白打开电脑,鬼使神差地在百度搜索框里输入“杭亦白的公众号”这几个字。大约30毫秒以后,672个搜索结果展示在眼前。逐个往下翻看这些结果,三个疑惑逐渐涌上大脑:
- 我要找哪些网页,百度怎么知道的?
- 网页这么多,百度是根据什么规则排列它们的?
- 它返回的和我想要的,相关性如何?
搜索的数学本质——搜索词对应索引表的布尔运算
刚刚经受毕业论文洗礼的我们,可能对摘要最后附带的几个“关键词“还留有深刻的印象。不止是毕业论文,几乎所有的学术杂志都要求作者提供3~5个关键词。
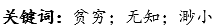
关键词的历史背景是什么?原来,在半个多世纪以前,搜索引擎已经广泛运用于文献检索了。为了方便期刊的编辑、读者查找文献,搜索引擎开发者们巧妙地为文献围绕的核心词建立了索引,也就是传承至今的关键词。如果你搜的词出现在某篇文章的“关键词“坑里,搜索引擎就会迅速把这篇文章返回给你。
比如你搜“显微镜“,多半会看到光学领域里显微镜相关的文献,因为这些文献往往附带着“显微镜”这个关键词;同理,搜”浙江村“和”社区“这两个词,项飙的《跨越边界的社区》很可能会出现在在显著的位置。
“索引”这个概念的引入,使得搜索引擎真正具有了实时反馈结果的可能。
一开始,由于计算机速度和容量都十分有限,只能对最重要的3到5个主题词建立索引。现在好了,计算机的性能已经不再是制约因素,还有了成熟的分布式处理手段,对互联网上所有网页的所有词建立索引理论上存在可能。
如果真的这么搞,互联网上就存在一张巨大的索引表,所有词都能找到对应的网页。当你搜索一个词组,搜索引擎把这个词组当作键(key)放到表里,取出对应的网页作为值(value)返回,理论上就初步完成了一次搜索行为。
逻辑看起来非常简单,数学上又是怎么实现的呢?
原来,最简单的索引结构就是一长串二进制数,来表示关键词是否存在在每篇文献中。有多少篇文献,二进制数就有多少位,位上取0代表对应文献里不包含关键词,取1则相反。
比方说,假设互联网上只有16个网页,搜索引擎首先对这16个网页做一个排序(如有新增网页,堆在队尾,保证前方网页序号固定),然后对网页内的所有词,分别建16位的二进制数,这些词与对应的二进制数就构成了一张索引表。
对于我要搜索的“杭亦白的公众号”,搜索引擎首先把这句话根据语意做分词处理,分出“杭亦白”、“的”、“公众号”这三个词。
关键词“杭亦白”对应的二进制数是0001 0000 0010 0011,表示第四、第十一、第十五、第十六个网页上包含“杭亦白”这个词。对“的”和“公众号”做同样处理,就得了三个二进制数。
对以上3个二进制数做布尔AND运算,结果是0001 0000 0010 0010,表示第四、第十一、第十五个网页满足搜索要求,搜索引擎向搜索者展示的就是这3个网页。
原来,搜索的数学本质,就是搜索词对应索引表的布尔运算,搜索引擎返回布尔“与”运算结果为1的网页。
这里可以多提一句,布尔运算的元素只有1(TRUE,真)和0(FALSE,假);基本运算只有“与”(AND)、或(OR)、非(NOT),十分简单,却为数字电路奠定了理论(布尔元素真假对应着电路通断),也对数学产生深远影响:
“布尔代数对于数学的意义等同于量子力学对于物理学的意义,它们将我们对世界的认识从连续状态扩展为离散状态。在布尔代数的世界里,万物都是可以量子化的,从连续的变成一个个分离的,它们的运算“与、或、非”也就和传统的代数运算完全不同了“
——《数学之美》
在实际情况中,网页的数量不可能像上面假设的只有16个那么少,很可能是上百亿的量级,产生的词组索引表更是爆炸,需要将索引通过分布式的方式存储在不同的服务器上,接受查询时,查询分发到各个服务器上并行处理,结果送到主服务器上合并处理,向用户返回最后结果。
搜索返回网页如何排序——PageRank投票表决
通过上面的布尔运算,搜索引擎向我们返回了三个网页。那么问题来了,该按什么顺序排列这三个网页呢?
Google在1998年给出了答案:表决式PageRank。核心思路只有一句话:网页之间会以互相之间链接锚文本(Anchor Text)的形式投票,获得的票越多的网页,排名越靠前。
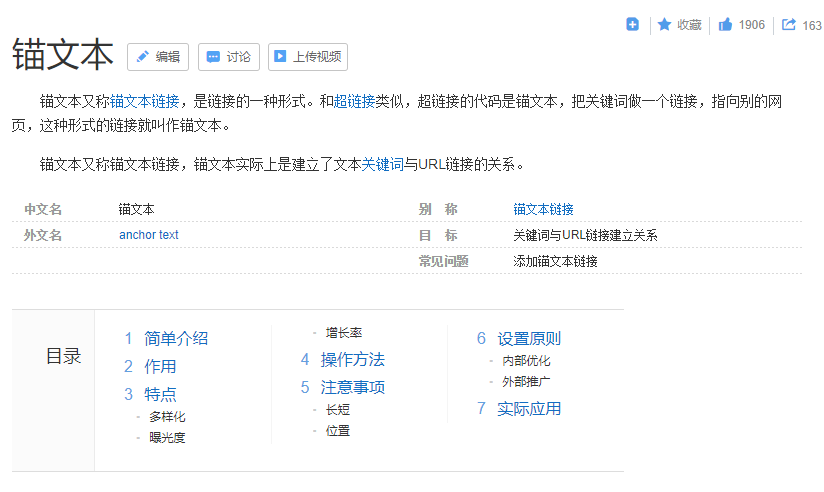
比方说我们百度”锚文本“,搜索结果里有一些蓝色部分的可跳转超链接,比如图上的“超链接”、“关键词”、“Anchor text”,这些部分就是指向其他网页的锚文本。
如果某个网页被其他网页指向地越多,可以认定这个网页人缘好,比较靠谱,可以放在前列。
当然,这么说也并不十分严谨。因为现实中,网页质量本身存在差异,它们的票对排序结果的影响并不是等效的:被越有权威的网站链接到,越有可能获得靠前的排名。
在这么一个逻辑下,PageRank具体是怎么运作的呢?不妨用一个简单的3层链接模型来模拟一下。
搜索引擎返回的3个网页(序号为第四、第十一、第十五),分别定义为X1、X2、X3,它们分别被Y系列网页链接,而Y系列网页又被Z系列网页链接。考虑到网页质量良莠差异,排名越高的网站贡献的链接权越大,网页X的最终排名,取决于所有指向这个网页的其他网页的权重之和。
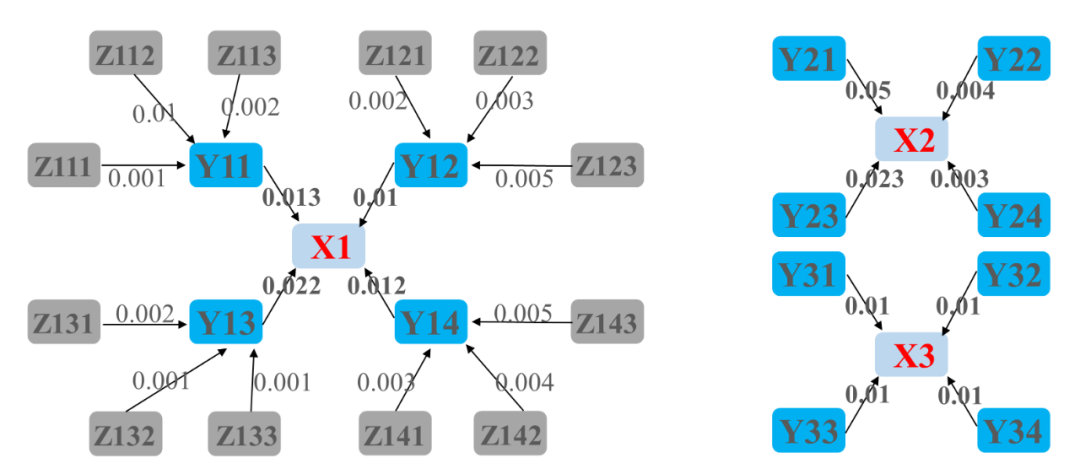
相加得到,
PR(X1) = 0.013+0.01+0.022+0.012=0.057,
同理,
PR(X2)=0.005+0.004+0.023+0.003=0.035,
PR(X3)=0.04。
根据结果,返回的搜索结果中,X1网页放在搜索引擎最前列,接着是X3,最后是X2。
细心的朋友可能会问了,不对啊,这里明显预设了Z的权重,实际上X的权重由Y求和,Y的权重由Z求和,Z权重还得从外一层网页计算…“计算搜索结果的网页排名过程中,需要用到网页本身的排名“,这不成了”先有鸡还是先有蛋“的问题了吗?
Google创始人之一布林解决了这个问题。先假设所有网页的排名是相同的,根据初始值算出各网页第一次迭代排名,在这基础上迭代出第二次排名,一般经过10次迭代,结果就会收敛到网页的真实排名上。
判别返回结果与用户搜索的相关性
其实,搜索结果的最终排名,除了得看搜索结果中网页质量高低(用PageRank链接权表征),还取决于结果与用户搜索的相关性。
你想想啊,我搜“杭亦白的公众号”,如果搜索引擎给我返回“仙林野猪”或者“大衣哥和他的邻居”这些莫名其妙的东西,我肯定不开心啊。哪怕是feed一些“公众号写作运营”弱相关的网页,我也好受一些;如果能呈现在杭一白里写过的文章,那就圆满了。心情一好,甚至要把百度设置成默认搜索引擎。
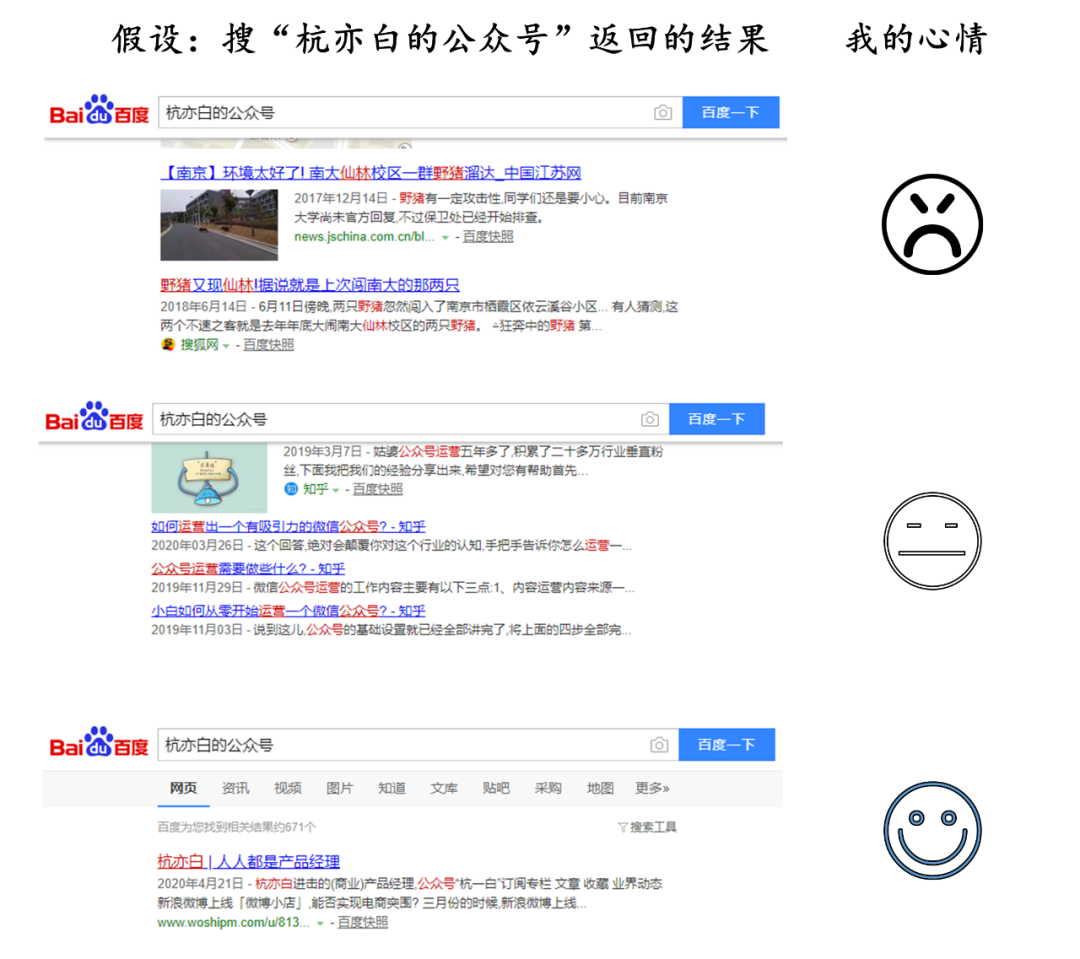
那么,搜索引擎是怎么保证返回结果与我搜索的相关性的呢?
经过十多年的搜索生涯,我把相关性泛化为 “检索准确性”,并且有以下两个感性结论:
- 搜索结果中,搜索词出现的频次越高,这个结果可能越准确;
- 如果搜索结果包含专业词汇,而不只有通用词汇,这个结果可能越准确。
即“如果一个关键词只在很少的网页中出现,通过它就很容易锁定目标,它的权重就应该大。反之,如果一个词在大量的网页中出现,看到它仍然不清楚要找什么内容,它的权重就应该小。”
这两个感性结论分别对应两个量化指标:TF(Term Frequency,单文本词频)和IDF(Inversed Document Frequency,逆文本频率指数)。
首先讲TF,还是拿“杭亦白的公众号”为例子。
搜索返回的X1网页里,共有1000个词,其中“杭亦白”出现了1次,“的”出现了30次,“公众号”出现了5次。那么这三个词的词频TF1、TF2、TF3分别是0.001、0.03、0.005,三数相加,其和0.036就是网页X1和搜索“杭亦白的公众号”的单文本词频TF(X1)。
同理,计算出TF(X2)和TF(X3),根据计算值大小,对应感性结论1,就可以知道哪个网页和搜索是最相关的。
就这?当然不是。如果只按照这个逻辑,“杭亦白”这个词可能要有意见了。
首先是对“公众号”不满:我一个信息量这么高的词,权重居然比不上你一个烂大街的词。差不多每10个网页里就有一次你的身影,说到对预测小白要搜索的主题的贡献,你拿什么和我比?引擎大哥,我认为有失偏颇!
其次是对“的”这个虚词:哪哪都有你,难怪数据这么好看,但是对相关性判别没有半毛钱贡献啊。
搜索引擎听了“杭亦白”的抱怨,默默引入IDF并更新了规则:
- “的”等虚词列为停止词(Stop Word);
- 专业词比普通词更能预测用户搜索的主题,需要适当提高影响因子。
具体操作是,对以上3个词,分别使用公式log(D/Dw)计算IDF,其中,D是全部网页数,Dw表示关键词w在多少个网页里出现过。
假设中文网页数D=100亿,专业词“杭亦白”出现在其中2000万个网页中,IDF1=log(100亿/2000万)=8.96;停止词“的”出现在所有网页中,IDF2=log(100亿/100亿)=0;普通词“公众号”出现在1亿个网页里,IDF3=log(100亿/1亿)=3.32.
因此网页X1与搜索词的相关性计算变成了以下的加权计算:
Relevance1=TF1*IDF1+TF2*IDF2+TF3*IDF3=0.002*8.96+0.03*0+0.005*3.32=0.02556。
即网页X1与搜索“杭亦白的公众号”之间的相关性系数为0.02556.
同理分别计算出X2、X3和搜索之间的相关系数。系数越大,证明网页“越准确”,考虑排在越靠前的位置。
学到这,小白心里又犯嘀咕了:好像都是一些上古时代PC端的知识,有没有偏APP端的呢?想到这,小白关上电脑打开手机,开始了新的征程。
号外:新开“小白学搜索”系列,暂定分上中下三篇更新,用尽量直白的语言把搜索讲明白。请搜索大佬不吝后台赐教。
参考资料:
《数学之美》 吴军人民邮电出版社
作者:杭亦白(微信号:xiehangfeng01)。互联网产品新人,对搜索、产品、社交感兴趣,坐标上海;微信公众号:杭一白(微信号:xiehangfeng02)
本文由 @杭亦白 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议










催更催更
什么时候出下篇啊,上篇学到了很多
这写的太好了!就等中下篇了!
大佬,坐等中下篇!
坐等中!
感谢分享~
把简单的东西讲得很复杂的感觉
果然是小白学搜索,我一个小白都看懂了呢。鞋大佬分享~
大佬可以分享一下自己网站内的搜索逻辑应该是如何的吗?
同坐等中下篇~
大佬,中下篇什么时候出呀,你这上篇看的我是有滋有味的,坐等中下~