
 起点课堂会员权益
起点课堂会员权益OCR在数据抢救中的应用设计
OCR是通过算法识别出图像中的文字内容,算是图像识别的一个分支。但是在数据管理抢救上,也非常实用。本文作者对具体的实现途径展开了梳理总结,并对过程中存在的问题进行了分析,与大家分享。

一、服务于业务:数据抢救的痛点在哪?
大数据工程的第一步是获得数据,而传统行业、政府机构、科研院所中有大量的存量数据,数据抢救就是把这些数据数字化,一是避免数据流失,二是提高利用价值。而存量数据中包括大量珍贵的纸质数据,比如天文地理水文测量数据、试验数据、政府公文、古旧书籍等等。
纸质数据如何抢救?这步很简单,基本解决方法就是先扫描成电子版进行存储。但光是扫描存储就够了吗?我觉得是不够的。
像前边所说的,数据抢救的目的一是避免数据流失,二是提高利用价值,扫描存储仅仅解决了第一个问题避免数据流失,但并没有很好的提高数据的利用价值。纸质数据的价值大部分在于文档的内容,仅仅把纸质文档电子化仍然不能对内容进行进一步的检索、分析。
所以我们把产品的目标聚焦在了“提高数据利用率”上。接下来就是对目标进行细化拆解。关于如何提高利用率,也就是数据如何应用,我是这样思考的,一是从大数据角度看,如何利用统计分析等手段提高数据整体的价值;二是从单份文档角度方面看,如何让单份文档更有价值,让有兴趣的用户更容易找到它,让用户找到这份文档后能快速了解其内容。
- 让有兴趣的用户更容易找到数据,也就是大家都非常熟悉的“百度一下”“谷歌一下”。纸质数据在图片/PDF状态时,无法检索到内容,如果只根据文档名称检索肯定效果会大打折扣,所以我们需要所谓的【全文检索】。通过全文检索,数据就有了一个出口。
- 让用户找到数据后能快速了解其内容,也就是大家读paper时熟悉的的关键词、摘要。我们可以利用【内容分析】,比如提取文章中的关键词、生成摘要等等,对信息进行概括。这样在通过全文检索发现数据后,用户能尽可能快速对数据进行更充分的理解。
通过上边的分析,单份数据利用的方式基本确定为【全文检索】和【内容分析】,而这两种利用方法都需要对纸质文档中的文字进一步进行处理,这就需要我们数据抢救的好伙伴:OCR上场了。
二、功能设计
1. 业务场景
小李所在的单位有大量多年积累下来的文书,有些年代久远的已经出现了破损遗失的情况,借着大数据工程建设的契机,单位决定开展历史数据抢救工作。
工作的第一步就是整理文书文档,然后扫描电子化,每扫描完一份文件小李就在页面上预览确认没有问题后提交,之后系统对文档进行OCR识别,识别完成后小李在页面上可以预览查看识别结果,发现位置识别不准或者文字识别有误可以进行调整,最后保存调整结果即可。
小李辛辛苦苦做完的工作体现在哪里呢?
同事小陈最近做的一项工作需要查阅往年数据A的相关记录,小陈登录系统直接搜索“数据A”,搜索结果显示了所以包含“数据A”的文档。小陈依次点击搜索结果就可以查看文档的摘要和关键词,从而判断该文档是否对他有用。
大概业务的流程就是下图这样,我们这篇主要介绍小李的工作部分。
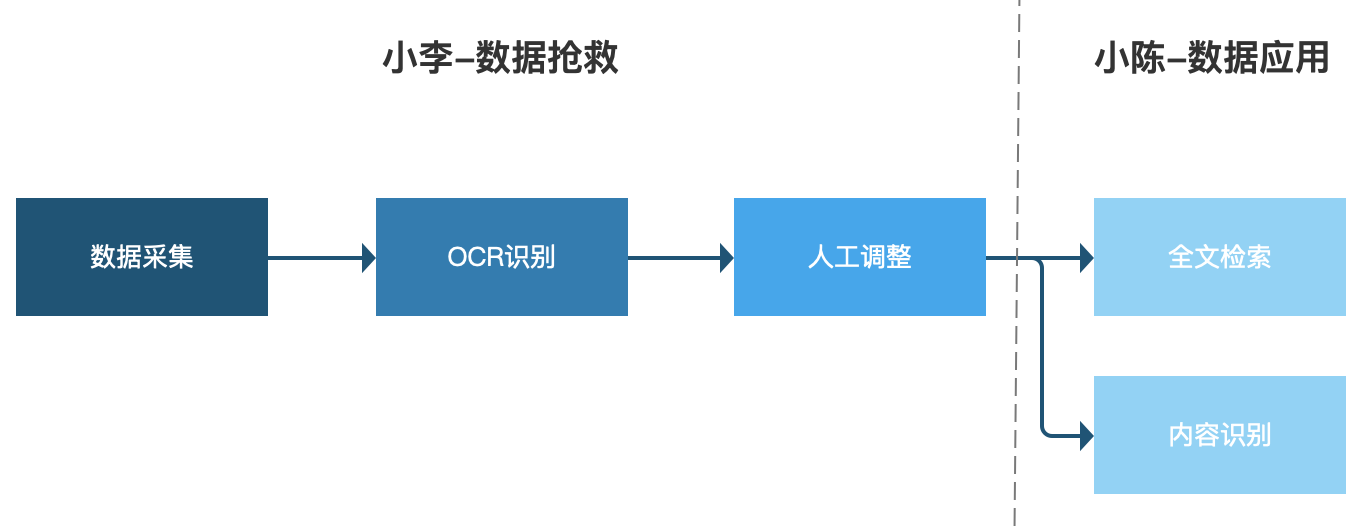
2. 实现途径
(1)数据采集
数据采集主要依赖于扫描纸质文档的扫描仪,所以这一部分是一要考虑扫描仪本身的性能,二要考虑扫描仪与整个系统的集成。
考虑到纸质数据量大、装订方式多样的特点,扫描仪最好满足快速扫描、不拆书、尽量自动化的要求。调研了市面上成熟的商用扫描仪,符合要求的扫描仪大概有几类:
- 专门用于古籍扫描的全自动翻书扫描仪,就一个缺点,太贵(140-180w)
- 需要手工翻页,但不用拆书的高速扫描仪,这类扫描仪选择比较多,成本也可以接受
- 最后一种选择,非常有趣,是google books的开源自动扫描仪方案,需要自行组装,有兴趣的朋友可以了解一下(https://linearbookscanner.org/)
系统与扫描仪集成方面,就涉及到扫描好的文件怎么存储到系统?大概有两种方案:
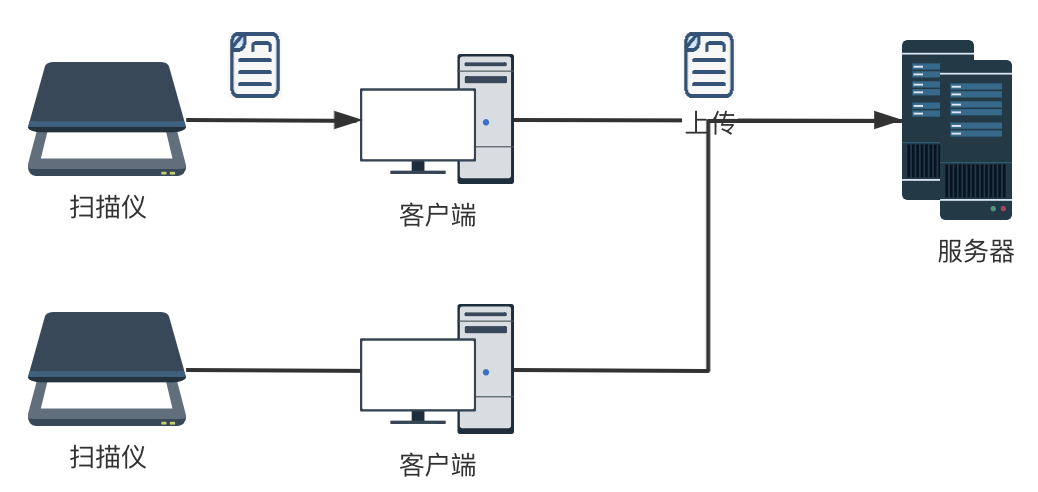
1)我们平时用的扫描仪,一般是连接电脑(客户端),把扫描好的文件存在本地,然后由用户把文件手动上传系统
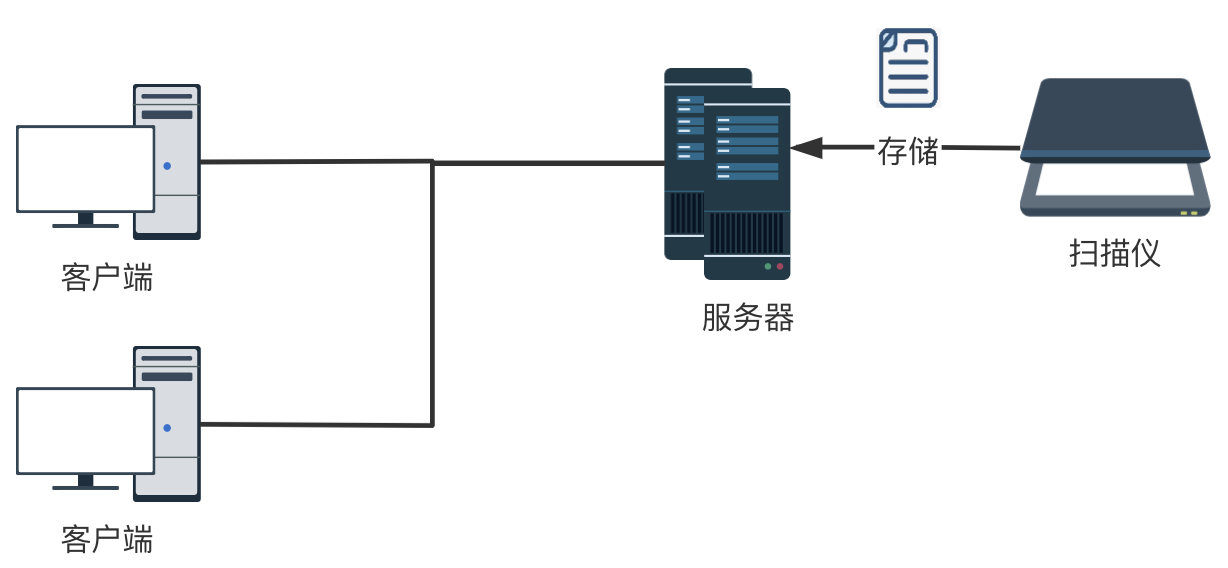
2)网络扫描仪直接通过局域网连接服务器,扫描好的文件直接存储在服务器指定位置。这种网络扫描仪的方案需要扫描仪支持TWAIN或者其他SDK、api,好处是多个用户可以共用扫描仪,操作步骤也要简化很多
结合扫描仪性能、系统集成和成本角度考虑,我们选择了一款支持TWAIN接口的手动翻页扫描仪作为数据抢救系统中硬件支撑。
(2) OCR识别
首先我们需要对OCR的算法有个大概的了解,可以参考OCR在资产管理系统的应用。
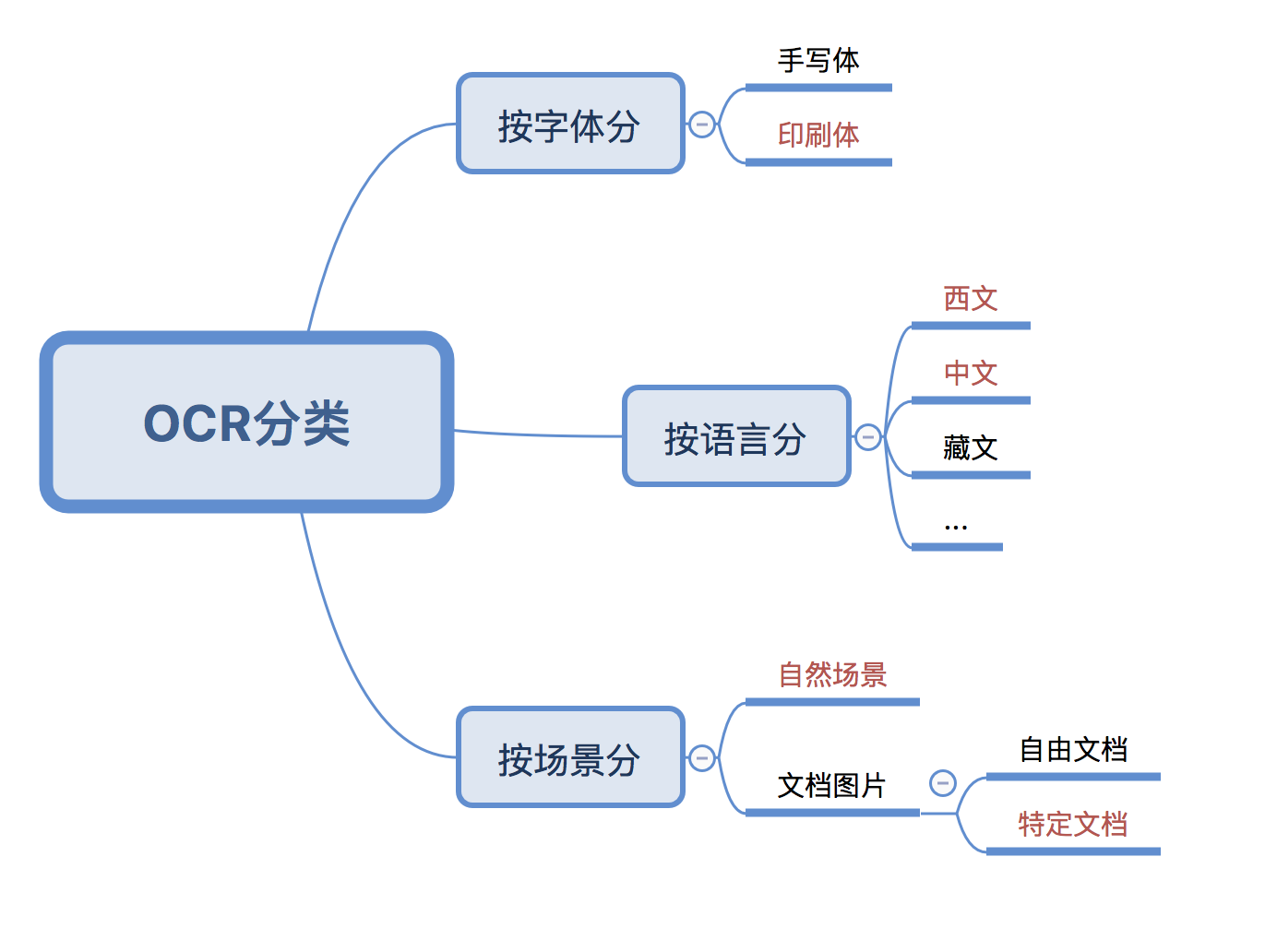
用于数据抢救的OCR和用于资产标签识别的OCR还是有一点区别的,资产标签识别中的识别对象是【自然环境】中的【印刷文字】,而数据抢救对象是【文档图片】中的【印刷文字】。
但总体来说处理的流程还是预处理-文字检测-文字识别,只不过对纸质文档中复杂的排版(图片、表格、文字、页码、公式混排等等)的文字检测换了种说法叫做版面分析(layout analysis),做的事情还是差不多的,除了负责检测出文字的位置外,也要同时确图表等其他要素的位置。
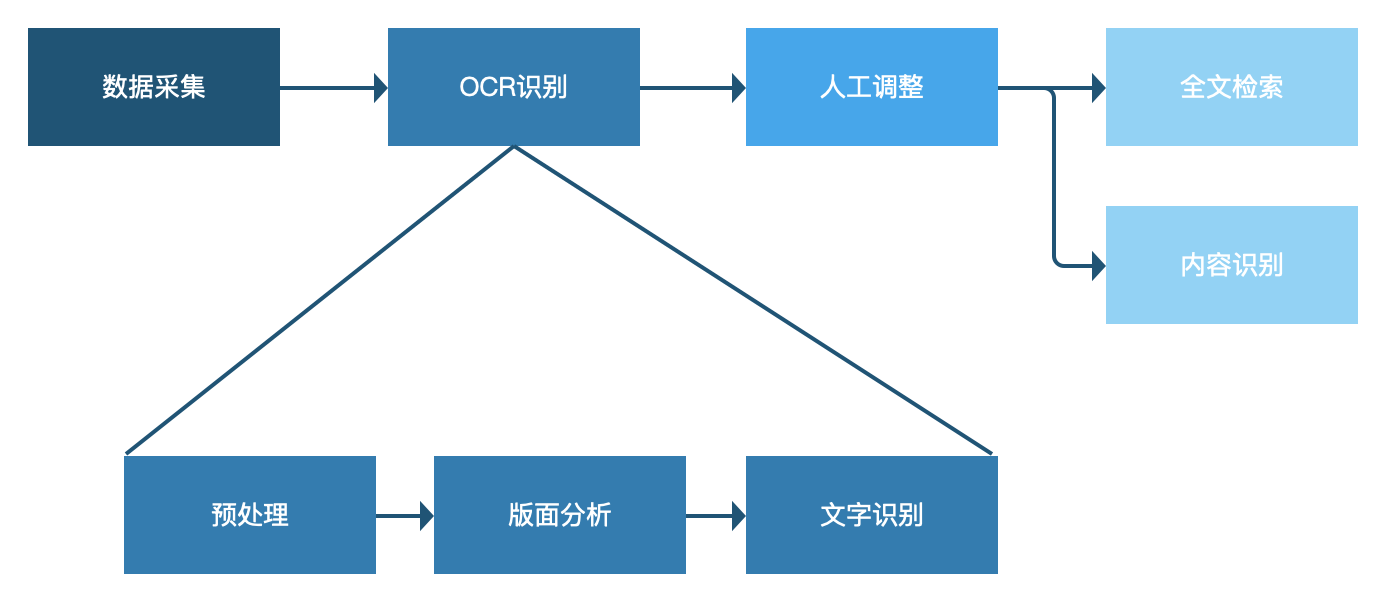
1)预处理:
预处理的目的主要是提高图像质量,一般用传统的图像处理手段就可以完成,现在很多扫描仪也会把这部分做在里边,比如自动纠偏、去黑边等,如果可以满足要求,预处理部分放在数据采集时由扫描仪完成也是可以的。
2)版面分析:

先看下直观的看下版面分析的预期效果。关于版面分析这块我们需要确认的事情主要有3件:一是检测的目标有哪些,二是目前算法的成熟度,三是性能方面的要求有哪些。
确定检测对象:毕竟版面分析是个检测问题,和检测图片中的猫狗没有本质区别,所以我们要先确定版面分析需要识别什么东西。在数据抢救中我们关心什么呢?首先文字是最重要的,第二为了定位图片和表格,我们也需要图片、表格的位置以及图注、表名,有了这些信息就可以形成类似索引目录,方便查找。所以初步确定,版面识别需要识别出文字、图片、表格、图注、表名五类对象。
算法成熟度:虽然传统的图像识别也可以实现简单的版面分析任务,但对上图这种非常复杂的版面分析经过调研比较靠谱的方法还是上深度学习。可以做版面分析的深度学习算法主要是图像检测一系列的,比如yolo、fastRCNN,这篇文章中的大佬是用MaskRCNN实现的。所以版面分析问题已经有不少研究基础了,但实际落地的应用可能还不是很多,其中需要优化的工作肯定还有不少。
性能要求:算法的选择当然要考虑实际中对硬件性能、识别速度、识别精度、召回率的要求。
- 用在我们数据抢救中,首先系统是采用B/S架构,在服务器完成识别任务,所以没有特殊硬件要求(如果是在端上实现就要考虑硬件对算法限制了)。
- 识别速度方面,目前考虑到一份纸质数据可能有成百上千页,所以识别时间会比较长,所以暂定以后台任务的方式执行,这就对识别速度方面要求也比较低(如果要求实时返回识别结果一般识别速度就要做到秒级)。
- 识别精度和召回率的平衡方面,由于后边有人工校验调整的环节,所以还是可以适当提高召回率,即使识别有所误差也可以通过人工调整弥补。
c)文字识别:
文字识别部分相对来说也比较成熟,目前两大主流技术是 CRNN OCR 和 attention OCR。在我们的整体流程中,需要对版面识别后的文字、图注、表名区域进行分别识别即可。
上边技术实现途径的调研主要为了证明我们设计的功能是在技术上可实现的,避免出现设计出无法实现的功能的尴尬情况。
3. 功能流程
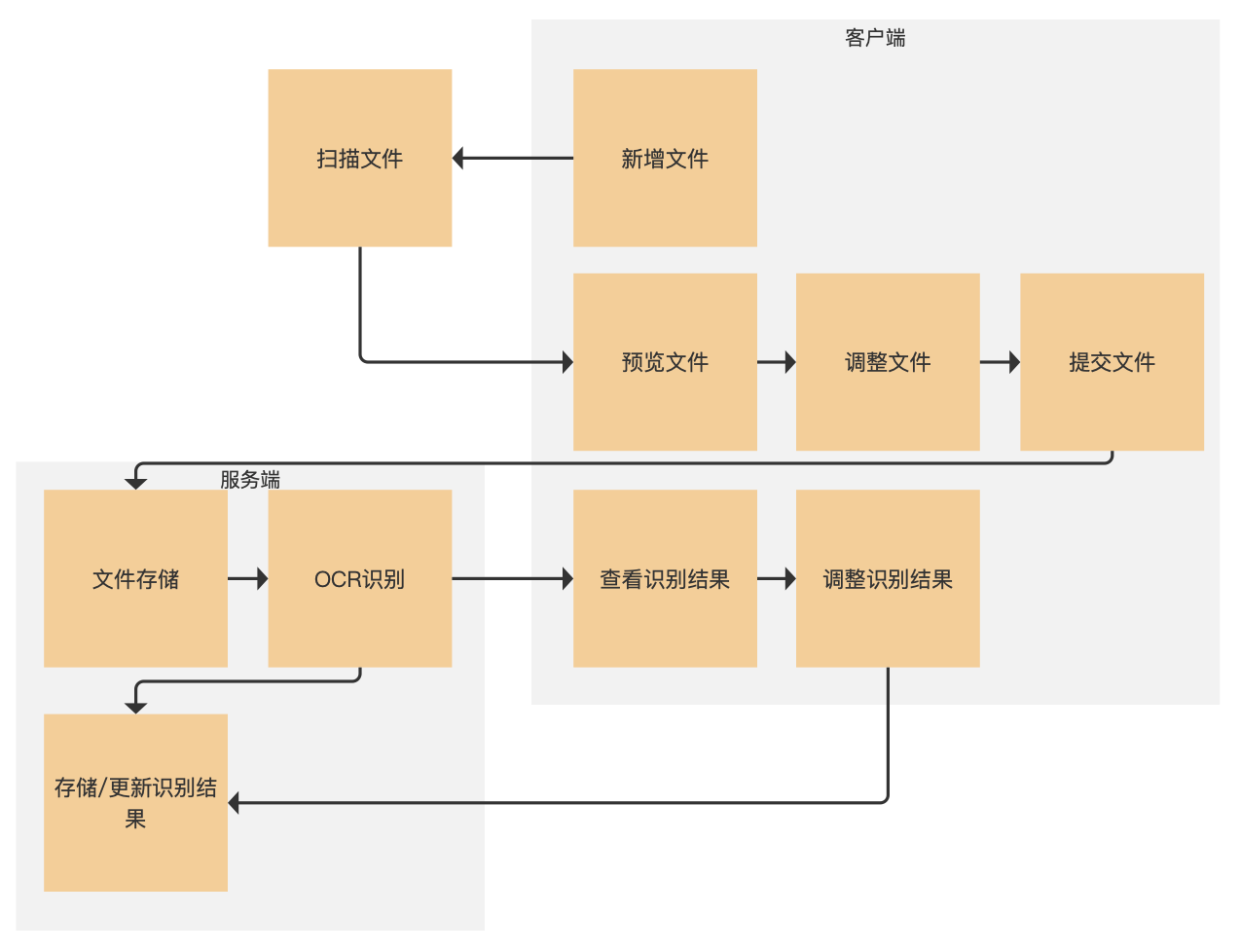
正如前边所说的,我们这里的功能只关注纸质数据抢救工作没有涉及到数据应用的部分,所以从扫描文件到最后人工调整OCR识别结果,整个纸质数据抢救的功能就算完成了。对用户来说,相较于只扫描文件并保存,多出的操作步骤就是查看识别结果并调整的部分。
4. 核心页面设计
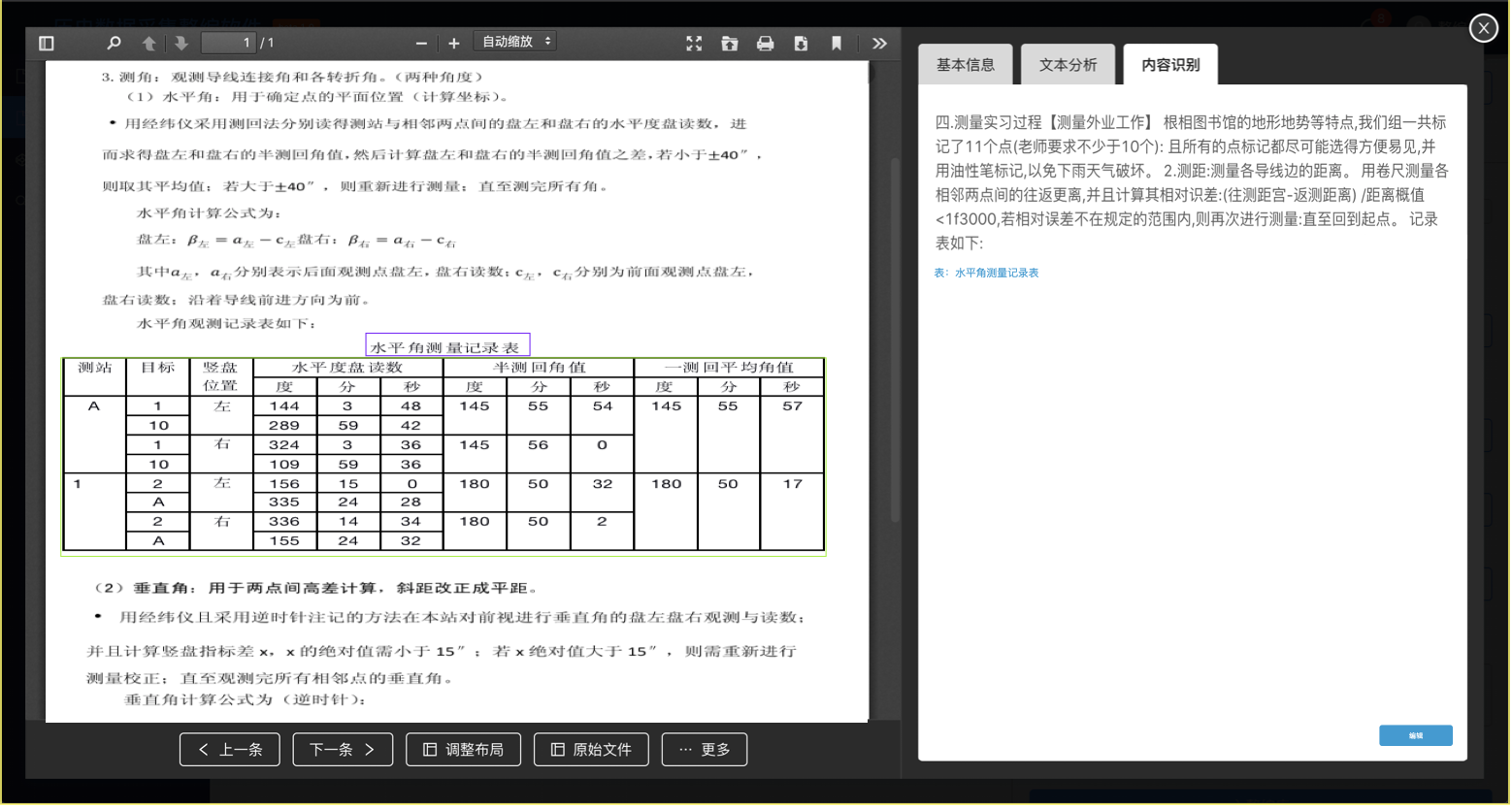
(OCR识别结果查看)
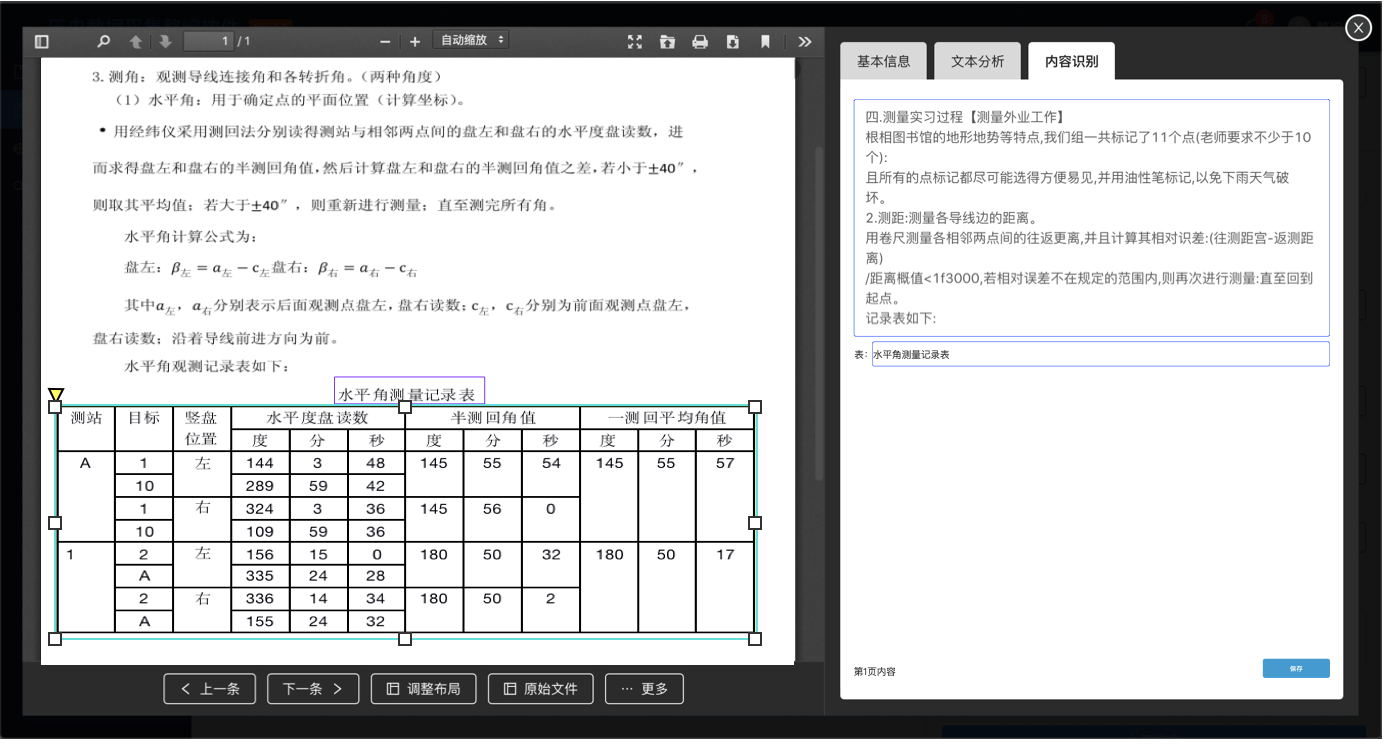
(OCR识别结果调整)
OCR相关的两个页面主要是查看识别结果和调整识别结果。查看页面主要包括预览文档、用线框表示图表区域和图表标题、显示OCR文字识别结果。点击【编辑】跳转到调整页面,调整页面以每页为单位显示,图表框可拖拽调整、文字变为可编辑状态。
三、小结
通过需求分析我们发现在数据抢救中的确存在OCR应用的必要性,然后从技术实现的角度进行调研验证需求是否是可实现的,最后梳理整个功能流程再加上每个功能点的详细说明/原型设计功能基本就齐活了~
本文由 @LCC 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。









ocr识别出来的数据是可编辑的还是不可编辑的,例如ocr识别驾驶证
看业务需求呀
像ocr识别驾驶证,为保证识别信息的准确性,应该要有人工校验的过程吧(也就是可编辑