
 起点课堂会员权益
起点课堂会员权益线下商场基于LBS的推荐系统方案设计
编辑导读:在现实生活中我们经常会用淘宝、京东、百度等产品去搜索想要买的产品或者想要知道的讯息。在需求不明确的情况下,产品会对我们的需求进行深度挖掘和匹配,这就是推荐系统在起作用。
本文从搭建推荐系统的意义出发,对推荐系统的设计和过程中需要注意的问题进行了分析总结,供大家一同参考学习。

一、搭建推荐系统的意义
1. 降低物品信息过载困扰,帮助用户快速找到喜爱商品
当前商场店铺比较多,物品排列密密麻麻,对用户的选择造成一定的干扰,以至于无处下手,最后不了了之,而推荐系统的搭建一定程度上解决了信息过载问题,直接将潜在物品推荐到用户面前,缩短购买路径,提高下单量。
2. 深度挖掘商场内长尾商品,提高GMV
经过一系列商品数据采集、分析、打标操作,实现商品的统一化管理,深度挖掘长尾商品,将该类商品推送至目标客户面前,提高其曝光度,降低商品对货柜、店铺位置的依赖,从而提高营业额。
3. 对于无目的客户,推荐折扣商品、营销活动,刺激购买欲望
针对对无购物目的的人群,推荐系统自动推荐低价好货、热门活动和限量商品,吸引客户注意力,达到营销和门店导流的目的,刺激客户购买欲,从而提高下单量。
4. 通过购物车分析,推荐给客户更多关联商品,提高用户的惊喜度和满意度
针对老客户,通过购物车分析,推荐给客户性价比更高的类似商品,提高用户购物体验的惊喜度和满意度。
二、数据采集与数据准备
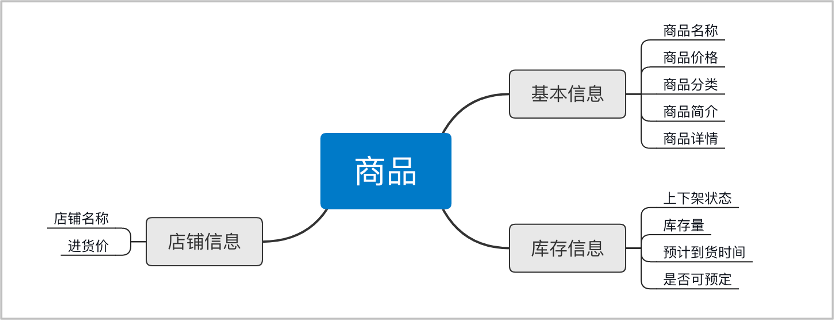
针对上述需求,我们最终的目的是将人、货、场进行匹配,为此我们需要收集用户、商场、商品的数据信息。包括:
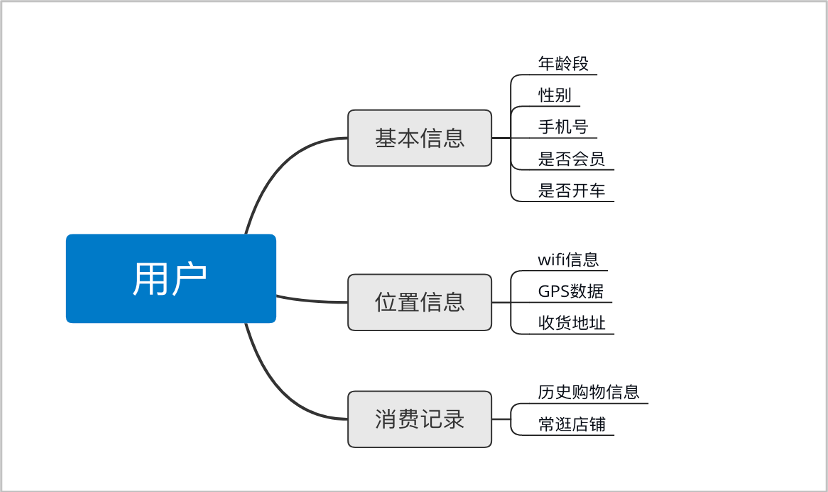
商场信息:
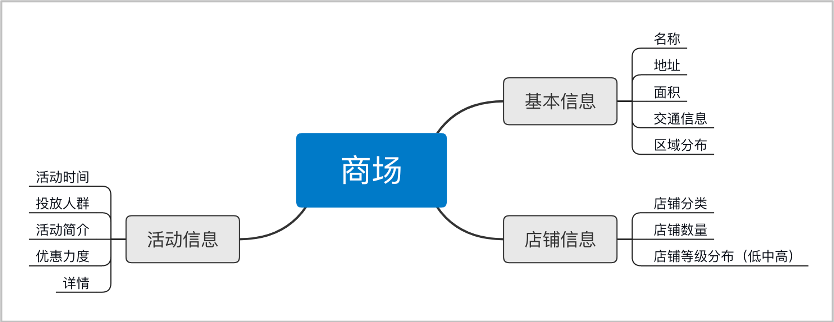
物品信息:
三、推荐算法实现
整个推荐算法主要利用商场的用户行为数据,采用基于邻域的用户协同过滤和物品协同过滤。
1. 基于商场用户的协同过滤算法
基于用户的协同过滤算法基本上分成2步:
- 通过分析商场用户历史订单信息,计算该用户的行为向量,找到相似的用户群体。
- 将相似群体所有购买过的物品列表中,从中过滤掉已购买的商品后,将未接触的商品同步推送给用户。
首先,计算用户相似度,找到相似的人群,通过两两用户对比,得出该对用户的相似度。具体算法如下:
假设有A,B 2个用户,A用户曾购买过{a,b,d},B 用户曾购买{a,c},我们约定:
- N(A):代表A用户所购买过的物品清单;
- N(B):代表B用户所购买过的物品清单;
- W(AB):代表A、B用户的相似度值;
那么根据余弦相似度公式得出:
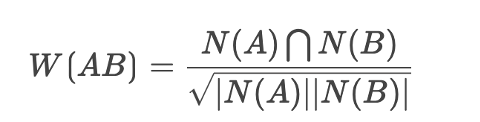
假设现在有一组这样的用户购买记录数据,如下图所示:
A用户购买了{a、b、d},B用户购买了{a、c},C用户购买了{b、e},D用户购买了{c、d、e},

我们可以得出:
W(AB)=0.409;
W(AC)=0.409;
W(AD)=0.333;
根据A用户与所有其他用户的相似度值从高到低排序,依次为B、C、D,一般情况下我们会选取与A用户最相似的K个用户用来做推荐,假设此时取k=3时,那么就是将B、C、D用户的所有物品减去A已经购买过的物品,从而得出可推荐列表,即{c,e}。
此时推荐列表是一个无序列表,为提高推荐的精准度,我们需要计算出A对以上列表项中各个物品的喜爱程度,进而把最符合A兴趣的物品进行推荐。
分别计算用户A对c、A对e物品的喜爱程度:
根据公式:
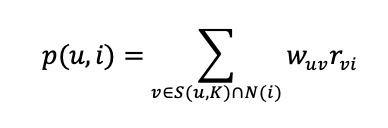
w(uv)是指用户u与用户v的相似度,r(vi)是指用户v对物品i的喜爱程度,此处默认 =1 得出:
p(A,c)=W(AB) +W(AD)=0.409+0.333=0.742;
P(A,e)=W(AC)+W(AD)= 0.409+0.333=0.742;
2. 基于物品的协同过滤算法
基于物品的协同过滤算法基本上分成2步:
- 计算该商场内商品/店铺的的相似物品/店铺集;
- 根据商品/店铺相似性以及用户对该类商品/店铺的喜爱程度,将权重最高的商品/店铺推送给用户。
在这里我们做一个约定:商品/店铺相似度的计算思路基于用户对物品喜爱的人数,我们默认:对物品a、物品b喜欢的人数越多,那么两个物品之间的相似度越大。
我们约定:
- N(a):代表喜欢物品a的用户名单;
- N(b):代表喜欢物品b用户名单;
- W(ab):代表a、b用户的相似度值;
那么同样利用余弦相似度:
假设,在数据采集中,有这样一组用户数据:
A:{a,b,d}
B:{b,c,e}
C:{c,d}
D:{b,c,d}
E:{a,d}
我们通过构造矩阵来得出物品相似度矩阵:
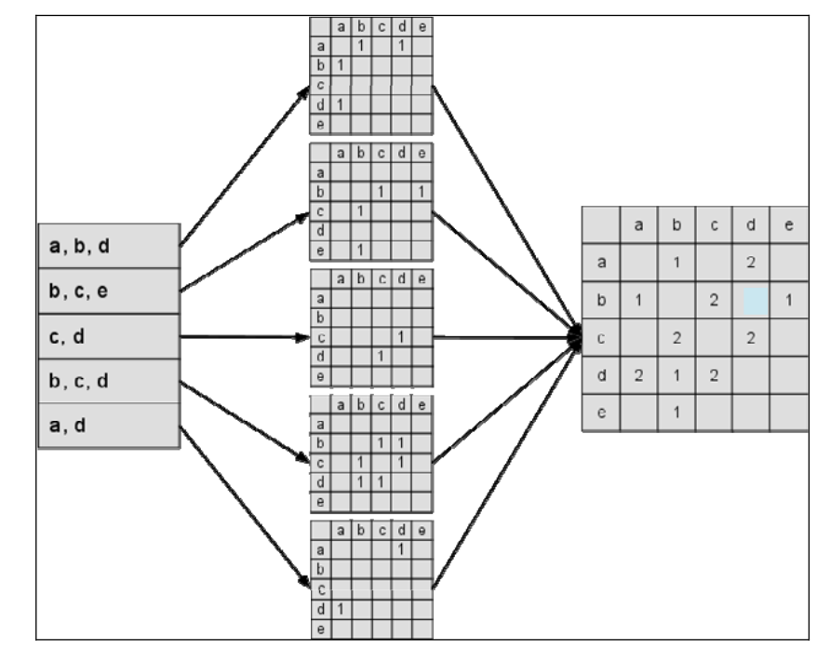
那么物品a和b的相似度即:
W(ab)=0.409;
W(ac)=0;
W(ad)=0.707;
W(ae)=0;
W(bc)=0.667;
W(bd)=0.333;
W(be)=0.578;
W(ce)=0 ;
W(de)=0 ;
利用公式,计算出用户u对一个物品j的兴趣:
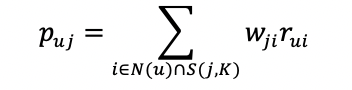
当K=3时,选出与a最相似的物品为b、c、d;与b最接近的物品为c、d、e;
3. 其他的混合推荐算法
选用基于用户标签、基于上下文信息和基于社交数据作为用户兴趣扩展推荐,从而丰富推荐系统的结果。
四、冷启动问题处理
当系统刚刚发布上线,数据准备不充分,想做精细化的个性化推荐就面临很大挑战,这时就需要寻找合适的方法解决系统启动后无推荐数据的问题,一般针对这些问题我们可以从几个方面入手:
- 利用用户注册信息,给用户推荐相应物品;
- 利用社交数据,推荐给用户其好友购买过和感兴趣的物品;
- 让用户自行选择自己感兴趣的品类,根据品类信息推荐相应数据;
- 推荐热门物品;
五、推荐系统的评估与迭代
一个商业推荐系统的评估一般是从用户满意度、预测准确度、覆盖率、多样性、新颖性、惊喜度、信任度、实时性、健壮性、商业目标几个维度来考虑。
1. 用户满意度
用户是推荐系统的重要参与者,用户满意是推荐系统优化的追求的目标。判断用户是否满意,我们可以从以下几个方面着手:
- 用户问卷调查,通过问卷的形式直接获得用户的感受;
- 数据统计,我们可以统计用户购买推荐商品的比率,如果用户购买了推荐的商品,那么就表示在一定程度上用户是满意的。
2. 预测准确度
推荐系统的准确度衡量是离线实验计算,在计算该指标时需要有一个离线的数据集,该数据集包含了用户的历史行为记录,然后将这个数据集分成训练集和测试集。最后将训练集的模型计算结果与测试集进行对比,将预测行为与测试集行为的重合度作为预测准确度。
例如在TopN推荐中,一般通过准确率和召回率来度量。令,R(u)表示在训练集中给用户推荐列表;T(u)是测试集上行为列表。
那么召回率(Recall)=
![]()
而准确率(Precision)=
![]()
3. 覆盖率
覆盖率是考核推荐系统对物品长尾的发掘能力。即推荐的物品集占总物品集合的比例。或者更细致一点就是统计推荐不同物品出现的次数分布,如果所有物品都曾出现在推荐列表,并且出现的次数差不多,那么就说明该系统覆盖率比较高。
4. 多样性
多样性要求推荐列表需要覆盖用户不同兴趣领域,既要考虑用户的主兴趣点又要照顾到用户其他的兴趣,从而扩大用户浏览量,提高订单量。
5. 新颖性
一般推荐结果的平均流行度度量新颖性比较粗略,如果要提高新颖性的准确度需要做用户调查。
6. 惊喜度
惊喜度对推荐系统是更高的要求,它是基本意思是如果推荐结果和用户的历史兴趣不相似但却让用户觉得满意。
7. 信任度
如果推荐结果的可解释性能提高用户的信任度,比如提示用户,你的xx好友曾购买过该商品,这样更能让用户对推荐的商品感兴趣。
8. 实时性
如果推荐结果能够根据用户的行为实时发生变化,那么就说明该系统实时性比较好,当前很多公司采用流式计算来提高系统的实时响应度。
9. 健壮性
众所周知,绝大部分的推荐系统都是通过分析用户的行为实现推荐算法的,那么如果有人恶意注入行为攻击,很容易导致推荐结果的不准确,所以一个好的推荐系统需要有较强抵抗噪声数据的能力。
10. 商业目标
推荐系统的结果要时时关注与商业目标是否一致,技术的驱动离不开业务的支持,一个能给公司带来盈利的系统才能更加长久。
本文由 @alentain 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。









一直觉得推荐系统在线上还有点用武之地,至于线下不说实施难度,就说这个必要性都有待商榷。我们逛线下商场一个重点就是逛,不在乎要买什么,就是漫无目的的逛,没有人一进商城留瞅准目标,然后买完就走人,这类人少之又少
用户场景:
1.商场一定距离,目标非消费
2.商场购物,按照当下时间推荐,例如改到饭点了或者可以去看场电影
3.根据用户路线(一般商场分类都是按照楼层的),推荐热门商店
这个线下推荐系统的业务场景是啥?有请作者给我们描述一个完整的用户故事
几个问题1.线下商场场景下,用户通过什么场景来为你提供数据。(进商场提示下载关注等诱导前提条件得考虑,不然你这个方案没法实现)2.线下商场的物品做协同过滤算法和线上无差别。但是问题来了,实际上并不是每一个商户都把商品数据共享给商场,也就是说没法打通商场所有(大部分)商品数据,然后就没法满足你的推荐场景3.线下商场设计商铺位置是根据客流来进行调整以及品牌关联度来设计。你这个推荐应该考虑客流数据(可以理解为行为数据应用但是这里的数据是通过啥来获取)和推荐的相关性~~最后线下商场的用户行为数据和商场打通确实不容易,敢情实现起来还是很难~纯感想
核心还是协同过滤,lbs只是一个纬度的数据呀