
 起点课堂会员权益
起点课堂会员权益从搜索说算法
编辑导读:我们每天都在用的搜索引擎,看似简单,其实背后的技术细节非常复杂。本文将从六个方面分析搜索引擎是如何工作的,希望对你有帮助。

我们每天都在用 Google, 百度这些搜索引擎,那大家有没想过搜索引擎是如何实现的呢?看似简单的搜索其实技术细节非常复杂,说搜索引擎是 IT 皇冠上的明珠也不为过,今天我们来就来简单看一下搜索引擎的原理,看看它是如何工作的。
- 网页抓取:搜索引擎通过爬虫将网页爬取,获得页面 HTML 代码存入数据库中。
- 预处理:索引程序对抓取来的页面数据进行文字提取,中文分词,(倒排)索引等处理,以备排名程序使用。
- 排序:排名程序调用索引数据库数据,计算网页的相关性。其中最著名的是Google搜索引擎的核心排序算法:PageRank。
- 查询:用户输入关键词后,首先肯定是要经过分词器的处理。比如我输入「中国人民」,假设分词器分将其分为「中国」,「人民」两个词,接下来就用这个两词去倒排索引里查相应的文档。
我们重点来看一下第一步:网页抓取。
这一步的大致操作如下:给爬虫分配一组起始的网页,我们知道网页里其实也包含了很多超链接,爬虫爬取一个网页后,解析提取出这个网页里的所有超链接,再依次爬取出这些超链接,再提取网页超链接。如此不断重复就能不断根据超链接提取网页。
如下图示:
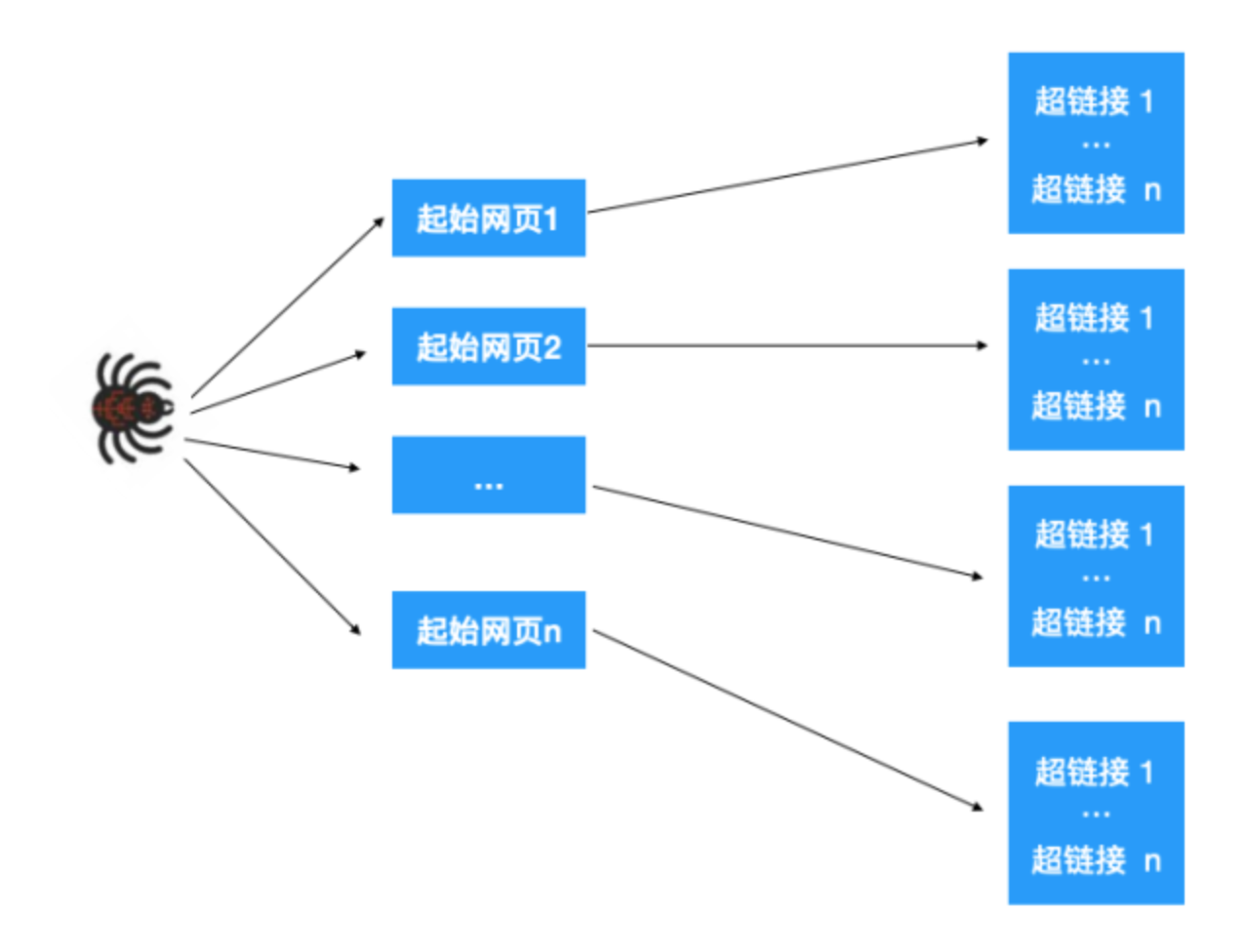
如上所示,最终构成了一张图,于是问题就转化为了如何遍历这张图。
一、什么是图的遍历?
从已给的连通图中某一顶点出发,沿着一些边访遍图中所有的顶点,且使每个顶点仅被访问一次,就叫做图的遍历,它是图的基本运算。
遍历的实质是找每个顶点的连接点的过程。
图的特点:图中可能存在回路,且图的任一顶点都可能与其他顶点想通,在访问完某个顶点之后可能会沿着某些边又回到了曾经访问过的顶点。
以逛公园为例,从公园入口v1出发,如何用最短的路程逛完公园全部7个景点,这就是一个典型的图的遍历。
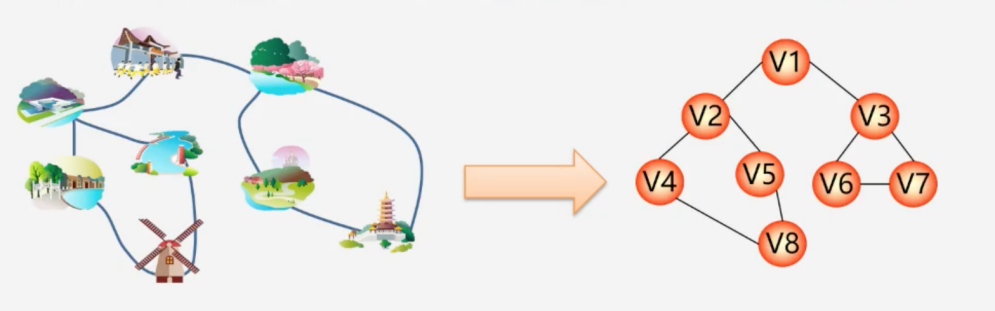
图常用的遍历方法有两种:
- 深度优先搜索(Depth_First Search——DFS)
- 广度优先搜索(Breadth_First Search——BFS)
二、什么是深度优先搜索?
以经典的迷宫图来看看如何遍历。
题目:如何从迷宫入口出发,点亮迷宫中所有的灯?
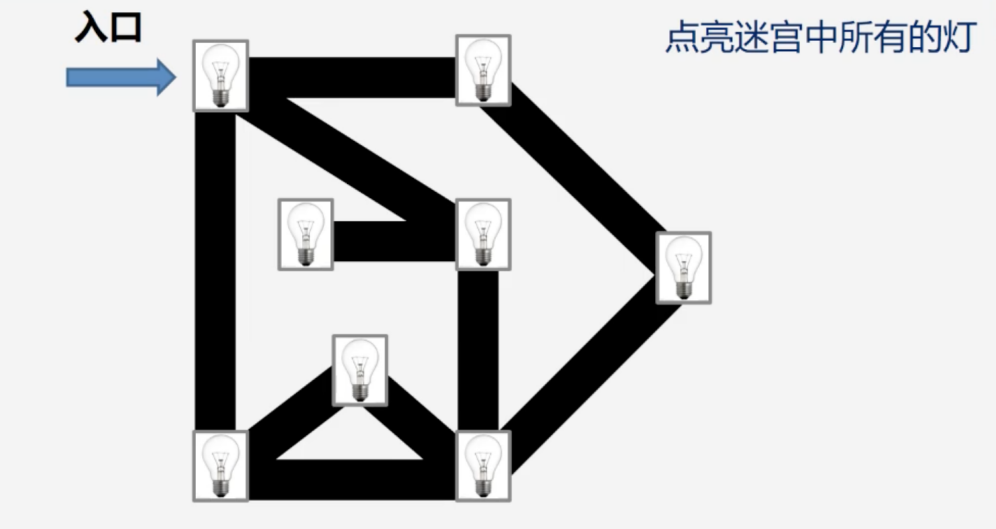
步骤一:从顶点(迷宫入口)开始遍历,它相邻的顶点有向右和向下的两盏灯,我们随机选择向右的那盏灯并将其点亮。
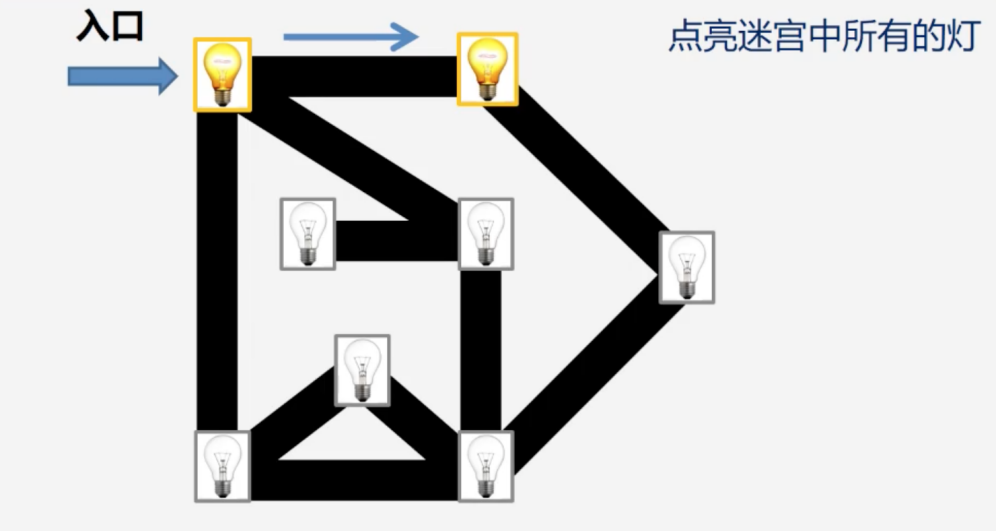
步骤二:以点亮后的这盏灯为顶点继续遍历。它相邻的顶点有两个:入口的灯和右下角的灯,由于入口的灯已点亮,我们只能点亮右下角的那盏灯。
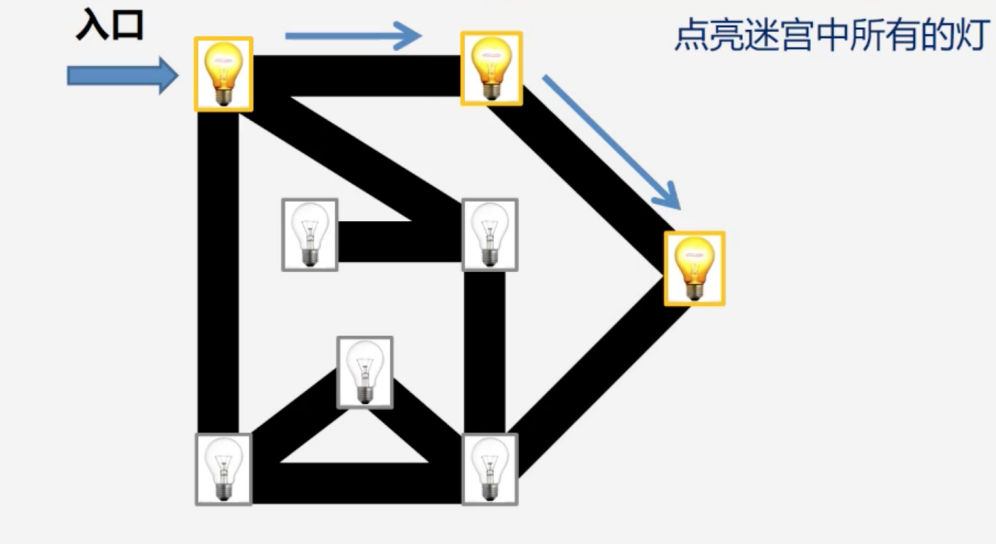
步骤三:重复以上步骤,以被点亮的灯为顶点继续遍历,直至这条路走不通为止,用通俗的话来说就是“把一条路走到黑”。如下图:
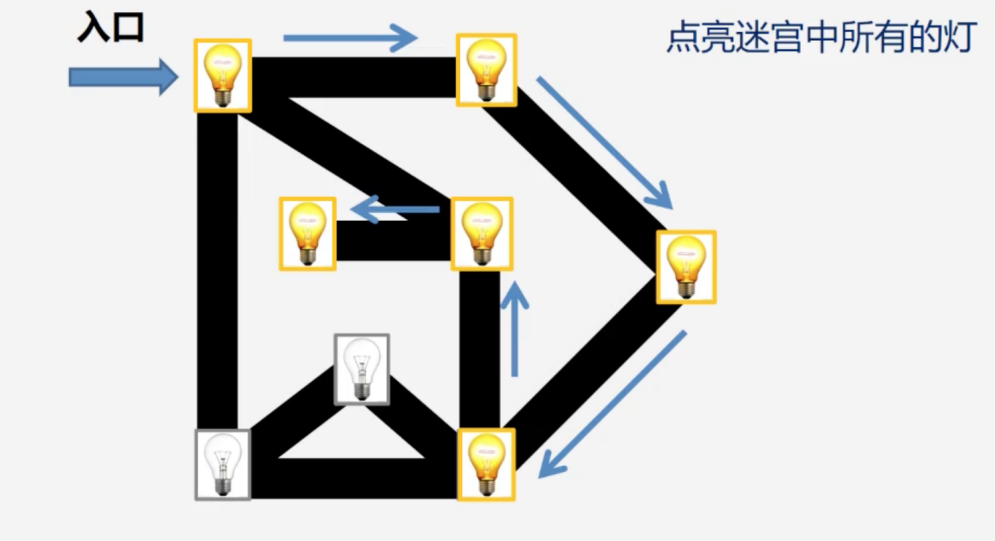
步骤四:无路可走后,沿着原路返回,继续寻找没有被点亮的灯,直至把所有的灯全部点亮。至此,我们完整地实现了深度优先搜索。如下图:
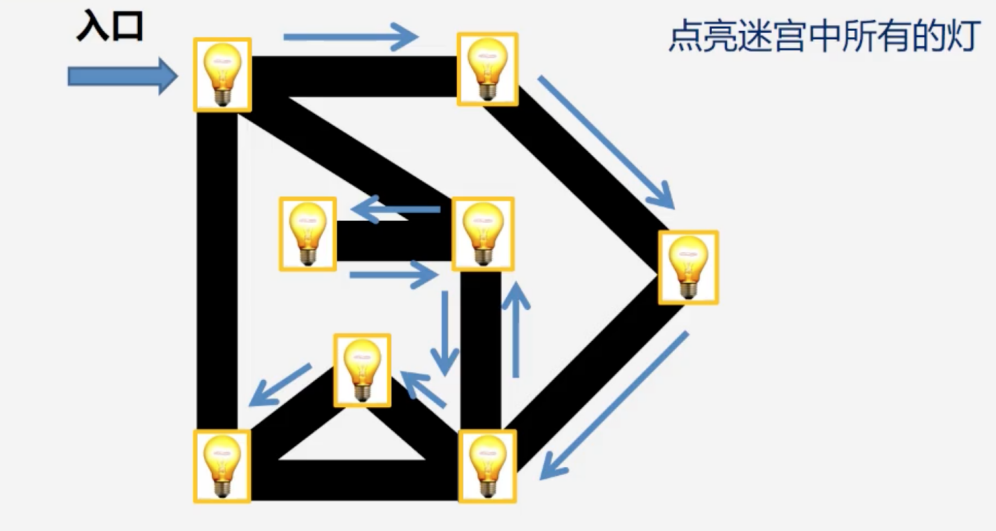
总结:
深度优先搜索的主要思路是:从图中一个未访问的顶点 V 开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底……
不断递归重复此过程,直到所有的顶点都遍历完成,它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走。
三、什么是广度优先搜索?
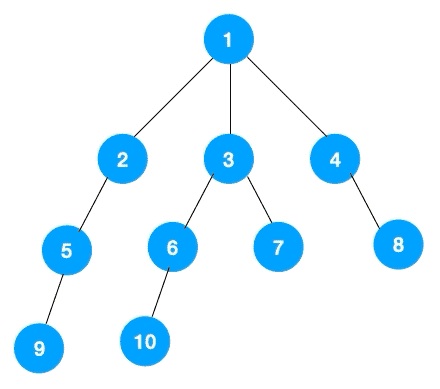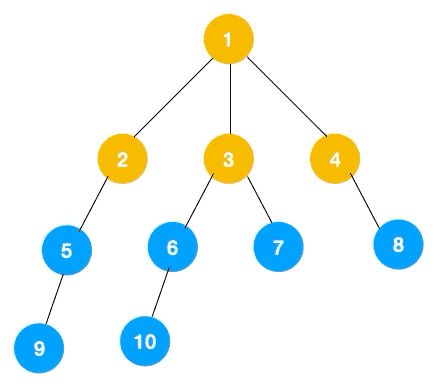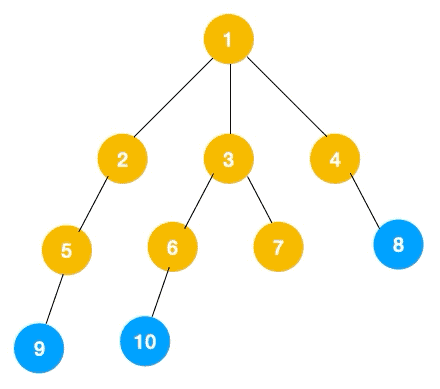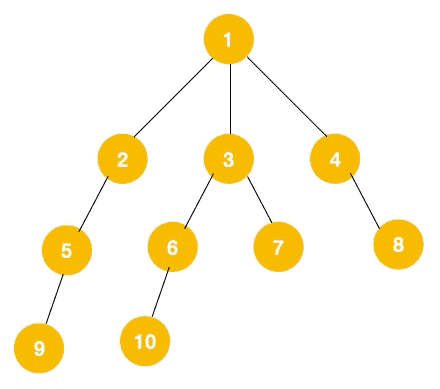
题目:如何从入口1出发,遍历整颗树?
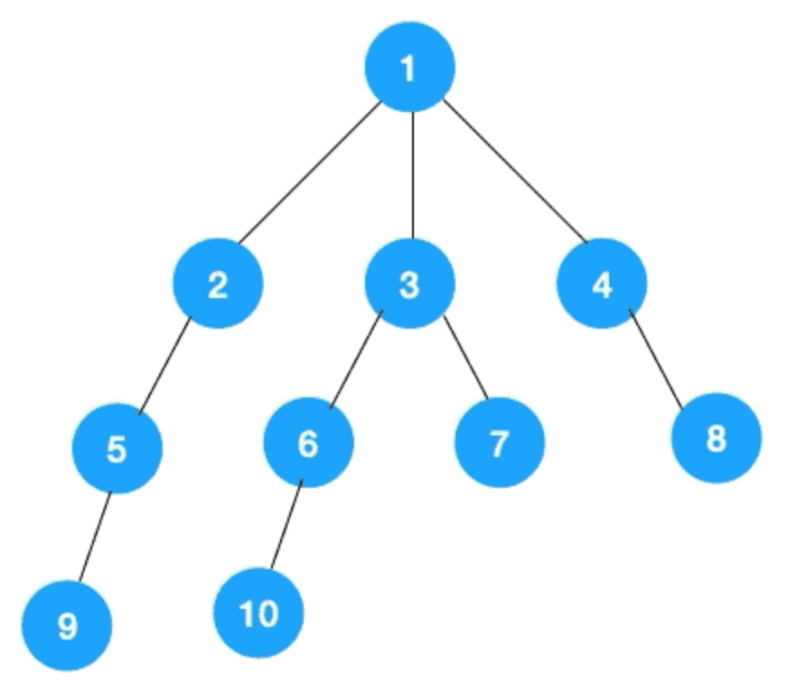
步骤一:先遍历节点1的所有节点——2,3,4。
步骤二:再分别遍历节点2,3,4的所有节点——5,6,7,8。
步骤三:再分别遍历节点5,6,7,8的所有节点——9,10。
总结:
具体思想:从图中某顶点1出发,在访问了1之后依次访问1的各个未曾访问过的邻接点,然后分别从这些邻接点出发依次访问它们的邻接点,并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问”,直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,则需要另选一个未曾被访问过的顶点作为新的起始点,重复上述过程,直至图中所有顶点都被访问到为止。
简单来说,广度优先遍历,指的是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点。
所以广度优先遍历也叫层序遍历,先遍历第一层(节点 1),再遍历第二层(节点 2,3,4),第三层(5,6,7,8),第四层(9,10)。
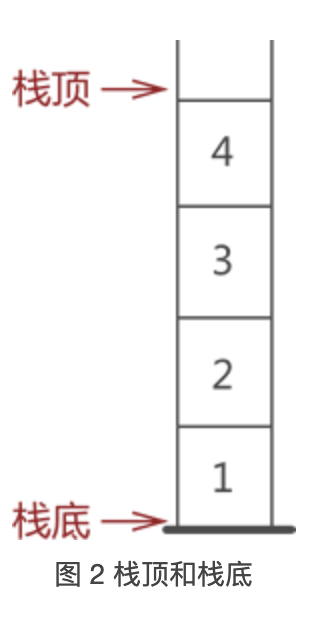
四、什么是栈?
栈是一种只能从表的一端存取数据且遵循 “先进后出” 原则的线性存储结构。
例如,我们经常使用浏览器在各种网站上查找信息。假设先浏览的页面 A,然后关闭了页面 A 跳转到页面 B,随后又关闭页面 B 跳转到了页面 C。而此时,我们如果想重新回到页面 A,有两个选择:
- 重新搜索找到页面 A;
- 使用浏览器的”回退”功能。浏览器会先回退到页面 B,而后再回退到页面 A。
而浏览器 “回退” 功能的实现,底层使用的就是栈存储结构。
五、什么是队列?
与栈结构不同的是,队列的两端都”开口”,要求数据只能从一端进,从另一端出。队列中数据的进出要遵循 “先进先出” 的原则,即最先进队列的数据元素,同样要最先出队列。
队列的应用也很广泛,只要满足“先来先服务”特性的应用均可采用队列作为其数据组织方式。例如在多用户系统中,多个用户排成队,分时地循环使用CPU和主存。
栈和队列在图的遍历中的应用:
深度优先搜索由于是先入后出的算法,使用栈来实现。而广度优先搜索是先入先出的算法,使用队列实现。
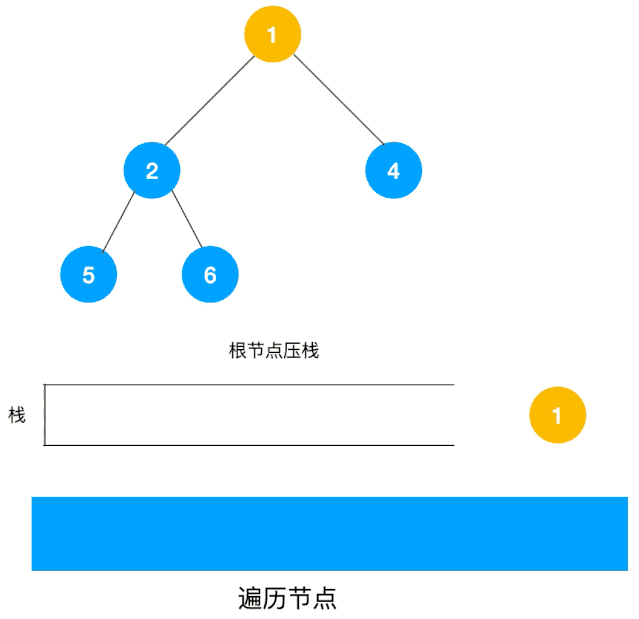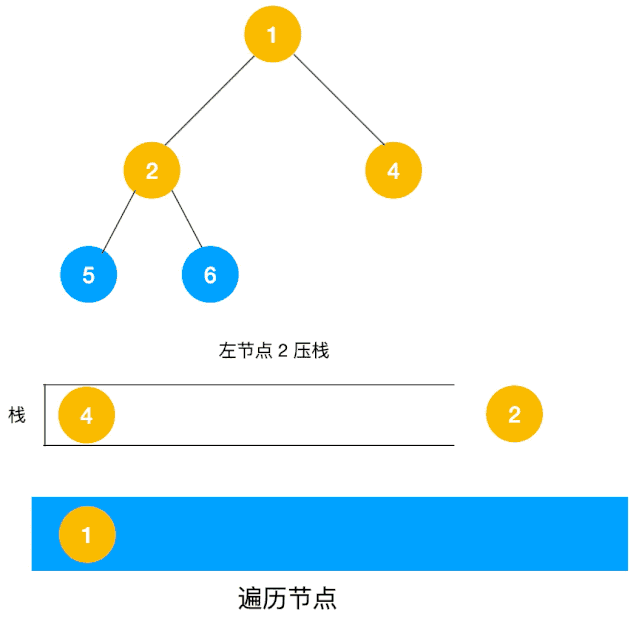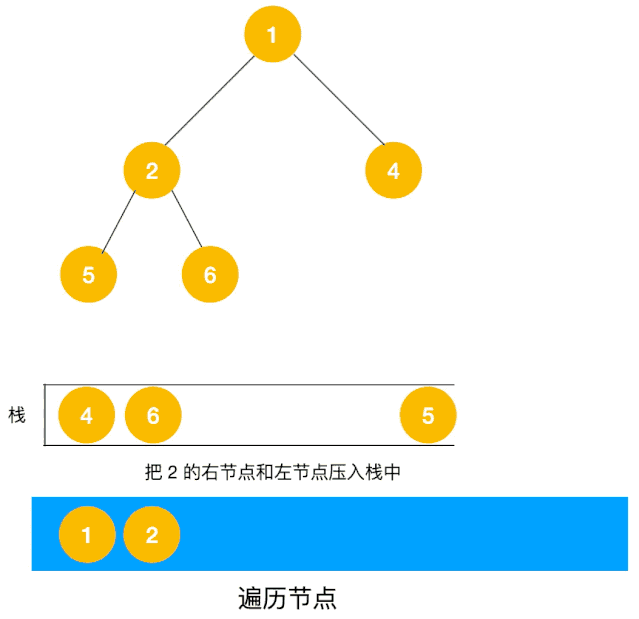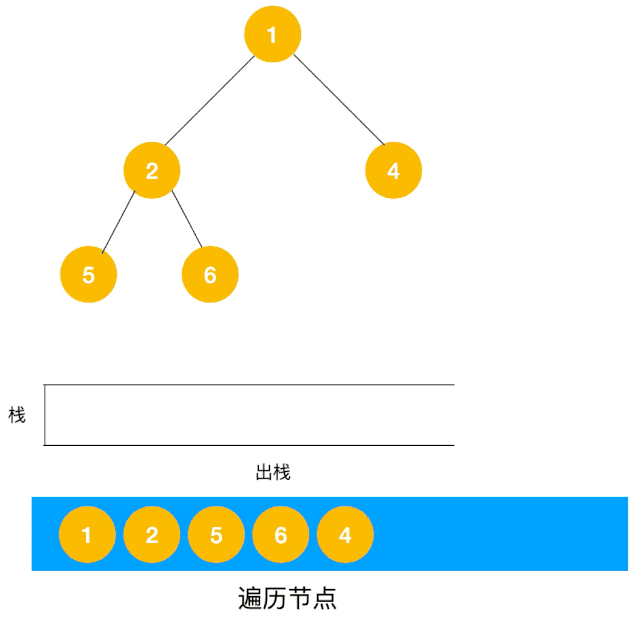
以二叉树为例来看下如何用栈来实现 DFS。
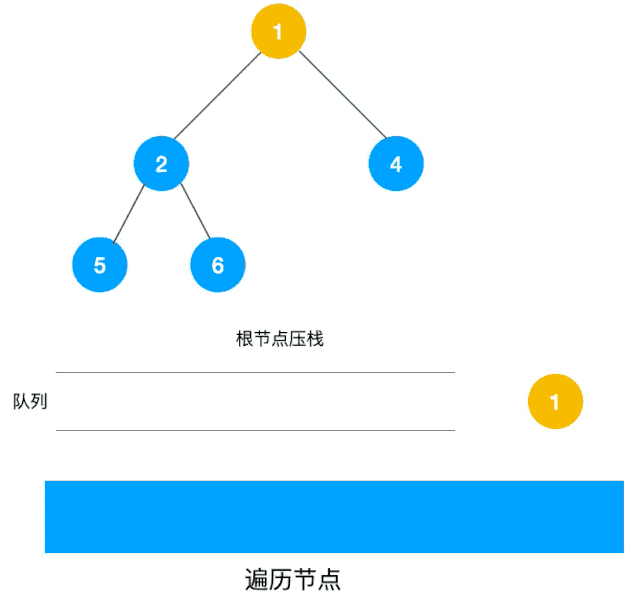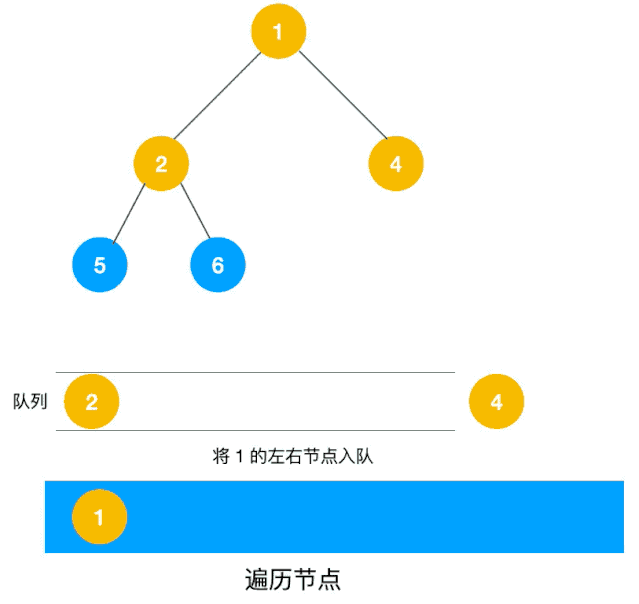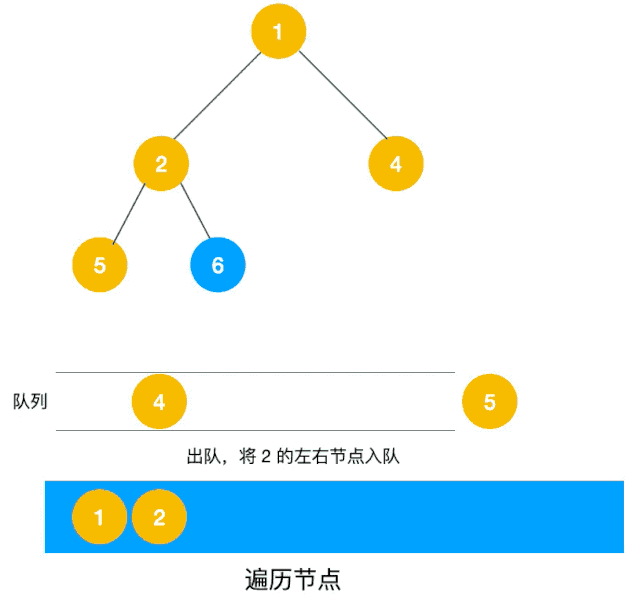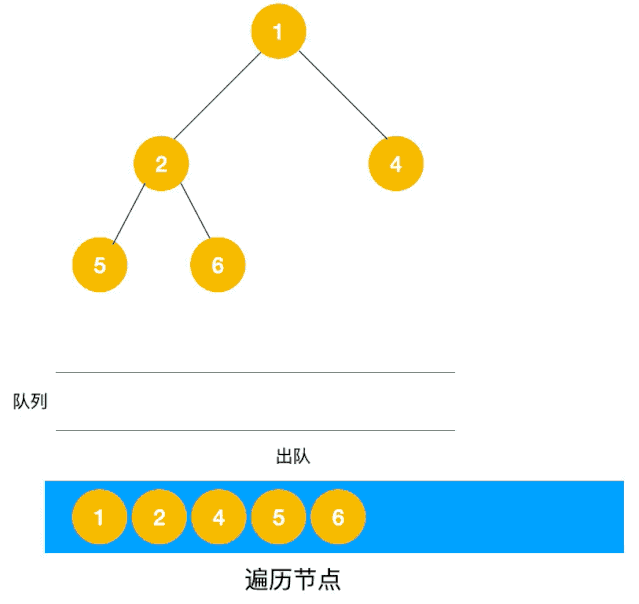
同样以以上图二叉树为例来看看如何用队列来实现广度优先遍历。
六、如何抓取网页?
回到开篇提到的搜索引擎,我们来继续看看网页抓取的大致思路。
如果是广度优先遍历:先依次爬取第一层的起始网页,再依次爬取每个网页里的超链接。
如果是深度优先遍历:先爬取起始网页 1,再爬取此网页里的链接,爬取完之后,再爬取起始网页 2。
实际上爬虫是深度优先与广度优先两种策略一起用的,比如在起始网页里,有些网页比较重要(权重较高),那就先对这个网页做深度优先遍历,遍历完之后再对其他(权重一样的)起始网页做广度优先遍历。
本文由 @CARRIE 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









这二叉树和栈、队列,立马让我想起了大学时候被C++和数据结构支配的恐惧。