
 起点课堂会员权益
起点课堂会员权益
如何设计一款百万日活的推荐系统(1)—大智慧RES从0到1实战
 B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等编辑导语:百万日活的推荐系统是很多人可望而不可求的,其系统的设计也并不简单,那么该如何设计这样一款推荐系统呢?本文作者基于自己的实际搭建经验,为我们分享了他的产品设计历程,希望能够帮助大家在系统搭建的过程中少走一些弯路。

前言
作者简介:本人3年金融行业产品经验,主攻python数据挖掘和机器学习。目前就职于上海大智慧,主要负责大数据平台、用户画像、推荐搜索、知识图谱等方向 。曾参与过ontrade数字金融交易所、区块链钱包、仙人掌股票证券投顾平台等多个项目。独自建立了datagrowth.cn数据驱动增长自媒体网站。
本系列专栏主要讲述本人从0到1搭建RES推荐系统的一些经验,记录下产品设计的心路历程,以此激励自己不断探索新知识。
与市面上泛泛而谈的博客不同的是,本文主要从产品的角度,结合行业特性,剖析踩过的坑。
一、产品架构
任何一款再简单的产品,都需要商业模式和产品架构的设计。架构不需要多么复杂、花哨,深入理解行业背景,适合产品规划才是最重要。
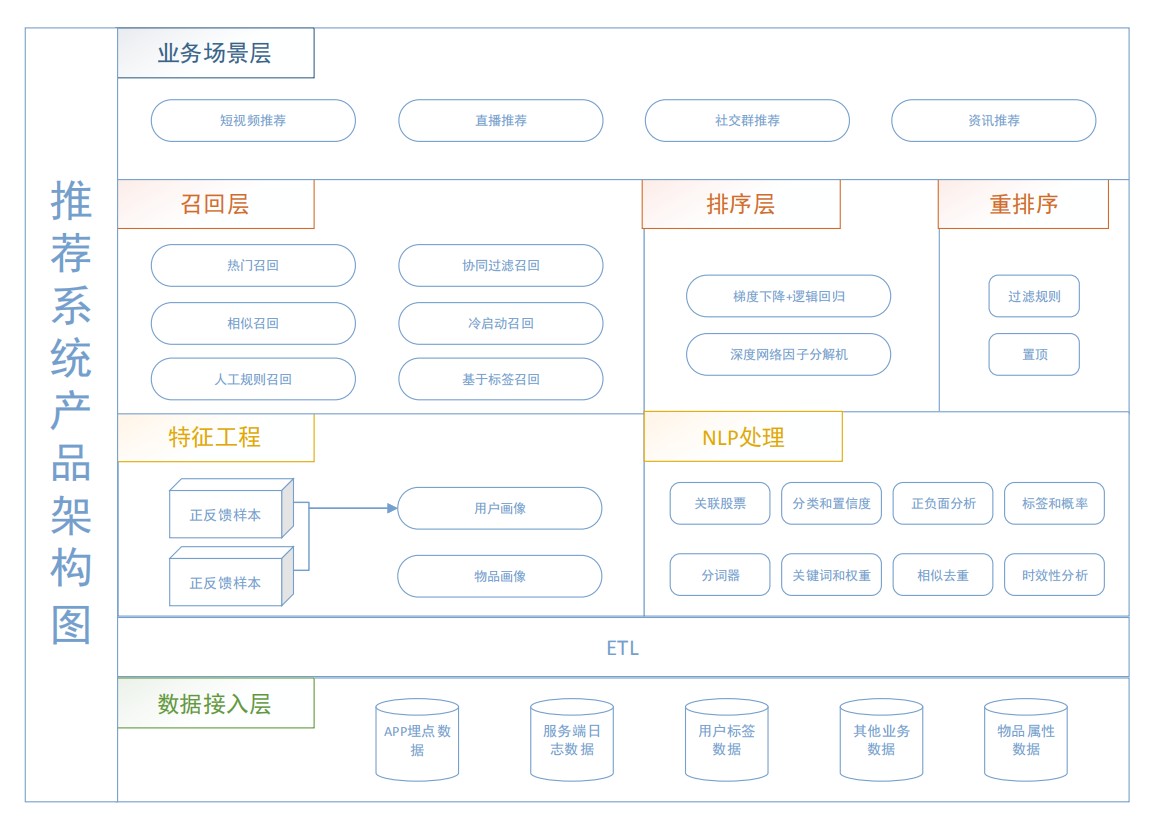
用visio画的一个比较满意的产品图,基本能把要表达的思路全部画了出来。
不同于前任设计的基于规则的1.0版本,这次重构主要在于搭建一个可扩展的体系,同时引入数据驱动、算法赋能,而不是拍脑袋决定。
从产品的角度看推荐,应属于业务应用层。
一切的一切,都是基于底层埋点到分析流程、大数据平台、用户标签画像、自然语言处理等基础服务搭建较为完善的前提下开展。
推荐的整体流程分为召回、过滤、排序(因为数据量不是非常大,所以不需要粗排、精排)、重排序,这次主要讲召回层最易理解但最重要的热门召回。
二、整体流程
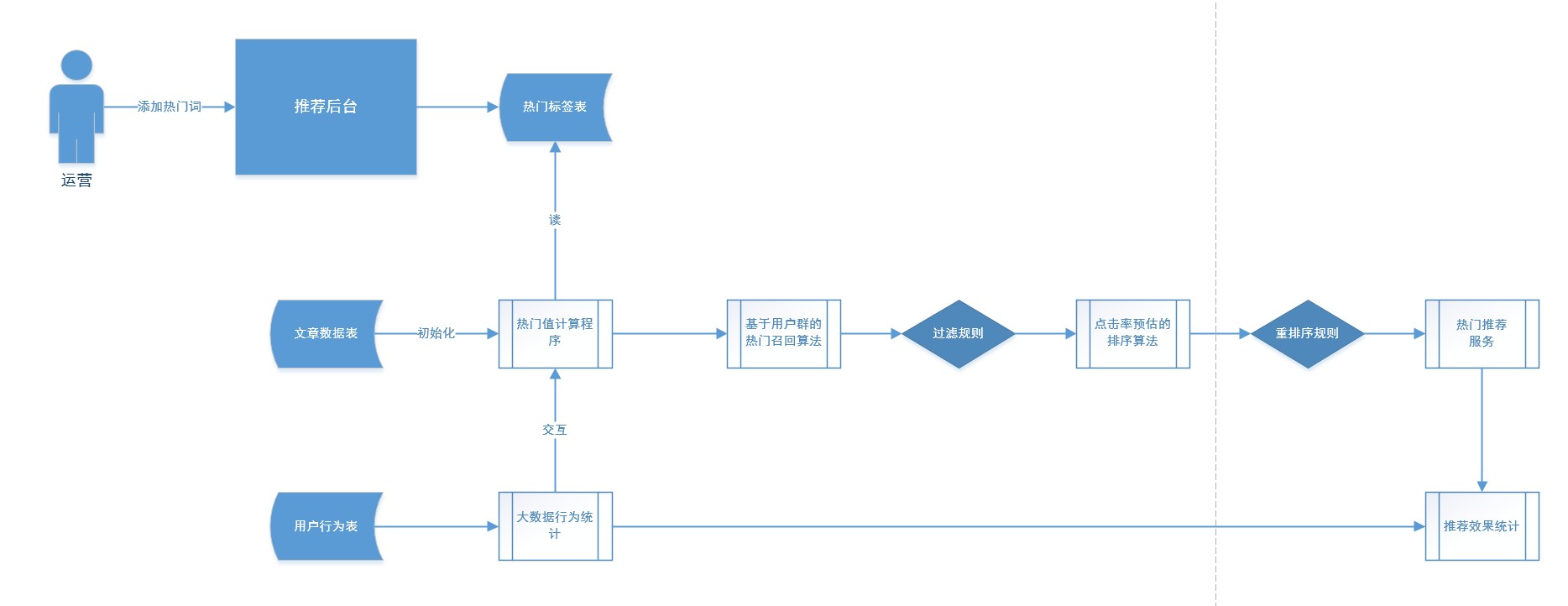
流程首先考虑闭环:从app用户行为产生、大数据实时统计,到产生热门召回、过滤、排序后,形成热门推荐服务;又通过用户行为来评估推荐效果【产品指标,如PV/UV、人均阅读时长、转化率等 】。
根据整体流程,发现核心在于热门值的计算方案。
新闻入到资讯的es库中,系统赋予一个初始热度值;进入推荐列表后,用户的点击、分享、点赞等交互行为可以提升新闻的热度值。由于新闻有较强的时效性,新闻发布后,热度非线性衰减。
资讯热度分=(初始热度值+用户交互产生热度值-低质量惩罚分(暂无))*时间衰减系数。
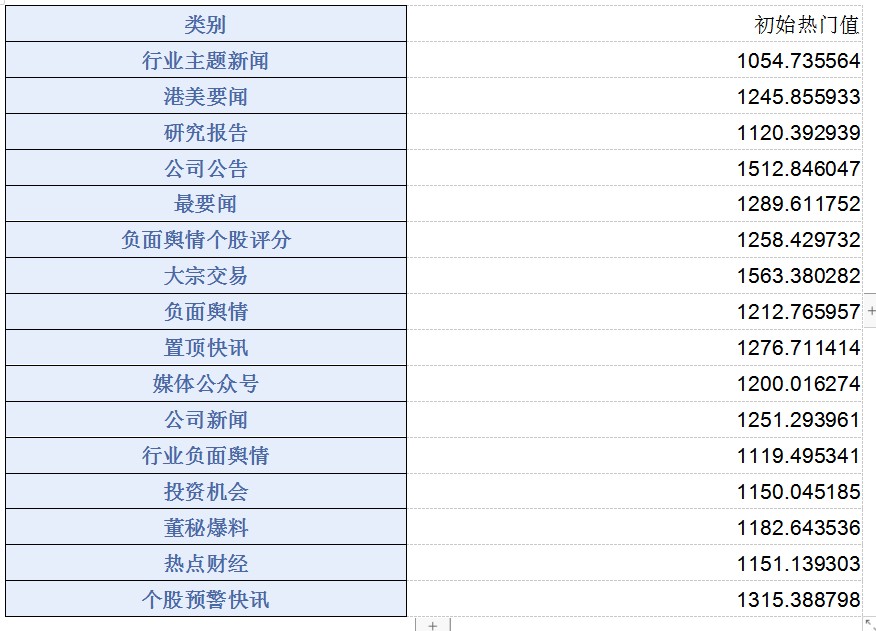
1. 初始热度值
1)不同类别的文章给与不同的权重
根据用户数据反馈,选择其中某些热门主题类型的文章,同时综合考虑高质量的类目,给与较高的权重。
类别初始热门值:
2)人工构建热门词库
新媒体运营的专家是最懂行业,最懂当前热点的了,引入人工规则,维护一张热门词库。

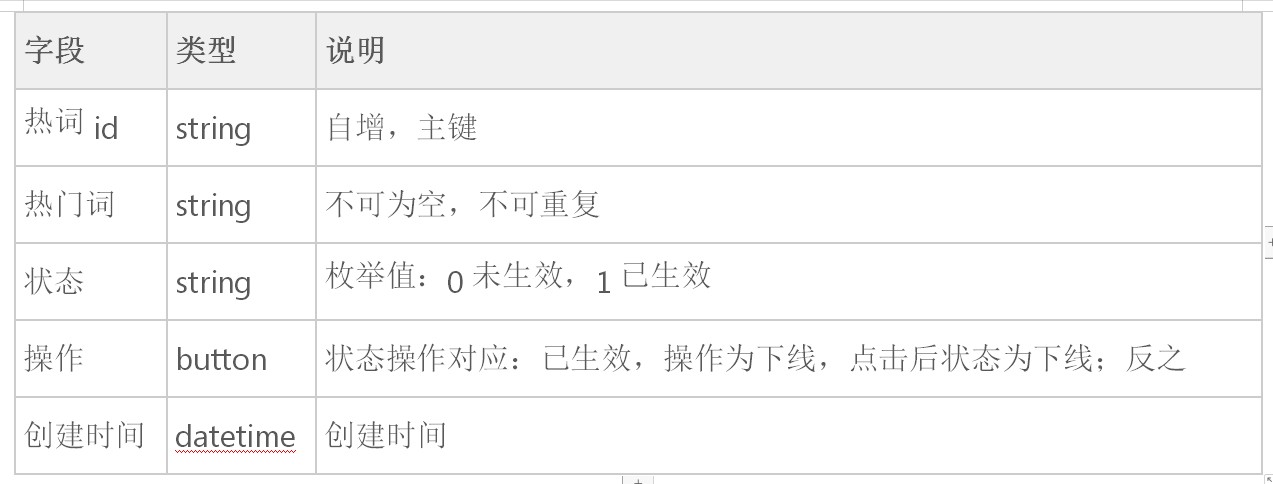
对文章进行提取关键字,进行匹配,根据匹配程度适当提升热门权重。提取关键字的算法也很简单,利用textrank,弥补tf-idf无法提取上下文关系的劣势,取共现词topN。
def get_keywords(self,conntent):
key_words1 = jieba.analyse.extract_tags(sentence=conntent,topK=50,withWeight=True,allowPOS=[‘n’,’v’,’f’])
key_words2 = jieba.analyse.textrank(sentence=conntent,topK=50,withWeight=True,allowPOS=[‘n’,’f’,’v’])
key_words1 = dict(key_words1)
key_words2 = dict(key_words2)
df1 = pd.DataFrame([key_words1]).T
df2 = pd.DataFrame([key_words2]).T
#取两者共现词作为关键字,取内连接
df = pd.merge(df1,df2,how=’inner’,left_index=True,right_index=True).head(10)
#取tf-idf算法的权重作为真实权重
df=df.drop(df.columns[1], axis = 1)
#重设索引
df.reset_index(inplace=True,drop=False)
df.columns=[‘feature’,’weight’]
print(df)
return df
作为关键词,当然前置工作有去除停用词,后置工作有同义词归并等等,所以NLP的底层基础能力很重要。
3)自动发现热词
若某一段时间,某一些文章的点击/搜素数量剧增,排除置顶等运营干预后,就应该考虑到可能出现了热门词。这种可以通过算法自动捕捉:算法思路也很简单,通过聚类,提取共性主题的关键字。
2. 交互热度值
取前M小时用户的不同行为赋予不同的分数,如【具体分值根据数据表现配置】:
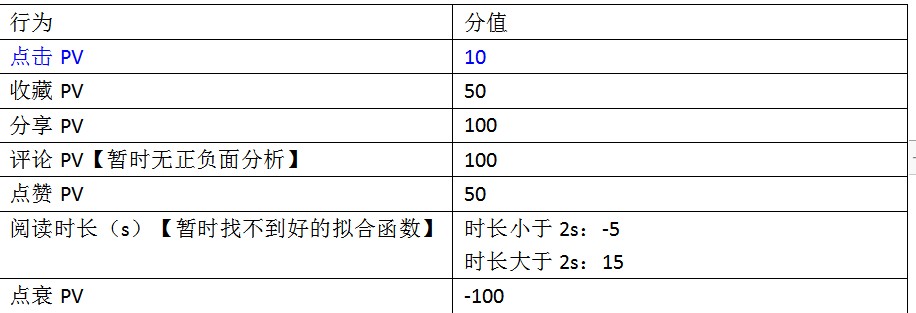
几个核心的点:
- 评论:无法单一的根据内容得出用户的偏好。需要对内容做正负面分析。
- 阅读时长:过短的阅读时长,可能是负面反馈。这里由于找不到好的拟合函数,就简单做了分段函数,正常来说应该是基于预估阅读时长做一个正态分布。
3. 时间衰减
采用经典的hacker news的排行算法:
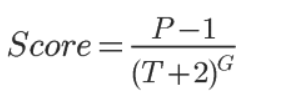
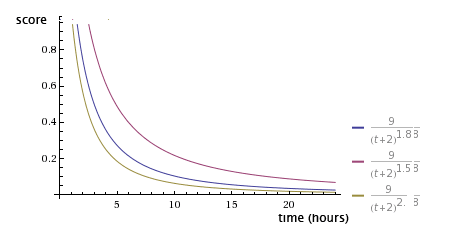
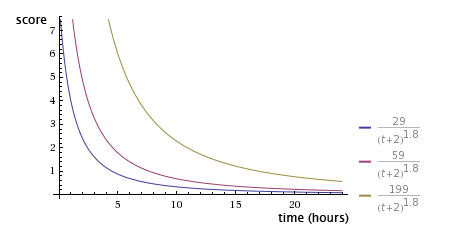
G重力衰减因子默认为1.8,值越大衰减越快:
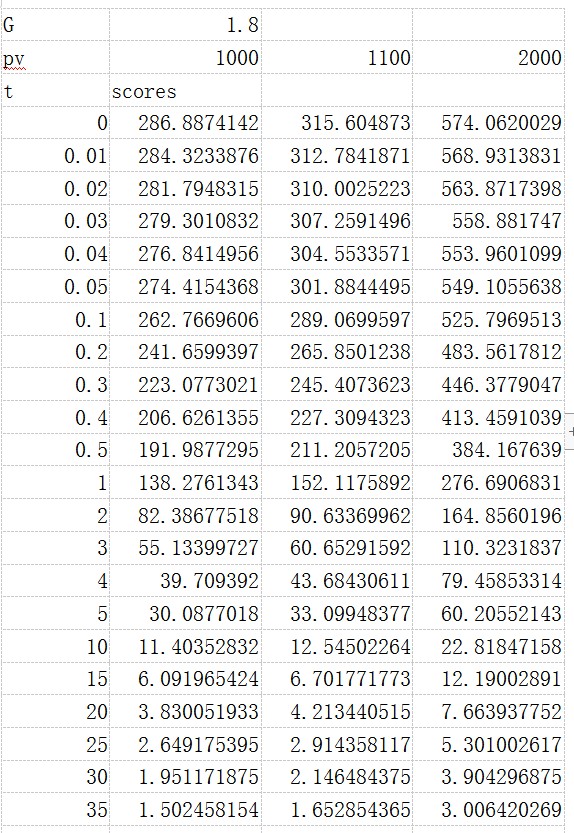
至于接下来的,LR+adam排序算法,将在后续章节介绍。
作者:数据增长创始人,datagrowth.cn数据驱动增长自媒体网站创始人。
本文由 @数据增长创始人 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Pexels,基于CC0协议









- 目前还没评论,等你发挥!









