
 起点课堂会员权益
起点课堂会员权益
评分模型性能不稳定?你需要知道这些
 产品经理的核心价值是能够准确发现和满足用户需求,把用户需求转化为产品功能,并协调资源推动落地,创造商业价值
产品经理的核心价值是能够准确发现和满足用户需求,把用户需求转化为产品功能,并协调资源推动落地,创造商业价值编辑导语:评分模型的性能稳定是很重要的,那什么样的模型才算表现稳定的模型呢?如何确信模型稳定性是否发生了变化?什么原因导致模型的性能不稳定?如果模型不稳定了该采取什么措施?带着这四个疑问,我们一起来看本文作者的解答。

对风控模型分类能力强弱的评估有一个前提条件,那就是风控模型的性能是稳定的,脱离了这个前提条件,分类能力再强的风控模型实用性也不高。
既然稳定性非常重要,那么什么样的模型才算表现稳定的模型?如何衡量模型的稳定性呢?影响模型稳定性的因素有哪些呢?如果模型不稳定了该采取什么措施呢?
本文带大家一探究竟!
一、什么样的模型才算表现稳定的模型?
模型稳定性高是指模型的预测能力在时间维度上是一致的,即模型在测试集、时间外样本集、线上测试和正式使用的时候有同样的区分度;而模型预测能力不稳定的直观表现是原本评分为500分的客户大概率是个好。
二、如何确信模型稳定性是否发生了变化?
实践中常用PSI指标衡量模型的稳定性,PSI指标是指群体稳定性指数(Population Stability Index),PSI反映了不同样本在各分数段的分布的稳定性。
PSI的计算公式如下:
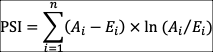
其中:A表示实际样本,E表示预期样本。
公式的意思是分别计算每一分箱内的实际样本占比减预期样本占比之差和实际样本占比除以预期样本占比的对数的乘积,然后将每个分箱内的这个乘积求和,这个求和值就是PSI。
下表表示PSI值的变动范围所代表的意义:
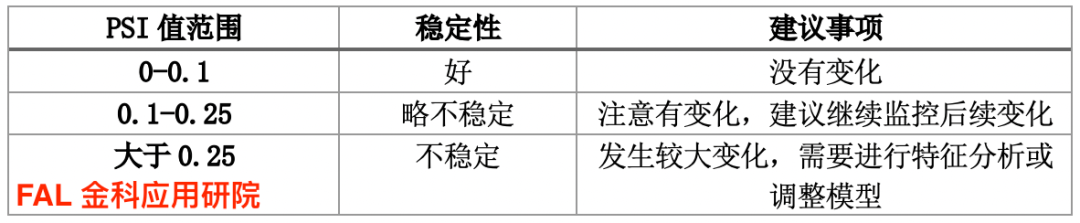
需要注意的是,PSI指标变化只反映两类群体变化大小,但不反映变化的方向。
下面以案例说明PSI的计算方式(数据不代表实际意义):
我们将评分卡开发时的样本和当前的样本进行比对,用同一个模型对两个样本打分后按照信用评分升序排序,并进行等宽分箱[1],即每个箱内(或分数区间)的信用评分差都相同;然后计算每个箱子内的实际样本[2]占全部实际样本的比例,并列入实际样本占比列。
预期样本[3]按照同样的模型预测信用评分后升序排序,并按照相同的分数区间计算每个分箱内的预期样本占全部实际样本的比例。
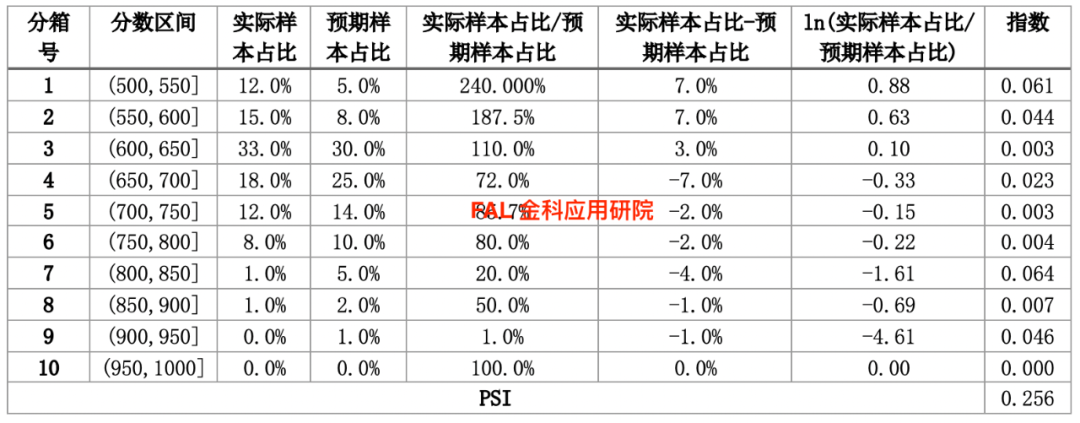
[1]在做模型排序能力表的时候用的是等频分箱,与这边的等宽分箱不同。
[2]这里的实际样本用的是模型开发时候训练集中坏样本的数据。
[3]这里的预期样本用的是当前坏样本的数据。
我们将预期样本占比列与实际样本占比列两列数据做对比柱状图(见下图):
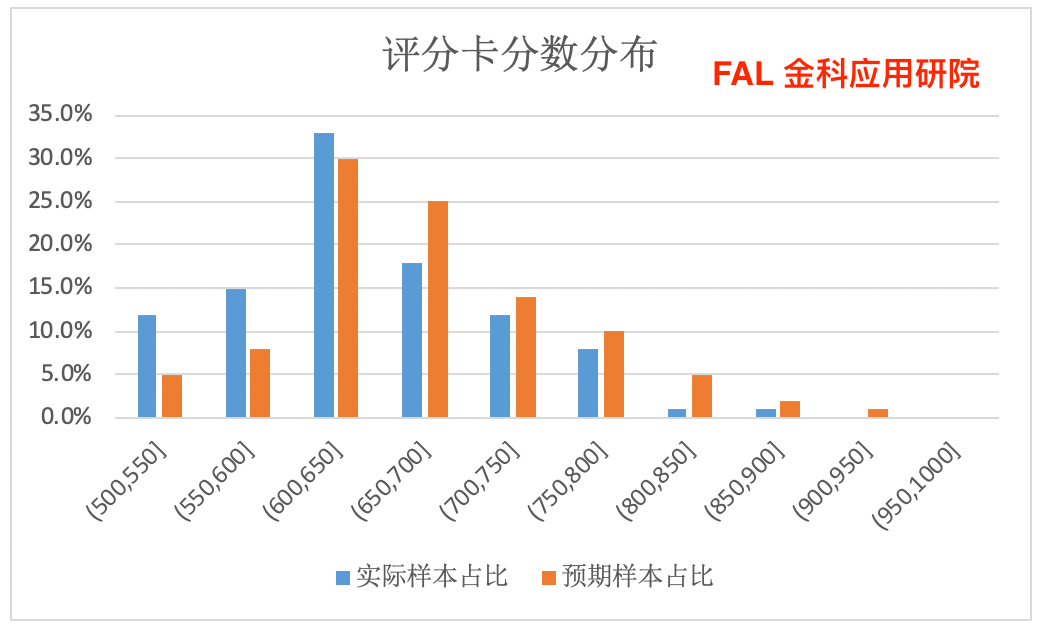
我们看到两个分布的PSI值达到0.256,超过了0.25,因此可以认为两个样本的分布发生了明显的变化,然后再观察发现预期样本评分的平均数大于实际样本评分的平均数,因此可以认为预期样本向高分段变动了。
三、什么原因导致模型的性能不稳定?
如果发现模型不稳定了,是什么原因导致模型的性能不稳定?
模型是一把尺,尺不会变长,也不会变短,那么导致衡量不准的原因只可能是客户变化的原因,具体讲就是好坏客户分布变化的原因。
我们以好坏样本评分分布图为例说明:
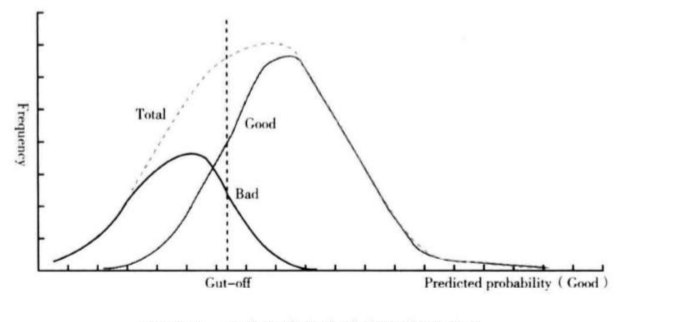
上图表示好坏客户在评分模型上的分布,可以看到好客户主要分布在高分区间,而坏客户主要分布在低分区间,两个分布交叉的地方表示模型无法有效区分的区域。
最好的模型是使得两类分布没有交叉,最坏的模型则是两类分布完全重合。中间垂直的虚线表示评分的阈值,高于阈值的为好客户,低于阈值的为坏客户。
因此,影响模型区分度的因素可以分为两个:
- 第一个是模型的排序能力,也就是模型是否能够将两类客户的分布尽可能的分开,使得交叉的部分足够小;
- 第二个是评分的阈值,也就是如何将两类样本分布的交叉区域进行划分。
假如客户群体发生了变化,那么变化的类型可以分为四类:
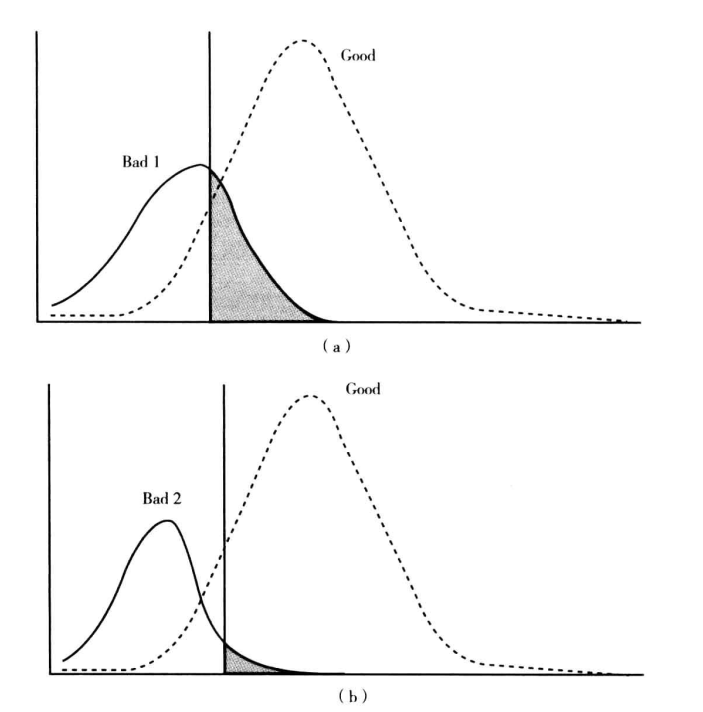
1. 坏客户的评分朝着高分段偏移而好客户的评分朝着低分段偏移(见上图a)
反映到实际的情况是全部客户的评分均值变小,且好客户和坏客户的评分均值之差也变小。
分析:这种变化是导致模型预测能力下降最常见和最主要的原因。因为坏客户和好客户分布的交叉区域变大,意味着模型的排序能力降低,从而导致模型的区分度下降。
发生这类变化的原因有可能是宏观经济恶化导致客户整体的还款能力下降,或者公司业务转型导致目标客户发生变化,或者公司业务团队在某段时间内集中某一类的客户过度营销,或者数据质量不稳定的原因。
2. 坏客户的评分朝着低分段偏移而好客户的评分朝着高分段偏移(见上图b)
反映到实际的情况是全部客户的评分均值变大,且好客户和坏客户的评分均值之差也变大。
分析:第二种变化的结果是改善型的,模型的区分度不仅没有下降,反而比以前更高了,实践中几乎不可能发生。
3. 坏客户和好客户的评分一起朝着高分段偏移
反映到实际的情况就是全部客户的评分均值变大,但好客户和坏客户的平分均值之差不变。
分析:这种变化相当于评分阈值的被动下调,从而导致提高了违约率,提升了通过率,但是模型的排序能力变化不大。
4. 坏客户和好客户的评分同时朝着低分段偏移
反映到实际的情况就是全部客户的评分均值变小,但好客户和坏客户的平均均值之差不变。
分析:这种变化相当于评分阈值的上调,从而降低了通过率和违约率,但是模型的排序能力变化不大。
四、如果模型不稳定了该采取什么措施?
对于第二种变化,我们无需做任何调整。对于第三和第四种变化,我们只需要相应调整评分阈值。但是对于第一种变化,调整评分阈值无能为力,因为这是模型排序能力变化导致的。
是不是遇到第一类情况就一定要更换模型了呢?有没有其他的应对措施呢?
首先我们得分析导致客户分布发生变化的原因:
1. 第一类是从时间切片的角度统计分类客户的PSI
例如我们通过计算每个月末的分类客户PSI值,发现某一类客户的PSI值连续发生较大变化,我们可以单独分析该类客户PSI变化的原因。
如果是该类客户所在的行业变动,地区性灾难(地震、洪水、疫情)等短期内不可逆的因素,建议将类似客户拒绝进件。若是公司营销部门针对某一类客户过度营销,建议与业务团队沟通优化业务方向。
2. 第二种是从特征角度考虑
即整体客群整体好坏比不变的情况下客群结构发生变化,此时可以考虑重新调整个别特征的分箱。
如果在客群变化的情况下,特征的每个分箱的好坏比与模型开发时候的好坏比变化了,那么每个分箱WOE也就发生变化,从而影响模型的排序能力。
因此如果能够将特征的分箱重新调整,使得新的分箱内的坏好比恢复到和模型开发时候一样,那就恢复了模型的排序能力。
举个例子:假如模型上线6个月后,我们观察到收入特征有如下变化(这里收入分箱是在模型开发阶段根据最优分箱的方法进行分箱的结果,过去坏好比是指模型开发阶段时训练集按照最优分箱后的坏好比。当前坏好比,是将模型上线6个月后的样本按照上述最优分箱进行分箱后求得的坏好比):
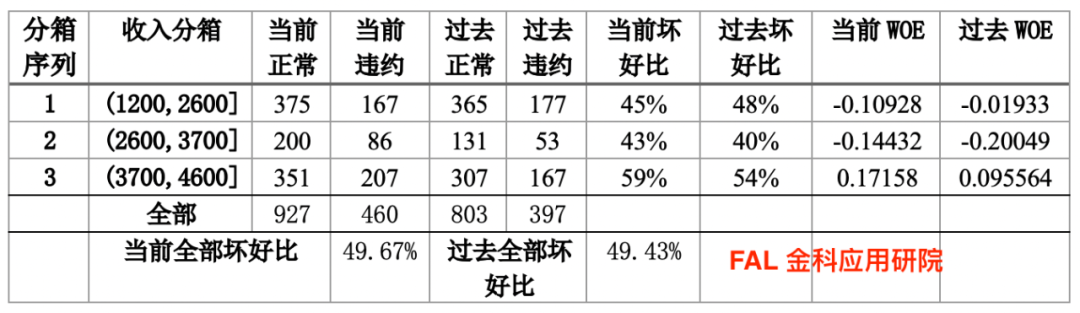
从上表可以看到,当前全部客户的坏好比与评分卡开发的时候全部客户坏好比相差不大(这是必须要满足的前提),但是当前坏好比在每个收入分段与过去坏好比有明显的差异。
例如:在高收入区间内,当前违坏好比比过去坏好比高,而在低收入区间内,当前坏好比比过去坏好比低,这反映了坏客户在收入维度的偏移,进而导致模型的区分度下降。
因此原本的分箱已经不适用于当前的情况,我们需要调整分箱,使得调整后新的分箱的每个收入分段内的当前坏好比与过去坏好比一样。
值得注意的是:采用这办法需要满足当前全部客户的好坏比和过去全部客户的好坏比保持一致的条件,如果信贷环境和客群质量发生不稳定的情况,使得条件无法满足,这种方法就无法使用,只能重新开发评分卡。
五、总结
PSI本身不是直接衡量模型稳定性的指标,而是通过衡量客群分布变化,间接反映模型预测能力稳定性指标。
PSI指标传递的信息有限,仅能够反映客户分布是否发生了变化以及变化的程度,但不能反映变化的方向以及变化原因,因此要我们需要结合业务实际分析PSI值变化背后的深层次原因,并采取针对性的措施化解负面影响。
以上,是我对模型稳定性及反应指标PSI的理解,期待与大家交流讨论!
本文由 @FAL金科应用研院 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 unsplash,基于 CC0 协议







- 目前还没评论,等你发挥!









