
 起点课堂会员权益
起点课堂会员权益搭建标签体系,学会让用户为你干活
编辑导读:用户标签是精细化运营的基础,能有效提高流量的分发效率和转化效率。用户由标签组成,但是这些标签打那些纬度标签?由谁来打?怎么打标签?本文作者对此展开了分析探讨,一起来看看~

标签,主要的作用就是用于商品识别,用来标志产品目标、分类、内容等。标签按照存在形式分,可分实物标签、网络标签(tag)等。
(1)实物标签
主要用于标明物品的品名、重量、体积、用途等信息的简要标牌。有传统的印刷标签和现代条码打印标签。
适用范围:包装:唛头标签、邮政包裹;商品:价格标签、产品说明标签;
(2)网络标签(tag)
它是一种互联网内容组织方式,是相关性很强的关键字,帮助人们轻松的描述和分类内容,以便于检索和分享,Tag已经成为自web 2.0以来的重要元素。
今天我们就来聊聊网络标签,let’s go
背景
假设一个场景:老板把你叫到办公室,让你做一套标签体系,你会怎样推进?
常规思路:调研市场上同类型产品做法→通过各种渠道,拿到标签体系结构(或者利用爬虫爬取标签体系数据)→直接套用过来→人工达标、模型训练→形成自有标签体系
这是一种快速便捷的方案,但是埋了很多隐性的“坑”,稍不留神就会被坑。
- 不同平台内容体量有差异,内容调性与用户调性亦有差异,完全照搬内容标签体系,弊大于利。
- 标签体系不完善,不适合自有内容生态,就花费大量人力、物力来做,劳民伤财。
怎样躲“坑”?那得学会灵活运用他人的体系
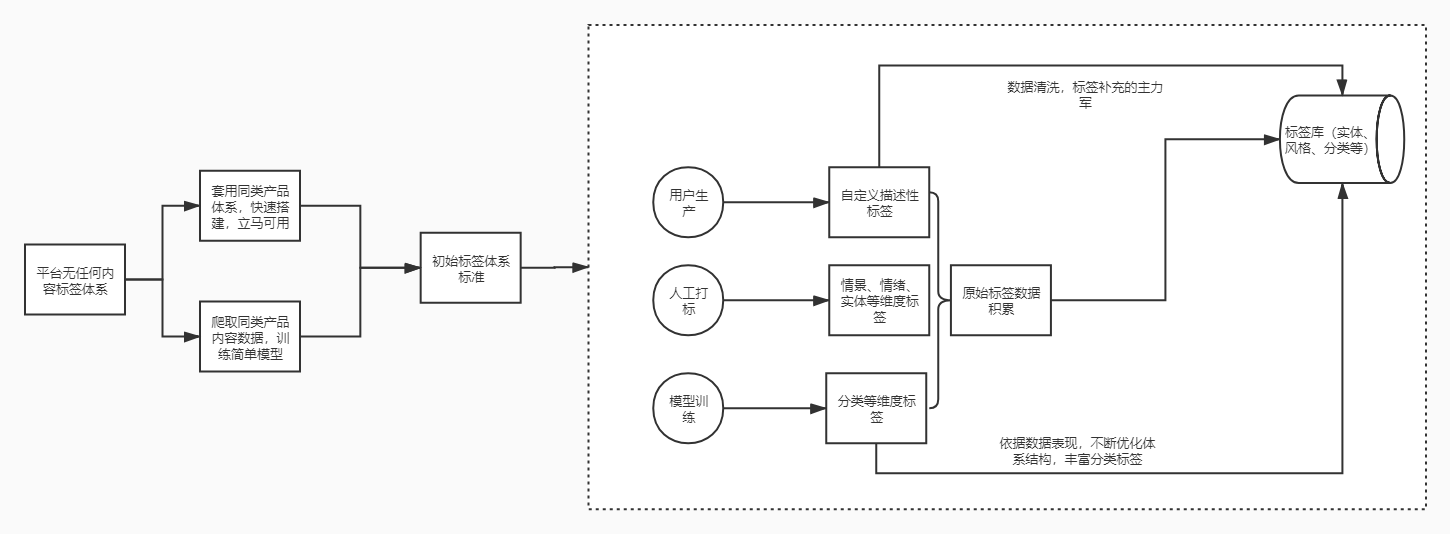
当拿到搭建标签体系的任务,首先想到有两个方案
方案一:调研同类型产品做法,直接套用其分类标签体系
优点:简单、高效
缺点:不完全适合自有内容生态
方案二:爬取同类产品内容数据,进行无监督训练,输出分类标签结果。
优点:可以更好的了解内容生态中内容分布情况,制定合理的分类标签体系。
缺点:时间周期长,成本高
不管方案一还是方案二,得到的都只是初版标签体系标准(比如一二级分类体系标准),只能用做建立底层分类标签,离标签体系建立还有一段露要走。
当有了底层分类标签,可以在此基础上进行多维度标签建构:
- 情感化标签
- 风格标签
- 实体标签
- 概念标签
……
多维度标签有了,怎样让内容打上这些标签?
1. 充分调用用户生产力,让作者打标
我们都知道,豆瓣将打标的权利下放给用户,在上传文章、写电影评论都可选择或手填标签,对于内容平台来说,这是一笔巨型财富。但是由于用户能力水平有高有低,打出的标签需要进行清洗、消歧等操作后才能使用。
一些资讯平台、视频平台,作者发布文章时,也会让作者选择、填写内容标签,比如趣头条、B站等。
B站发文页面
问题点:用户手动填写的标签没有统一标准,标签名称不规范,无法直接使用。笔者拉出所在公司作者手填tag,利用率也就50%-60%左右,需要人工进行标签分类,比如筛选出实体标签、概念标签、风格标签等。
2. 人工打标
作者手动填写tag,只能作为tag体系补充的一环,且利用率有限。因此,专门的标注同学、真实用户打标,是必不可少的一环,更好的保证标签可用率与准确率。
调动用户生产力,让真实用户打标签,不知大家有没有用过。把打标伪装成用户活动,既是用户运营的手段,也是标签生产的手段,利用用户运营的思路来生产标签,好处多多。
我们来算笔账——
假设日活用户1000万,圈出100万用户做活动,预计每日参与活动用户20w,真正完成答题用户7w-8w,剔除无效数据,最终可用数据可以有10w左右,平均成本可灵活调控。
如果找专人一天标注10w数据,按照人效1500来算(上限值),那么就需要66个人,人力成本一天也得大几万。
对比来看,调动用户生产力,优势不言而喻。
第一步:洞察用户
- 人口学特征:性别、年龄、职业等
- 地理位置特征:所在城市,城市等级
- 活跃行为特征:最近60天、30天、14天、7天等活跃天数
- 阅读行为特征:最近60天、30天安、14天、7天等阅读视频、图文次数、时长。
通过这些不同维度的用户数据,让你对用户做个深度剖析,找到你需要的那部分用户。
第二步:吸引用户
将打标签的项目伪装成用户活动,比如要进行影视剧剧名打标,可以开展一个“看视频猜剧名”的活动。比如要进行相似图片标注 ,可以开展一个“看图片找不同”的活动。
怎样做好伪装,吸引用户参与?
- 活动名称接地气,要点突出,直接要害
- 设计有看点的活动banner
- 做好答题页面交互体验设计
- 充分利用金币、奖金竞品激励
第三步:服务用户
当把用户吸引进来之后,需要为它们做好服务,提升活跃留存。
- 定期监测参与活动用户质量,剔除羊毛党、质量低用户。
- 制定奖惩机制
- 收集用户反馈,对于有用建议及时响应。
- 由于项目具有周期性,做好用户召回(利用psuh、站内信等手段触达召回)
再多说一句,当把这套流程机制中台化,可以满足不同业务场景需求,对于用户促活、标签打标等具有很强的实操价值。
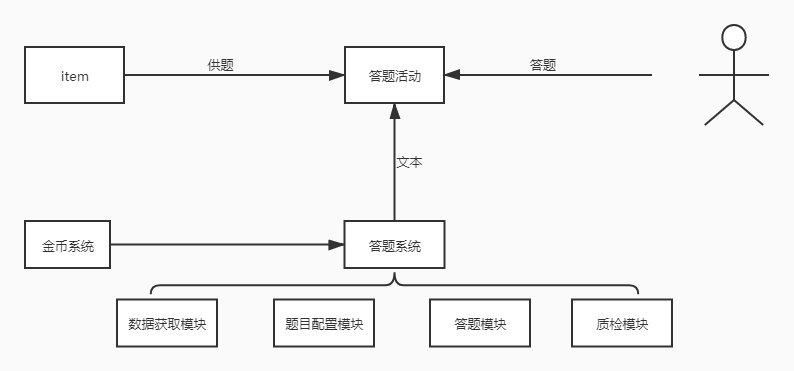
3. 模型训练
常规的模型训练流程很简单,大致分为五个环节:
标准制定→样本标注→模型训练→数据评测→上线
随着业务需求增加,对于模型迭代效率要求越来越高,普通的模型训练流程太繁琐,需要跨部门沟通,费时费力,因此,搭建一套模型训练自动化平台显得尤为重要,对于简单的模型,可以由运营或者产品协调标注,快速训练、迭代模型,提升效率。
这里简单聊聊模型自动化训练平台的搭建,或有不足之处,大家一起交流学习。
平台工具可分四大模块:数据处理、模型训练、数据集打分、模型对比
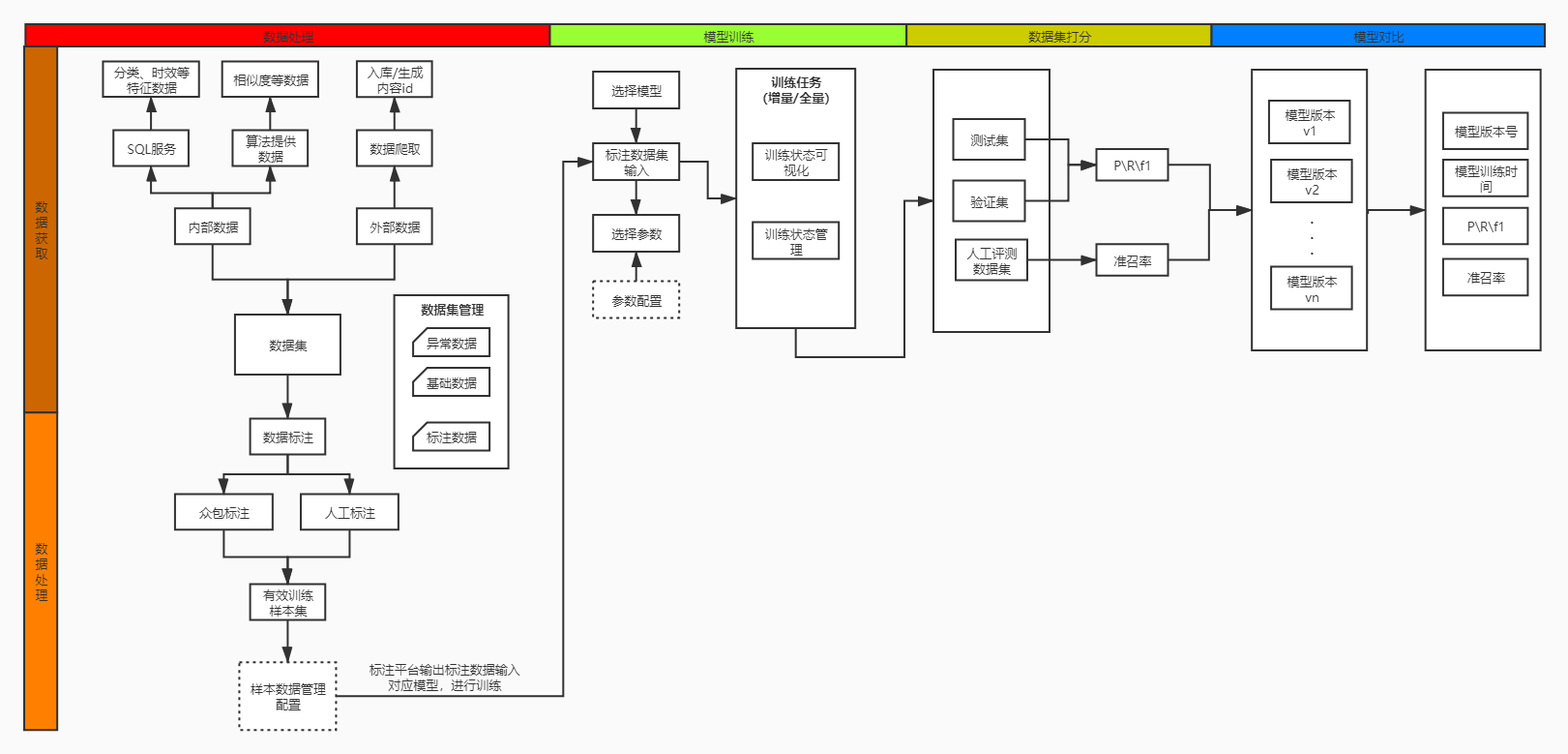
模块一:数据处理(整合数据获取、数据处理两个小模块)
(1)数据获取
1)内部获取
- 来自内部,整合已有工具,平台加上工具跳转入口;利用sql自行获取想要样本标注数据。
- 来自内部,算法侧提供相应样本标注数据
2)外部获取
根据具体需求,制定内容爬取方案,瞭望爬取相应内容(图文、视频、小视频等全体裁),需要入库,支持输入标注平台、众包进行数据标注。
(2)数据处理
- 针对内外部获取的数据集,支持输入标注平台、众包进行标注,输出有效标注样本数据集
- 针对众包、标注平台输出的有效标注样本数据集,需要有个样本管理配置平台,进行数据处理,然后将数据直接推送至对应模型进行训练。
模块二:模型训练
- 算法提供每个需求所需模型
- 选定所需模型,输入有效标注数据集进行训练
- 支持配置选择模型参数,比如,基于神经网络模型,一般可以迭代训练轮数、学习率、网络层数、向量宽度、选择的优化器等。
- 支持增量与全量任务训练,训练状态可视化,便于及时掌握训练情况
- 建立监控报警机制,训练状态异常时触发,保证训练状态正常。
模块三:数据集打分
- 已经训练完毕的模型,输入测试集、验证集数据,输出P\R\F1值
- 输出P\R\F1值后,再次输入人工评测数据集,输出评测数据结果,人工离线评测,输出准召率。
模块四:模型对比
对于准召率达标不同版本模型进行留档记录,便于对比迭代前后模型效果
- 对比维度:模型版本号、训练完成时间、P\R\F1值、人工评测准召率等
通过作者打标、用户打标、模型训练等方式,输出了各个维度内容标签,存储于标签库中,为各业务场景提供底层数据支持。
本文由 @珂然 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!








