
 起点课堂会员权益
起点课堂会员权益
说说智能推荐的那些事儿
 B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..
B端产品需要更多地依赖销售团队和渠道合作来推广产品,而C端产品需要更多地利用网络营销和口碑传播来推广产品..编辑导语:有人认为,智能推荐是一个伟大创造,是信息时代必不可少的工具。与此同时,有人急切的想要拒绝智能推荐,认为这种追踪是对个人隐私的侵犯,也有人认为智能推荐会使我们获取的信息越来越狭窄、越来越片面从而走进信息茧房。今天这篇文章中,作者就来为我们说说智能推荐的那些事儿。

一、智能推荐的重要性
智能推荐是非常重要的数据产品,是比较早期的实现了智能化、自动化的的数据产品。在现在的科技发展中,客服智能化了么?没有~优惠券?定价?都还没有智能化,只有分发实现了智能化。
字节跳动做智能推荐很厉害,对公司的业务产生了巨大的变革,所以今天我们把智能推荐这个事情来讲讲清楚,让大家明白明白。
二、智能推荐的背景
用户越来越多,商品越来越多,那么用户想要找到想要找到的商品也越来越困难,让某个或某些产品在众多产品中脱颖而出也是特别特别的困难,简单的来讲就是供需匹配,两者无法匹配的上,所以怎么办呢?如何解决这个问题呢?
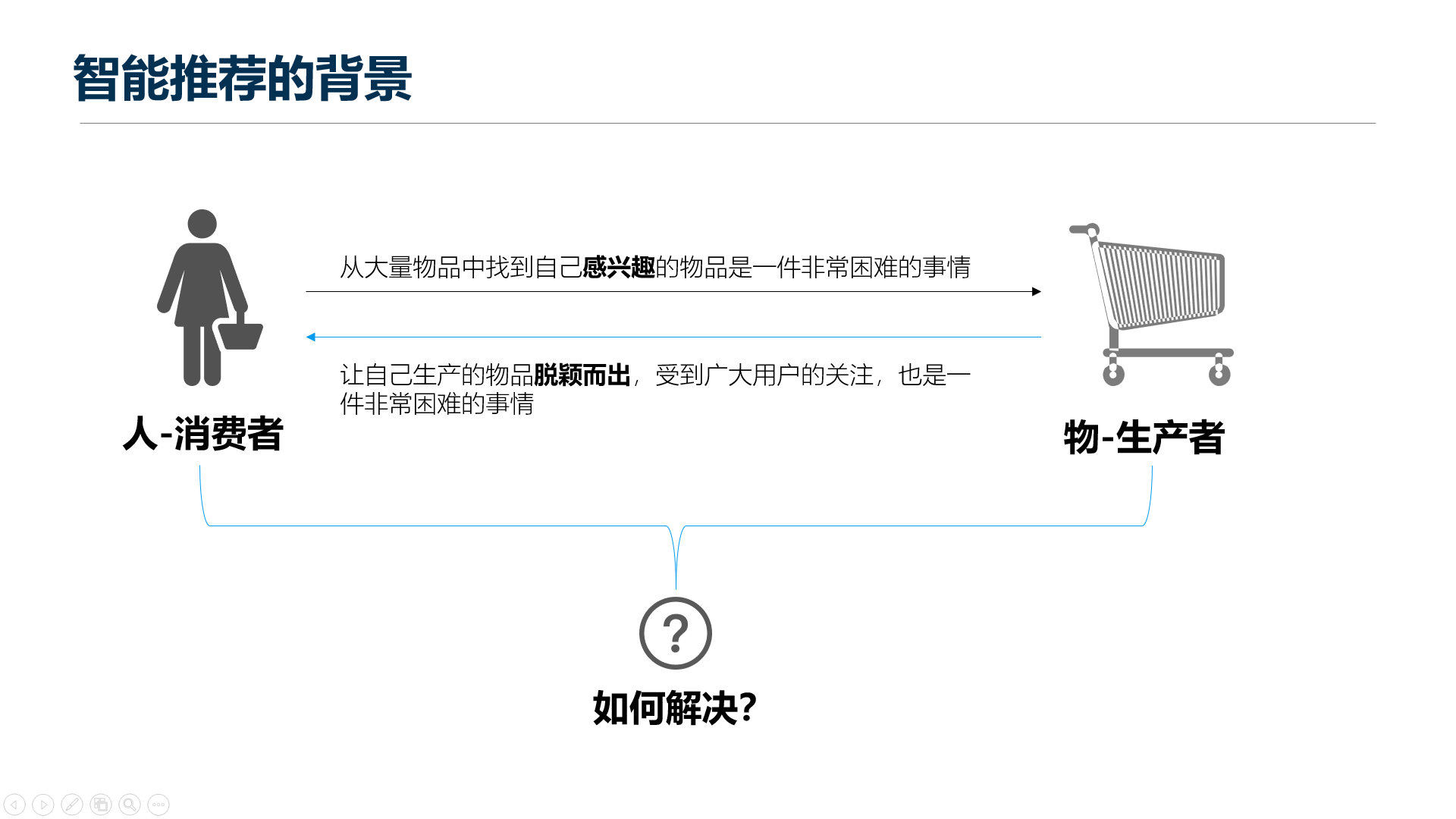
三、各类方案解决的优劣
所以当前有这么几种解决方案,分别是搜索引擎、分类目录和智能推荐,接下来我们就简单介绍一下这三种解决方案的优劣势。
1. 搜索引擎
需要用户主动去搜索,这个是百度干的事儿,但是这个时候是需要用户的目的性很强才行,要知道自己想要什么,但是很多时候我们并不知道我们想要什么东西,我也不想去绞尽脑汁去想我要什么,只想放松,那搜索可以做到么?做不到,可能搜索出来的东西并不是可以满足我们的东西~
2. 分类目录
在这个里面,我们要知道我们想要的东西属于哪一种属性,知道了之后才能去找,如果分类属性选择错了,那就在当下这个错的目录里面永远也找不到我想要的东西。而且一旦我不清楚我自己想要什么的时候,面对纷繁复杂的分类目录,更是无从下手~
3. 智能推荐
而智能推荐呢?我不需要用户提供明确的需求,我只需要根据用户的历史行为去建模,然后根据他们的历史行为判断接下来的行为和喜好,去给用户做相对应的内容、产品推荐。所以当用户没有明确的目的的时候,也可以帮助用户发现新内容。
四、智能推荐的机制
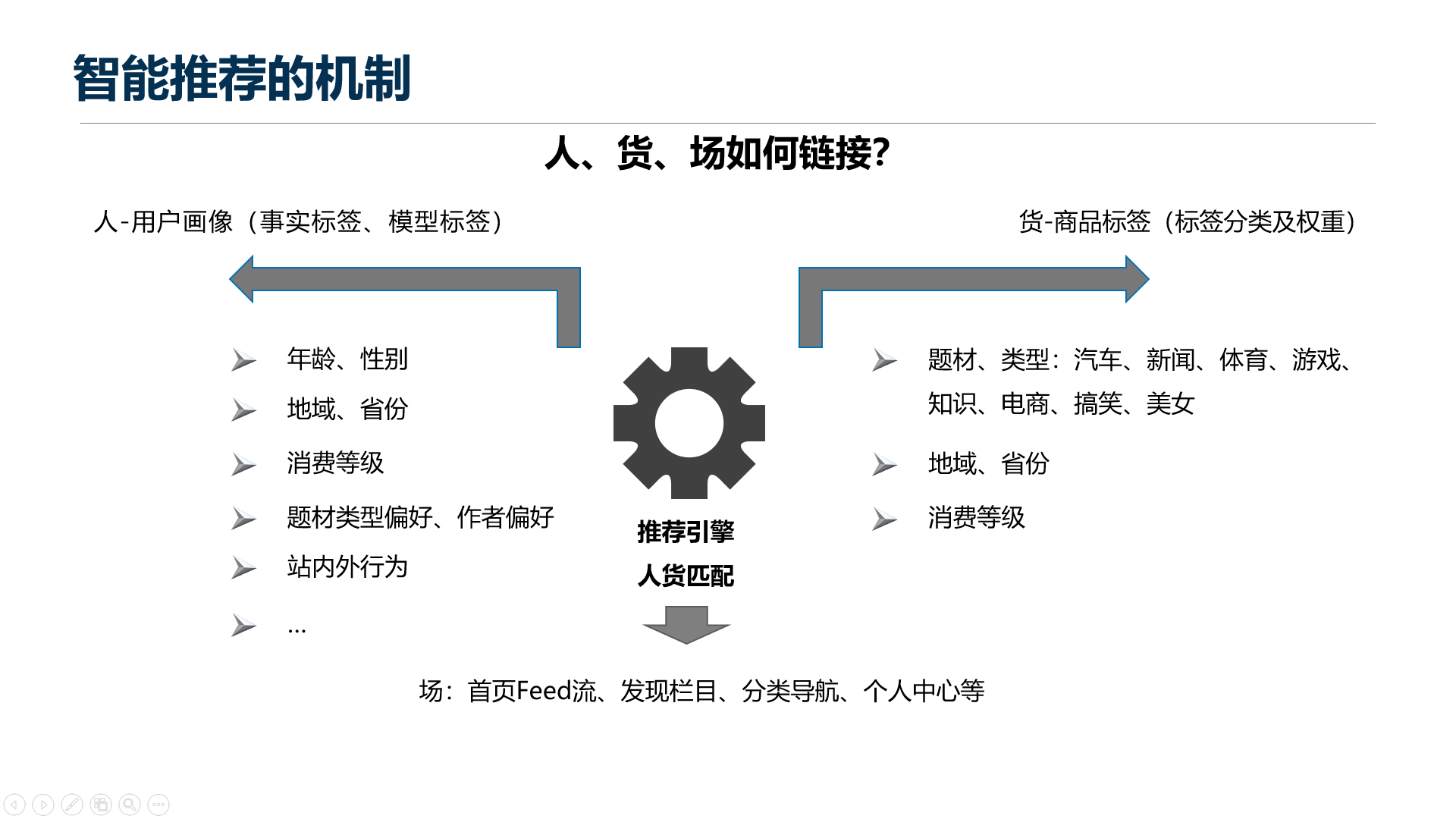
1. 人
建立用户画像,给用户打上事实标签和模型标签,什么是事实标签?就拿虚拟人物“小明”举个例子吧!小明经常在某购物平台上购物,并已完善自己的个人信息,那么平台就会把该信息收集,作为事实标签。
- 姓名:小明
- 性别:男
- 身高:180cm
- 体重:70kg
- 爱好:看电影
- 职位:产品经理
- 目前所在地:上海
- 消费等级:极高(根据日常消费习惯判断)
- 常看类型产品:高科技产品、数码产品、大牌运动鞋
那什么是模型标签呢?就是系统可能会把一类人划分为一个模型,他们的事实标签可能会比较相似,这就是一个模型标签。
我接着拿玉康举例子:比如说系统给他们这一类人建的模型标签名称是“大款”,那可能别的某个大款看上了一个布加迪,加购并付款了,虽然孙玉康没有看这个产品,但是可能布加迪及相关产品也会出现在孙玉康的推荐列表中。
2. 货(内容)
给内容或产品打上标签,比如一个运动上衣,可能会有夹克、运动、长袖、外套等等各种各样符合这个产品的标签,并记录这个产品的售卖数量,收藏、加购的数量等。
然后通过人货模型,就可以知道,比如说:年轻的女孩子,喜欢口红,包包、购物、逛街;年轻的男孩子,喜欢女孩子,喜欢手机、手表、汽车,然后怎么匹配呢?
3. 场
就是在对应的场里做匹配,比如说首页、Feed流、导航栏、个人中心等等,在你想要的场景匹配上你所需要的数据。
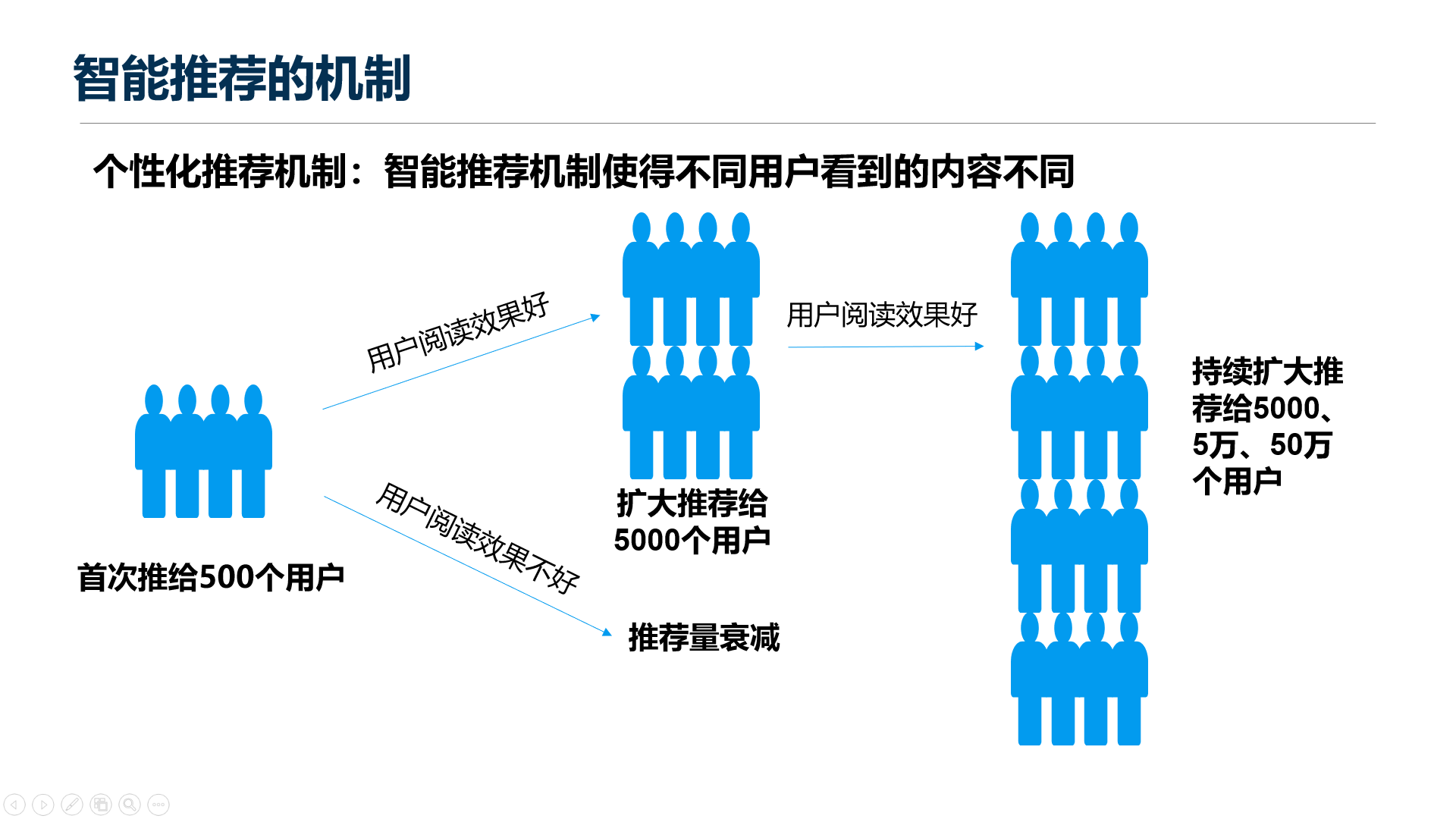
然后我可能有了这个标签的推荐方法,我把一个东西推给一部分人,然后这部分人很喜欢这个东西,那我就可以把这个东西推给更多类似的用户了,然后不停不停的去扩展流量,我就知道每个用户喜欢什么东西了。
五、智能推荐系统的框架
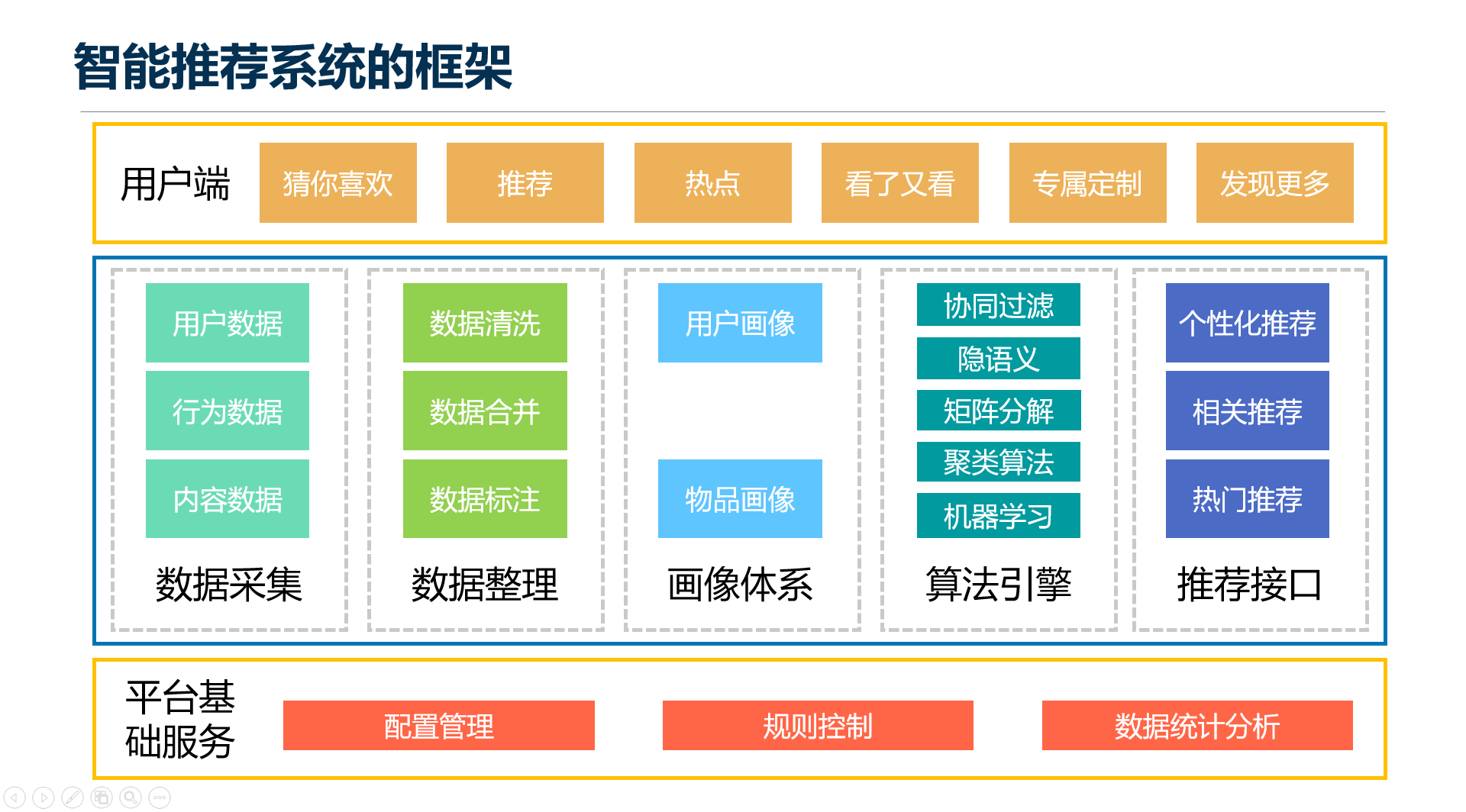
1. 数据采集
怎么去采集啊?要去做埋点,要去记录用户的数据。
比如说一个用户打开了我们的某小程序,他注册的信息是什么?他是几点打开的,几点关闭的小程序,查看了哪些页面,浏览了哪些产品,每个页面的停留时间是多久,用的4G还是5G还是WIFI啊,在哪儿?
这时候用户数据和行为数据都知道了,那什么是内容数据呢?比如说抖音,亿万的人在抖音产生了千亿条抖音短视频,这些都是内容数据。
2. 数据整理
采集到数据之后,就要把数据做标注,数据标注的类型有:图片标注、语音标注、文本标注、视频标注、道路标注、行人标注、人脸106点、图像语义分割等。
然后有些数据是重复的,需要做合并,有些事无意义的数据,影响后面的数据整理,那就做数据清洗,把它干掉等等
3. 画像体系
有了这些数据,我们就可以生成画像了,就知道是什么了。
画像有人物画像,也有商品画像;我们继续来说小明,比如说:小明,26岁,性别男,爱好看电影,喜欢吃小龙虾,商品画像其实就是描述这个商品的内容的东西。
4. 算法引擎
- 协同过滤:比如说小明喜欢《数据挖掘导论》,小红喜欢《三个火枪手》,基于 UserCF(用户协同过滤),找到与他们偏好相似的用户,将相似用户偏好的书籍推荐给他们;还可以基于ItemCF(物品协同过滤),找到与他们当前偏好书籍相似的其他书籍,推荐给他们。
- 隐语义模型:根据用户的当前偏好信息,得到用户的兴趣偏好,将该类兴趣对应的物品推荐给当前用户。比如,小明喜欢的《数据挖掘导论》属于计算机类的书籍,那我们可以将其他的计算机类书籍推荐给他;小红喜欢的是文学类数据,可将《巴黎圣母院》等这类文字作品推荐给她,这就是隐语义模型。
此外还有聚类模型等。
5. 推荐接口
由于有这些底层的数据及算法,那就可以根据这些数据通过接口,在某些场景去给他们做分发,我们继续来说小明,不仅喜欢吃老乡鸡,还喜欢打网球,弹琴,琴棋书画样样精通啊。孙总打开手机的时候,我就可以在他的用户端的各个模块下给他推荐他喜欢的东西了。
6. 底层规则控制及配置
比如说我知道孙总喜欢吃老乡鸡,可是我已经给他推送了3天了,第四天我再给他推送,估计他就吐了,那我给他推送一波小厨娘,名称就很符合孙总的审美,他是不是就很大概率会买呀,这个就是一些规则的控制与配置,最后通过重新得到的数据去统计分析。
7. 数据采集及画像构建
有些数据用户会手动填写,有些我们需要根据用户的行为去分析、推测,还有一些 需要我们去埋点获取。
8. 根据数据,构建用户画像
根据各个标签,我们可以知道这个人的用户画像。然后根据这个人是谁,我们就可以去查找他对应的信息有哪些,我们就可以根据用户画像中的信息去推送他喜欢的东西。
9. 算法的工作机制
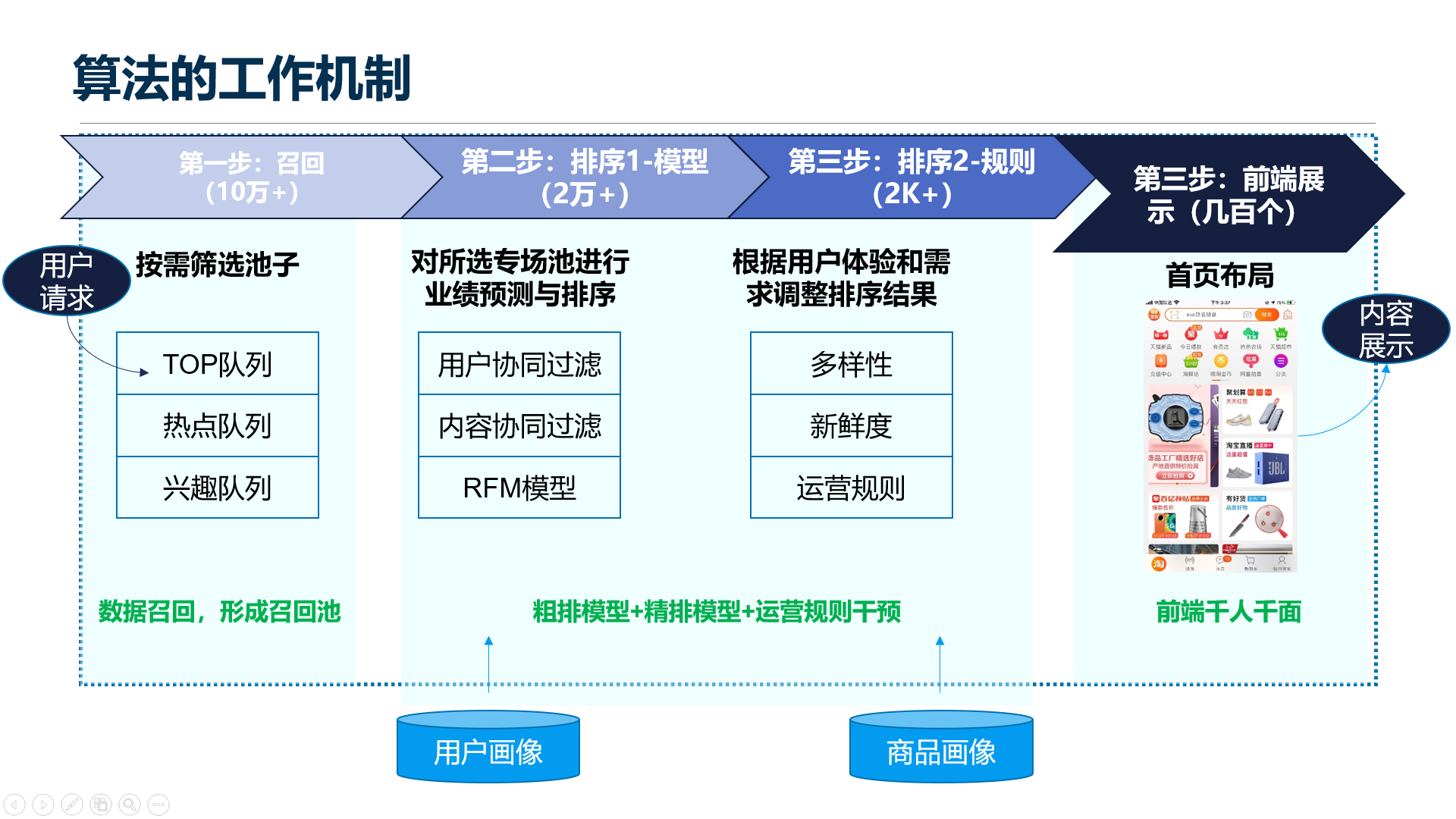
我们把用户画像和商品画像丢到了算法池子里,过来一个一个用户请求后,我们会先调用用户画像,让我看看你是谁?
然后我会再看看我有哪些东西,知道了这些后,系统会按照你的需求去做召回,把东西从库存中拿出来,比如说我从热点里召回了500个,从兴趣中召回500个,从TOP队列中再召回500个,从很多队列中召回。
比如说我们召回了1500个东西后,我不可能全给你展示,还是太多了,那我就会给这1500个东西评分,排出来个123,所以就会通过协同过滤去做一个排名,用RFM模型去做排序。这是第一次排序。
然后会根据一些运营规则和玩法再去做一次排序,为什么要做两次排序呢?因为计算量太大了,所以要做两次排序。排序之后,就是对每个人做一个千人千面的展示了。
六、冷启动的问题
为什么是智能推荐系统?因为他有很多的数据去支撑你的整个系统,但是如果没有数据该怎么办呢?这个时候就需要做冷启动了,冷启动常遇到的问题分三种:
- 用户冷启动:主要解决的是如何给新用户做个人化推荐的问题?
- 物品冷启动:主要解决如何将新的物品推荐给可能对它感兴趣的用户这一问题;
- 系统冷启动:主要解决如何在一个新开发的产品上(还没有用户,也没有用户行为,只有一些物品的信息)设计个性化推荐系统,使网站刚发布就让用户体验到个性化推荐服务这一问题。
常见的冷启动方法,如下图:

七、智能推荐系统的指标体系
然后我们评价我们的系统是不是一个NB的系统,就需要建立一个指标体系,怎么建立这个指标体系呢?需要从三个维度来建立,第一是人的维度;第二是货的维度,第三就是场的维度。
1. 人的维度怎么评价一个推荐系统做的好不好呢?
要看的是人均展现,就像女孩子逛街一样,你开心你就多逛一会儿,不开心可能逛一会儿就结束了,看你吸不吸引她。
人均点击就是她点进去这个产品查看了,阅读时长(消费)指的就是这个东西符合他的口味,比如一本书,肯定是阅读时间越长,越能表现这个这个书越符合人的口味,我推荐的东西,肯定是他买的越多,说明我们的系统越好。
她逛了多少家店,看了多长时间,买了多少钱,肯定是推荐系统越好,推荐的东西越符合他的品味,她逛的时间就越长。这个东西都是成正比的。那Dislike就是你不喜欢这个东西,不点击,如果dislike率太高的话,那就说明我们的系统还是不太NB的。
所以说在对人的维度:是C端的维度,我们要考虑的是满足用户的需求。
2. 货的维度,比如我哪些品类被曝光了,哪些品类被卖出去了
这个要看的是每个单品商品的拉新、留存、转化能力。
为什么要说货的维度呢?是为了建立一个稳定的生态,比如说抖音,就那么几百个人火,其他人发了都不活,那么长此下去,还会有其他人去发抖音了么?不会了。
比如说漂亮小姐姐发啥都火,人均点击量就是特别高,那我是一个糙老爷们儿,我没有那么美丽的皮囊,但是我有内涵,我在抖音上讲干货,我的抖音没人看,我发了几次,一直没人看,那我就不发了。
所以在算法上,为了生态平衡,为了生态的健康,系统也会给我一些流量,让我的内容有点点击率,也利于刺激我去做内容,从而扩大整个系统的生态。
所以在货的维度上:是B端的维度,是为了要满足生态的稳定性。
3. 场的维度、平台的推荐机制等
我建了多少队列,队列是不是多样的,覆盖的内容是不是够广,内容时效性是不是够强,不能说都2020年了,我给你推2001年911恐怖袭击是吧?
还有我们的内容是不是低俗低质量的,比如什么我推的都是什么咪蒙文《港囧:斗小三的正确方式是,你要有很多很多的钱》、《如何科学的搞死渣男老公和小三》,都是很吸引人点击的内容,但是画风就很难看,所以为了持续的生态,平台也要去打击屏蔽类似的内容、字眼。
内容聚集度指的是:top100的内容占全部内容的比例,比如说我抖音top100的内容的播放量占了全部内容播放量的80%,说明大部分用户只看头部内容,那生态就是不健康的,我们还是希望是把流量平分给各个哥们儿。
但是各个平台内容是不同的,比如说抖音主要是把流量分配给各个MCN机构的,但是快手的算法是把流量分配给各个老铁的。大家可以试试,你去抖音发和快手发同样的一个视频,快手的播放量大多数是要超过抖音的,因为抖音的算法,除非爆款,不然他是不会把流量分发给你的。
而快手的Slogan是“快手,记录生活”,是一个记录生活的地方,他的流量分发是相对比较平均的。抖音为了让大家的使用时长提高,广告的转化率提高,所以会推荐一些精品的内容,但是精品的内容制作是需要有团队的,或者说门槛比较高,我们普通人制作不出来,所以内容聚集度就高了。
八、智能推荐还有哪些延伸?
比如说用在PUSH上,在大麦APP里,你平时关注的音乐会,我平时关注的是演唱会,那可能系统给你推荐的就是《【南京】【跨年场】《维也纳施特劳斯之夜》新年交响音乐会》,给我推荐的可能就是《【南京】汪苏泷大娱乐家演唱会-南京站》。
比如说智能客服,同样都是买东西遇到了困难,你是的手机维修,我的是家电维修,咱们两个收到的内容也是不一样的。
比如说智能营销,孙博士在系统里是机械学院的老教授,张博士在系统里是生物学院的老教授,那系统给他们发送的内容,给孙博士发的就是机械相关的内容,比如说机械相关的产品,相关的会议。给张博士发的就是生物相关的产品和会议等。
再来说智能搜索, 智能搜索会根据每个人搜索的历史记录不同,所在国家、地区的不同,展示不同的搜索结果,现在谷歌,百度等搜索已经是了,比如说百度,你在南京搜医院和你在北京搜医院,展示的内容肯定是不同的。
此外还有什么东西可以用到智能的个性化的产品,大家可以自己在工作之余想想。
本文由@孤独的美食家丿 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议

















我觉得你还应该再写点儿文章(doge)
好厉害,大佬
优秀~
文章很优秀
你这真的是英俊潇洒、风流倜傥、玉树临风、神勇威武、天下无敌、宇内第一、寂寞高手、刀枪不入、唯你独尊、玉面郎君、仁者无敌、勇者无惧、英明神武、侠义非凡、义薄云天、古往今来、无与伦比、谦虚好学、…简直是前不见古人后不见来者,玉树临风,风度翩翩,一树梨花压海棠……
还行还行,一般优秀
可以啊,好好努力,继续肝