
 起点课堂会员权益
起点课堂会员权益数据中台:从0到1打造一个离线推荐系统
编辑导语:如今电商平台发展的十分迅速,很多用户都会选择在各种电商平台进行消费,并且现在的电商平台对于推荐算法的机制更加精确;本文作者分享了关于如何从0到1搭建一个离线推荐系统的全流程,我们一起来了解一下。

之前文章讲了《数据中台:2个实战案例教你搭建自动化营销平台》;这篇文章我们以一个电商类推荐系统项目为例,介绍从0到1搭建一个离线推荐系统的全流程。
一、离线推荐系统设计思路
对于电商类产品来说,实时的推荐系统已经是标配的功能,因此我们的目标是做一个实时的推荐系统,但如果我们还没有推荐系统,那么一步做出实时推荐系统还是有些难度的。
我们可以分两个阶段实施,第一阶段先设计一个离线的推荐系统,做到隔天推荐,第二阶段再基于这个离线的推荐系统进行改造,做出实时推荐系统。
搭建推荐系统的核心问题是召回算法的选择,在刚开始搭建推荐系统时可以选择一些经过验证的、逻辑清晰、运营稳定的召回算法;基于物品的协同过滤算法、基于商品内容的推荐算法都比较适合电商产品,一些大型的电商巨头如亚马逊、淘宝也都在使用。
二、离线推荐系统算法选型
在实际项目中,我们使用的第一个召回算法是基于物品的协同过滤算法。
构建推荐系统的最基础的算法是基于用户的协同过滤算法和基于物品的协同过滤算法,这是标配。
上文曾提到这两个算法的优缺点,对于电商产品来说,其实更适合使用基于物品的协同过滤算法,该算法的核心原理是:如果大多数人购买商品a的同时又购买了商品b,那么我们就可以向买了商品a的用户推荐商品b。
在实际项目中,我们使用的第二个召回算法是基于商品分词的算法。整体思路是:先基于用户的历史行为数据找出用户可能喜欢的商品,将商品名称通过ES搜索引擎进行分词操作,并且给每个分词进行打分,然后通过分词搜索商品库中能够匹配到的商品,搜索引擎会自动给出匹配的分数。
比如一个用户喜欢的商品的名称为“秋冬新款韩版破洞宽松长袖T恤”,通过分词处理后就可以得出用户偏好的分词有秋冬、新款、破洞、宽松等,通过这些分词在商品库中搜素就能得到可能和“秋冬新款韩版破洞宽松长袖T恤”相似的商品;这种推荐方式也属于内容推荐的一种,实现起来比较容易。
在冷启动的情况下,我们会用到保底算法。在实际项目中,我们使用的保底算法基于商品的热度模型。商品的热度模型定义了商品近60天的销售指数,商品的浏览人数、加购人数、收藏人数等指标被分别赋予不同的权重,用来计算商品的热度。对于一个新用户,或者一个使用各种召回推荐算法都没有算出感兴趣商品的用户,我们可以在热销商品中筛选出基于用户偏好的热销商品。如果无法确定用户的偏好,我们可以直接推荐热销的商品给用户,这是保底策略。
接下来要选择排序算法,每个召回算法都会计算出用户感兴趣的商品,那么我们如何从这些召回算法推荐出来的商品中选出一部分推荐给用户呢?
前文已经讲过——如果每个地方出来的状元都彼此不服,那么我们就再统一进行一次考试,通过考试的成绩决定,也就是将这些不同算法推荐出来的商品进行排序;推荐的最终目的是让用户浏览我们的商品,最理想的结果就是让用户购买我们推荐的商品。我们需要预测用户是否会点击我们的商品,从而根据预测的点击率排序。
接下来笔者介绍一下推荐算法中常用的排序算法:“GBDT+LR”算法。
笔者简单介绍一下“GBDT+LR”算法。GBDT(Gradient Boosting Decision Tree),即梯度提升决策树;LR(Logistic Regression),即逻辑回归。使用“GBDT+LR”算法预测点击率需要两个数据:特征和权重。
特征比较好理解,比如一个用户的年龄、地址,该用户近期浏览过某品类的商品的次数,加购过这个品类的商品次数类似等,都是特征。
权重是由人工制定并通过数据再不断优化的参数。比如一个用户如果浏览过这个品类,我们觉得用户有40%的可能喜欢该品类;一个用户如果加购过这个品类,我们觉得用户有60%的可能喜欢该品类。这里面的40%和60%,就是我们设定的权重。
GBDT模型的具体操作可以理解为:不断对一个用户提问。
- 比如向用户提问:是女性用户吗?
- 如果答案为“是”,再问:喜欢毛衣吗?
- 如果答案为“是”,再问:喜欢哪个价格段的毛衣?
这些提问按照层级组织起来。对于不同答案再提出不同的新问题,直到最后得出最终答案:用户对这个商品满意吗?这就是GBDT模型。该模型天然可以肩负起组合特征的任务,第一个问题相当于树的根节点,最后得到的答案相当于叶子节点,整条提问路径就是若干个特征的组合。
GBDT的优点是自动挖掘用户的特征,得到最佳的特征组合,省去构建特征工程的烦琐工作。
逻辑回归(Logistic Regression, LR)又称为逻辑回归分析,是分类和预测算法中的一种,通过历史数据的表现对未来结果发生的概率进行预测;例如,我们可以将用户喜欢某商品的概率设置为因变量,将用户的特征属性,例如性别,年龄,注册时间、偏好品类等设置为自变量。根据特征属性预测用户对某件商品喜欢的的概率。
在实际项目中,我们可以找产品线的产品/运营人员一起讨论下推荐方案。他们对业务更了解,可能会提出一些好的建议;比如笔者在构建推荐系统过程中,同公司的产品/运营人员就提出了以下建议。
1)笔者所在公司的电商产品定位快时尚女装,所以几乎每天都会新品上架,而新品上架7天后就基本没有货了,这种情况给推荐算法带来很大挑战;而且新款一般不会有太多的交易数据,无论是基于物品的协同过滤算法,还是基于用户的协同过滤算法只会推荐很少新款。
经过与产品/运营人员的讨论,我们决定为商品打上“新款”或“旧款”标识。因为每一件商品都放在某个专场内,而专场都有开始时间和结束时间。如果商品所在的专场没有结束,那么我们会给商品打上“新款”标识;如果商品所在的专场已经结束,那么我们会给商品打上“旧款”标识。如此一来,只要提高基于内容的推荐算法中“新款”标签权重,这样就能更好地推荐新款商品。
2)为了应对实际的业务场景,需要增加一些过滤条件。比如对于下架的商品、用户若干天内购买过的商品,我们需要在提交给用户的最终推荐结果中将之去除;对于一些退货率比较高的商品,我们设置了一个阀值,如果商品的退货率超过该阀值,那么这些商品也会在推荐列表中被统一去除。
3)需要考虑商品的上架时间和用户访问高峰期因素。笔者所在公司的电商平台一般都是在早晨10点左右上架一次商品,在下午18点左右也会上架一次商品,而中午12点左右和晚上20点左右是用户访问的高峰期,也是用户下单的高峰期。
如果离线推荐系统的计算引擎只在晚上计算,那么在早晨10点左右和下午18点左右上架的商品,大部分都不能被推荐出来,这就需要调整离线推荐系统的计算调度;首先在中午12点左右进行一次计算,保证在上午10点左右上架的新品都能出现在用户的推荐列表中,然后在下午19左右进行一次计算,保证在18点左右上架的新品也能出现在下一次用户访问高峰期的推荐列表中。
三、离线推荐系统开发过程
接下来,笔者从工程角度讲一下应该如何搭建推荐系统。
1)首先需要数据开发工程师根据推荐算法的需要准备几类数据。
第一类是用户的基础数据,如表1-1所示,此类数据可以用来挖掘用户的特征。
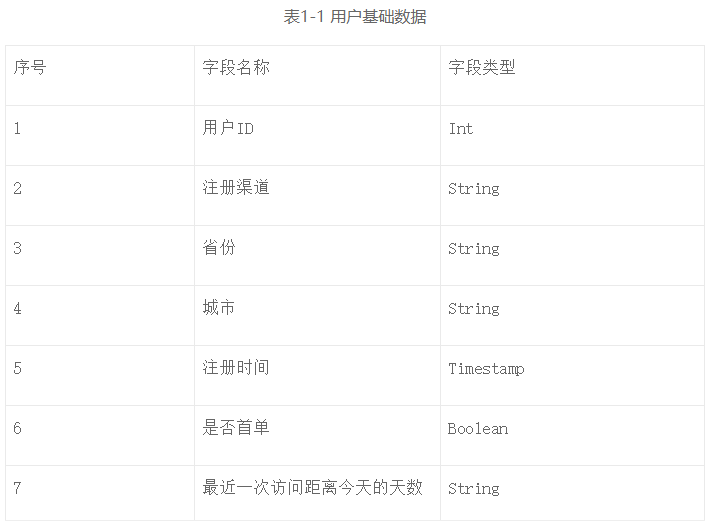
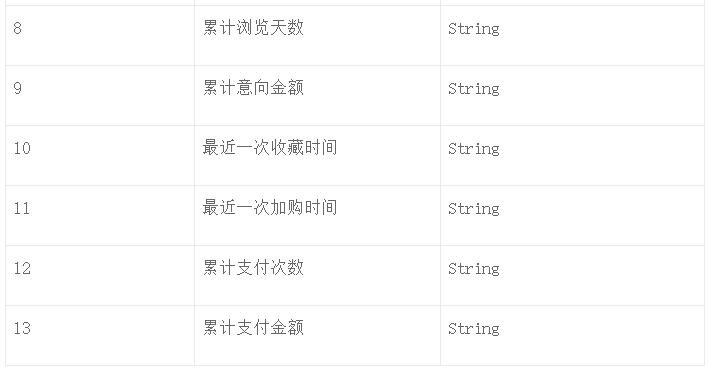
第二类是用户行为数据,如表1-2所示,比如用户在什么时间对商品有浏览、加购、下单等行为。此类数据是召回算法的基础支撑数据。
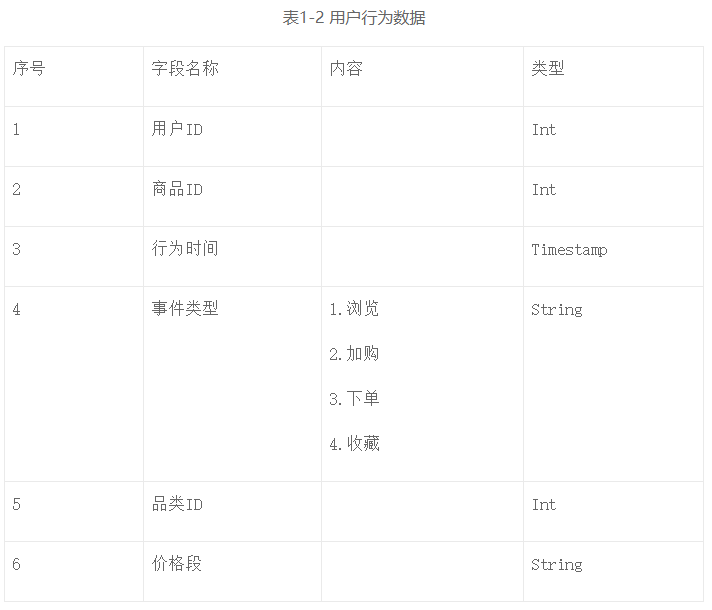
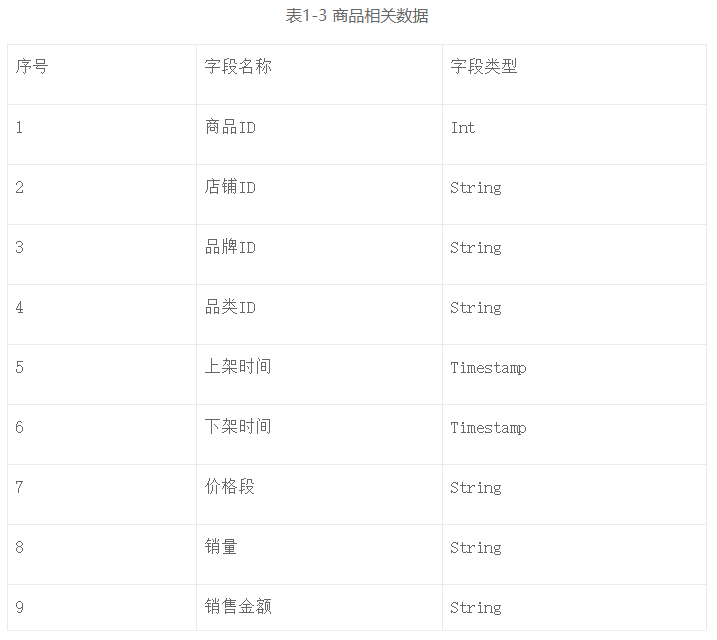
第三类是商品相关的数据,如表1-3所示,比如商品的品类、是否上/下架等基础信息。此类数据可以让算法工程师快速获得商品的相关信息。
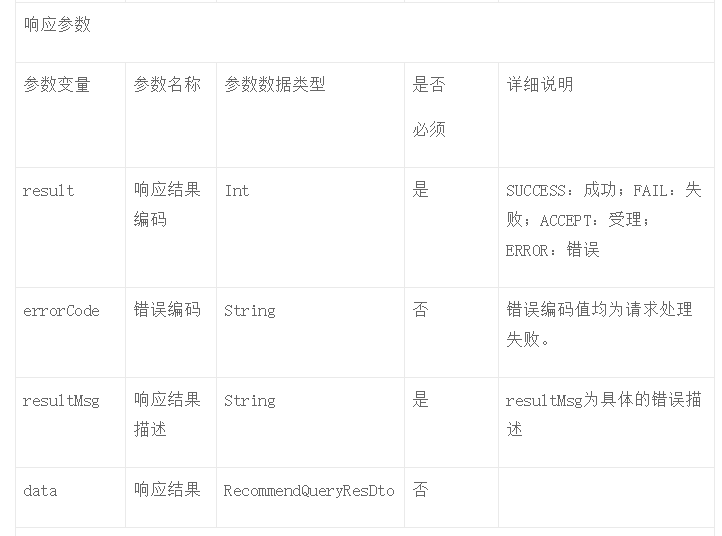
当算法工程师和数据开发工程师按照召回算法和排序算法的规则完成开发后,就会形成最终用户的推荐结果,一般存储在MySQL等关系型数据库中,通过接口对外提供服务。
每个用户获得的最终推荐结果的参数如下:
- 用户ID:用户的唯一标识。
- 商品ID:商品唯一标识。
- 召回算法ID:召回算法的唯一标识,用于统计召回算法的效果。
- 点击率:用户点击的概率,一般是取值在0和1之间的小数。
- 计算时间:产生推荐结果的时间,一般存储近几次的计算结果。
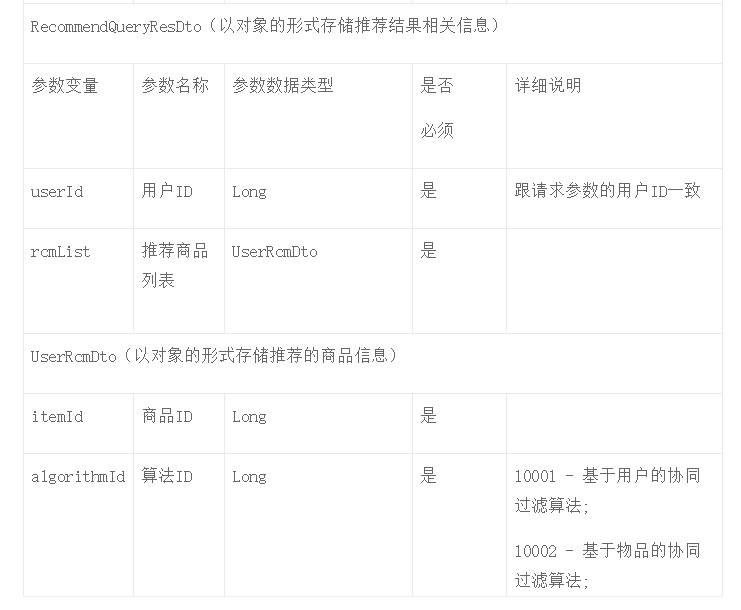
基于推荐结果的数据,数据中台的后端开发工程师就可以开发对外的服务接口,如表1-4所示;请求参数包括用户ID、页码、每页商品数量。响应参数主要包括用户ID、推荐商品列表,商品列表可以通过JSON的格式存储。

2)搭建推荐系统还需要其他部门同事的配合,比如产品线的产品/运营人员。
运营人员需要在产品的功能界面中预留一个位置,类似淘宝网的“猜你喜欢”频道,可以基于自己的产品特性来选择位置;运营人员还需要协调UI资源,设计推荐位的LOGO、背景图等。
电商产品线的产品经理需要协调前/后端开发工程师完成推荐位置的前/后端和数据埋点开发的开发工作。前/后端开发工程师负责调用数据中台的推荐接口,完成推荐功能界面的开发。
数据埋点开发要解决2个问题:
一是要知道每个场景、每个算法、每天的交易额,当用户加购时,要把场景ID、算法ID,同商品一起加入购物车中,当用户下单时再将场景ID、算法ID一并加入结算。
二是我们要统计每天有哪些用户访问我们的推荐位,点击了哪些商品,就需要针对推荐模块做一个常规的埋点,埋点方法可以参考第2章“数据采集”部分内容;有了这些埋点数据,我们就可以计算推荐位每天产生的总交易额、总访问用户数等相关商业指标,也可以通过查看每个算法的准确率、召回率、覆盖率这三个指标,来找到最合适的算法。
数据中台主要承担算法的开发、推荐接口的开发、推荐系统的数据分析等工作。推荐系统的方案设计大概需要1周时间,另外需要3天的时间来评审方案,电商产品线的产品经理进行前/后端和埋点的开发工作大概需要1周的时间,数据中台针对算法的开发工作大概需要1个月的时间。
由此可知,打造一个简单版本的推荐系统预计共需要2个月左右的时间。
四、离线推荐系统测试
至此,推荐系统的整个开发流程就结束了,接下来需要进行推荐系统的测试。
为了方便测试,我们可以开发一个快速拿到每个用户推荐结果的功能,方便产品经理和测试人员查看推荐数据。这项开发工作需要满足三方面要求。
- 可以快速查询每种召回算法带给每个用户的推荐结果。
- 可以快速查询通过排序算法生成每个用户的最终推荐结果。
- 可以快速查询向用户展示的最终推荐结果。
要想开发查询推荐结果的功能,最好配上商品的图片,看商品图片比看商品名称,更令人印象深刻,如图11-13所示,可以快速筛选出某个算法在某天为某个用户推荐的结果。

用户推荐界面
测试工作的流程如下:
1)需要对召回算法进行测试
召回算法主要需要测试其算法的逻辑是否正确。一般来说,算法工程师和测试工程师需要合作完成测试用例的验证。算法工程师按照测试工程师的要求提供数据,测试工程师则负责验证算法逻辑的准确性。
2)需要对排序算法的结果和用户最终的推荐结果进行测试
因为逻辑比较复杂,这两个步骤的测试很有挑战性。在这里推荐一个简单的方法,项目组可以一起定义几类典型用户,比如:无用户行为的用户;有历史行为数据,但很久没来访问的用户;有历史行为数据并且最近很活跃的用户。
对于第1类用户,可以验证一下推荐给他们的结果是否符合冷启动的策略。
对于第2类用户,他们虽然有历史行为,但是历史行为的数据陈旧,无法再利用,需要验证一下推荐给他们结果是否符合我们制定的策略。
对于第三类用户,可以让算法工程师基于他们最近的行为,推荐给他们可能喜欢的商品,然后对比他们喜欢的商品,检查推荐的商品是否有很大的误差;假如某用户喜欢50~100元价格段的牛仔裤,而我们推荐给他的结果都是500元以上的牛仔裤,那么推荐结果就有问题了。
3)最后还需要对过滤的规则进行测试
比如对“用户近期买过的商品不能出现在推荐列表中”“退货、缺货率很高的商品不能出现在推荐列表中”等过滤规则进行测试。
相关阅读:
#专栏作家#
Wilton董超华,微信公众号:改变世界的产品经理,人人都是产品经理专栏作家。畅销书《数据中台实战》作者,曾任职科大讯飞,现任富力环球商品贸易港数据中台产品负责人。主要分享商业、产品、运营、数据中台相关原创文章。
本文原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议









老师您好 请问产品经理在推荐系统建设中的主要工作包含那些