
 起点课堂会员权益
起点课堂会员权益推荐策略产品必备技能之推荐系统框架(上)
编辑导语:推荐策略产品的必备技能之一:推荐系统框架,可能有的同学还不太了解,作者简单地分享了一些相关知识,我们一起来看一下。

本模块的目标:
- 了解推荐系统框架,以及这套架构的演进
- 了解推荐系统框架中的各个模块的功能
- 了解推荐系统的数据流
一、推荐系统架构组成模块
一个经典的推荐系统的架构,主要包括如下四部分:
- 推荐服务:该服务从服务器获取推荐请求,然后返回推荐结果。
- 存储系统:这些系统存储用户画像、物品画像和模型参数。
- 离线学习(Offline learning):该组件从用户行为数据中学习模型参数,然后按照一定的周期将参数更新后的模型推送到在线存储系统中;物品画像学习;用户画像学习。
- 在线学习(Online learning):实时更新模型。
1. 推荐服务
“推荐服务”的功能是对来自业务的request进行预测。
比如,我这会打开抖音,抖音后台会发送一个request给推荐服务所在的服务器,服务器接收到这个request之后,会根据过去我在抖音上的行为偏好,为我推荐我可能感兴趣的短视频。
2. 存储系统
“存储系统”的功能是存储用户画像、物品画像、以及模型参数。
3. 离线学习
“离线学习”的功能包括:模型训练、物品画像、用户画像计算。
- 模型训练是指给定用户和物品,以及用户对该物品的响应数据,来训练模型参数,这个过程一般需要耗费好几个小时的时间。
- 物品特征是比如对于非结构化数据,经常需要对这些数据进行TF_IDF计算,这个也是在离线层进行。
- 用户特征也是。
4. 在线学习
“在线学习”的功能是利用用户的即时数据进行预估。
二、经典的推荐系统架构
每研究任意一款产品,我第一个想法,都是去看看世界上经典、优秀的产品他们是怎么设计的,以及为什么要这样设计。我的关注目标很简单:
- 这套架构的设计目标是什么?
- 为什么是这些目标?
从目标开始,以终为始,同时know how。
know- how(或know- how,或程序性知识)是一个关于如何完成某事的实践知识的术语,相对于“know-what”(事实)、“know-why”(科学)或“know who”(沟通)。
为了支撑这个目标,creator都做了哪些设计?是否存在好的「设计模式」值得我学习?
设计模式是我尝试通过学习行业经典的产品,从而发掘出可复用的知识结构。
这类复杂产品设计师是如何做到快速深入业务,做到设计驱动,达到业务与专业双成长,是否存在好的「设计工作模式」、「设计思维」值得我学习?
业务专业双成长:双成长指的就是如何在消耗大量时间深入业务的同时,在专业深度上也能保持精进。
1. 为什么选择Netfix的推荐系统架构
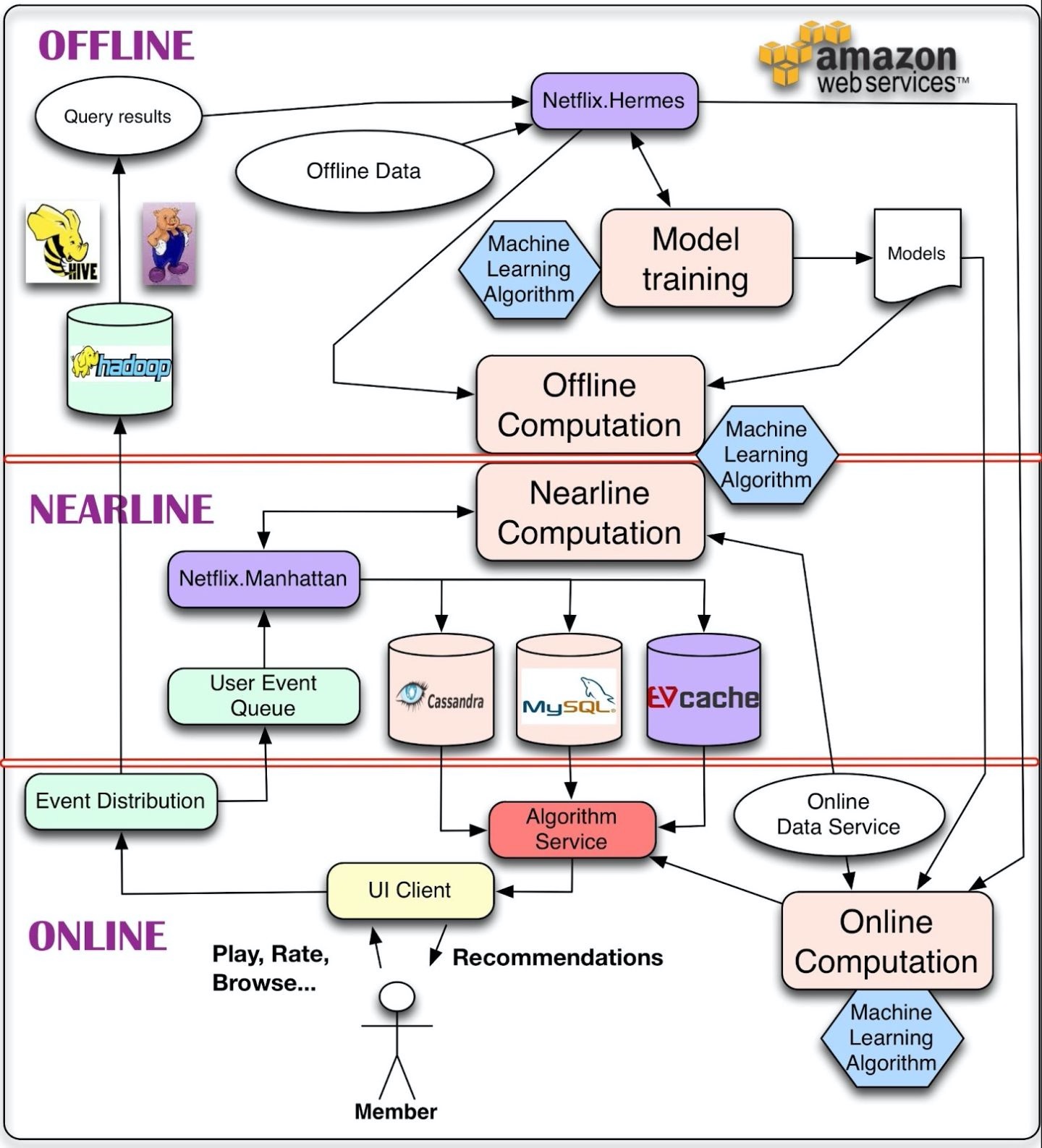
这是Netflix的推荐系统架构,分为离线、近线和在线层。这样的设计模式,在当前依然是主流模式。
2. Netflix的设计目标是什么?
这是Netflix的推荐系统架构,这个架构的设计目标是:
- 支持好的用户体验,且能支持新的推荐策略开展实验。
- 针对用户的行为,作出快速的响应。
- 能处理海量数据。
《个性化和推荐的系统架构》中提到:
开发一个能够处理大量现有数据、能够响应用户交互并易于试验新的推荐方法的软件体系结构并不是一项简单的任务。
在这个架构中,计算被分为了离线、近线和在线。
计算可以离线进行、近线进行、也可以在线进行。对于用户产生的最新行为,在线计算能更好地进行反馈,但是在线必须实时进行反馈。
这样的话,就对算法的计算复杂性有很大的限制,同时,也会限制能处理的数据量。
离线训练能处理较大的数据量,且不要求必须是实时相应的。
模型的更新一般是离线进行的,在模型的前后两次更新这个时间窗口中,由于没有进入新的数据,所以这个模型一直使用的是旧的数据。
对于推荐系统架构最关键的因素是如何将在线和离线计算无缝结合。
近线计算是在上述两者之间,在近线计算,我们可以执行类似在线的计算,但不要求实时响应。
再简单理解一下离线、近线和在线。
- 离线:不用实时数据,不提供实时服务;
- 近线:使用实时数据,不保证实时服务;
- 在线:使用实时数据,要保证实时服务。
3. 推荐系统的用例
背景设置:这样一个场景,西蓝花资讯问答是一个基于多端(Web、APP、小程序)的文档服务平台。在这个平台,有两个主要的角色,文档发布者和文档消费者。
- 发布者(publisher)会在这个平台上不定期的上传文档内容。
- 消费者(consumer)会在这个平台上通过搜索获取他们需要的文档材料。
我们根据这样一个场景,来初步分析一下推荐业务如何开展。对于任意一个推荐业务,我们都可以先简单抽象成3张宽表:用户表、物料表、用户行为表。
该场景的用户表,是所有consumer的信息集合。物料表是publisher发布的所有物料的集合。用户行为表是用户在这个平台上产生的所有行为。
我们通过上述场景来理解推荐系统架构。
3.1 存储系统
存储系统。存储系统中饱含候选物品、用户信息、特征和模型。
物品索引:在这个例子中,物品加入组件监视一组生成新物品的物品源(例如:发布者)。当新物品j产生时,物品加入组件提取物品特征,并将物品以及其特征放入物品索引,以便按特征快速检索物品。
这么说比较抽象,具体一点就是说,比如我们首页相关推荐用的物料库,在2021年6月1日23点59分有物料更新,那么系统会监测到这个时间点有物料更新,并且对这些更新的物料进行特征抽取,计算完毕后会将这些特征存储在我们的存储系统中。
用户数据存储区:用户特征存在于用户数据存储区中。该存储区是一个键-值存储区,支持通过给定一个键(比如:用户ID)快速检索出值(比如:用户特征)。
模型存储区:离线学习组件按一定周期更新模型。
3.2 离线学习
给定用户和物品的特征,以及用户的行为数据,也就是三表(用户表、物料表、用户行为表),离线训练模型。因为离线学习很容易耗费好几个小时,因此在西蓝花资讯文档这个case中,我们每天执行一次离线学习。
3.3 在线学习
实时更新模型,暂不展开。
3.4 推荐服务
每当客户发一个request,经过网关、后台,返回对应结果。
数据流部分下一篇讲哦。
如果这篇文章对你有帮助,并且有兴趣看接下来的更新~
#专栏作家#
一颗西兰花,人人都是产品经理专栏作家。关注AI产业与写作工具,擅长数据分析,产品研发管理。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









赞赞👍非算法的人学到了很多