
 起点课堂会员权益
起点课堂会员权益算法为什么比你还懂你自己
#本文为人人都是产品经理《原创激励计划》出品。
移动互联网的快速发展、互联网信息的爆发增长,都让用户面临着某种信息无法完全消化的茧房困境。在这一问题维度上,推荐算法的应用可以帮助用户过滤、筛选、乃至“便利”地获取信息。不过,问题往往需要多维看待,当被赋予过强的商业化目的时,推荐算法应当回归工具的本质。

又是一年一度的“618”购物节,浏览淘宝时,感叹“为你推荐”越来越精准了,就像是肚子中的蛔虫,我想要什么它马上就可以推荐给我。
不光淘宝,还有网易云音乐、美团、快手、Bilibili ……“为你推荐”、“猜你喜欢”等推荐功能似乎成了大多 APP 的标配,既像一个贴心的管家关心着我的每一喜好,也像一个躲在屏幕后的偷窥狂窥视着我的一举一动。
那么“为你推荐”,“猜你喜欢”背后的推荐算法是怎么做到比你还了解你呢?
一、推荐算法的由来
在介绍推荐算法之前,先问个问题:我们为什么需要推荐系统?是我们对发现自己需求产生了什么困难抑或是表达需求遇到了什么阻碍?
1. 从客观环境上,信息时代为推荐算法的诞生提供了基础
1)信息爆炸
我一直很喜欢“网上冲浪”这个词,不仅表现出浏览信息的畅快感,也提醒随时有沉溺于信息之海的危险。
现在就是这样,每个人无时无刻被信息包裹,甚至“溺亡”。根据《科学》杂志的统计,截止2014年,互联网信息1000万亿亿字节,如果把这些信息打印出来,则需要1.36×10¹²张 A4 纸打印,一个人可能十辈子也无法看完这些信息,然而信息增长的速度还在加快。
2)碎片信息
信息时代的另一个特点是“碎片信息”,信息的碎片化导致从信息形式本身来说是反系统、反归类的。文章的字数越来越少,视频的时长越来越短,公众号也经常“旧坑还没填完”就开始不断“挖新坑”,就连持续关注也难以获得系统的信息。
2. 从主观需要上,我们某种程度上被裹挟着需要推荐算法
1)速食文化
“一分钟学会**”,“十句话告诉你**的秘诀”……速食不仅仅在饮食上,也蔓延到对信息的摄取上,我们越来越缺乏耐心,期望可以更高效地获取信息。
2)错过焦虑
有没有担心错过某篇“大佬”的内容,有没有为看不完的“课程”而焦虑……我们担心错过一条有价值的信息而不断刷新,订阅或寻找下一条信息。这似乎是身体曾经对食物渴求记忆的遗留,这种渴求也反映在信息上。
3)选择无能
选择太多也意味着难以选择。从刚开始订阅三四个公众号,每天还可以看一看,随着公众号订阅得越来越多,除了焦虑,更多的是躺平,就这样吧,反正也看不完,也不知道看什么。
我们对于信息的获取,自古就有,只是以前由于技术资源等限制,这些只是少部分人才会有的烦恼,毕竟学富五车已经是很丰富的知识量了。然而,信息时代的到来,信息早就不能用“五车”来衡量,信息的量和形式都发生了飞速的变化,几乎人手一台手机,让大部分人都拥有了这样的烦恼。
就像淘宝,商品琳琅满目,已经多到一个人几辈子都不可能买完,一方面想快速找到自己想要的商品,另一方面又不想错过任何一个优惠。推荐算法提供了一个可行的方法,我帮你找到你想要的东西,或者我来告诉你,你想要什么。
二、推荐系统的定义
推荐系统是一种信息过滤系统,用于预测用户对于物品的“评分”和“偏好”。
——维基百科
从维基百科的定义可以看出,推荐系统主要解决的问题是,帮助用户发现自己喜欢的东西,并将其以适当的方式(APP 信息流)展现给用户。
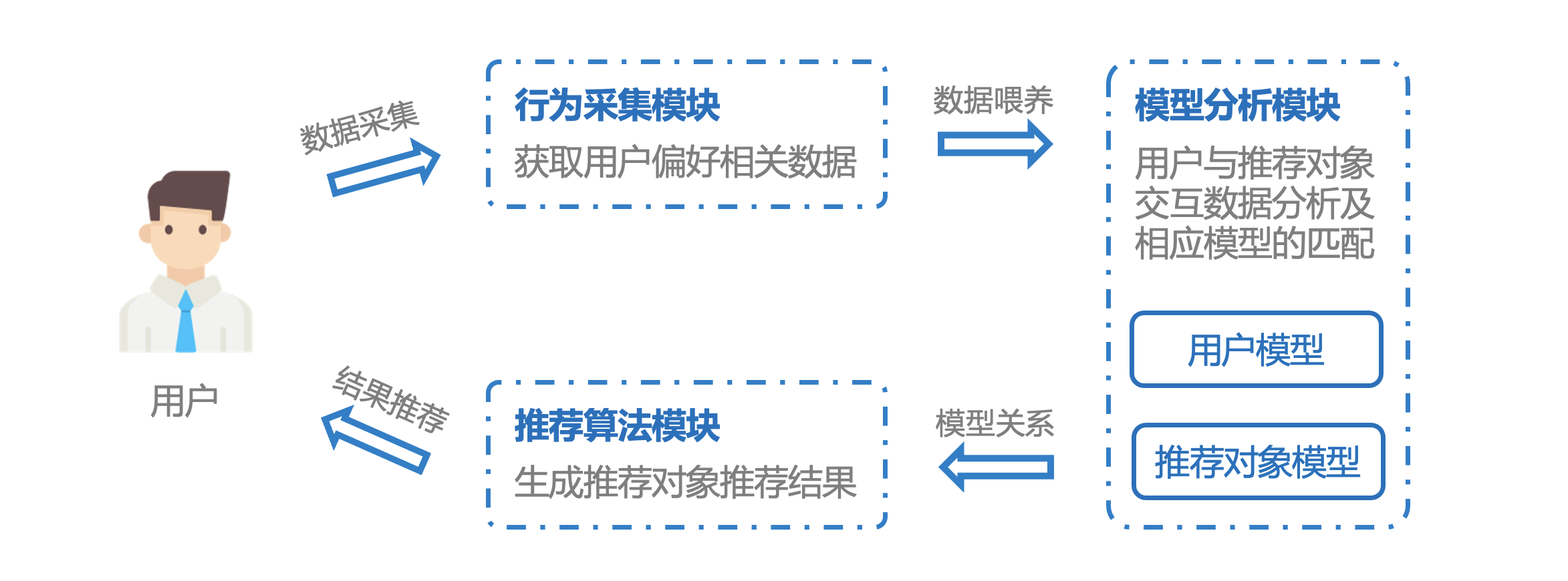
推荐系统一般由三个部分组成。
1. 行为采集模块
主要负责采集记录用户的(与推荐对象交互)行为数据,比如浏览、收藏、点赞、评论、加入购物车等。
2. 模型分析模块
包括用户模型和推荐对象模型,主要利用采集到的用户行为数据,分析用户和不同推荐对象之间喜好程度,并结合相应模型分析用户兴趣。
3. 推荐算法模块
根据用户特征和推荐对象特征,结合当时的环境特征,对用户进行推荐对象的推荐。
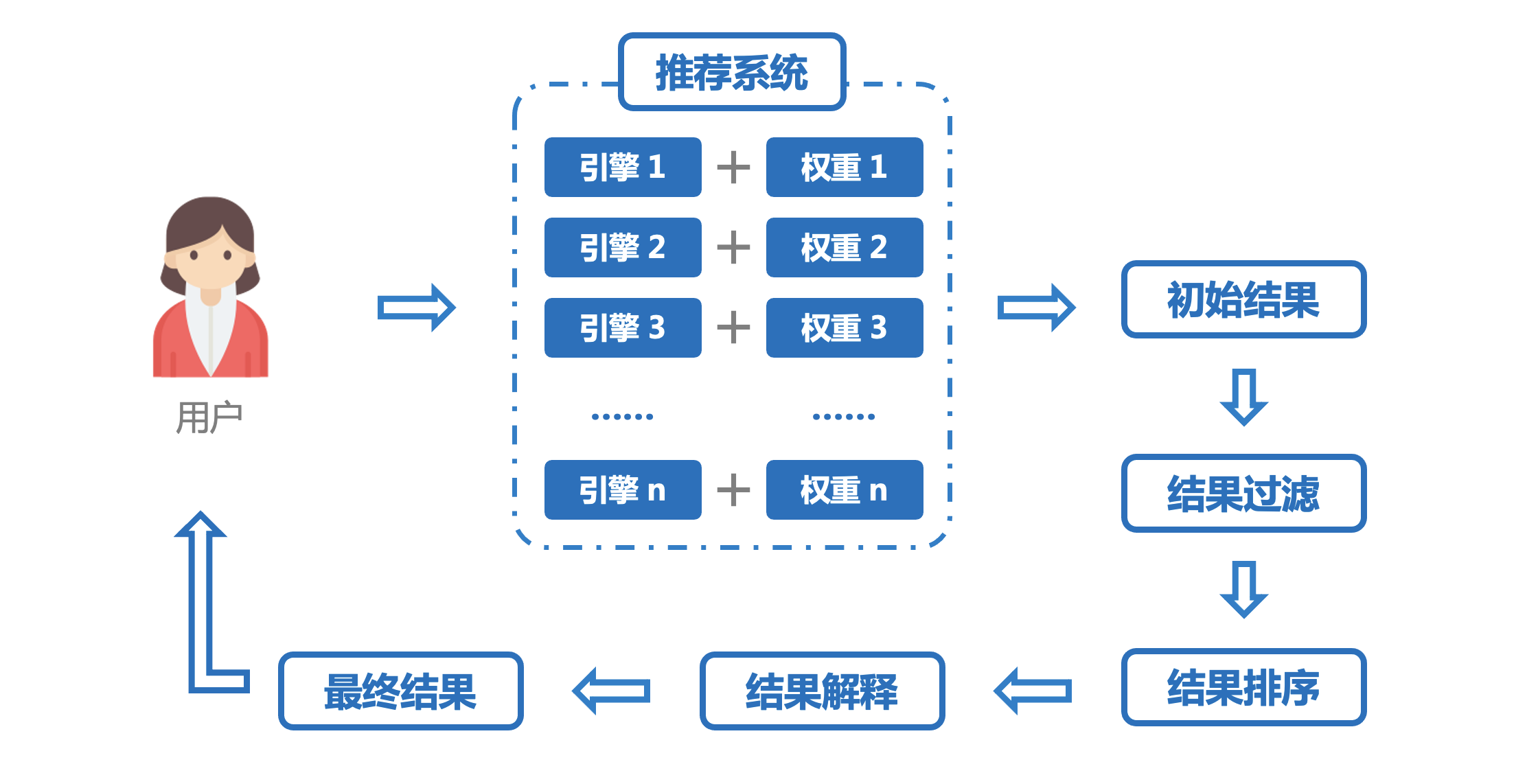
我们现在使用的APP,推荐结果一般都是以列表的形式展现,也就是“Top-N”问题,即在不同的场景下为用户提供一个包含 N 个推荐对象的列表,这 N 个推荐对象是否是用户喜欢的是推荐系统重点解决的问题。一般通过多个多个推荐引擎,每个引擎负责一类特性和一种任务产出相应的结果,结果再按照一定的权重进行排序生成列表。
三、常见的推荐算法
推荐算法是推荐系统的核心,在很大程度上决定了推荐系统的优劣,也就是我们常说的“推荐得准不准”。如何知道你的偏好,从而让推荐准确,可以从以下四个方案提供思路。
1. 方案一:大家都喜欢的东西,你也会喜欢
人是集体性生物,个人行为会受到外界人群行为的影响,而在自己的判断,偏好上表现得和大多数人一样。这为推荐算法提供了一个思路,即“大家喜欢的东西,你也会喜欢”,热度推荐算法也应用而生。
对不同物品赋予个初始得分,用户对物品的交互会产生不同的分值,比如点赞 +2,点踩 -1,加入购物车 +3 等,根据发布时间与当前时间的差值再得出该物品“新鲜度”的衰减分,初始分加行为分再减去衰减分就可得出当前得分,按照得分值的大小进行排序就可得出推荐列表。那么大多数用户都喜欢的(点赞、收藏、转发)物品,结合发布时间,会优先推荐给你。
热度算法的应用很多,比如淘宝、微博的热搜,还可以根据不同维度生成分榜单。当然具体到各个产品当中,不会像上文写的简单加减,会根据场景、自身用户特点进行加权等更复杂的计算。

2. 方案二:你喜欢这个东西,也会喜欢这一类东西
虽然会有“三分钟热度”,但在一段时间内,人对某物品的喜欢会保持稳定,即你喜欢这个东西,也会喜欢和它同属一类的其他东西,比如你喜欢姜文导演的电影《让子弹飞》,那么他导演的《鬼子来了》, 你也大概率也会喜欢。这种推荐方式就是利用内容过滤推荐算法。
基于内容推荐,需要提前对推荐对象进行分类,分类的方式有很多,可以按照种类,比如水果、蔬菜、粮油……也可以按照归属,比如某导演的所有电影、某歌手的所有歌曲……其实就是判断不同对象之间的相关性,对相关性取值,划分区间,不同区间内的所有对象归为一类。比如抖音,一旦你浏览了这一类中的某个内容,就会推荐这一类中其他的内容给你。
相关性可以通过贝叶斯定理计算,以用户观看视频为判断相关性的标准,设用户观看视频 A 的概率为 P(A),观看视频 B 的概率为 P(B),则:
- 用户看完视频 A 再看视频 B 的概率为:P(B|A);
- 根据 P(B|A) 值的大小来决定是否来推送视频 B。
3. 方案三:找到一个和你很像的人,他喜欢的东西你也会喜欢
人总是期望得到熟悉或相似的东西,就连人也是,两个相似的人更容易产生交集,也有更多相同的东西可以进行分享,比如都喜欢某一首歌,某一部电影……
找到那个和你很像的人,不只是一个浪漫的梦想,也是推荐算法一直尝试实现的事情,协同过滤推荐算法就是致力于解决这个问题。
协同过滤推荐算法利用用户信息进行近邻搜索,找到近邻用户,在根据近邻用户的喜好来进行相应的推荐。
举个例子,在身高维度,身高差异最小的两个人更像,再增加体重维度,就成了二维空间,通过两点的夹角大小可以判断相似性,如果再增加年龄维度,就是三维空间,也可以通过夹角大小来判断相似性。
实际应用中一般都是多维空间,比如网易云音乐,以用户对歌曲的交互行为(点赞、收听、收藏等)建立多维空间,在多维空间中计算你与别人的夹角值,通过夹角值的大小来寻找近邻用户,再将她喜欢的歌曲推荐给你。还记得有段时间,网易云音乐推出了社交的功能,那个推荐给你的人可能是在音乐品味上与你最相似的人。
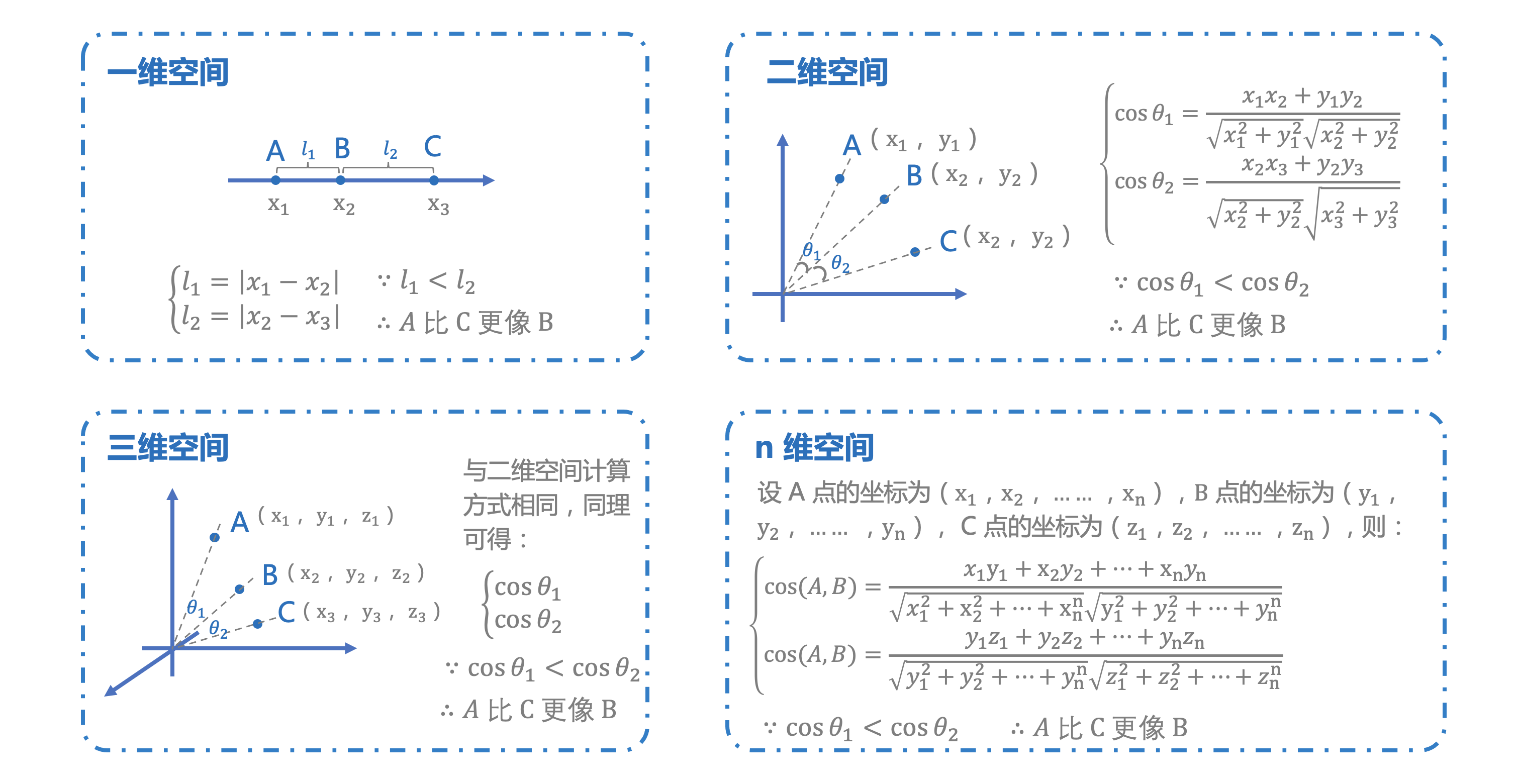
上图所示的余弦相似度是一种典型的协同过滤相似办法,还有对数似然相似度法、Pearson相似度法、Jaccard相似度法……都是基于存储的协同过滤算法。
4. 方案四:找到一个和你存在某种关系的人,他喜欢的东西你也会喜欢
方案三中的方法主要是利用用户在 APP 内的行为数据,如果是新用户,行为数据非常少,那怎么办?
既然 APP 中没有你的信息,那么可以从你现实世界中寻找线索,通过社交圈是一个不错的途径,毕竟这也是你在现实生活中找到“近邻用户”。
当然这种现实关系不仅仅指社交圈,比如音乐网站 Spotify 宣布与 DNA 网站合作,任何人只要允许 Spotify 查看他的 DNA 序列,Spotify 就可以给用户推荐根据他的 NDA 定制的歌曲。
上述的四个方案提供给算法了解用户的思路,但各有利弊,比如方案三就会面临“冷启动”、“数据稀疏”等问题。所以实际使用中,都是好几种算法的混合,即混合推荐算法。主要有七种不同的混合方式:加权、变换、混合、特征组合、层叠、特征扩充、元级别。
四、推荐算法的挑战
大数据时代一个典型的特点是海量的信息,信息从未像现在一样庞大,也从未像现在一样易得,推荐系统帮助我们在海量信息中快速找到自己需要或感兴趣的信息,提供便利的同时,也面临着诸多挑战。
1. 挑战一:信息茧房
为了增强用户黏性,提高用户停留时间等,算法会迁就用户的偏好,不断预测并推荐符合其偏好的信息,这使得用户接收的信息面越来越狭窄,并进一步强化其偏好,就像身处在一个茧房中,被层层束缚,无法“破茧而出”。算法让兴趣相投的用户更容易产生联结,但也加剧了社会价值观念和意识形态的分化。
2. 挑战二:信息暴食
“某音,某手正在毁掉一代人”这样的营销文甚嚣尘上的同时也反映了一个现象,APP 越来越关注于争夺用户的时间,算法推荐无穷无尽的内容,刷完一屏,马上生成下一屏的内容。
APP 设计也越来越看重“沉浸式体验”,曾经抖音通过隐藏时钟这一人为创造物,让用户更容易忽略掉时间流逝,一不留神好几个小时就过去了。
3. 挑战三:隐私风险
上文提到的方案四,在冷启动阶段,为了更精准地推荐,会挖掘用户现实中的关系,其他方案也会存储用户行为数据以供模型的优化,但是如果这些数据被泄露呢?科技越发达,隐私越少,人们让渡隐私,换取更便利的生活,但是什么该做、什么不该做,应该由谁来保障?
4. 挑战四:黑箱操作
“你的 APP 在监听你”,“APP 偷看了你的相册”……等等诸多的怀疑都来自算法是“黑箱操作”,我们只知道被推荐了这些信息,但是不知道是怎么推给自己的,未知导致恐惧,恐惧加剧怀疑。
五、结语
这是一个最好的时代,也是一个最坏的时代。
——狄更斯 《双城记》
推荐算法是技术的产物,也是时代的产物,诞生于如何在海量信息中帮助人们找到需要的信息,但是否“真正”需要是非常难界定的,是出于主观意愿上的独立选择,还是外部干预下的被动选择,到底是“我需要”还是“平台觉得我需要”,是两件非常不同的事情。
信息的摄取自人类诞生之日起就存在,推荐算法面临的挑战,曾经的信息摄取工具或多或少也遇到过。
信息茧房或许是算法建立的,但终究是自己选择躲进去的。
信息暴食更多是物质匮乏时代的遗留,在物质过剩的现在,仍有很多人无法克服对脂肪淀粉等本能的生理渴望,错过一篇公众号文章都会焦虑不已,怎么能奢求他们克服对信息的暴食。
隐私风险一直存在,人们只是数据库中的一串数据,我们用隐私作为交换,选择便利。
黑箱操作,算法最初是作为核心机密来保护的,但随着推荐系统回归到数据本质,算法本身只是成了一把钥匙,箱子里的宝藏是你拥有多少可用的数据,这样也提供了一些了解黑箱操作的途径,但是比起“沙雕视频”,了解算法并没有那么有趣。
推荐算法某种程度上是基于一种“无能”的假设,即:用户没有能力独立找到自己所需的信息,所以需要算法“喂养”。
当然算法可以自信地拍着胸膛说,我比你还了解你,你为什么不愿意接受我的推荐,但是作为创造者,作为追求自由精神的人类,我们不是“事事挂在脸上”的三体人,我们需要一些私密的空间,需要有做出选择权利。可以有一部分人选择放弃这个权利,也可以有一部分人选择行使这个权利,但关键在于能够给予用户做出主观选择的权利。
工具应该回归工具的本质,而不应该被赋予太多原本不属于它的能力。
就像推荐算法被赋予太多商业上的目的后,它虽然依旧行使着工具的作用——帮助我们获取到了信息,但却让我们存在着“被无微不至关心”和“被肆无忌惮窥视”两种割裂的体验。
本文由@Pluto_蛋蛋 原创发布于人人都是产品经理,未经许可,禁止转载。
本文为人人都是产品经理《原创激励计划》出品。
题图来自 Unsplash,基于 CC0 协议









脉络清晰,见解深刻,赞一个~
有太多人沉溺于信息之海了,水下待的太久就变成了鱼,没有思考,没有记忆。
做推荐系统需要什么样的人员组织架构啊?
架构师,高级程序员,算法