
 起点课堂会员权益
起点课堂会员权益线下业务数据体系搭建(二)——逾期资产处置系统数据底层逻辑设计
编辑导语:本文就线下业务数据体系的搭建进行讲解。以自己公司上线系统后出现的问题为例,从四个方面进行讲解,解决了系统数据构建问题。推荐想要搭建线下业务数据体系的用户阅读。

最近开始上线系统,公司目前又没有数据产品经理参与系统设计,勉勉强强上线了系统,但是在系统上线之前经历的打断数据清洗迁移系统的过程,是想记录下来分享给大家的。
整个产品项目提出大概是去年年末今年年出,确定初版原型图设计大概是6月份,需求调整、开发、测试、灰度,到现在才开始进行实际业务测试,期间经历了很多困难,实际在业务的生产中,我们在7-8月份实现了整个部门业务处置能力的飞跃,整体的业务模式也发生了比较大的变化,这导致实际开发进度远落后于业务的进步。
一、业务逻辑
在很长一段时间内,我们一直依靠数仓建立的一张极高自由度的表结构下操作,大量的数据由实际前端业务员汇总,导入数仓留存,这样的操作就导致了,在实际业务逻辑中,有大量存在强逻辑相关性的字段,并没有按实际的固定的逻辑进行留存,像类似有一部分用户/订单委派给了渠道进行诉讼处置,但渠道回传的案件进度数据中,只给定了诉讼结案时间,却没有立案时间。
但由于这张极高自由度的表格,会让这样不合业务逻辑的数据被留存下来,如果渠道在中途不再合作,立案时间这个字段可能就彻底丢失,在系统数据中转化为错误值,在业务中的有效数据因为工作流程上的不规范成为了无效数据,这是得不偿失的。
所以,在实际设计线下业务数据体系的时候的时候,第一个需要考虑的就是业务上的逻辑,简单以诉讼为例。
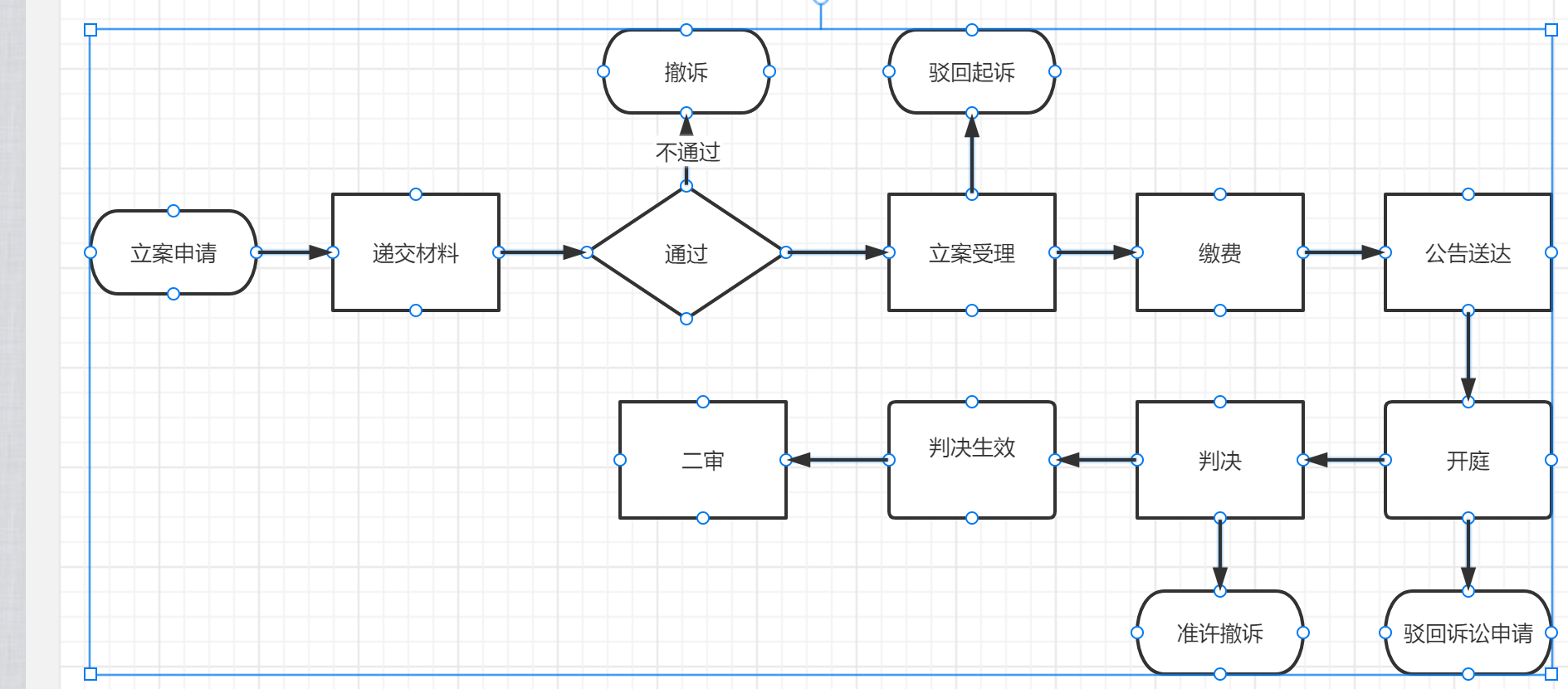
这是一套简单的诉讼流程,实际在作业中,我们需要明确,有哪些事件的发生是带有强关联性的,这在一定程度上能帮助我们对数据是否合理,是否真实进行校验,同样能对合作的三方机构、渠道的作业能力、作业方式有一定的了解。
在上述流程中,如果同时出现二审受理时间和驳回诉讼申请的反馈,可以说明在某一程度上数据是有问题的,同样的,有二审审理开始时间却没有一审结束时间同样是数据有可能产生问题的点。
按业务逻辑校验数据,除了能在流程数据校对中发现一定问题之外,还能通过这部分流程数据获取渠道不愿意同步的情况,尽量减少信息不对等的问题,减少我方损失,例如渠道在递交材料这个环节没有同法院沟通顺畅,就要求我方提供大批量同类型案件处置,却最终反馈撤诉的情况下,很有可能在最初渠道反馈的他们可合作的法院便是不接受这类案件,且无法处置的,这时候说明在前端商务沟通层面上,渠道反馈的作业信息是有误区的,这种误区会容易耗费大量的人力物力。
所以,数据在之前先做好稳定收集校验的工作,是能够稳定判断渠道的实际作业情况的。
当然,我们实际业务中碰上的问题便是没有先进行业务逻辑校准,便补充了看似准确的业务数据,这部分不符合业务逻辑规范的数据在系统强关联的操作步骤中无法正常体现,甚至导致历史数据迁移的时候报错,无法导入,这时候就需要数据组校准逻辑之后对核准判断并清0从业务数据体系建立的逻辑层面上关注,就需要一开始从部门业务起始到最末端的数据回流收集,需要根据实际业务建立一套完整规范的数据收集体系,规定在某个时间节点获取某些指标数据,这样也利于从一开始摸清实际业务中会出现的问题类型,以渠道准入为例:
有大量商务人员在前期渠道准入的获取的渠道信息是没有实际同步实际运营人员的,在渠道准入之后有大量的实际对接工作在就会落在后端运营人员这,同样的,渠道方也会更换实际的运营沟通人员,大量的前期对接工作在运营人员未知的时候业务就流转到了下一个节点,如果对各个部分人员权限管理的再严格一点,很可能出现运营人员连实际的合作协议签署都还没确定的情况下就被业务推动着不停往前走,不停沟通合作尝试。
最后发现渠道甚至合作协议的签署,合作模式都不是很清晰,这种情况在这种0-1的创业公司、创业部门非常常见,实际业务需求推动过于紧张,但实际业务逻辑、运营逻辑的搭建被远远落在后面。
二、数据自由度
数据自由度在实际业务场景下应当被定义为实际数据操作人员的数据规范化操作,就以简单的数据清洗补充为例,在线下的业务流程中,会有大量的数据以表格的形式在线下本地存储,需要把这部分数据以规范化的逻辑、格式上传至系统留存,才能汇总所有人的数据记录,在数据没统一上线系统之前,甚至“需求表-排期表-跟进表”三个不同功能作用的工作表的数据、文本都可能产生差距,就比方说需求表内法院信息补充为“厦门市集美区法院”,在实际排期表、跟进表中存储的法院信息为“福建省厦门市集美区人民法院”,这部分信息在系统的留存可能只能以一个标准字段的形式存储,用于代表用户的所生成的用户ID假设包含英文的大小写,同样要规范以统一的大写/小写的形式作为留存
举个例子,碰上底层如果对大小写敏感的JAVA、C++等语言撰写,同一个用户如果存储方式是“A”和“a”是完全不一致的,在甚至身份证号中的“X”和“x”都会被识别为两个用户,这样的数据不规范会在很大程度上影响数据的清洁程度,进而影响业务数据分析等方面;
一方面来说,数据自由在某种程度上确实很爽,可以以任何形式(CODE码,文字、数据等)留存关键数据,在业务流转过程中会很快乐,工作很迅速,如果这部分数据只是做无检验留存,在数据上传的时候甚至不会做任何校验,这样的数据在实际导入系统,做分析使用的时候都会产生比较大的问题。
在所有的线下业务中都可能会发生类似的情况,对数据自由度进行一定规范话,需要对所有要留存的数据设计留存格式、留存方式,在数据库中的更新模式(只允许新增数据/只允许覆盖数据),在规范化的操作下,才能保证部门内每个人的每一项线下工作都能按一定的逻辑交付,不会存在数据工作存在断档,同事无法接手、合作的情况。
三、底层数据表逻辑设计
任何系统都需要在底层设计数据存储的表格形式,而每张实际存储的表都需要有主键作为唯一识别,根据不同维度的表格实现表于表之间的连接
我们以消费金融逾期资产处置为例,对于任何一种逾期资产处置的手段(电话催收、人民调解、法院调解、律所调解、诉讼等)来看,所有的处置手段的作用逻辑均在用户上,而单个用户下可能会存在多笔实际借款行为,单个用户在借款额度未用尽的情况下,多次操作借款,这样会在用户的维度下生成多笔借款记录,每一笔借款记录在最细的维度上都是以借款订单的账单维度展现的,而订单维度的借款行为构成了用户维度的行为。
在逾期资产处置上,又是以多个用户绑定的方式推送给渠道,渠道对不同的用户下多笔借款行为实际跟进处置,所有的处置逻辑是一层一层挂钩的,这种层层嵌套的数据结构,需要在实际操作的业务流程中,根据不同的业务流程中的主要展示表,去做表之间的不同关联形式,以下是各个维度的底层表可能会涉及的字段:

可以看到,每个维度所要收集、展示的字段很多时间不太能在统一的数据底层数据库中获取,且各个维度的数据之间是以主键的方式去层层递进的,账单—订单—用户—批次,依据主键进行关联,这样的关联模式能较好的完成各个表结构之间的搭建,让同一个维度的字段仅保留在同个维度的表中,这种模式的拆分也能让数据之间打破数据孤岛,实现关联。
这种表之间的逻辑关联设计,让实际业务系统中可以实现多模式的临时表,数据仅在被需要的事件节点被提出计算,在无需留存的事件节点会被剔除,这样的临时表搭建方式会减少系统实际占用的服务器性能,在快速响应方面也能支持不同权限的个体同时进行线上操作。
业务数据底层的搭建,最好是根据实际业务的逻辑拆分不同的表结构,根据业务操作人员可能会涉及的颗粒度去展示不同的逻辑层级,最后搭建起实际业务数据体系。
四、系统业务逻辑搭建
在系统底层数据搭建好之后,需要设计上层的业务操作逻辑,所有的业务操作逻辑都需要提前设定好整个系统可能会涉及的权限分配,根据不同的业务权限进行拆分,举个例子,仍是以上面四个表的维度进行拆分,在逾期资产的处置中,人民调解员可以根据自己被分配到的用户进行操作,根据实际自己分配到的权限进行操作,通过权限对系统功能各个模块进行拆分,能够通过权限功能的拆分,实现多人同时操作,避免多人同时操作对系统查询造成大量负担,但这种根据业务拆分系统的权限,就需要实际业务流程、逻辑完善搭建之后才能完善,根据不同部门的业务模式才能正常操作,这就是因人而异了。
五、写在最后
对于现阶段很多线上业务而言,重要的是线上前端业务的发展,对后端的关注度其实都没有那么高,以互联网消费金融为例,在前端的用户画像、用户行为分析,其实已经做到了比较优异的状态,但后端逾期资产处置的方面,却被极大的忽略了,大量的后端处置风控数据没法按合适的逻辑回传前端,在逾期资产处置方面,有一些资产在还未进入处置之前就已经被定义为“坏账”、“不良资产”,甚至不被考虑回收,这部分资产都是直接被定义在“无法处置”,不被纳入资产回收的考量范围,在这种程度上实际如果把这部分“坏账”跟进回收,是能够成为公司账面上的关键现金流的,这对消金公司有着非常大的意义。
此外,大量后端处置数据回传,能够帮助前端风控完善逾期用户行为链路,确定各类型行为发生的触发机制,这对本来就难以完全实现的快速风控有积极意义,也是希望大家能更关注各个行业后端的业务,完成整体业务逻辑闭环的搭建。
作者:Logan_RRRC,公众号: Logan的运营学习日记
本文由 @Logan_RRRC 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


