
 起点课堂会员权益
起点课堂会员权益六大环节,教你如何从 0 到 1 搭建一场 A/B 测试
随着“增长黑客”概念的盛行,A/B 测试作为“数据驱动增长”的最佳实践受到了国内外众多公司的青睐。许多童鞋想要了解A/B测试却不知该从何处下手,本文作者基于A/B测试的六大环节,与大家分享小白入门A/B测试指南。推荐对此感兴趣的童鞋阅读分享~

随着“增长黑客”概念的盛行,A/B 测试作为“数据驱动增长”的最佳实践受到了国内外众多公司的青睐。
A/B 测试的目的在于通过科学的试验设计、高效精准的流量分割算法来获取具有代表性的试验结论,并将该结论推广运用至全部流量。目前,A/B 测试已广泛运用于产品交互设计、推荐算法、运营策略制定等方方面面,在最优方案的判断与决策过程中为公司提供有力的数据支持。
因为市面上对于 A/B 测试搭建的信息都比较碎片化,没有成体系化的梳理,且缺少标准化、规范化的 A/B 测试工具,所以,我们结合数百场 A/B 测试的服务及交付经验,总结、沉淀出了建立假设、确定评价指标、设计试验、运行试验并获取数据、结果分析、最终决策六大环节,帮助企业顺利落地 A/B 测试,为客户带来价值。

一、建立假设
A/B 测试最核心的原理是假设检验。先假设,然后根据数据检验试验组和对照组的结果,辅助决策。一般情况下,假设成对出现,如果我们认为试验组和对照组的结果没有显著差异,那么可以称为零假设(H0);相反,则称为备择假设(H1)。
在试验前,我们需要先明确想要实现的结果。比如,我们希望通过优化注册流程,提高用户的注册转化率。针对这个场景,零假设就是优化后流程(试验组)和优化前流程(对照组)的用户注册转化率无显著差异,备择假设则是两组结果有显著差异。
另外,在建立假设的过程中,需要注意两点:第一,A/B 测试本身属于因果推断,所以要先确定原因和结果;第二,假设必须是可衡量
的,需要有相应的评价指标来检验假设是否成立。
二、确定评价指标
注册流程优化的试验目的是为了提高注册转化率,那么注册转化率就可以作为检验假设是否成立的评价指标。同时,评价指标也需要分层级,确定唯一核心指标,辅助多个观察指标,才能从尽可能多的角度来评估试验结果。
评价指标主要分为三类:核心指标、驱动指标和护栏指标。
1. 核心指标
核心数据指标通常情况下只有一个,或者是极少数指标的合集,很多时候是一家公司或组织的核心 KPI,可以驱动业务核心价值,比如注册转化率(衡量注册流程优化试验效果)、活动按钮点击率(评估某项推广活动试验的 CTR 效果)、人均使用时长(评估某项推荐算法对用户粘性的改进效果)等。
在确定核心指标时,需要满足两个关键原则:第一,简单的,易理解的,可以在公司/团队范围内被广泛接受;第二,相对稳定的,无需频繁为了一个新功能更新核心指标。
核心指标除了用来衡量试验的效果,还可以用来计算试验所需的样本量(将在后文中详细介绍),由此可见,核心指标直接关系着试验的成败,需要重点关注。
2. 驱动指标
驱动指标一般比核心指标更短期,变化更快也更灵敏,帮助我们更加快速、全面地观测业务变化。我们可以通过两个案例做进一步了解:
在某项商品推广活动试验中,核心指标是下单转化率,运营同学可以使用客单价、人均下单次数、退货率等作为驱动指标。观察发现,虽然下单率有所提升,但退货率或客单价指标下降,此时便需要做针对性调整。
某个视频推荐列表试验中,核心指标是人均播放视频数量,驱动指标是完播率、人均观看时长,通过核心指标和多个驱动指标的配合来进行推荐算法效果的评估。
通过以上我们可以看出,驱动指标能够帮助我们从更多、更全面的角度来观察试验给业务带来的影响,尤其是当发现问题时,能够帮助我们及时分析原因、调整策略,通过不断优化达到最终的试验目的。
在确定驱动指标时,需要满足三个原则:第一,驱动指标与核心指标的目标一致,能够直接反映业务变化;第二,当指标发生变化时,能够有既定的途径和方法来优化指标,是可行动、与业务相关的;第三,驱动指标是核心指标的先导指数,需要具备足够的灵敏性,快速衡量大部分试验的效果。
3. 护栏指标
护栏指标,可以理解为保护业务的指标,在实际应用过程中,护栏指标的异常可以有效反映出试验设计、基础设施、数据处理环节是否正常,能够帮助我们在评价试验效果时做出正确的权衡取舍,避免因为短期指标优化影响长期指标,从而得出值得信任的试验结果。
举个例子,我们在试验中设置一定的比例让用户命中试验分组(通常建议各组流量平均分配),实际运行中如果发现样本量和构建时的预期不一致,那么可以猜测是否是分流服务出了问题,导致可信度降低。
三、设计试验
在确定试验评价指标之后,我们就可以开始进行试验设计,主要分为四个阶段:
1. 选择正确的试验主体
试验主体是试验中进行分流的随机化单元,在试验时需确保分流主体与评价指标分析主体相同。
用户(通常为 user_id )是当前主流的随机化单元。如果分流主体是用户,那指标分析主体也应该是用户,例如人均会话数、人均点击量、人均支付金额等。
在实际业务场景中,可能使用其他分流主体,比如设备主体(device_id),按照设备进行随机化,意味着每台设备产生的指标数据是独立的,比如在点餐机或者自动售卖机(一般为 Android 系统)的试验场景中,不需要用户进行登录即可下单购买,那么此时试验的分流主体和分析主体就是这个独立设备,可以用每台设备的平均下单时长(完成下单的总时长/独立设备数)作为评价指标,用来衡量下单页优化效果。
除了以上两个常用的试验主体外,也会存在其他主体,例如在推荐算法试验中,可以用推荐的页面(或推荐的商品)作为试验主体单位等,在评估选择使用哪种随机化单元(分流主体)时,需要结合具体试验场景来考虑,可以重点从用户体验一致性、分流主体和评价指标主体一致性两个角度综合评估。
2. 确定试验目标受众
当我们假设了一个试验并选定试验主体时,需要进一步明确试验的受众范围,也就是说需要明确哪些用户参与到试验中。通常有完全随机和定向筛选两种方式:
- 完全随机,是指不做任何干预,所有的线上用户都是目标受众。
- 定向筛选,是以特定的用户群体为目标。比如,某在线教育 App 的会员活动试验中,想要通过不同活动来探索和提升用户的购买转化,便将新用户设定为目标群体。
需要注意的是,当使用定向筛选圈定受众意味着当前的试验效果只对这部分用户有效,并不能代表线上全量用户应用后都具备相同显著的效果。因此,在实验结束将新 Feature 固化到线上时,需要考虑有针对性的发布策略。
3. 确定试验样本量
(1)样本量并非越多越好
我们都知道试验的样本量大小对结果的精确度有直接影响,从统计学理论来讲,越大的样本量意味着有更大的几率检测出很小的变化,得出的结论信度就越高。
但在实际业务场景中,当我们回收到优胜方案时应尽快发布给全量用户,这样才能扩大试验效果、实现业务的全面增长。另一方面,虽然 A/B 测试的目标是验证某个优化方案能够提升收入指标、改善用户体验,但试验总会伴随着未知、未被考虑到的风险,就有可能出现与假设截然相反的结果。因此,快速分析定位原因,及时调整试验就显得尤为重要,“快”是A/B 测试的重要优势,能够快速应用、扩大收益;快速得出结论驱动决策等。
在进行试验设计时,我们需要在实际业务场景和统计理论中做到平衡:既要保证足够的样本量,又要把试验控制在尽可能短的时间内。
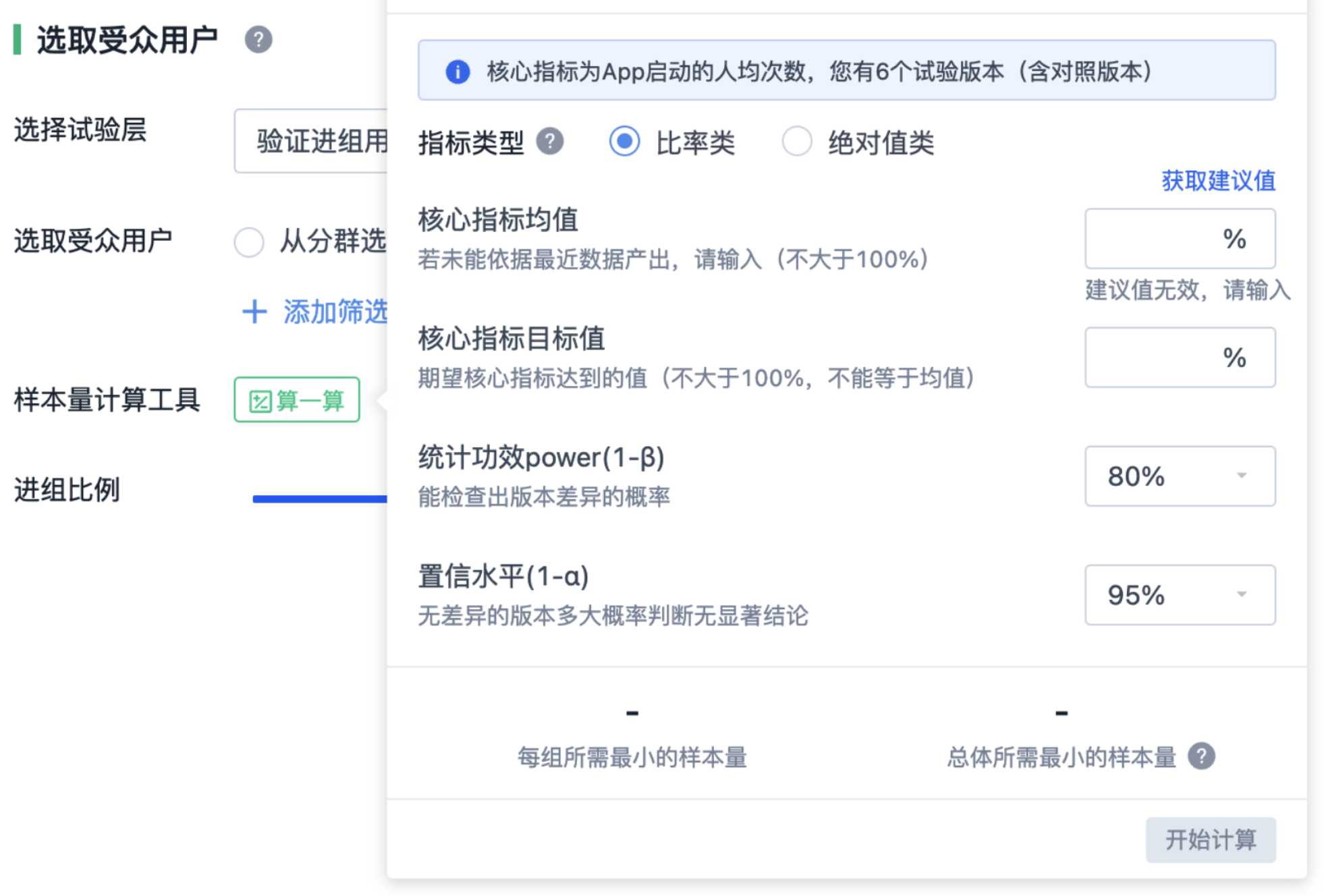
(2)如何确定试验所需的最小样本量
样本量并不是越多越好,那么该如何确定样本的数量呢?这里我们需要了解一下中心极限定理,通俗地理解为:只要样本量足够大,无论是什么指标,无论对应的指标是如何分布的,样本的均值分布都会趋于正态分布。基于正态分布,我们才能计算出相应的样本量,作出假设与检验。
样本量计算背后的统计学逻辑较为复杂,计算公式如下:

从公式中我们可以看出,样本量主要由 α、Power、△ 和 σ^2 四个因素决定,当确定了这几个变量,也就确定了试验所需的样本量。相关统计原理详见文末「补充阅读」。[1]
目前市面上有很多样本量计算工具,其背后的统计逻辑基本一致,这里需要提醒大家的是,大部分工具都只能计算比率类指标,而均值类(绝对值类)指标的计算需要用到历史数据,通常只能利用公式来进行计算。
4. 确定试验运行时长
只要试验结果显著,并且符合最小样本量,是否就可以停止试验了呢?答案是否定的。除了最小样本量之外,我们还需要考虑试验指标的周期性波动以及新奇效应影响。
(1)周期性
在实际业务运行过程中,往往需要考虑周期性带来的指标变化。比如,旅游行业在周末的用户访问量明显高于工作日;而办公软件的各项指标都证明在节假日的使用频率远低于工作日。因此,当需要考察的指标自身带有周期性特征时,那么在试验中就必须要考虑到周期性影响,不能单纯地根据结果显著性来做决策。我们通常会建议客户在合理的试验时间内至少包含一个完整的数据波动周期。
(2)新奇效应
在试验的初始阶段,可能会产生一些明显的效应,并在接下来的一段时间内趋于稳定。原因在于刚上线新策略时用户的兴趣值较高,从而引发新奇效应;随着时间推进,用户的新奇感会逐渐消失。所以,在做 A/B 测试时,我们需要评估引入的新策略能否引发新奇效应,从而判断当获得显著结果时,是否需要延长试验周期以得到稳定的结果。
四、运行试验并获取数据
虽然试验上线前我们已经做了充分的测试工作,但仍需要验证试验是否按照预期的设定正常运行。其中以下两项工作需要重点验证:
- 分流验证:分流比例和预期设定是否一致,不同分组策略是否正常展示,用户有无跳版本等。
- 数据验证:缺少有效、准备好的评估数据,再多的试验也是徒劳。
在确保试验正常运行的情况下,我们还需要对不同分组的数据进行观察分析,避免因为设计缺陷或者引入功能 bug,造成重大业务损失。
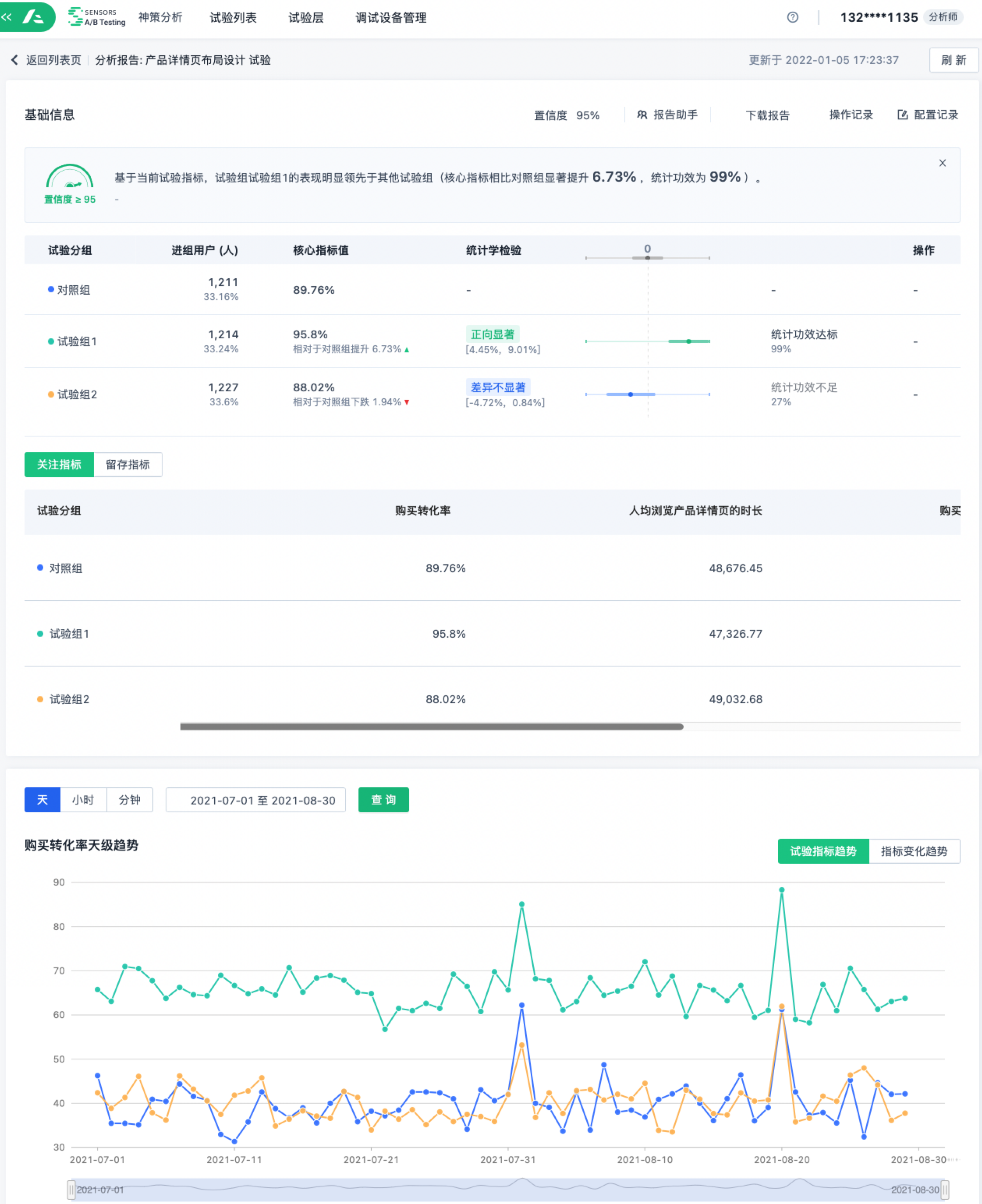
五、结果分析
A/B 测试能够高效驱动决策。在统计学中,会采用 P 值法和置信区间法评估结果显著性,这里我们详细介绍一下使用频率较高的置信区间法。
置信区间是一个范围,最常见的是 95% 的置信区间。如何理解呢?对于一个随机变量来说,95% 的概率包含总体均值的范围,就叫做 95% 的置信区间。也可以简单理解为总体数据有 95% 的可能性在这个范围内。
在 A/B 测试中,我们会计算两组指标的差异值,如果计算得出的差异值置信区间不含 0,那么就可以拒绝零假设,认为两组结果差异显著;反之则接受零假设,认为两组结果差异不显著。
六、数据驱动决策
运行 A/B 测试的终极目的为了提升业务指标。那么在收集试验数据到最终决策的过程中需要考虑哪些因素呢?
- 试验结果差异是否真实可信,是否具备统计显著性?
- 统计功效是否充足(通常根据是否大于 80% 来判定)?
- 试验放量之后会带来哪些风险,风险处理的预备方案是什么?
显著结果往往比较容易判断,可以通过增加统计功效来提升真实显著的几率。但对于一些差异不显著的试验,就需要在试验方案中做出取舍,我们需要明确决策对未来可能产生的影响,并让影响尽量控制在可预测的范围内,而非局限于根据某个单一指标来进行决策。
以上是一个完整 A/B 测试流程,后续我们将结合具体业务案例,深入探索试验各个环节,敬请期待!
补充阅读:
[1] 试验样本预估指南:https://manual.sensorsdata.cn/abtesting/latest/abtesting_SampleSize-58327106.html
作者:李世强,神策数据产品经理
本文由 @神策数据 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议。










您这假设检验都用上。。。小白不一定看得懂啊
学废了学废了,让我再仔细瞅瞅
原本复杂的测试说得挺好的,发现仔细读下来还是很多不懂,收藏了得空时再仔细瞧瞧