
 起点课堂会员权益
起点课堂会员权益聊聊A/B实验那些事儿
编辑导语:作为一个大部分业务都依赖的重要引擎,在实际使用过程中却发现会遇到各种各样的问题。这篇文章详细介绍了数据驱动的核心引擎——A/B实验,分别从过程、节奏以及结果进行阐述,推荐想要了解A/B实验的童鞋阅读。

A/B实验是数据驱动的核心引擎,目前大部分业务都依赖它进行决策,但在实际运行过程中会遇到各种各样问题。
下面让我一起聊聊A/B实验那些事儿。
一、AB实验设计过程
首先聊聊实验设计过程,实验设计过程包含4个核心问题:
问题1:随机分桶单元是什么?
大部分随机分桶是按用户维度,用户维度有登录id、设备id、匿名用户id(cookie),除cookie在时间纵向上不稳定,登录id和设备id均是长期稳定的。
分桶方法:目前有很多A/B实验平台都可以支持分桶,主要通过设备id和层级id使用Hash函数进行分桶,同样也存在按尾号分桶情况,若是尾号分桶需要考虑各个尾号样本数据是否均衡,例如是否会存在某个尾号经常做实验,造成样本不均衡。
问题2:我们的目标群体是什么?
思考实验的目标群体是什么,实验的背景和目标是什么,是实验设计的核心问题,若实验是一个以特定群体为目标意味着你只想对具有某一特征下的特定用户运行实验,那么触发条件变得尤为重要,因实验触发条件不同可能会导致幸存者偏差等各类问题,从而导致实验结果不可信。
问题3:实验需要多大的样本量?
实验需要多大样本量,涉及到实验功效是否充足情况,对结果的精确度有直接影响。样本量越大,样本的功效越好,实验结果越可信,但同时耗费的资源也越多,如果样本量太小,实验功效不足,结果不可信,那么如何计算最小样本量,可以参考下面公式:
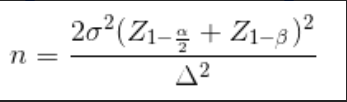

问题4:实验需要运行多久?
对于线上实验,用户随之时间进入实验,时间越长,用户数越多,统计功效通常也会随之提高,考虑到用户会反复访问,用户随时间的累计可能是次线性的,即第1天来N人,第2天累计进入实验用户<2N,所以实验运行仅运行1天,则更侧重在高频活跃用户。
同样因周末与工作日用户群体不同,也会有周末效应,季节性也同理。
有些实验在初始阶段有较大或较小的新奇效应,也会影响数据指标,因此建议实验至少运行一周。
二、A/B实验放量节奏
通过逐步放量的流程来控制新功能发布带来的未知风险是很普遍的,我们需要衡量速度、质量和风险。
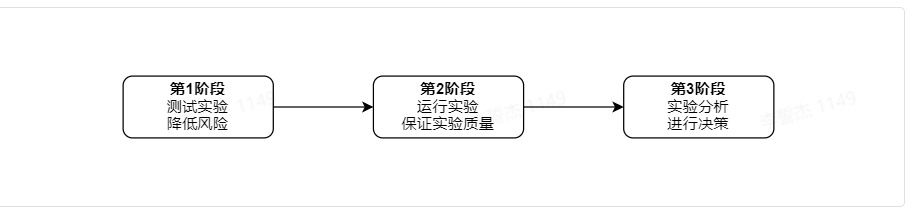
第一阶段目标降低风险:可以建立测试人群,测试实验运行风险,观察实时或近实时结果,尽早了解实验是否有风险,如遇问题可快速回滚。
第二阶段目标保证实验质量,我们建议最后保持一周,如有初始或新奇效应,则需要更长时间,若仅运行一天的实验,其结果将倾向于重度用户,根据经验,如果没有发现初始或新奇效应,则一周之后每多运行一天带来的额外收益都会越来越小。
第三阶段目标通过实验进行决策,通过分析实验核心指标,确定实验是全量或者放弃。
若实验期间提前达到统计显著,根据经验,是不建议提前全量,通常使用的统计学假设是在实验结束时进行统计测试,而提前提前结束实验违反了假设,会导致一些虚假的成功。
三、A/B实验结果分析
陷阱1:样本量不均衡
实验分析第一步检验实验组与对照组样本是否均衡,实验组UV/对照组UV=1代表均衡,如果实验组和对照组样本量不均衡,那可能在实验阶段发生漏洞导致的,那么我们不应该相信任何其他指标。产生样本量不均衡有多种原因,主要是以下原因:
- 浏览器跳转,一种常见的ab实验机制是实验组跳转到另一个页面,这通常会导致样本比率不均衡,主要原因:a、性能差异:实验组用户需要接受额外的跳转,跳转过程性能可能快可能慢。b、跳转不对称:实验组跳转新页面后,可以进行收藏、转发、返回等各种动作,而对照组均没有;所以对照组和实验组都需要有跳转页面,让实验组和对照组有相同待遇。
- 残留或滞留效应,新的实验通常会涉及新的代码,所以错误率会比较高,新实验会引发一些意想不到的问题导致实验中止并快速修复上线,重新随机化会打破用户的连贯性,会让用户从一个用户组转到另一个用户组,从而影响样本均衡。
- 用户随机分桶过程有漏洞,有可能在放量过程中出现bug导致实验组和对照组样本不均衡
- 糟糕的触发条件,触发条件应该包含任何可能被影响的用户,触发条件基于可能被实验影响的属性也会让实验样本不均衡
那如何识别样本不均衡呢?
- 验证分桶时机点或触发时机点的上游有没有差异;
- 验证实验样本的分桶设置是否正确;
- 顺着数据漏斗路径排查是否有任何环节导致样本不均衡;
- 查看用户细分群体样本比例
- 查看与其他实验的交集
陷阱2:分析单元不一样
在分析页面跳转时,有个核心指标CTR,CTR有两种常见计算方法,二者的分析单元是不一样的。
第一种CTR1=总点击数/总曝光数。
第二种CTR2,先计算每个用户的CTR然后平均所有用户的CTR。
如果随机分桶单元是用户层面,那么第一种方法使用了一个与分桶单元不同的分析样本,违背独立性假设,并且让方差计算变得复杂。
例如下面例子,有1W用户,假设每1K人有相同曝光和点击, CTR1=7.4%,CTR2=30.4%,显然CTR1受到了离群点影响。

这两种定义没有对错之分,都是CTR的有用定义。但使用不同的定义会得到不同的结果。一般两个指标都会做成看板。
陷阱3:稀释效应陷阱
计算对触发人群的实验效应时,需要将效应稀释到整个用户群,如果在10%的用户上增加3%的收入,那么整体收入是否将提升10%*3%=0.3%?一般并没有,总体效应可能是0–>3%之间任意值!
如果改动针对站用户总体10%的低花费人群(花费为普通用户的10%),且该改动将这部分用户的营收提高3%,那么对整体营收将提高=3%*10%*10%=0.03%。

陷阱4:样本间信息干扰
我们假设实验中每一个实验个体是独立的,不会相互影响,但用户个体会因为社交网络,对同一内容的互动信息等导致相互影响。
例如对社交类app有个策略“你可能认识的人”这个功能,实验组更好的推荐策略,会促使用户发送更多的邀请。然而接收到这些邀请的用户可能在对照组,如果评估指标是总邀请量,那么实验组和对照组的邀请都会增加,因此测量出来的实验组和对照组的差异会偏小。同样一个人可能认识的人是有限的,因此新算法在一开始可能会表现更好,但由于供推荐的供应量限制,长期来看可能会达到较低的均衡。
那要如何应对上述问题呢,首先不是所有用户行为都会出现网络效应,我们可以界定特殊行为会造成影响,只有这些行为被影响时,我们观察特殊行为是否影响下游的指标,同时重点分析该行为带来的生态价值,根据行为对生态系统的价值和贡献来考量最终决策。
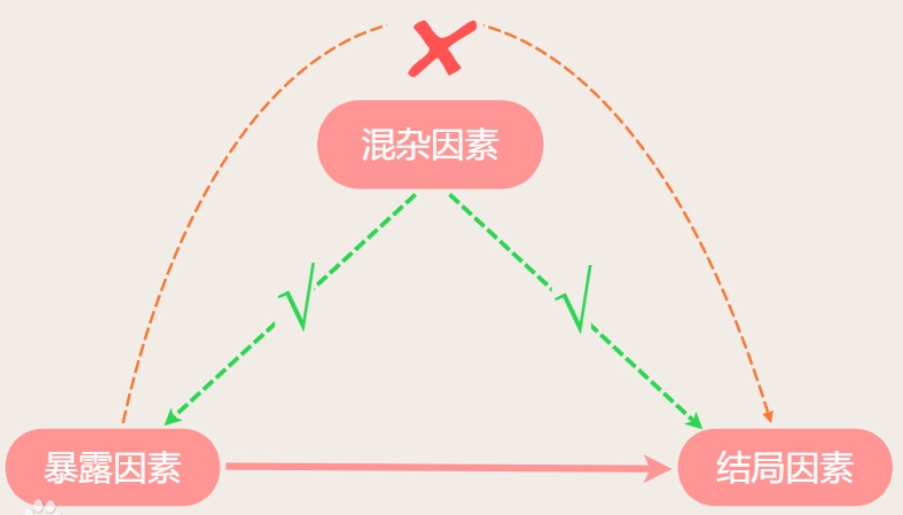
陷阱5:混杂因素误导
混杂因素是指与研究因素(暴露因素)和研究结果(结局因素)均有关、若在比较的人群组中分布不匀,可以歪曲(掩盖或夸大)暴露因素与结局因素的真正联系的因素。
例如:很多产品有一个现象:看到更多错误的用户通常更少流失!
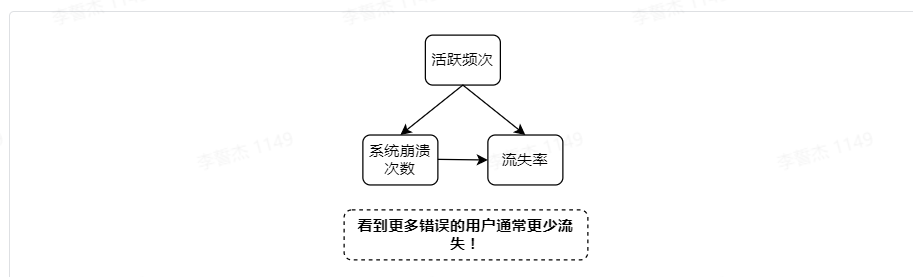
所以,可以尝试显示更多的错误以启迪可以减少用户流失吗?当然是不可以,这种相关性是由一个共同愿意造成的:使用度。重度用户会看到更多错误,同时流失率更低。
如果发现某个新功能可以减少用户流失,需要分析是新功能在起作用,还是因为高活跃用户流失率低,同时更可能使用更多功能?
这种实验就要拆分活跃度进行实验。AB实验是需要控制变量的,但控制的东西过多了,实验变得束手束脚,具体控制哪些变量是非常值得思考的,有时候最终控制你真正想要测量的东西,那样功亏一篑。
有些时候实验结果给不了清晰的答案,但仍然要做出决策。对于这种情况,我们需要明确需要考虑的因素,尤其是这些因素如何影响实验显著和统计显著的边界设定。这些考虑会为为了决策提供基础,而非局限于当前的单一决策。
本文由@李誓杰 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议










写的很棒,很详细,也很专业,但是可能专业性太强了,作为行外人可能看不太懂
谢谢,主要是针对分析师,如有不懂可以深入交流