
 起点课堂会员权益
起点课堂会员权益从5W1H起入门风控系统设计
编辑导语:相信有很多小伙伴都想了解如何学习风控系统设计,这篇文章作者详细阐述了如何从5W1H起入门风控系统设计,内容通俗易懂,感兴趣的小伙伴一起来看看吧。

一、什么是风控
场景1:一位跟你从小玩到大,而且一直都有联系、有故事的好朋友,突然说家里有啥事,想问你借一笔钱,一想到好朋友有困难,你可能会当仁不让的出手相助,甚至什么时候还都没问,就把钱借出去了。
场景2:某天你突然接到一个,来自十余年没回过的老家的陌生号码的电话,电话那头,是一副你完全陌生的嗓音,搭配咄咄逼人的语气,说道:xxx啊,我是你小学同学某某某,我现在很缺钱,想要借五千块钱。但是你想了一会儿,可能都记不起这个同学的模样,甚至怀疑到底有没有这个同学。此时你大概率会认为是诈骗电话,臭骂骗子一通,然后把电话挂了。
在这些很常见的场景中,我们其实就完成了一次又一次完整的风控过程:
- 画像分析与风险评估:通过对借款人的背景信息评估,好朋友的往事信手拈来,家庭背景、偿还能力、近况都很清晰,风险系数低;默认的同学,背景信息缺乏、近况完全未知、偿还能力未知,风险系数极高。
- 风险措施:风险系数低的朋友,放款快、额度高、还款周期宽松;风险系数高的同学,要是再来电话,得问清楚家庭关系、地址、原因、目前从事的工作类型、工作单位及地点等信息,就算有别的认识的同学担保,也要打个借条明确还款时间、逾期惩罚,如果哪点做不到或者内容含糊不清,一概拒绝借钱。
风险控制的目的:就是在自我利益最大化的前提下,采用各种举措,减少风险事件的发生,或者减少风险造成的损失。
二、风控第一步:明确利益
风控的前提是,保障自己的利益,如果不需要保障自己的利益,那也就没必要风控了,就像电影《西虹市首富》,王多鱼的投资策略就是,投资的事情最好越离谱越好,无偿的为大家的梦想买单,这种情况下,风控就完全多余的。
但现实生活中,一个系统、一款产品,都需要考虑风控这件事了,那必然是出于某个目的、某种利益驱动的。免费的APP希望屏蔽爬虫,节省服务器流量;收费的APP希望屏蔽羊毛党,减少损失、增加利润……
明确风控的目的,是设计风控系统的第一要务,现在我们有个系统,用户通过在指定地点签到完成任务,累计一定数量,就可以兑换奖励,那我们风控的目的,是不想奖励给那些作弊的人,把奖励真正给到那些真实完成任务的人,从而激励大家更积极、认真的参与任务。
- 明确目的:减少奖励损失、让奖励给到真正参与的人
- 采取手段:找到作弊者,然后拒绝发放奖励,对此作弊甚至直接拉黑处理
- 前提条件:如何找到作弊者呢?尽可能的减少人工审核投入,希望根据收集的大数据,建立数据模型,找出最可能有作弊嫌疑的用户,再进行人工复核。
再例如最常见的借贷APP,他们是对风控系统依赖、专研最多的行业之一。
- 明确目的:把钱结给能还得起、且愿意还钱的人,从而保障本金成本少流失、利息收益最大化。
- 采取手段:鉴别贷款者的还款功能,对于还款能力低的人,授予额度低甚至不授予额度
- 前提条件:如何鉴别贷款者还款能力呢?根据收集的大数据、人行征信及其他第三方系统数据等,找出该用户的收入能力、消费能力、信用记录等,从而评估该用户:是否还得起、是否愿意还。
只有明确了需要风控系统介入的目的,才能更好的进行风控模型、风控举措的设计,从而让风控系统的价值最大化。
三、风控第二步:设计风险模型
风险模型用于评估风控对象对于风控目标的风险程度,那要如何构建风险模型呢?
首先我们要尽可能掌握风控对象可能与风控目标有关联的所有信息,然后评估这些信息的风险程度,不同的信息根据关联程度不一样,又会有不同的权重,最后加权计算就得出了风控对象的风险系数。
结合实际例子理解:现在有一款产品,运营会创建一系列的指定地点打卡有奖的任务,用户领取任务后,在对应地点完成打卡,即可获得一定的奖励。但是考虑到运营获得的地点信息不一定是准确的,所以签到地点允许有一定的距离误差。
1. 业务流程梳理
我们对用户获得奖励的行为路径进行梳理:

2. 数据整理
我们将每个阶段会产出的数据进行梳理:
- 注册:注册时间/时长、手机号码(引申出运营商、号码段、归属地等信息)、注册IP(引申出ip归属地)
- 浏览:近3天、7天、14天、1个月、3个月、1年活跃程度,包括看了哪些页面、访问频率、一般什么时候看、访问地点(通过ip地址分析)、访问的设备信息(引申出设备型号、设备号、APP版本等)
- 实名认证:姓名、性别、年龄、身份证号、户籍所在地
- 银行卡信息:卡号、卡户行、开户地
- 领取任务:任务类型、创建时间、创建人、任务时间、任务地点、任务热度(任务最大领取人数、任务已领取人数、任务PV/UV访问情况等)、任务奖励、领取时间、领取地点、领取设备等
- 打卡:打卡时间、打卡地点、照片质量、备注质量、打卡设备(手机型号、设备号、APP版本、IP地址、ip归属地)
- 奖励:已领取奖励、已提现奖励、领取次数、平均奖励金额、平均提取周期等
如果对这些数据,或其他业务流程中可以产出、依赖性强的数据没埋点采集的话,还需要先完善埋点,确保尽可能的把数据采集全面。
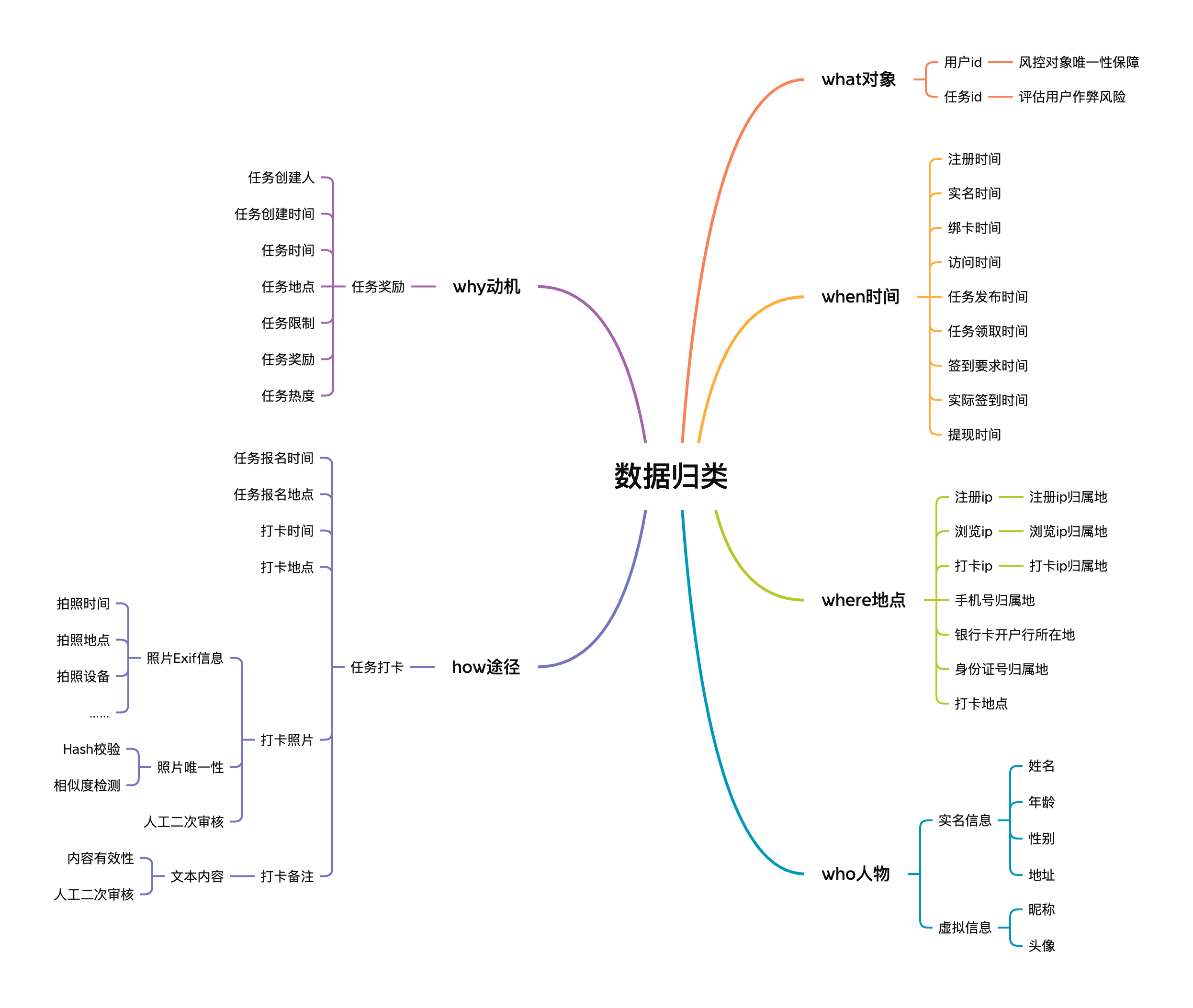
3. 数据归类
我们按照大名鼎鼎的5W1H对整个业务流程可以产出的数据做个归类。
5W+1H:是对选定的项目、工序或操作,都要从原因(何因Why)、对象(何事What)、地点(何地Where)、时间(何时When)、人员(何人Who)、方法(何法How)等六个方面提出问题进行思考。
4. 风险关联分析
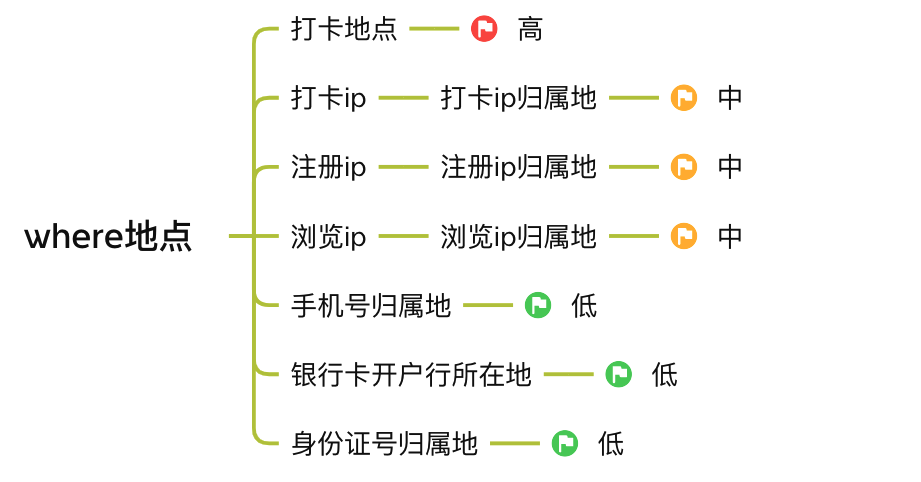
我们对所有掌握的数据进行归类后,可以将该数据与预期风险进行关联分析,例如我们有那么多的地址信息,由于我们业务的特殊性,一般都是同城内打卡,所以用户注册地、日常浏览的所在地、打卡地址,都应该在本市,且打卡地点不出意外的话,都应该距离设定的任务地址非常近。
诸如手机号归属地、银行卡开户地、身份证归属地,这三者可能不是在本地也正常,如在老家办的身份证、手机号、银行卡等,但是这三者应在省份层面,应该有一致性趋势,例如一个用户身份证是郴州的,银行卡是泉州开的,手机号是衢州的,最后在宿州参加任务打卡,这风险就很大了。
由于我们业务的特性,一个打卡任务从发布到要求打卡完成,都不会超过1个月,且每次奖励都不多(不到百元),所以浏览页面所在地点与实际打卡地点大概率应该是在一个城市,临近的城市都比较少,如果出现广东省浏览了一个山东省的任务,最后打卡点是山东省,这风险也极大。
所以我们就可以列一下每个数据与最终风险的关联系数。
5. 风险阈值设计
我们采用“可信度”计分,标记为s,单项最高100分,最低0分。如果一项数据可信度越高,则分数越高,相对而言风险程度就越低。
同时给每一项数据加一个权重值,标记为w,为方便计算,需要让w1+w2+…+wi=1,即所有权重相加等于100%。
最终可信度分数 = ∑ 单项分数s x 单项权重w,可信度模式,也被称之为健康分、健康度、信用分等。
(1)打卡地点,系数w假设为0.1
按要求就应该在任务要求的地点附近,我们采用经纬度距离计算的方式,判断风险度:
- d(距离)<=50米:可信度极高,单项+100
- 50米 <= d < 200米:+80
- 200米 <= d < 500米:+60
- 500米 <= d < 1000米:+40
- 1000米 <= d < 5000米:+20
- d >= 5000米:+0
(2)打卡ip归属地,系数w假设为0.02
打卡ip归属地其实并不准确,由于网络运营商问题或使用了虚拟专用网络(Virtual Private Network),可能出现“漂移”,不过ip作弊难度相对于修改地址而言更难,所以还是有很大的价值。
- 打卡ip归属地与打卡地点一致在同一个城市,可以增加打卡的可信度,单项+100
- 不一致,单项+0
(3)其他ip归属地,系数w假设为0.03
注册ip、浏览ip的归属地,和打卡ip有同样的准确性问题,但是我们可以用离散度来衡量,一般情况,我们预期的用户注册ip、浏览ip与实际打卡ip都应该是同一个城市的,所以我们可以取注册ip归属地、最近3天使用最多的ip地址归属地(需要占浏览记录的30%以上,如果没有则为空)、最近7天使用对多的ip地址归属地(需要占50%,如果没有则为空),与打卡地点进行比对:
- 其中0个同一个市:+0
- 其中1个同一个市:+30
- 其中2个同一个市:+60
- 其中3个同一个市:+100
采用同样的方法,我们可以对5W1H里面的每一项数据,都拟定一个权重、还有一套评分规则,就可以进行所有人员的风险评估了。
6. 模型测算
当我们梳理出所有风险相关的数据、拟定了权重、评分规则后,我们就完成了分析评估模型的初步设计,但是这个模型准不准,我们还需要进行测算。
我们会从系统中随机抽取一定数量的、包含了已知作弊记录在内的真实记录,然后使用模型规则,算出可信度分数,然后查看可信度分布情况:
- 已知的作弊记录,是否多数分布于可信度低的区域。如果不在,查明是哪个指标权重或计算规则导致的,调整对应指标权重、计算规则
- 其他可信度低,即风险高的记录,人工核实是否真的作弊了,或者具有高作弊嫌疑。
- 根据业务特征和运营经验,分析分数分布情况是否符合预期的分布特征,如正态分布,即极高风险的和极低风险的应该都在少数,大部分处于中间区间。
- 不断优化权重配置、计算规则、多抽样几批真实业务记录进行反复测算,提高模型的准确性
- 总结不同可信度分值的分布区间特点,对记录结果分类,如总分0-20为极危,20-40分为高危;40-60为低危;60-80为健康;80以上为优秀。
目前我们的模型是根据最终打卡记录来计算的,保障任务奖励的资金安全、发放给应得的用户。但是有时候我们可以会需要根据用户的历史记录,来评估对用户维度的可信度,用来在任务报名节点就过滤掉部分用户,这时候可能就要建立新的模型进行评估。
另外对于新用户,没有过多的数据时,可能就需要用更少的数据指标,来建立用户维度的可信度等。
四、风控第三步:风险模型应用
我们根据任务的奖励情况,任务奖励越多,那被刷、用户作弊的风险就越大,可能造成平台的损失就越大,所以对其打卡记录,根据可信度,采用不同的策略,以实现减少人力成本投入、提高安全系数的目的。
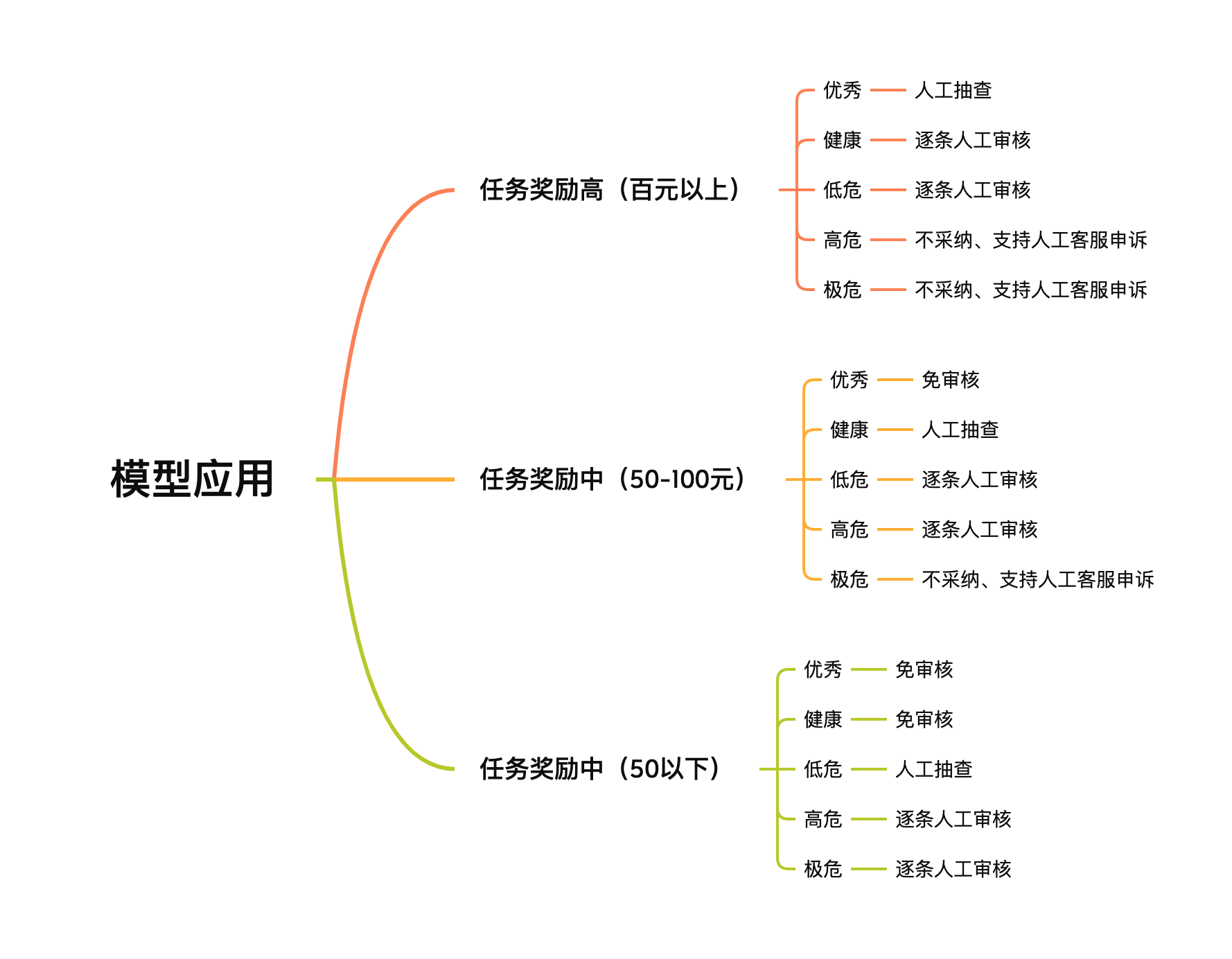
到此,我们就完成了风控系统的设计、应用全流程。但是风控模型不是一成不变的,是需要通过不断积累的技术、数据,不断迭代升级的:
- 随着业务场景的拓展、技术的不断更新,我们可能采集到更多维度的数据,用于升级风控模型;
- 那些“免审核”的优秀记录记录中,还是会隐藏着新的作弊手法、作弊风险,一旦被发现,我们也需要对风控模型进行更新,及时堵住漏洞,防止损失扩大;
- 通过与第三方安全公司、风控系统的合作,不断完善风控指标
五、总结
万丈高楼平地起,5W1H作为我们日常生活、工作中最实用的方法论之一,对于基础的风控模型设计也一样适用,通过一定的分类,把杂乱无章的线索整理归类,让其特征得以显现。
实际生产实践过程中,由于法律法规要求、用户体验需要等,可能还未必能采集到那么丰富的数据;另外所需要面对的业务,复杂度也可能高得多,很多风险隐患可能深藏于错综复杂的业务流中,不容易被察觉。此时我们就需要设计更复杂的风控模型,如通过灰色关联分析来设计权重、使用机器学习来识别风险等等,路漫漫其修远兮,吾将上下而求索。
#专栏作家#
iCheer,公众号:云主子,人人都是产品经理专栏作家。房地产/物业行业产品经理,Python编程爱好者,养猫发烧友。
本文原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议










陈总:你这废物写的都是什么狗屎,来公司就是骗吃骗喝骗钱的吗?你给我滚蛋
我旁边的那个小伙子就是参考的这个
5w的思路适合很多地方,作者分享的很详细!期待更新
哪些地方都用到5W1H,这么多的思维模型要多多学习,感谢作者