
 起点课堂会员权益
起点课堂会员权益智能座舱系列六:车载语音系统介绍
编辑导语:随着科技的进步,智能座舱技术也在不断地发展中,本篇文章作者系统地介绍了智能座舱的语言系统,从各个方面详细地介绍了其车载语音的功能介绍以及整体架构等,感兴趣的一起来看一下吧。

智能座舱有两大人工智能交互系统,一个基于视觉(计算机视觉)、一个基于语音。前者的应用体现在IMS系统,我之前的文章有过介绍;后者的应用在舱内的语音功能。这篇文章就系统地介绍智能座舱的语音系统(VOS)。
一、概述
VOS(语音操作系统)旨在为用户提供车内环境下的语音交互服务。 VOS系统系统采用了唤醒、语音识别、语义理解等技术实现语音控制。
座舱的车设车控、地图导航、音乐及多媒体应用、系统设置、空调等均可通过语音来操作。除了针对车身、车载的控制外,语音还支持天气查询、日程管理以及闲聊对话。
用户只要说唤醒词,即可使用。语音指令可以一步直达功能,既能解放手指,又无需视线偏移注视车机中控区域,从而保障行车安全。
二、总体架构
在总体的架构上,语音系统可分为四个模块。即车端系统、云端系统、语音运营管理平台以及训练和分析统计模块。整体的语音系统和要求,包括车端到云端链接、数据到功能的构建、Online的运营平台、线下线上的数据采集和标注。
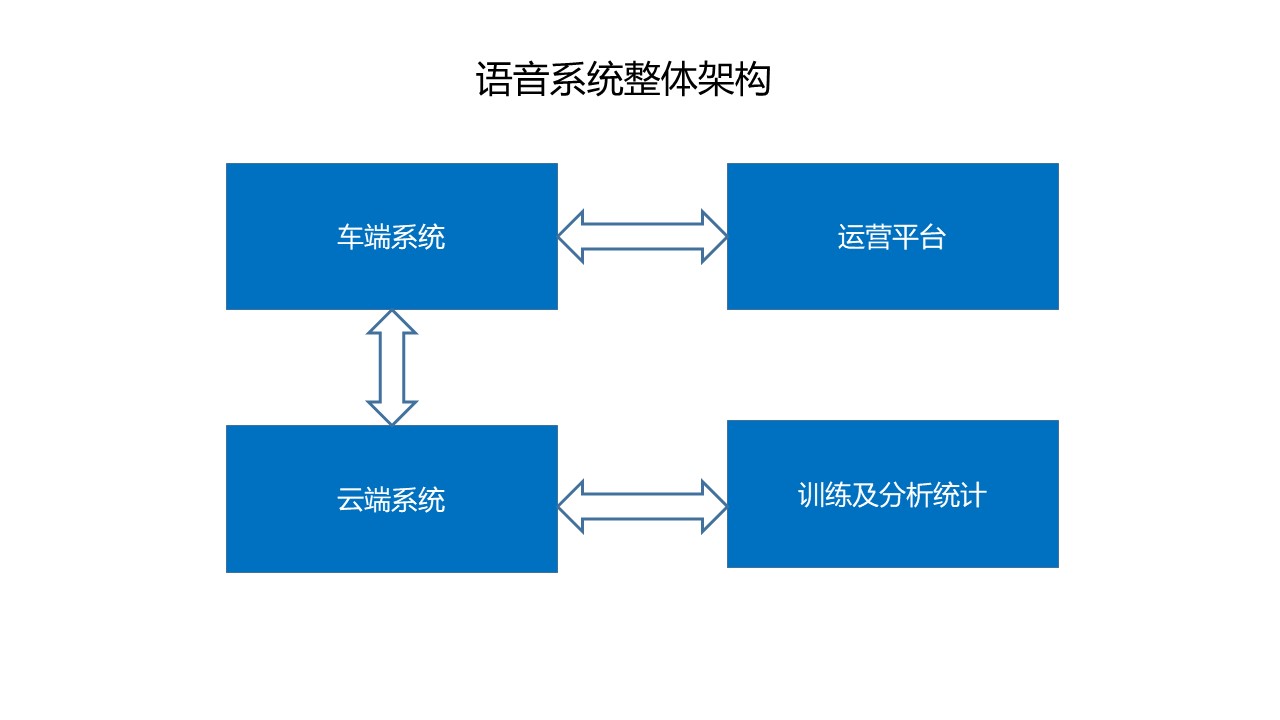
三、架构模块
1. VOS车端系统
车机端主要是对话系统(DS),也是用户感受最直观的,产品的重点侧向交互设计。
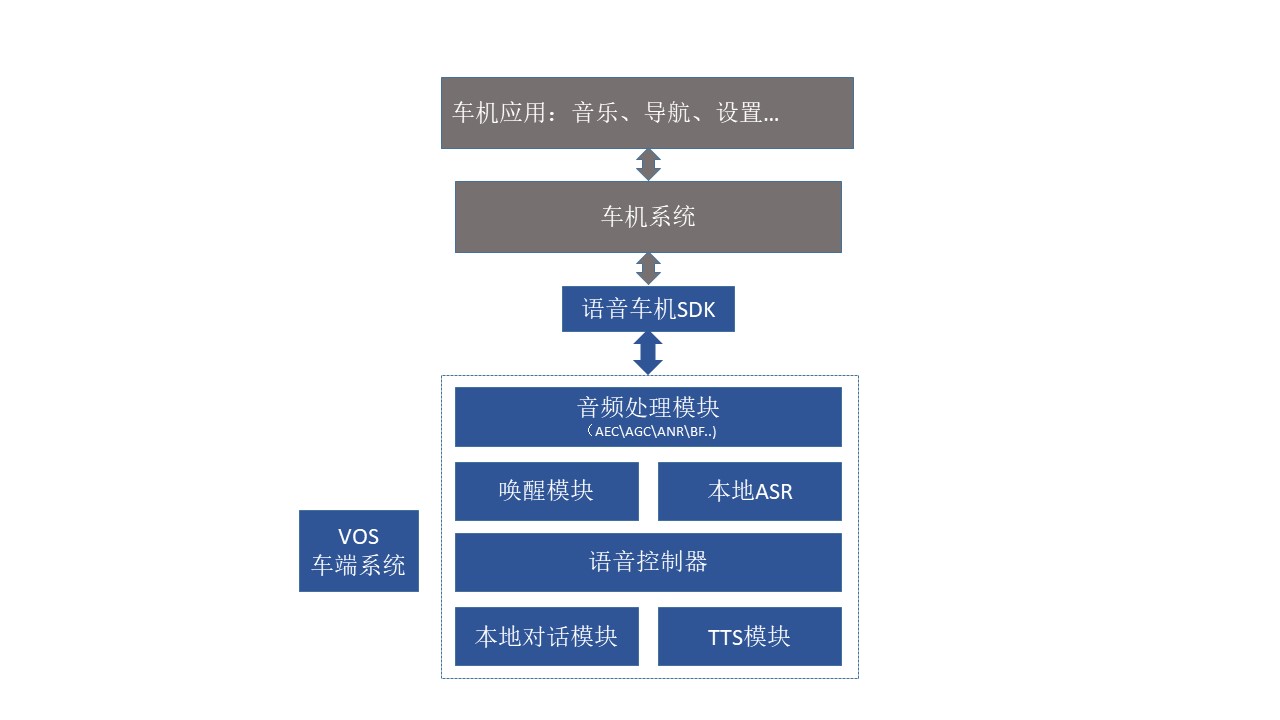
2. VOS车端模块
从上图可以看到,车机端由以下几个模块组成:
- 音频处理模块:AEC /AGC/ANR/ BF;
- 唤醒模块/本地ASR;
- 语音控制器语;
- 本地对话系统;
- TTS模块。
以上每个模块均包含一个或多个应用,这些应用内置在车机:音频处理包括AEC (Acoustic Echo Cancelling)、VAD (Voice Activity Detection)、音频压缩、唤醒词、本地的ASR识别等。该模块可以对来自麦克风的原始音频信号进行各种预处理,向语音助手提供获取唤醒信号、预处理后的音频、本地ASR识别结果等接口。
前端信号处理包括:AEC、ANR、AGC、声源定位(SSL)、Beamforming,全部通过软件方案实现。
3. 语音助手
车机端负责语音对话的中枢控制模块,负责协调车机端对话系统的总体流程。车机端的其他模块或者被语音助手调用(音频服务、本地对话系统、TTS模块、应用程序),或者属于语音助手的组成部分(对话控制器)。
4. 本地对话系统(本地DS)
本地对话系统是云端对话系统在车机上的一个镜像。它负责执行那些需要在车机上执行的对话处理,如:离线无网络状态下的对话功能、基于本地SDK的导航或音乐搜索相关的对话处理、 或者其他一些本地优于云端的场景下的对话功能。本地对话系统提供了一系列接口供对话控制器进行调用。
本地对话系统从云端对话系统相同的基础架构衍生而来,和云端的设计和功能大体相同。
但也根据本地的特点和需求进行了变化。如鉴于车机运算资源的匮乏而精简了模型;集成了车机专属的基于SDK的媒体和导航搜索功能;本地对话系统包含语音识别、语义理解、语音合成, 系统倾向于支持断网场景下的业务,如车控、打电话等基本场景。
本地对话系统的交互入口是语音唤醒,有的唤醒会支持双唤醒词(隐含)。像百度地图就支持“小度小度”也支持“小德小德”(高德地图的唤醒词),容错率更好。
5. 本地NLU
本地NLU在无网络状态下,提供基础语义理解服务,考虑到车机端的运算能力,在NLU模型上需做大量的模型裁剪和压缩,并结合车机芯片进行指令集层面的优化,确保将本地NLU的效果最大程度的逼近云端NLU的效果;本地NLU的资源大约是在线的1/10, 最大程度的保证了本地的效果。
6. 本地TTS
TTS模块被语音助手调用,负责将文本转换为语音播报。TTS合成引擎由供应商提供,对话话术的TTS文本通过话术运营系统来制定和编辑,其结果存储在数据库中、供对话系统调用。
四、云端系统
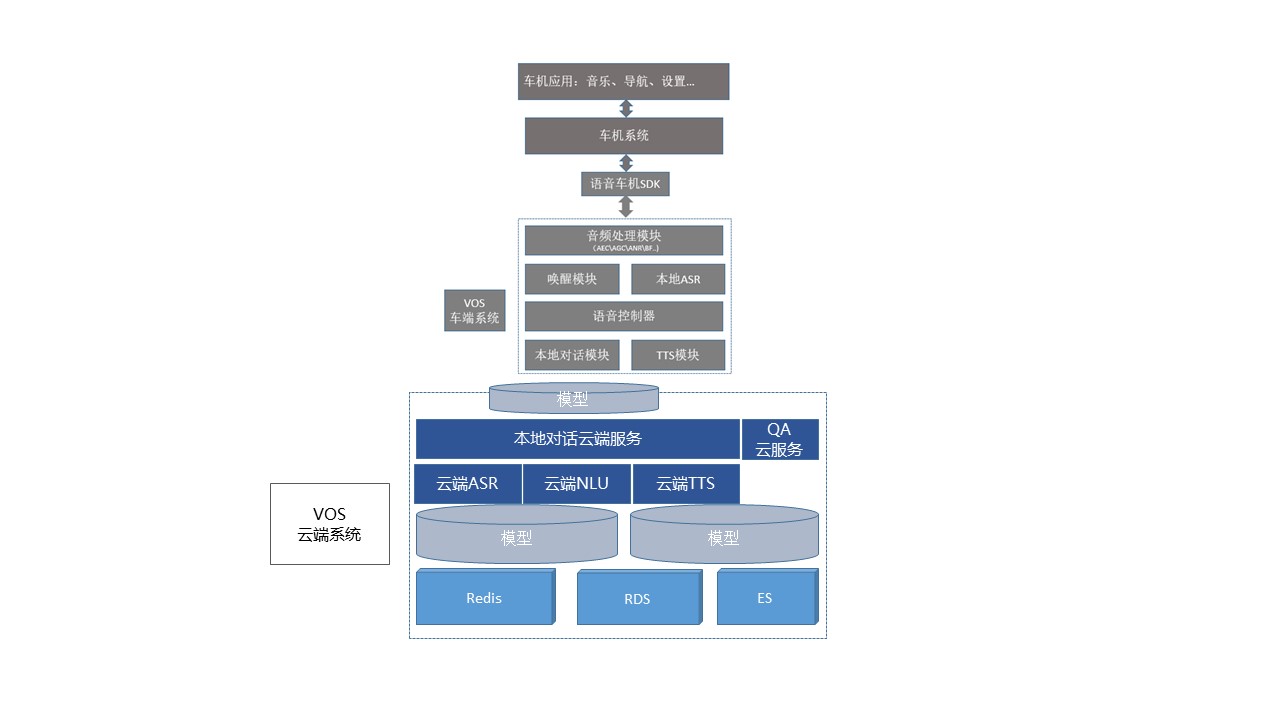
1. 对话系统
对话系统的云端部分(或者说在线对话系统)由多个部署在云服务上的服务和存储组成。
云端向车机提供两种接口:一种是基于TCP的socket流式数据传输接口,用于传输语音数据并给出
云端ASR识别结果和对话结果:一种是基于HTTP的用于发送非语音类消息的接口。云端服务可以部署在各种云服务(如aws、华为云等)的计算节点上;一套部署在具备64G内存的计算节点
上的云端节点可以同时支持2-3万台设备的访问。
对话系统的云端部分主要提供以下几项功能:
- 在线ASR识别对话服务模块可以接受用户发起的语音对话的音频输入,并给出识别结果。
- 对话 对话服务模块可以接受用户发起的语音对话的文本输入,并给出相应的对话结果,包括TTS文本、要车机进行的操作、车机用来屏显的内容等。
- 其他功能如向用户进行主动推送等。
2. 模型
模型主要提供各种AI算法的运行模型数据,包括声学模型、语言模型等等多个不同算法不同用途的模型,可独立升级,来实现最优的AI处理效果。
对于通用领域,模型优化能够带来整体的提升,例如整体升级声学模型和语言模型,在用户数据积累到一定程度的时候,如1万小时交互音频数据,可以带来20%-30%错误率下降。
对于专有领域,模型优化能够实现从极低到极高,甚至从无到有的提升,例如一些产品强相关的词汇、使用常见的一些专有名词、人名地名等,都可以做特定的优化,达到通用的效果。
3. 云端TTS
云端TTS有别于本地端TTS,基于强大的计算能力,云端使用更大的数据库,技术上使用基于拼接的方案,相比于本地端基于参数合成的TTS,音质更自然;
TTS的声音可以进行定制,需要经过文本设计、发音人确认、录音场地和录音、数据筛选、标注、训练等过程。
五、运营平台
运营平台通过云端和线上对话系统联通,负责以可视化的形式干预对话系统线上的数据和功能。其中主要包含两大类功能:数据运营、功能运营。
1. 数据运营
数据部分的运营主要针对两部分比较常用的可运营数据:
- 针对系统接入的CP/SP的可运营的内容,比如喜马拉雅的推荐数据、黄页数据等等,可以在系统中以手动的方式调整数据的内容、排序等;
- 针对企业自有的数据,比如主机厂独有的充电桩数据、服务门店数据,可以有机的结合到对话系统中来。
2. 功能运营
功能运营主要是在特定的时间点,比如某些节日、或者有特殊意义的日子、或者临时发生一些事件的时候,通过快速干预某些特定的说法的反馈,通过编辑特定说法的TTS回复,来实现系统对特殊情况的特殊处理。
六、训练及分析
1. 用户数据统计分析
用户数据统计分析系统,通过对所有实车用户使用车载语音的情况进行统计分析,能够得出不同维度、不同粒度的分析报表。定期进行报表的解读和分析,可用得出的结论来指导系统功能的改进。
2. 训练系统
针对音频、文本、图像的采集+标注系统,企业通过定期常规的对线上数据的回收、标注和不定期的对特殊要求数据的采集、标注,生产出各个AI模型需要的数据,提供模型训练支持;每次模型训练完毕会有迭代上线,从而实现训练数据系统和线上模型的一个闭环迭代,不断的提升整体的语音产品的能力。
以上便是对智能座舱车载语音系统的完整介绍。如果你对智能座舱产品感兴趣,关注我。
本文由 @赛博七号 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
本文由 @赛博七号 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。










你好,我想请问下,车载语音方向的PM有市场吗?吃香吗
有市场,吃香不吃香看公司。有的给钱给资源给人,有的“用公版软件,给你八个月,做出来和小鹏一样水平的车载语音”。。。。
这个系统看上去好智能耶 不知道能不能自定义唤醒词 那样应该很有意思!
很早就可以实现了~