
 起点课堂会员权益
起点课堂会员权益电商系统搜索场景推荐的千人千面——语料库建立
编辑导读:搜索是产品最常见的功能,尤其是电商产品,利用搜索功能和场景推荐功能,达成千人千面的效果。本文作者以语料库的建立为例子展开分析,希望对你有帮助。

搜索和推荐场景的联动行为,千人千面的用户兴趣;
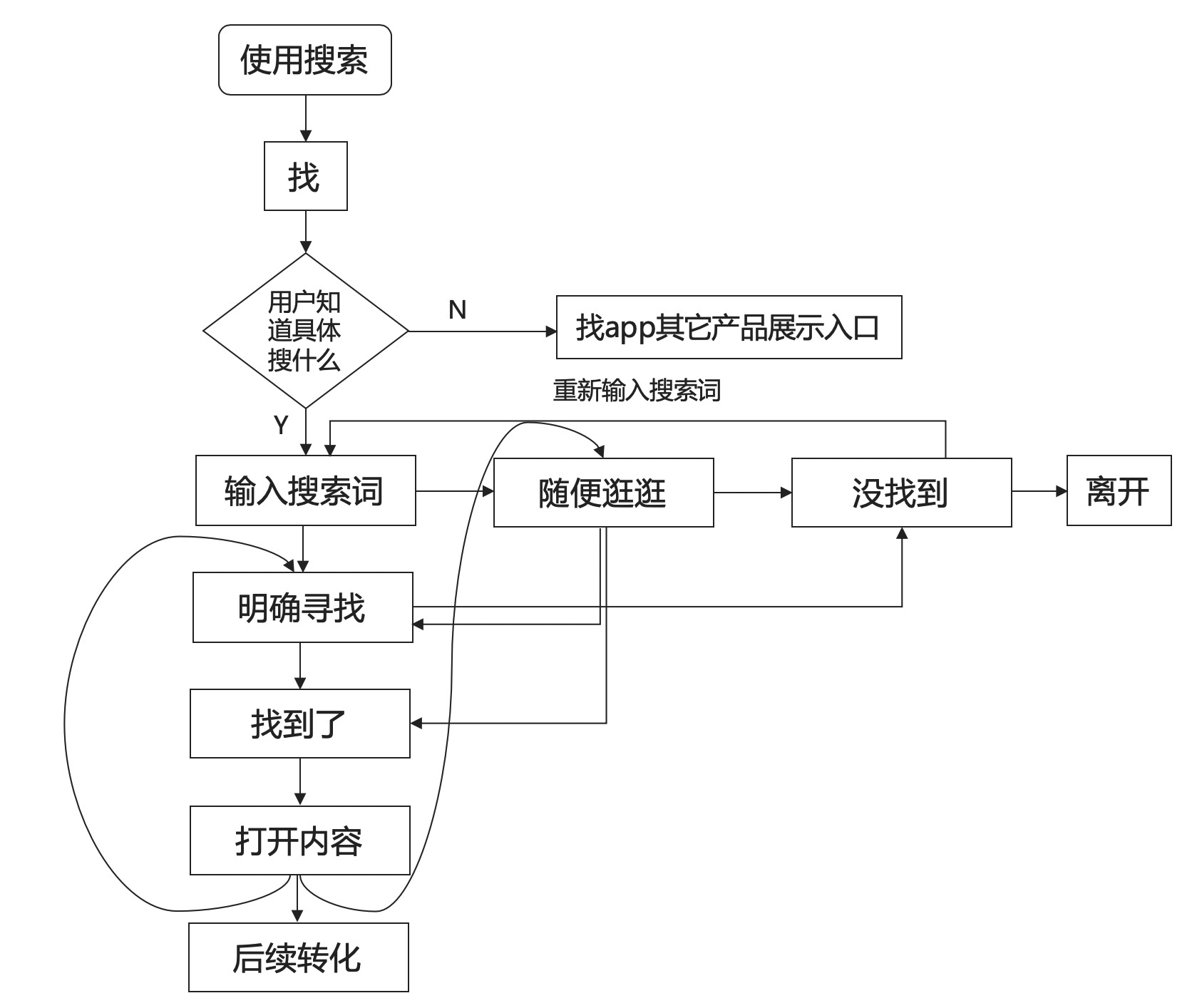
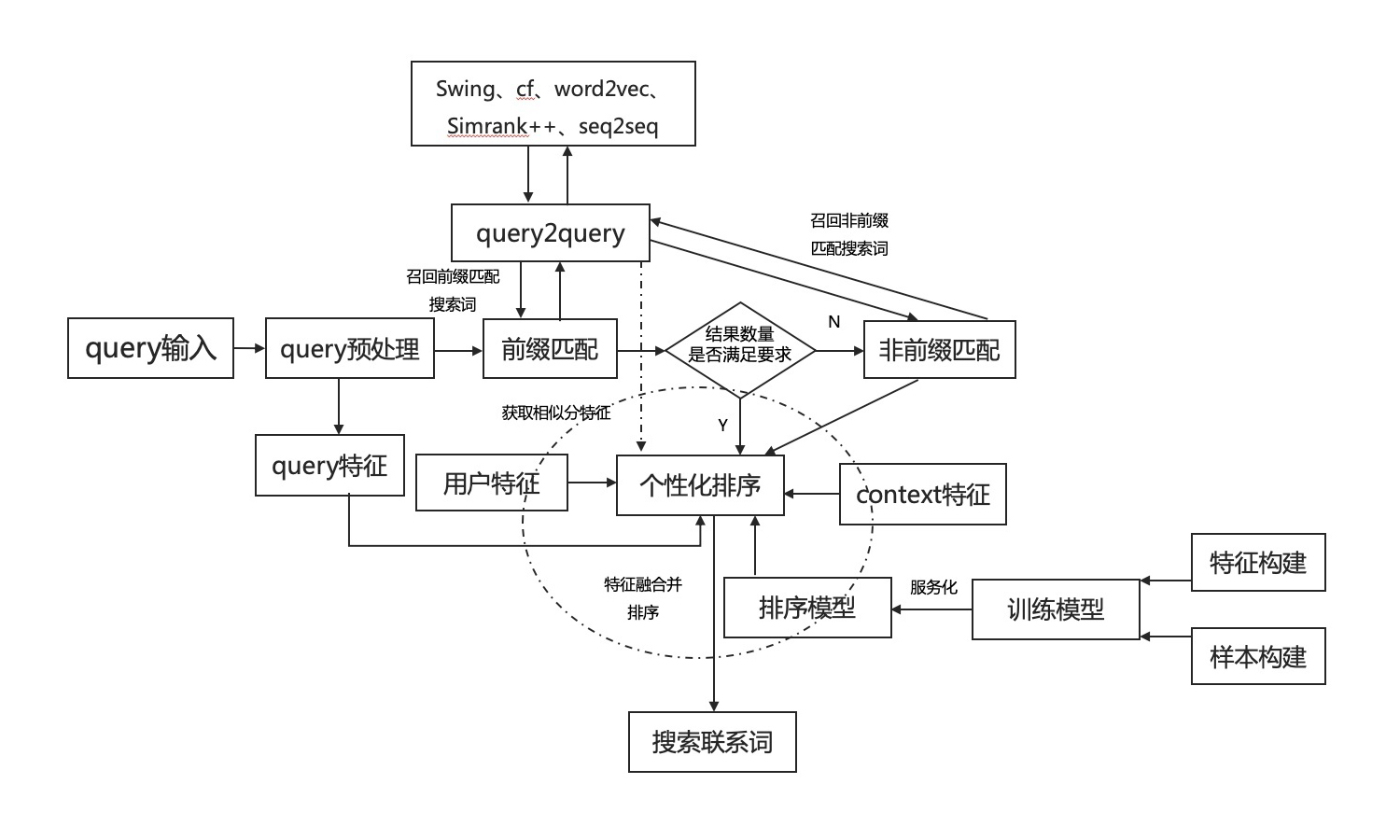
01 搜索步骤
用户输入搜索关键词,搜索系统根据输入信息,筛选出用户可能喜欢的内容,同时按照某种重要性进行排序并展示。简单而言,搜索可以分为三步:
- 对用户输入搜索词的解读
- 根据搜索词对内容筛选
- 对筛选后的结果集排序并展现,并且根据用户反馈进入新的搜索服务
1. 搜索前行为记录
- 条件:对用户当前需求没有显式信息
- 定位:以推荐为主
- 典型产品:搜索底纹、搜索发现 、历史搜索词、热门搜索词
- 搜索物料:历史搜索词、短期、长期商品交互(点击、加购、收藏、购买)、其他人的搜索及站内行为

2. 搜索中行为记录
- 条件:需求部分已知
- 定位:辅助查询输入
- 典型产品:查询智能补全(SUG) /搜索联想
- 搜索物料:短期、长期商品交互(点击、加购、收藏、购买)、其他人的搜索及站内行为
3. 搜索后的行为结果
- 条件: 用户完成搜索, 已获取结果列表 ,排序及展示结果页
- 定位: 辅助用户修正结果或重新查询
- 典型产品: 相关搜索、筛选、泛词引导/锦囊、搜索纠错,搜索确认、搜索排序
- 搜索物料:搜索词下类目重要属性,短期、长期商品交互(点击、加购、收藏、购买)、其他人的搜索及站内行为
02 动态流通语料库
语料库的语种,语料库也可以分成单语的(Monolingual)、双语的(Bilingual)和多语的(Multilingual),按照语料的采集单位,语料库又可以分为语篇的、语句的、短语的;双语和多语语料库按照语料的组织形式,还可以分为平行(对齐)语料库和比较语料库,统称为的语料构成译文关系。
- 语料:从单语种到多语种
- 数量:从百万级到千万级再到亿级和万亿级
- 加工:从词法级到句法级再到语义和语用级
- 文本:从抽样到全文
- 特点:动态性,不确定一个固定的库容量(例如:把库容量目标确定为数百万字,上千万字,数千万字,数亿字等)
不确定一个固定的选择文本的时间段(例如:确定为49年-82年,80年-90年,90年-95年语料等);
不确定一个固定的文本选择范围或应用领域(例如:确定为只收现代汉语文学语料,或新闻语料,或科技语料或中小学生语料等,从而建立一些专门的语料库);
不确定一些固定的文本抽样对象(例如三只松鼠,新能源电池,蒙牛酸奶,等)。
定时抽取的语料库:根据大众媒体的传播情况,依据一定的原则来动态抽取;以观察和测量到流通度的变化情况,可以追踪到语言成分的产生,成长和消亡。
03 搜索的精准匹配推荐与记录
搜索词充当了用户与搜索工具之间的重要沟通载体,借助关键词实现用户自我意识与搜索引擎之间的交流,形成了一个意识产生、关键词转化、搜索、信息获取、动机满足的信息闭环。
当然还有很多因素也会去影响这个闭环,如用户(历史行为,浏览偏好,性别、年龄等)、地域、天气,一个宏观、长周期的链路等。
根据搜索的过程,可以拆解用户的搜索流程如下:搜索入口-搜索触发-内容输入-点击搜索-反馈结果。我们从这个流程的各个环节上来看四大电商app(京东、天猫、手淘、拼多多)的搜索功能,进行对比分析。
电商搜索为例,以用户搜索过程中输入搜索词(点击“搜索“按钮到按下”回车“之间发生的事)的过程为切入点,结合产品及技术方案展开,结合相关搜索词功能进行论述;
从而形成分词:长尾词,属性词,精准大词,短词、单词、双词。
划分等级:搜索热度、点击率、频率、竞争度、时间段落。
04 搜索词自动索引推荐产生联想效应
关键词匹配/补全/联想/纠错的作用主要划分为:引导、纠错和高效。
通过统计再计算,用户在第一次查询中得到预期搜索结果的概率非常低,所以需要引导查询自动建议可以减少用户搜索的工作量,并通过数据挖掘(群体行为和智慧)来给出高频恰当的搜索建议,语料库的词匹配与联动效应,在不断的记录分词中构造出相对完整的词库。
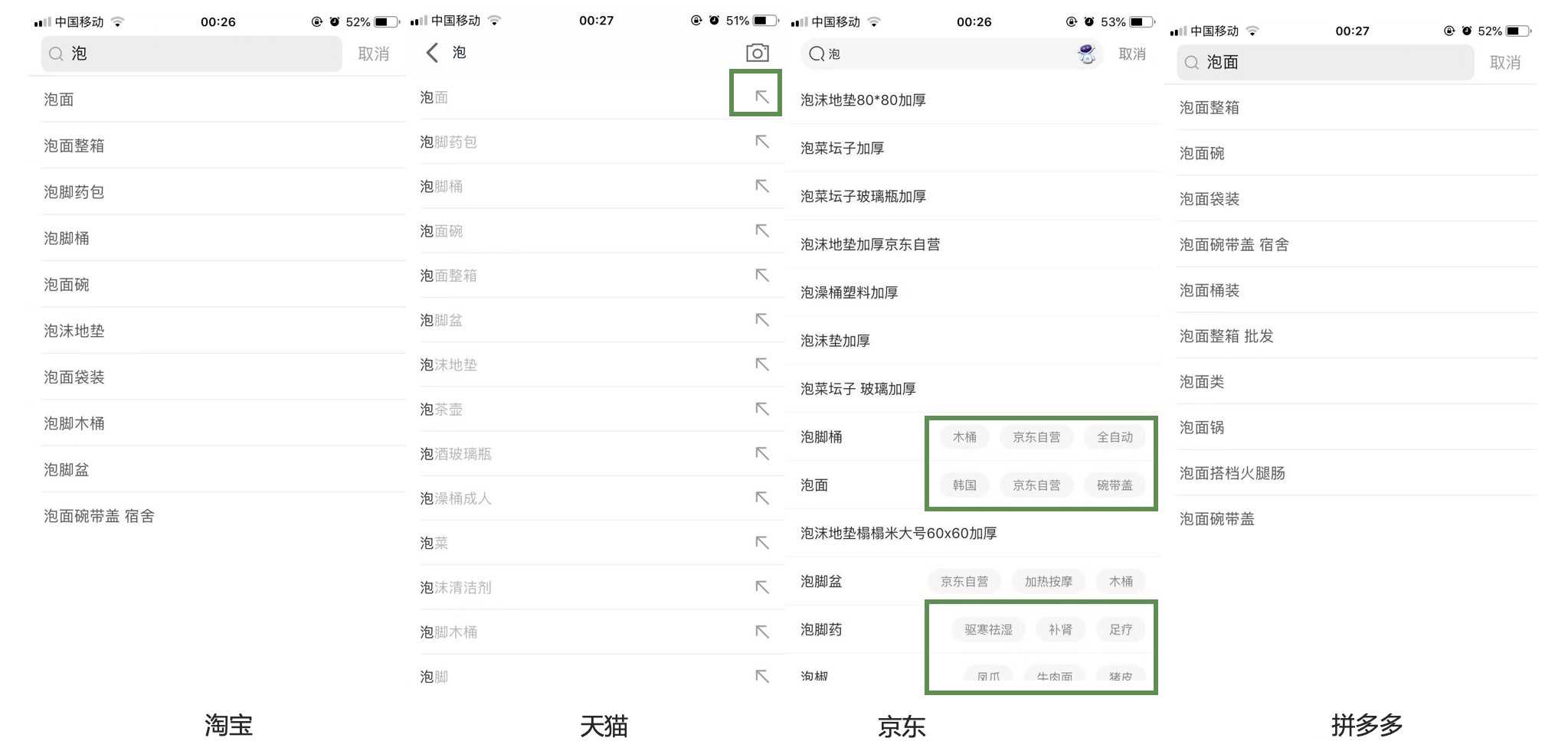
搜索时使用了前缀匹配,但是手淘和天猫使用了拓展icon,可快速将推荐词黏贴至搜索框,京东使用了属性、标签、类目扩展 (除了对输入内容做联想,还会展示出与关键词相关的维度,自动补全关键词,增加用户的选择),拼多多则相对搜索词产品探索较少。不过目的都是帮助用户快速锁定意图,并开展搜索。
用户在搜索框输入字符时,会在搜索框下面实时显示下拉提示词给用户,方便用户选择;可以帮助用户快速输入和优化搜索条件,且避免输入错误;在此基础上很多电商app也出现了筛选功能,在当前搜索建议词基础上进行扩展,进一步减少用户操作,一般在用户搜索的不够具体,会推荐该搜索词更细的分类。
淘宝的辅助多重筛选搜索,输入时展现的一系列联想内容,点击右边的一个拓展icon,就可以采用联想出的内容,在此基础上继续缩小范围筛选,从而帮助用户获得最接近需求的内容。
通过当前实时输入的词去匹配候选词,一般查询频度和同查询词的历史查询记录为重要参考依据。
在搜索词补全和联想数量上,淘宝为10条,拼多多为10条,京东/天猫超过10条,但是不能过多,过多的选择会给用户造成记忆负担,并且占据空间,有损用户体验,所以需要控制数量以便信息不会过载。
当然部分电商在历史的版本迭代中会尝试在搜索输入阶段进行纠错,比如输入联衣群,下拉框中自动纠正为连衣裙的一些选项,目前四个电商app均并无此功能,而是在搜索结果展示内做纠错及提醒;自动容错功能,将极大地提升用户体验,并提升用户的购买率。
语料库的建立实现:
- 可选择对接第三个已有的语料库开放平台(可减少开发时长)
- 自主构建语料库体系
前缀匹配原则,完整词未出现时一般使用补全/联想功能,品类引导词为主;当出现明显品类词后开始出现更细粒度属性及标签筛选词。一般从Query log中挖掘出大量候选Query,并且保证前缀相同,然后根据某种计算模型给候选Query 计算一个分数,最后按照分数选出TopK作为最终结果。
主要考虑因素:当前搜索词,用户(性别、年龄等特征),日志中的群体。
常见搜索引擎均带有Suggestion功能,直接使用前缀匹配后的候选词(Trie树 + TopK算法,回溯算法遍历trie树),使用用户搜索频度最高的TopK个搜索词,但是这样会使长尾词无法得到曝光机会。
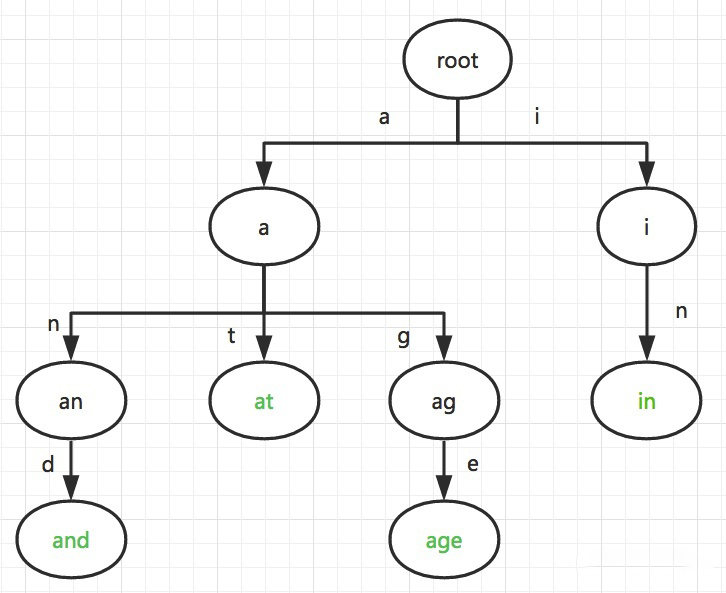
05 AC联动算法
在用户进行搜索商品时,通过用户与搜索词信息进行意图预测,并辅之以类目、性别预测,前缀匹配后最终将某个性别和类目下的共现最高的TopK热搜词作为搜索框下拉框提示词。
复杂模型版1
复杂模型版,使用前缀匹配算法进行候选集召回(若召回量过少,考虑非前缀匹配结果),并做简单截断;然后使用用户特征(性别、年龄、行为序列)、Context特征(季节、天气、温度、地理位置)进行、当前搜索词的Embedding Vector,然后候选搜索词也有一个Embedding Vector,三个Vector分别与候选Vector计算Cosine similarity,最终使用一个线性模型融合三个分数,最终的排序结果会进行语义去重再选择TopK(这里也可以用生成模型来做排序)。
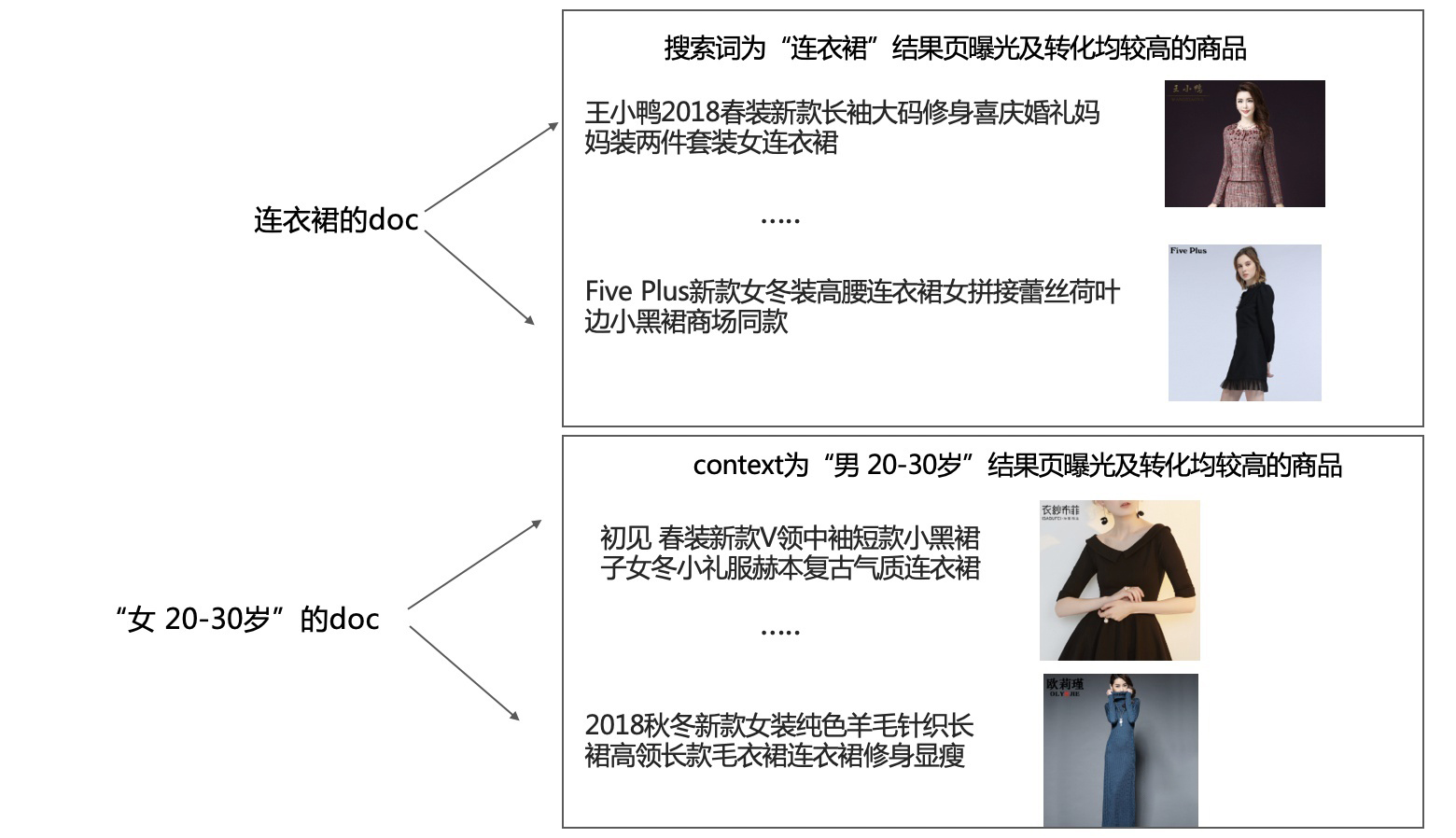
这里可以将用户、Context均视为搜索词,就可以用日志数据构造Doc,最终使用Doc2vec或Word2vec。
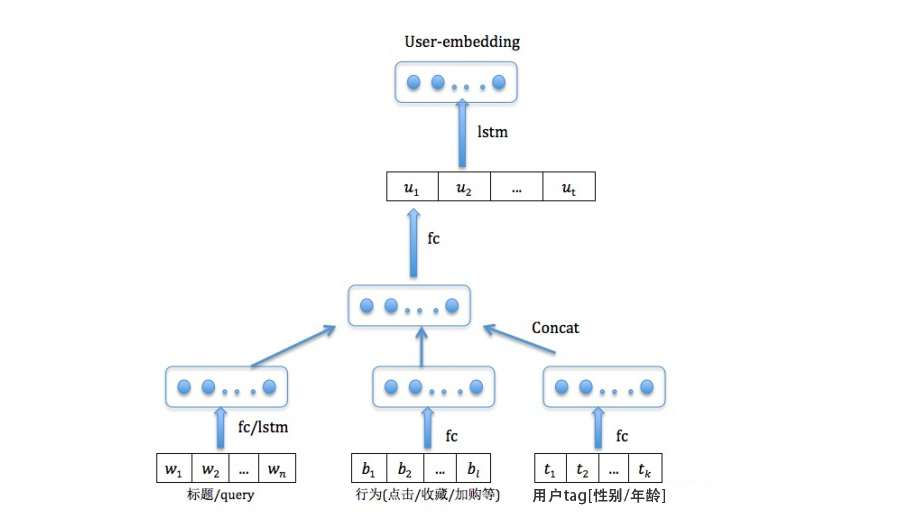
通过语义、行为、Session log等挖掘出Query间相似分,并加入用户、搜索词、Context类特征及其交叉特征。多维度相似融合再排序: 按照点击相似度、文本相似度、Session相似度衡量Query之间的相似度,得到候选的Pair(可选)交给重排序模块,对Query pair的优先级做优化,生成Top K的改写结果。
query2query召回基于行为: item cf/swing、Simrank++基于session: Word2vec、Seq2seq基于内容: Query2vec(类似Word2vec,构建Query序列)query排序模型: LR/GBDT
样本: 用户日志,行为加权(展现:1,点击:5,购买:50)
特征: 搜索词的Pv/Ctr/Cvr,用户是否活跃,用户画像/特征,用户+候选词(查询词/浏览详情页与热搜候选词相似度),Context特征(地理位置,温度,天气等)
文献参考:【数据堂】/【陌生人社交算法拆解】
#专栏作家#
村上春树,人人都是产品经理专栏作家。养成挖掘性的思考习惯、综合、市场、运营、技术、设计、数据、擅长跨境电商,综合电商与商业模型。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
专栏作家
小镊子,人人都是产品经理专栏作家。养成挖掘性的思考习惯、综合、市场、运营、技术、设计、数据、擅长跨境电商,综合电商与商业模型。
本文原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。










销售管理制度