
 起点课堂会员权益
起点课堂会员权益风控策略模型上集:策略这样做
风控决策引擎一定程度上可以看作是规则的集合,也因此,策略同学需要更加了解风控规则的制定原则。那么,如何制定原则?如何理解策略一侧需掌握的核心能力?本篇文章里,作者结合自身经验发表了他的看法,一起来看一下。

互联网消费金融领域,每一笔贷款都是风控决策引擎的结果,而风控决策引擎本质上是一系列规则的集合。
风控规则也叫做风控政策、风控策略。欺诈、盗号、作弊、套现以及营销活动恶意刷单、恶意抢占资源等都是风险,都需要复杂但高效的规则引擎。
这里我们只关注信贷风控。
一、如何制定规则
风控规则的制定原则:
- 监管层面的原则:国家监管规定的客群不能放;
- 公司层面的原则:老板说不能放的客群也不能放;
- 风控层面的原则:业务经验、专家经验、数据分析和模型认为风险高的不能放。
1. 监管层面
监管会约束机构禁止对未成年发放贷款,执行起来,准入规则就会强制要求用户年龄大于等于 18 周岁。
学生贷也会有较多监管要求,因为学生群体大多没什么稳定的经济收入来源,按时还款的能力不足,容易滋生过度借贷和诈骗。
3. 公司层面
准入通常也会设定一个年龄上限,例如 60 岁。设定年龄上限往往是出于舆论的考虑,老年人贷后事故可能会更大,例如遇到催收反应过激。这一般并不在监管范畴,而是公司层面的原则。
高危地区也是如此,某些区域历史上出现过集中诈骗,为了防止被团伙攻击,在公司层面直接不对这些高危地区准入的做法也是存在的。
另外,公司也会规定同一申请人被拒绝一个月内不能再次申请借款。这是因为短时间内用户的信息不会发生明显变化,用户的风险评估结果不会前后差异过大,前次被拒绝,再次评估往往还会被拒绝。而评估一个人是有成本的,低效地去重复查询数据是不可取的。
4. 风控层面
根据行业经验,制定欺诈类、黑名单类、多头类、信用不良类的强规则是不言而喻的。
欺诈主要可分为一方欺诈和三方欺诈。一方欺诈是指申请人自身的欺诈行为;三方欺诈是第三方盗用、冒用他人身份进行欺诈,申请者本人并不知情,比如团伙利用非法收集的身份证进行欺诈。
其实还有两方欺诈,是内部人员勾结的欺诈,一般不在考虑范围。
一方欺诈往往较难定义,它跟信用不良的表现结果无二。可以先验地设置一些专家判断,例如手机号入网时长一般限制最小值为 6 个月或 12 个月。新号来注册申请,显然更可能是欺诈骗贷,当然这些规则很容易被撸口子大军绕过。道高一尺,魔高一丈。
人脸识别显然是一个很有效的三方欺诈防控的办法,但也是一个很笨重很伤用户体验的办法。三方欺诈防控更大程度地依赖于大数据挖掘,盗用冒用在设备行为和关系网络上一般是有迹可循的。基于大数据的反欺诈模型是风控中重要的内容之一。
黑名单一般分产品内部黑名单和行业外部黑名单,内部黑名单指的是历史用户中的欺诈用户和严重征信不良用户,外部黑名单指的是三方数据提供的命中信贷逾期名单或法院执行名单或其他高风险的用户。黑名单防控和一方欺诈有交叉重叠。
命中黑名单的客群一般会直接拒绝。业务持续发展过程中,黑名单客群数量可能积累过大,这往往是由于入黑规则过于严格,误杀会较严重。将其根据风险差异再拆分黑名单和灰名单是必要的,对灰名单用户可以测试放开。从而实现名单优化。
多头指的是用户在多家平台借款,存在借新还旧、以贷养贷的风险。用户也许能够从其他平台借到款来还自己平台的款,但对任何单一平台来说,赌自己不会成为受害方就跟赌比特币自己不接盘一样,不是风控该允许的做法。
行业的共识就是制定多头规则。多头指标往往是制定成可变规则,因为多头是一个程度问题,阈值可以调整,多头规则是整个风控规则中调整频率比较高的。
实际上,基于数据分析的规则制定是方便易行的。基于特征库,挑选出一些风险区分度高的变量是一个单变量分析的过程。只要遵循三个指标,准确率、召回率和稳定性,就能找出有效可用的规则集。
准确率是说命中的人当中坏用户占比要尽量高。
召回率指的是命中的坏用户要足够多,一条规则只找出了几个人,即使都是坏人,也没有意义。
稳定性当然很重要,命中的人数、命中的人当中坏用户占比,都需要持续稳定。否则要频繁跟踪调整。
需要说明的是,模型也可以理解成一条规则,只不过它是将许许多多的弱变量组合成一个强变量。强变量用于规则,弱变量用于模型。
他们的本质都是将用户分层,方便我们将用户一分为二,将其通过或拒绝。
对于一些可变规则,应定期检测规则的时效性,有些规则是经常需要更新的。另外还需要保密,尤其是反欺诈规则。
二、策略的核心能力
说说策略同学的关键技能。
业务总会不断对策略进行迭代优化,这往往也导致策略体系过于庞杂,怎么样从庞杂的体系中分清轻重缓急是策略同学的核心能力。
如果推倒重来要怎么做?给一家新公司业务做策略顾问你要怎么做?这些都不是照搬现有体系能够解决的。设想下,假如需要你去做风控能力输出,从 0 开始制定一套风控流程。你会怎么做?
决策引擎是一套决策流程,它的要素组成是规则清单和规则被执行的顺序。前者要求全面且高区分性,后者对成本优化至关重要。
为了使风控输出的规则保持清晰有效,既需要考虑规则变量提取的易行性,又要考虑规则执行的必要性。命中低、难执行、成本高是失败规则的常见特点。重复命中也是策略体系中常见的问题。
规则清单制定完成后,需要动态监控每条规则命中的人数。不同时期激活的规则可能不一样,也就是说,可能其中一部分是激活状态,另一部分是抑制状态。动态调整规则的阈值,以及激活抑制的状态,是很有必要的。
例如,某些月份的逾期相对较高,新增了一些规则,后期监控到这些规则发现其区分能力明显下降,就应该适当取消。
不管是规则还是模型,一定会有很多误杀,但误杀是允许的,因为贷款本金的损失往往是利息收益的几十甚至数百倍。
平衡决策对通过率的影响和对风险的影响,对成本的影响和对收益的影响,是风控策略从业者需要培养的职业嗅觉。
三、多头规则实例
多头借贷在策略上一般作为拒绝维度参与到整个风控流程中。不同机构、不同信贷产品、不同场景,对于多头借贷的拒绝线划分都是不一样的。
如何找到当下最适合的多头借贷拒绝线,是风控策略分析人员工作中的核心任务。
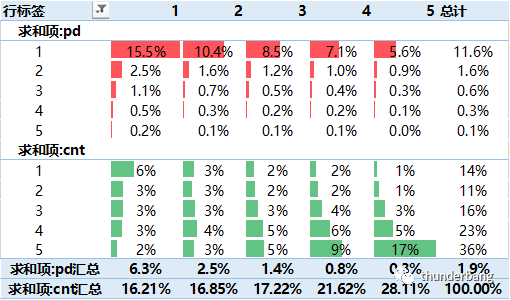
我们找个合适的变量来看看统计数据,下面是“近一年在互金机构查询次数”的结果。

以上,如果我们采用宽松政策,可以将阈值定为大于等于 2 作为拒绝线,这样拒绝率只占 3.2%,被排除的用户坏账率更高。
而如果我们采用严格政策,可以改为大于 0 则拒绝,这样拒绝率增加为 10%,被拒绝的用户相比通过用户仍然显著要高。
这两个规则都是有效的,实际业务中采用什么样的阈值取决于公司的政策。从严 or 从宽。
当然,最顶层的目标是利润最大化。
值得说明的是,多头数据往往覆盖率有限,体现在变量取值上是 0 值占比过高,这个时候便可以考虑取大于 0 的部分来做多头排黑规则。
如果单变量不具备足够强的区分能力,组合多个变量是另一种策略制定方法。下面是两个变量的交叉结果,两端的 11.6%和 6.3%的风险组合起来能得到 15.5%的风险,这个也许就能满足一条规则上线的要求。
利用决策树制定更多变量更丰富的交叉组合可以得到更有效的规则。
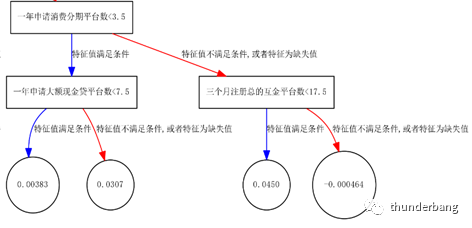
多头变量除了用于制定强规则直接去拒绝用户外,还以为作为软规则用于客群划分。多头严重或者不严重区分出来后,再结合其他维度的风险评估交叉使用。
国内缺的从来不是策略,而是将策略贯彻的决心与环境。
为我投票
我在参加人人都是产品经理2022年度作者评选,希望喜欢我的文章的朋友都能来支持我一下~
点击下方链接进入我的个人参选页面,点击红心即可为我投票。
每人每天最多可投35票,投票即可获得抽奖机会,抽取书籍、人人都是产品经理纪念周边和起点课堂会员等好礼哦!
投票传送门:https://996.pm/7mXqv
专栏作家
雷帅,微信公众号:雷帅快与慢,人人都是产品经理专栏作家。风控算法工程师,懂点风控、懂点业务、懂点人生。始终相信经验让工作更简单,继而发现风控让人生更自由。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。










“国内缺的从来不是策略,而是将策略贯彻的决心与环境。”这句话认同。
想请教下,关于制造业厂家端,如何针对下游的经销商、零售商进行零售订单数据风控,实现零售补贴资源真正给到用户,里面涉及到的最大阻碍是,严厉打击后,可能影响下游向上游采购的意愿,下游向上游的投诉,作为推行者,该如何操作呢?
在金融风控领域,有没有类似的场景,会涉及到这种问题?
帐号风控反作弊小白飘过~从文字可以体会到为人和经验、知识结构的强大,有很多认知拓宽,开始持续关注~比如,策略指标除了准召、稳定性也很有必要(一段时间里命中量数量,命中里黑产占比)