
 起点课堂会员权益
起点课堂会员权益风控策略模型下集:模型这样做
模型开发是为业务需求服务的,高效解决业务的难点和痛点,就是模型开发的护城河。本文对模型开发中的模型定位和目标、标签定义、样本选择等方面进行了概述,一起来看一下吧。

模型开发是为业务需求服务的,高效解决业务的难点和痛点,就是模型开发的护城河。而不是所谓的算法。
业务有什么样的需求,模型就要做针对性的设计。这是实际工作中最吃功夫的内容。也是和那些建模比赛差异点最大的地方。
模型开发并不是一件容易的事情。所以更要确保各个环节合理有效,才能完成整个项目的交付。关键要点包括模型定位的合理性、数据质量的可靠性、建模方法的适用性、模型输出的准确性,以及模型表现的稳定性。
模型开发周期可根据项目的需求及难度可以适当调整,开发期间通常需要安排至少 3 次里程碑会议。
- 立项会议:参会方应包括模型开发方、模型使用方(需求发起方)、以及模型验证方。主要阐述模型立项的背景和目标,同时明确模型开发方、使用方、验证方、及部署方的职责与排期;
- 初步汇报:由模型开发方展示模型初步的数据分析结果和建模思路,并与各方确定模型框架;
- 模型评审:模型方汇报模型开发的过程和结果,验证方给出验证结果,各方对模型结果和模型应用展开讨论,确定最终版模型。
我们下面概述下模型开发中最为关键的内容,包括模型定位和目标、标签定义、样本选择、数据来源与处理、模型开发和模型评估。
一、模型定位和目标
为了量化处理业务中不同的实际问题,模型开发方需要与业务方沟通确定建模目标。
我们知道,信用风险模型主要是为了评估用户还款能力和还款意愿;反欺诈反作弊模型防止用户骗贷、薅羊毛和保证平台安全等功能;资本计量模型主要适用于 Basel 体系确定最低资本要求和进行压力测试。
但模型定位和目标的沟通不止于此。我们需要了解的更多,模型被用于哪些场景,模型的应用客群是什么,有没有需要重点针对的客群,预期效果怎么样,什么时候要用等等。
目标是 KS 越高越好,还是 30 以上就行(这个 30 应该是参考已有模型的一个经验值),对接下来的模型方案是完全不同的。
前者是寻求上限问题,要求你清楚地知悉现有体系的弱点,在合理的排期下做最优决策。特征空间是不是跟不上业务的发展了,标签定义是不是可以改进,业务上是不是在做新的客群,是不是需要分客群建模,能不能用外部的数据做实时模型,等等问题都需要回答。
后者是保证下限问题,实现起来容易地多,挑最重要的一两个点进行优化,往往就能解决。
二、标签定义
标签一般分为 GBIE,G 是 good 好用户,B 是 bad 坏用户,I 是 indeterminacy 不确定用户,E 是 exclusion 排除用户。
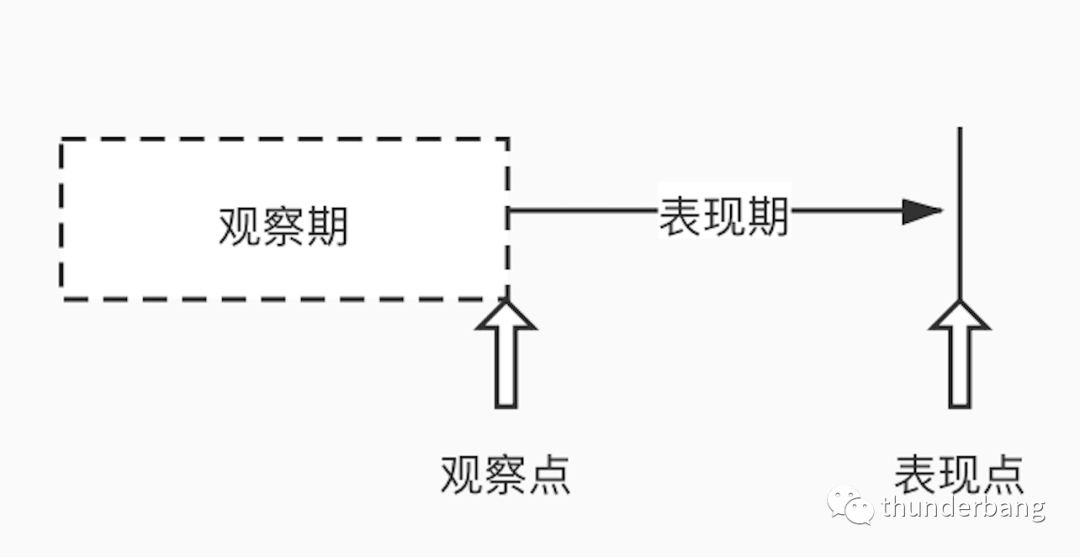
- 观察期:用来加工用户的特征,也就是说对观察多久来统计建模;
- 观察点:贷前是申请时点,贷中可以是任意时间点;
- 表现期:用来定义好坏样本的时间区段,看用户在这个时间窗口内的逾期变现来加工标签;
- 表现点:是表现期的末端。
我们从观察点开始看用户,这个时点不需要考虑的用户就可以定义为 E 用户,例如信用模型不考虑欺诈用户。表现期内风险良好的定义为 G,风险高的定义为 B,中间段还设有 I。
观察期的长短视特征加工的时间范围确定,表现期的长度需根据 vintage 曲线定义。我们需要客户的违约是比较稳定的,这样才能保证结果的准确性。B 逾期程度的定义需要计算滚动率。
工程上,这些定义会有很多明细要求。
三、样本选择
样本选择是最能体现模型开发定位和目标的,也是最吃功夫的部分。不同模型的开发,其他的有迹可循,唯有样本的选择是各有各的不同。
1. 样本选取原则
选取样本时要考虑样本的代表性,是否能够有效地代表总体,必须包含可靠的预测信息和表现信息。通常来说在选择样本上需遵循三点原则:
- 代表性:样本必须能够代表总体,过去以及未来;
- 充分性:样本量太大则需要业务积累时间较长,数据加工要求更高;太小,可能达不到统计的显著性,置信度太低;
- 时效性:建模样本需要与当前实际群体具有相似特征,如果由于外部环境或具体业务发生巨大变化,建模样本可能不再具有时效性。
需要剔除的样本,一般就是非模型应用客群,这个被定义在 E 客群上了,自然就被建模排除在外了。
2. 抽样原则
在样本数据较大及运算能力有限的情况下,应对总体样本进行抽样处理。
- 简单随机抽样:在给定样本规模之后从总体中完全随机抽取,每个抽样单元被抽中的概率相同;
- 分层抽样:根据业务需求确定样本的类别,确定针对每个类别的抽样个数,在每个类别内随机抽样;
一般,业务简单就随机抽样,业务复杂精细化程度高,就分层抽样。
3. 样本不平衡问题
好坏样本的比例总是差别很大的,尤其是反欺诈这个场景里面。极端的不平衡可能会导致模型忽略小样本的学习。
1)欠采样
- 随机欠采样:对多数类样本(一般是 G)随机抽一个比例。
- 有选择的欠采样:通过一定规则有选择的去掉对分类作用不大,即远离分类边界或引起数据重叠的多数样本。
2)过采样
- 简单复制法:对少数类样本(一般是 B)复制个倍数。
- 人工合成数据:借用已有样本,组合构造一些数据。
在通过欠采样或者过采样后,样本的比例发生了变化,因此需要在入模时通过权重调整法将比例调回来。如果只在乎排序性,这个也可以不考虑。
4. 分群
林子大了什么鸟都有。不同的人差别可能很大,一个模型不能有效地适用于所有客群。有时间需要用不同的特征来对不同的人群进行预测,即构建多个模型运用在各个子客群上。
分群也可以分为基于经验的分群和基于数据的分群。
基于经验的分群,主要是利用从业务知识中了解到的客群差异分群,如不同的营销渠道上风险差异较大,新的子产品上线了,业务更下沉了等等。
也可以通过聚类、决策树对数据进行分群,但因为我们本身建模都用集成树模型,分群本身就是树模型训练时干的事情。做任何额外的工作,都要考虑下必要性。
四、数据来源与处理
数据一般分为内部数据与外部数据。内部数据,是公司内部搜集存储的客户信息,例如商户在平台的销售、贷款、运营信息,客户的登陆、注册、消费信息等;外部数据一般为第三方数据,例如人行征信报告、运营商数据、第三方机构提供的多头借贷数据等。
模型开发文档中需明确列出所用到的数据来源和特征列表,并且需要多方确认数据可用,包括持续稳定和监管许可等。
同时,模型开发还需要考虑对缺失值处理和异常值处理。
1. 缺失值处理
直接删除含有缺失值的样本,缺失值较少,这是比较合适的,但当缺失值样本比例较大时,就会产生较大损失。
根据样本之间的相似性填补缺失值是更技术的方法。但是工程上更常用的方法是根据经验进行默认值填充,例如-1 或者 0 等。
不处理也是一种处理,而且也许是最好的处理。尤其是风险模型都在用 XGB,它可以自动学习缺失的最优划分。
2. 异常值处理
异常值是指明显偏离大多数数据分布的数值。可以采用离群值检测的方法来找出样本总体中的异常值。
有单变量离群值检测、局部离群值因子检测、基于聚类方法的离群值检测等等。
同样的,如果是树模型预测分类问题,异常值处理并没有太大必要。
3. 变量筛选
变量分为数值型变量和类别型变量。两者筛选不太一样。
数值型变量筛选可以用特征稳定系指数(Characteristic Stability Index)、信息价值(Information Value)、模型重要性排序(Feature Importance)等多方面考量,对于使用证据权重(Weight of Evidence, WOE)转换的模型,需保证根据变量分组后的样本分布符合业务逻辑。
对于类别型变量指标,应选择样本分布符合业务逻辑的变量,并考虑各类别取值的分布是否充足且较为均衡,避免因少数异常值伤害类别的代表性。
五、建模方法
应根据业务需要、建模目标和数据特点选择最合适的建模方法。
1. 传统统计模型
主要包括线性回归模型,非线性回归模型,广义线性回归模型,逻辑回归模型和时间序列模型。
线性回归、非线性回归或广义线性回归,用于拟合数值型因变量与自变量的函数关系,函数类型需根据实际情况进行尝试与选择。
逻辑回归模型用来处理因变量为分类变量的问题,通常用于二分类或二项分布问题,也可以通过累积逻辑回归(Cumulative Logistic Regression)处理多分类问题。
时间序列模型,用于根据已有历史数据对未来进行预测,可根据实际数据情况,选择回归差分移动平均模型 (ARIMA),向量自回归模型(VAR)或广义自回归条件异方差模型 (GARCH)等。
2. 机器学习模型
机器学习类模型大体分为 3 类:监督学习、无监督学习和强化学习。
监督学习有标签去计算预测正确与否;无监督学习则没有,算法仅尝试根据数据的隐含结构进行分类;强化学习会接收反馈,但反馈并非对每个输入或状态都是必要的。
风控模型中最常用的是集成树模型。相比于逻辑回归的线性分割,决策树类模型可以寻求非线性分割,以实现最优的样本空间分割。
在建模过程中,需要有训练集、测试集和验证集。模型训练是基于测试集上的效果去迭代模型训练过程。训练完成后要在验证集(最新的时间窗口内)上计算各种指标,例如回归模型中的 R-square 等,分类模型中的 AUC,AR,KS,GINI 系数等。
六、模型评估
模型上线后怎么用,就应该怎么评估。
如果要拓展下层客群的授信,就要把下层客群单拎出来计算,而不是混在全体样本里充数。
如果要和已有模型交叉使用,就需要评估交叉效果。
如果数据源可能会缺失,就应该评估缺失后的效果,若可接受,则后期数据源发生缺失时,调整下阈值接着用,而不是下线不用。
等等。
模型开发时我们总在关心模型效果,但当模型开发完后,最重要的是稳定性。没有策略会盯着模型分的变动反复调整阈值的。有问题的变量千万不要用。
无法详尽。
为我投票
我在参加人人都是产品经理2022年度作者评选,希望喜欢我的文章的朋友都能来支持我一下~
点击下方链接进入我的个人参选页面,点击红心即可为我投票。
每人每天最多可投35票,投票即可获得抽奖机会,抽取书籍、人人都是产品经理纪念周边和起点课堂会员等好礼哦!
投票传送门:https://996.pm/7mXqv
专栏作家
雷帅,微信公众号:雷帅快与慢,人人都是产品经理专栏作家。风控算法工程师,懂点风控、懂点业务、懂点人生。始终相信经验让工作更简单,继而发现风控让人生更自由。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于CC0协议。
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。










”在通过欠采样或者过采样后,样本的比例发生了变化,因此需要在入模时通过权重调整法将比例调回来”,权重调整法具体怎么操作的?