
 起点课堂会员权益
起点课堂会员权益设计就是在追求熵减
设计的本质在于追求熵减,这是一个不断分类、排序和规整的过程。无论是产品设计还是其他设计领域,都需要不断地优化和精炼,让其变得更加清晰和易读。那么,为什么设计就是这样一个不断分类和排序的过程呢?让我们深入了解一下。

我们在做产品设计的时候经常会遇到以下场景:
例1:设计一款APP,首先要考虑底部导航放几个,分别是什么,顺序是什么。这时我们可以根据计划为目标用户实现的价值,包括未来功能迭代的方向,罗列的有可能需要的功能,然后对功能进行分类,汇总,再分类,这样就完成了一个APP的底部导航设计,同时它也是这款APP的产品架构设计的重要组成部分。微信坚持底部只有四个导航,而且尽可能的不进行改变,分别是“微信聊天”,“通讯录”,“发现”,“我”。
例2:在电商领域,产品的品类可以说电商产品的核心功能,一方面商品管理从品类开始,另一方面它也是电商产品C端流量的重要入口之一。前台类目、后台类目、一级类目、二级类目、三级类目。
例3:在内容领域,从最早的门户网站、分类信息网站,到微博,抖音,b站,视频软件等等,都是围绕对内容进行分类,再分发来运转业务。
例4:我们常用的搜索引擎技术,其算法中很重要的一步是通过检索排序技术,建立索引,而这个过程实际上是一个对网站进行自动分类的过程。
例5:在机器学习和推荐算法的背后,通常系统将一个物品/内容推荐给用户主要经历两个步骤,即召回与排序(最后是推荐)。这个过程通俗的讲就是让机器去完成我们人类无法完成的对海量数据的分类,对内容或者商品进行分类,再对用户行为分类,然后对两组分类进行比对,完成推荐(当然实际过程要比这个系统和复杂的多)。
类似的场景不胜枚举,仿佛做产品,就是无时无刻不在分类,然后排序(先后,优先级)。
为什么会是这样呢?
01
俞军老师在他的书中提到,产品经理做的工作更接近于社会科学,而不是自然科学。自然科学的研究对象是自然界存在的物质,可证伪。而社会科学研究对象是人作为社会中的存在,或人与人组成的社会。由于人类意识的复杂多样,决定人类行为的互相博弈和不确定性,所以社会科学无法重复验证,得出的结论存在不确定性;另外社会科学还具有主观性的特点,对社会事物的认识和评价会受到众多主观因素的影响。
张小龙也有在公开课上表示“设计就是分类”。这种表述首先肯定是不科学的,它不能被证明;其次这一表述代表了张小龙对设计这一工作的一种认识和评价,而笔者表达了认同这一观点。笔者认为产品经理在日常工作学习中,通过强化分类这一意识,可以更高效地成长。(这里的探讨,也反映了产品设计这一工作,既要考虑用户的主观感受,也离不开设计者的主观意见)
既然“设计就是分类”不是科学,那么接下来我的解释也会是归纳性的,基于自己理解的。
其实张小龙在2012年8月的一个内部演讲中已经简单阐述了他这样说的原因:“设计就是分类,分类是人类大脑的识别模式,分类是化繁为简的方法之一,PM每天都应思考如何让事情更条理,越简单的分类越容易被接受。”
我们把他的表述断句,来列举下他说的几点原因:
1、分类是人类大脑的识别模式。
我的理解:我们认识这个世界,学习知识,储存知识的模式或者方法是分类。而设计就是在表达我们的认知。
2、分类是化繁为简的方法之一,越简单的分类越容易被接受。
这一点我觉得大家会好理解一些,简单代表着好的用户体验,分类可以帮助我们做好用户体验设计。(简单其实代表着更大的信息量,少即是多,以后有机再展开来和大家探讨)
3、PM每天都应思考如何让事情更条理。
条理代表着有序。分类是为了让研究对象变得条理,有序。如果说设计就是分类,那么设计也是为了让研究对象变得条理,有序。
那么为什么条理和有序就意味着正确和有价值呢?
02
我想这应该才是回答为什么设计就是分类的关键。
熵增与熵减,无序与有序。
1、熵,系统状态的一种量度,本质是一个系统“内在的混乱程度”。熵衡量系统的无序性。(信息熵:把信息中排除了冗余后的平均信息量称为“信息熵”。信息熵的提出解决了对信息的量化度量问题。)
2、熵增定律,在自然过程中,一个孤立系统的总混乱度、总稳定度(即“熵”)不会减小。熵增定律揭示了万物演化的终极法则,暗示着人类终将走向毁灭,整个宇宙也终将归于热寂。
3、熵减,对开放系统而言,由于它可以将内部能量交换产生的熵增通过向环境释放热量的方式转移,所以开放系统有可能趋向熵减而达到有序状态。著名物理学家薛定谔在其著作《生命是什么》中指出,生命以负熵生,其本质是一个负熵系统,一个能够通过摄入环境中的负熵使得自身不和外界环境热平衡的系统。
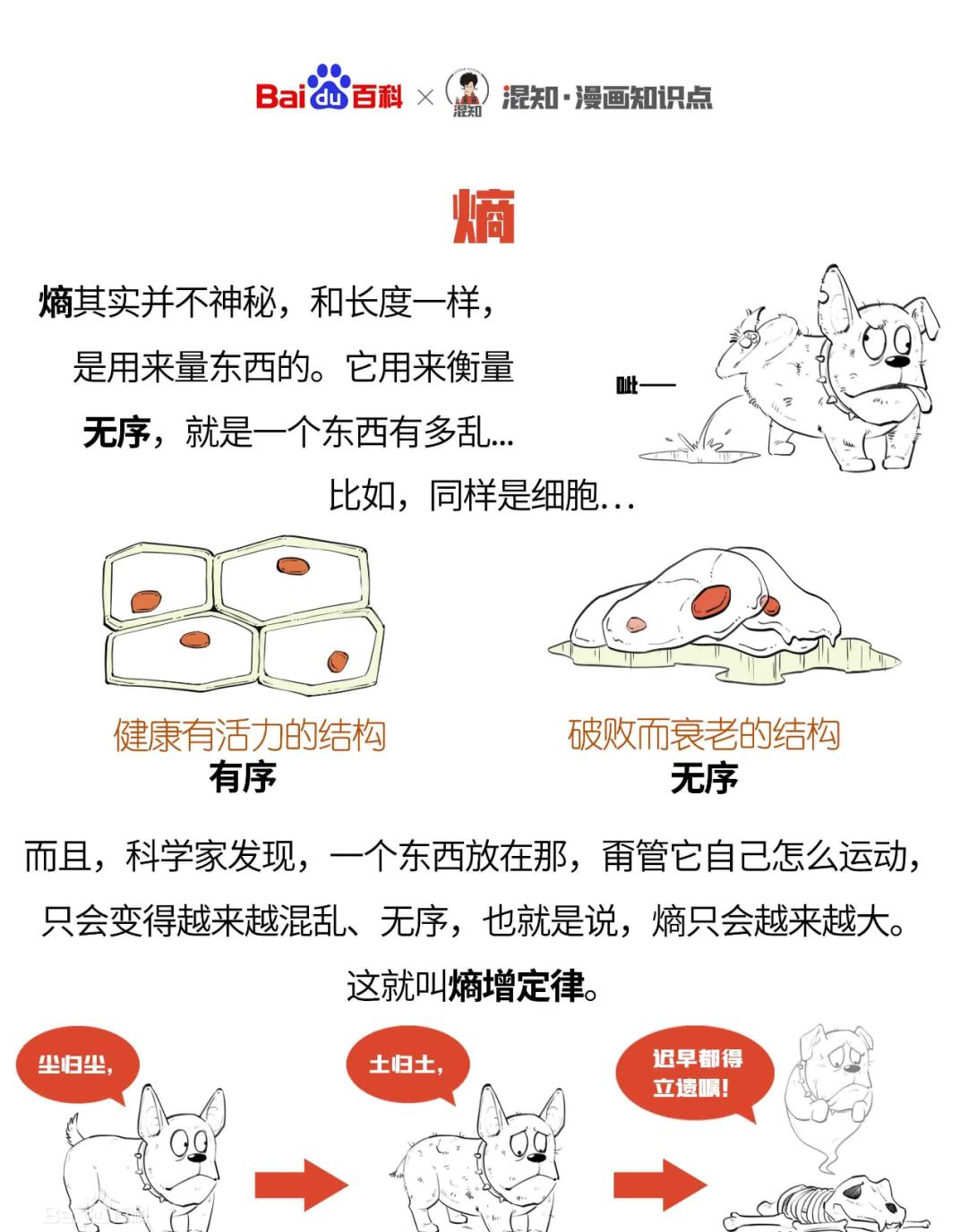
4、在物质世界,价值象征着原子的有序度。也就是有序度越高,其蕴含的价值越高。生命的诞生是原子、分子、基因、蛋白质…有序组合的结果;汽车是上万个零件有序组合的结果;芯片是硅原子有序排列的结果;一款软件是无数代码有序排列的结果,而产品经理有序排列了需求。
总结一下,熵代表系统的混乱程度,封闭系统是不断熵增的,混乱程度不断增加,直至毁灭。而开放系统通过与外部环境交换能量达到有序,即熵减。物质的构成(原子)越有序,其价值量越大。
综上,设计是一个熵减的行为。设计者吸收能量(吃饭),消耗脑细胞,对研究对象进行分类,让其变得有序,从而提高价值。
那么产品都会对哪些具体的信息分类呢?
03
其实很难穷尽,如果我们把他们抽象到最高一级,它们都是信息,对于初学者来说,这个高度的抽象就是废话,为了方便大家理解,我们试着去对这些产品经理需要关注的信息分分类(如下图):
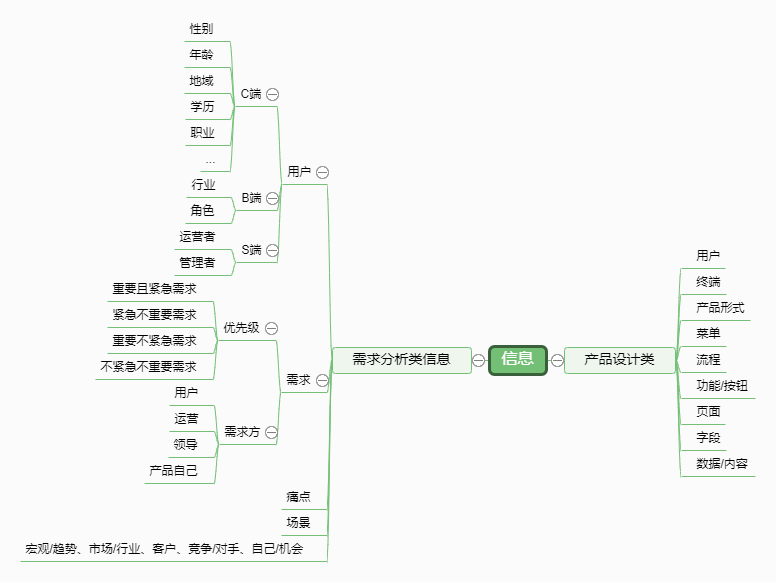
信息永远是海量的,尤其是在这么大的一个范围下去列举,很难完整,准确地列出来。仅供大家参考。
“一千个人眼中就有一千个哈姆雷特”,面对同一组信息(需求、问题),不同的人,从不同的角度,在不同的应用场景下,可以做出不同的分类,设计出最优的分类(能有效解决用户在某一场景下的问题),是优秀的产品经理必须具备的基本技能之一。
那么我们该如何分类(其实我认为没有统一的方法):
第一步:认知,对所研究的对象进行全面地认识和了解。查资料,看竞品,用户调研等。
第二步:列举,把所有有用的信息,概念,都列举出来。比如可以使用思维脑图。
第三步:合并、整理,通过抽象、归纳等方法,对所罗列的信息进行向上一级的总结或提取。这样的操作可以进行多次,最终形成一个树状的信息脑图(比较常用的信息结构,不代表全部)。
合并、整理后的信息,同一父节点的兄弟节点直接应尽可能具备以下两个特点:独立性和完整性。
独立性:同一级的信息之间,不重复,不包含。比如列举身份证号码,肯定不能重复,都是独立的;再比如需要列举歌手的姓名,周杰伦和JAY同时出现的话,可能就是重复的;在关系型数据库中(二维列表),主键(能够唯一标识数据表中的一行记录的字段)是不能重复的。
完整性:在数据库中是指数据的精确性(Accuracy) 和可靠性(Reliability),主要强调输入的数据不能有错。在产品设计中,我认为除了准确之外,还应该包括对对象描述的完整性。比如一个定义一个商品,应该有哪些字段;一个订单应该有哪些字段;一个页面哪些元素是必不可少的;合规(如用户隐私)的用户注册流程的必要步骤是什么等等。
那么独立性和完整性必须具备吗?实际设计中其实很难保证,但是如果不独立,就可能会带来重复,冗余,我们的产品很难设计的简单,甚至程序运行也会有BUG;而不完整,就可能遗漏字段、功能、流程、场景,从而不能彻底解决问题甚至根本不解决问题。
这里我还建议产品经理(包括我自己)多去了解下数据库的运行逻辑和特点。数据存储在数据库中,产品经理在对信息进行分类时,既要考虑什么样的分类能满足用户的需求,同时也要考虑什么样的分类更符合数据库的存储逻辑。比如在数据库中,数据会有树状结构、网状结构、关系型结构等,我们在做产品设计时经常会设计组织架构,最简单的组织架构就是树状的(金字塔型)。数据库本身也是一个产品,他的设计同样是为了解决现实世界的问题的,所以数据库中的很多知识点在现实世界中也是大概率同样适用的。
第四步:排序,根据所研究对象的特点或者与用户价值的相关性,或应用场景等,对其进行排序。方便在产品设计时,快速决策。(关于如何排序也是一个可以展开讲不少的话题,核心其实就是找准维度,按什么来排序)
第五步:产品经理还应该思考分类后的信息之间的相关性。好的产品是一个有机的整体,鲜活而有生命力。厘清信息之间的相关性,在产品设计时处理好它们之间的相关性,可以让用户更好地理解和使用我们设计的产品。
产品经理每天都在做分类,同时每天也都在做选择,寻找最优解,追求更有序,最终实现系统的熵减。
本文由 @李海鹏 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









咩咩……
好家伙,一篇水文把熵增定律都搬出来了,下一篇文章争取把量子纠缠也引入题干哈
哈哈,被你洞穿了
学习啦,期待作者分享更多内容
感谢感谢