
 起点课堂会员权益
起点课堂会员权益搜广推策略产品:灰盒“look alike”种子人群扩展策略(上篇)
在广告定向领域,look-alike策略的诞生帮助广告主投放保持了营销确定性范围,有助于投放效果提升,因此,look-alike定向策略也是投放策略产品需要了解的重要内容之一。本篇文章里,作者便针对look-alike策略进行了拆解分析,一起来看。

讲完白盒定向DMP策略,我们接下来讲讲广告定向领域非常经典的灰盒定向策略“look alike”目标人群扩展策略,其拥有定向能力强,用户扩展精准等特点。
首先大家需要理解一下所谓的“白灰黑”盒定向策略一般在行业中指代的就是智能化和可解释性,像白盒DMP是客户根据数据平台标签圈选的人群(代表可解释性最强,智能化能力最弱),智能定向则是一个“优选黑匣子”。
广告平台根据广告投放的主体item优中择优圈选定向人群圈投放,而Look-alike介于两者之间平衡(兼顾可解释性与效果),所以我们称之其为灰盒定向策略。
具体怎么实现与怎么定义我们在文章中详细介绍,文章下篇我们将介绍Look alike策略思想在微信RALM模型框架在看一看中的应用。
一、Look-alike定向策略诞生背景&定义
1. Look-alike定向策略诞生背景
前文给大家讲到了DMP白盒人群投放有投放人群标签和数量规模确定性的特点,广告主明确了自己的广告计划主体(商品item、视频)被展示的广告用户对象,营销结果可解释性较强,也容易做“人群投放价值”的数据分析与复盘。
但是DMP投放也存在一定的缺点:
1)人群投放规模有限&人群活跃度不可控,DMP投放包人群圈选范围过窄或者是人群活跃度偏低,例如我圈选的1W人明天都不来京东浏览,那么我的广告无法获得任何展现。
2)平台流量分配效率无法最优,DMP少数人群包投放马太效应明显,少数优质的定向人群,例如京东-plus高消费人群包,广告主集中高价投放,导致很多广告主无法拿量,而对于少数冷门DMP人群,广告主投放较少,广告投放应以UV粒度而不单单以DMP人群包视角投放整体效率价值才会更优。
基于此,为了兼顾广告主圈选人群的一定的可控性与可解释性,同时保证广告计划正常拿量&投放效果,Look-alike广告策略应运而生。
2. Look-alike定向策略定义
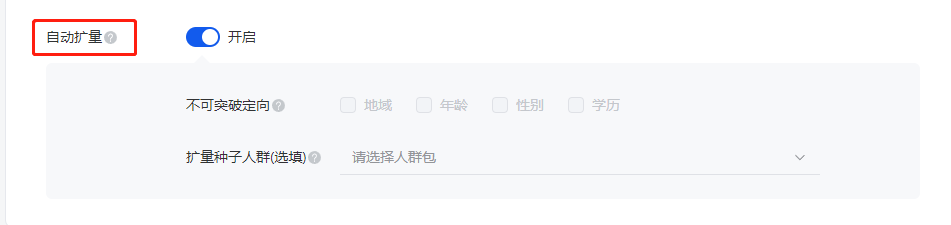
腾讯广告自动扩量工具
如腾讯广点通的自动扩量功能所示,Look-alike即相似人群扩展,即基于广告主提供的现有DMP人群包作为种子人群,通过一定的算法评估模型策略,找到更多拥有潜在关联性的相似人群的技术。通俗易懂的说,就是在保证精准定向广告主营销标的人群的同时,扩大人群的投放覆盖面。当然,平台一般也会提供类似“不可突破定向/屏蔽定向”等功能,限定某些Look-alike的探索边界,保证广告主营销范围可控性。
“ 例如广告种子人群的用户投放选择的是【青春痘皮肤医药购买者】,按照其背后的规律(例如青春期、压力大等),Look-alike会找到其对应的关联性群体【熬夜上班族、游戏玩家、世界杯球迷】等等”在挖掘相似人群的过程中,Look-alike主要依据用户基本属性及其拥有的行为信息相似性分析源头,找到相似人群。
DMP人群是Look-alike目标人群扩展技术的核心基础,我们需要依据种子人群的特征画像,用户行为来扩展,我们又叫做DMP人群为种子人群(seed user)。
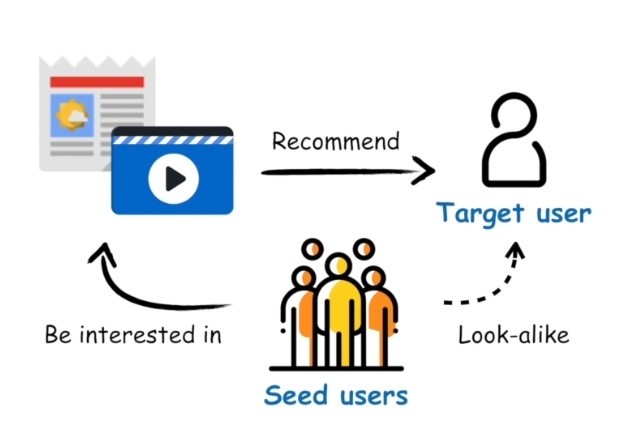
种子人群扩展原理示意
二、look-alike定向策略的具体实现
1. 常见的机器学习Look-alike策略
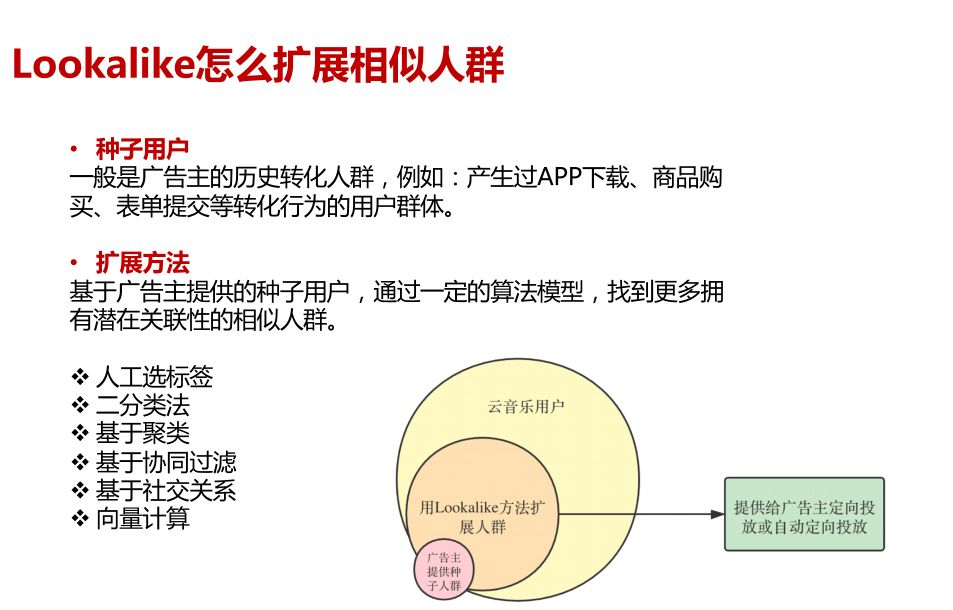
网易云音乐种子人群扩策略示意
行业当中用机器学习的防范去做Look-alike的策略其实有非常多的方式,主要也是充分利用DMP种子人群相关性的建模思路去做扩展。
基于社交关系的扩散:以具有相似社交关系的人也有相似的兴趣爱好/价值观为前提假设,利用社交网络关系进行人群扩散,一般平台会通过登录QQ、手机通讯权限或者其他社交媒体粉丝、古关注等信息进行种子人群的扩散。
人工选择标签扩散:DMP的人群圈选一般是多个标签的组合人群,如果希望去做相似人群的,可以对存量的人群进行画像的解析,然后再对标签泛化找到机会人群。
基于标签的协同过滤:在标签扩散的基础上,采用基于User-CF协同过滤算法,找到与种子人群相似的机会人群,例如在电商平台中,有点击、加购以及入会收藏多个相似商品之间的用户,计算相似余弦距离,再进行加权平均,详情可见Arthur关于推荐系统召回的文章。
基于K-Means 聚类的扩散:根据用户画像或标签,采用层次聚类算法(如BIRCH或CURE算法)对人群进行聚类,通过画像、标签内容去找到聚类相似性,再过制定相似的阈值从中找出与种子人群相似的机会人群。
基于向量相似度embedding方法:把用户user embedding,映射到对应的低维度向量当中,再根据k-means做局部敏感的hash聚类,根据用户属于哪个聚类再进行对应的推荐
目标人群分类方法:以种子人群为正样本,候选对象为负样本,训练分类模型,然后用模型对所有候选对象进行筛选,涉及PU Learning的问题。
2. 网易云音乐Look-alike目标人群扩展思路——基于向量embedding方法简述
基于用户向量表示召回相似用户,计算种子用户的向量表示与候选用户的相似度,基于相似度打分来召回相似用户。
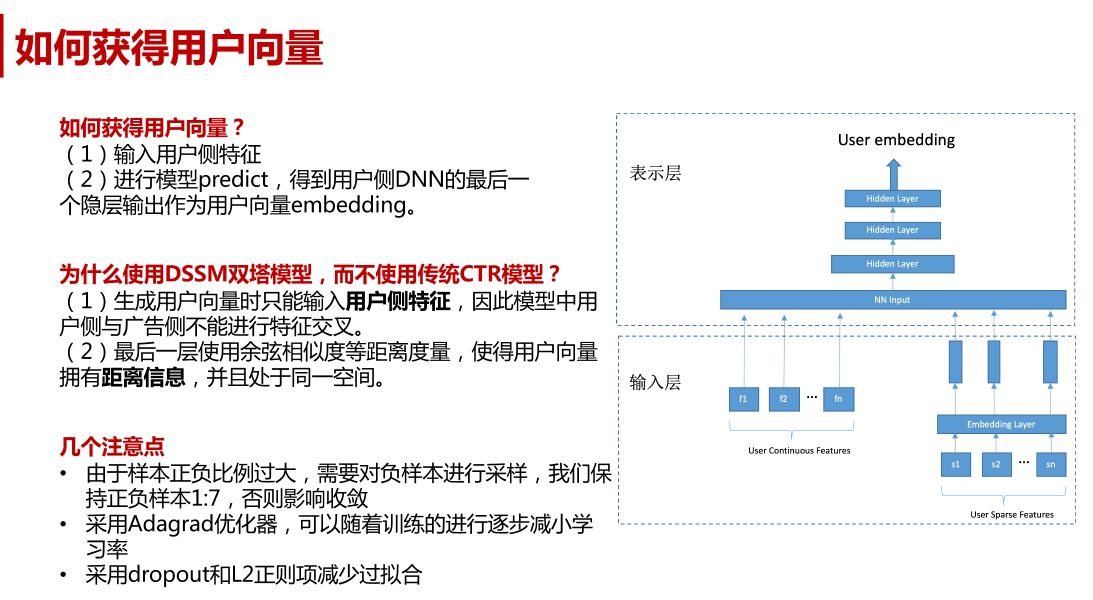
网易云音乐Look alike获取种子人群向量思路
优点:用户向量可通用,能服务于所有广告主的扩量。
难点:如何有效地学习到用户向量表示。
如何衡量种子人群相似度?
① 种子人群向量聚类;使用种子人群的K个向量聚类中心表示种子人群。
② K个聚类簇的重要程度衡量;增加种子人群每个聚类簇的历史统计CTR作为权重。
③ 候选用户与种子人群的相似度打分:
- 计算候选用户与K个聚类中心的向量余弦相似度;
- 使用K个聚类簇的权重对相似度进行加权;
- c选择选用户与K个聚类中心的加权相似度的最大值作为候选用 户与种子人群的相似度打分。
三、关于look-alike定向策略总结与思考
Look-alike策略的诞生其实在算是广告定向领域划时代的策略产品标志,在帮助广告主投放保持营销确定性范围的同时,提升了投放的效果,提升了广告计划投放的拿量获取PV、和转化效果的能力,是DMP定向往前迈入的一大步,也是定向策略的重点研究方向。
广告投放平台中的定向策略也是投放策略产品的三大方向之一,不了解定向策略也不算真正了解投放平台策略。
下一篇我们会借助微信看一看的RALM框架来详细的了解Look-alike是如何实现“准而全”的种子人群扩展,以及最后线上实验如何达成正向的效果。
作者:策略产品Arthur,5年大厂策略产品专家。
本文由 @策略产品Arthur 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









衡量种子人群相似度的第3.3,应该是指“选择候选用户与K个聚类中心的加权相似度的最大值作为候选用户与种子人群的相似度得分”吧?我看网易原文是这么写的:https://mp.weixin.qq.com/s/WGLZi29ZMle1CjRNmDZJMA
是的,最终求得的就是和种子人群用户最大相似度候选集的K个人群