
 起点课堂会员权益
起点课堂会员权益
策略产品经理必读系列—搜广推业务中如何对预估CTR进行校准
 B端产品经理需要更多地进行深入的用户访谈、调研、分析,而C端产品经理需要更多地快速的用户测试、反馈、迭代
B端产品经理需要更多地进行深入的用户访谈、调研、分析,而C端产品经理需要更多地快速的用户测试、反馈、迭代搜广推三大业务场景中都需要CTR预估模型,并基于模型预估的Pctr对内容进行排序。但我们又该在搜广推业务中如何对预估CTR进行校准?本文作者总结了相关流程,希望对你有所帮助。

一、CTR预估的保序与保距
搜广推三大业务场景中都需要CTR预估模型,基于模型预估的Pctr(Predicted CTR)对内容进行排序。但不知道各位读者有没有思考过一个问题:用户对于某个内容的单次点击概率真的是可以被预估的嘛?
因为在现实生活中,用户对于内容的兴趣度最终反馈的结果只有“点击”和“不点击”,并没有反馈是在多大概率的情况下点击的。实际工作中我们统计的Actr(Actual CTR),并不是单次的的CTR,而是在大数统计的维度上,将该内容曝光给大量用户以后,统计了所有用户对该内容的点击情况,然后得到的一个CTR大数统计值。
无法构建一个CTR预估回归模型,只能退而求其次构建一个二分类模型。
实际情况导致在CTR预估中,我们无法构建一个回归模型去拟合用户对于每个物料的预估CTR,只能通过用户实际反馈的“点击”和“不点击”来构建一个二分类模型,然后将分类模型对于正样本的概率预估值近似地视为CTR预估值。
我们在对CTR预估模型做离线评估时,针对CTR预估模型主要看的是AUC指标,AUC指标是衡量模型的排序能力,是模型将正样本排序在负样本前的概率。如果该场景仅仅只是使用CTR预估模型返回的Pctr来对内容进行排序,那么CTR预估模型只要能保证顺序的准确性即可,也就是保序能力,具体Pctr和真实点击率之间绝对值的差异有多大,其实影响不大。
但目前搜广推三大业务场景中,实际都用到了Pctr的绝对值。在搜推业务的排序公式中,Pctr是作为一个排序因子。而在广告业务中Pctr的准确性将直接影响广告收益。
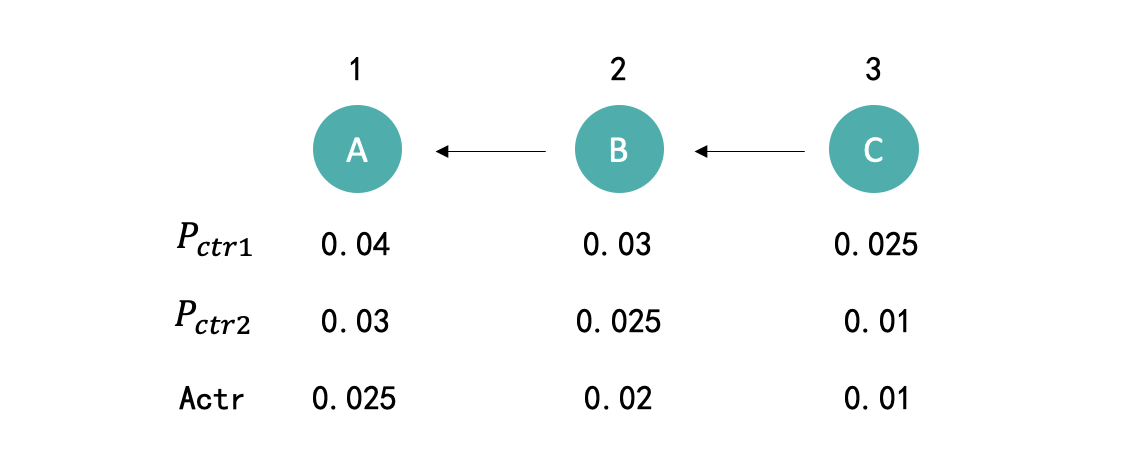
如上图所示,模型1和模型2分别对A、B、C三个不同的内容进行CTR预估并进行排序,虽然模型1和模型2对于内容的排序顺序都是正确的,但是很明显模型2预估的Pctr和内容实际的Actr更接近。如果从离线AUC指标上来说模型1和模型2的AUC是完全一样的,但很明显模型2的预估效果是要优于模型1的。如果模型本身只是将内容进行排序,那么模型1和模型2达到的效果是一样的,但是在广告业务中确不是。
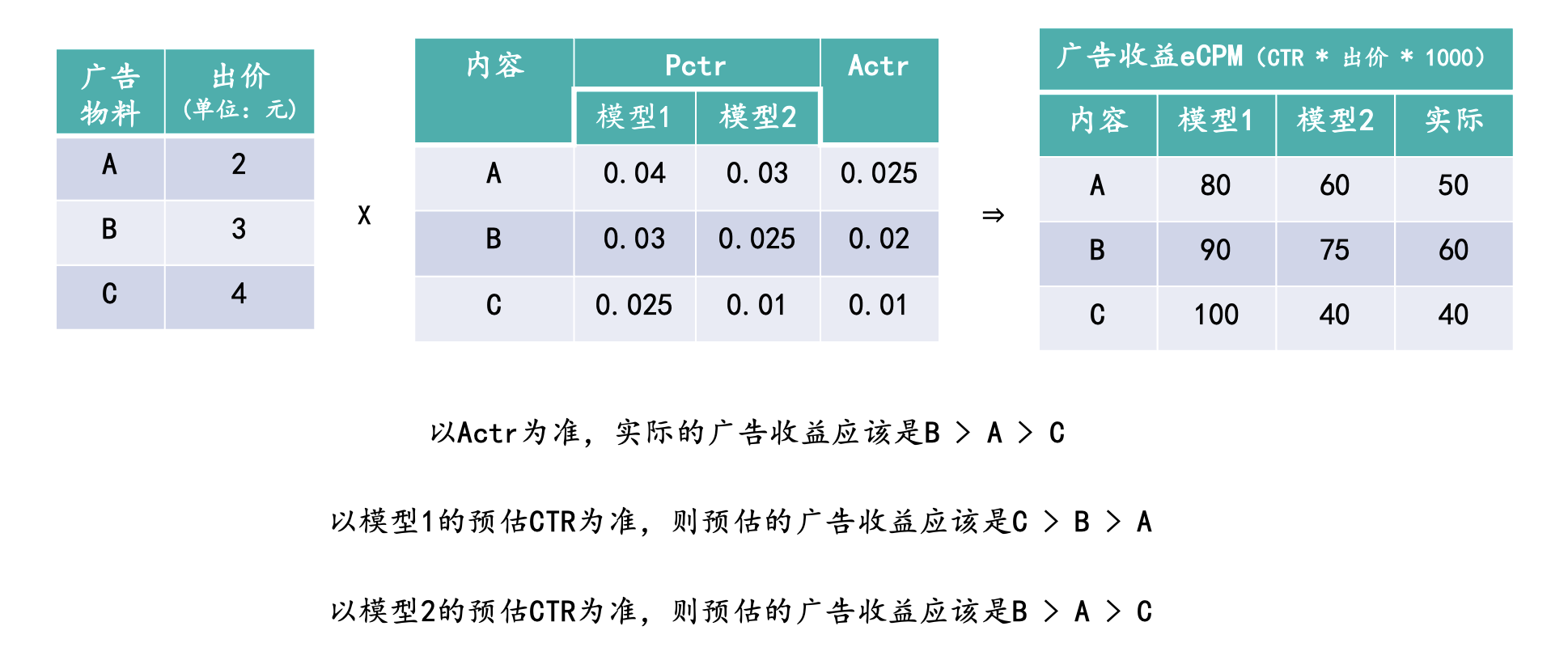
如上图所示,在广告业务中以点击来进行扣费,假设内容A、B和C分别对应的点击收益是2元、3元、4元。广告业务中的物料排序是以eCPM来排序,eCPM = CTR * Bid(出价)* 1000。 如果以Actr为准,实际广告收益应该是B > A > C,这也是最终的理想排序。模型2的排序结果就是和理想排序一致的,但是模型1的排序结果是C > B > A。虽然模型1和模型2对于物料的CTR预估排序顺序是一样的,都是A > B > C。但是实际应用时结合了其他业务指标后,模型1的效果就不如模型2了,根本原因还是模型1对于CTR的预估和实际后验CTR之间的差距太大。
所以模型在进行CTR预估时,不仅仅要保序还需要保距。 既要保证排序的准确性,又要保证具有一定区分度,且区分度最好要无限接近真实水平之间的差异值。
但是实际CTR模型预估时总会和真实的概率值存在一定偏差,所以目前在互联网公司搜广推业务里都会有CTR纠偏模块,专门去对CTR预估模型给出的Pctr值进行再一次纠偏。纠偏技术的目标就是将用户行为的预估值尽可能逼近真实概率值。这里读者可能会疑问,上文介绍单次真实点击概率是没法被观测到,那么我们应该以什么为标准来进行纠偏了。目前行业里面统一用大数统计维度的后验CTR来作为纠偏标准,但是这里的后验CTR统计是有技巧的,本文第三部分我们展开介绍。
二、CTR差异产生原因
在我们介绍CTR纠偏方法前,我们需要先了解预估CTR(Pctr)和真实CTR(Actr)之间的差异是怎么产生的。只有弄清楚差异产生原因才能更好地去调整模型和对结果进行纠偏。CTR差异一般有以下两个原因:
1. 模型训练中正负样本有偏采样导致的
CTR预估模型训练时,我们一般以实际的点击曝光日志来作为训练样本,曝光且点击数据为正样本,曝光未点击数据为负样本。但实际点击数据会比较稀疏,点击和未点击的数据比例可能在1:100或1:1000。模型训练时针对点击数据,模型需要全量学习的。但是因为曝光未点击数据量太大,实际训练时我们会进行随机采样,控制正负样本的比例在1:10左右。因为正负样本比例和实际真实数据分布存在差异,最终模型对于CTR的预估会比较接近训练数据集中正负样本的分布,CTR平均值会在10%左右。
可能有读者会疑惑,既然有偏采样会导致CTR的差异,那么能不能不有偏采样,直接使用全部数据来进行训练。部分业务场景下是可以这么做的。但如果部分业务场景下负样本数据过于庞大,导致模型训练时间很长,算力消耗很大,这时候不得不丢弃一些负样本。
2. 模型构建本身就不可能完美
除了有偏采样,模型构建本身就不可能完美。无论是特征选择还是神经网络搭建,各个部分一定都会存在某些不完美的地方,最终模型预估出来的Pctr就会和真实点击概率存在一定偏差。只有不同模型可能偏差大小不一样,但是一定都会有偏差。
三、CTR纠偏的方法
那么实际工作中如何对CTR进行纠偏了?一般我们有以下两大类方法:基于先验知识的调整和后处理方法CTR校准,下面我们分别展开介绍。
1. 基于先验知识的调整
针对已知可能导致CTR有偏的因素,在模型构建和训练时就提前反向引入特征处理或者对损失函数进行调整,端到端来优化Pctr。这种方法在于我们得提前知道哪些因素可能会导致CTR有偏,不过我们即使做了基于先验知识的调整,最终Pctr肯定还会存在偏差,因为模型不可能完美。因此也就引出下面第二种CTR纠偏的方法:后处理方法。
2. 后处理方法CTR校准
基于后处理方法的CTR校准,首先在系统架构上需要单独加一个校准模块,将CTR预估和CTR校准完全解耦开。此种方式更加灵活即插即用。基于先验知识的端到端的优化方式,整体周期太长,无法快速响应线上环境的剧烈变化,尤其是在大促期间线上环境变化非常频繁,我们需要更加轻便灵敏的模型校准能力,此时后处理方法就很适合。
后处理方法都是基于后验CTR来进行校准,前面也提到了单次真实点击概率不可被观测,那么我们只能使用后验CTR来代替真实点击概率进行校准。这里就衍生出一个新问题,如何去统计后验CTR。读者可能觉得这很简单,直接统计推荐内容的点击曝光次数然后进行计算。这种统计方法会导致单个内容的CTR是一个统一的值,原本不同用户对于该内容的兴趣度应该是不一样的,但是现在变成了千人一面。我们需要统计后验CTR,但是后验CTR的统计却很有技巧。
如何统计后验CTR(Actr)
目前行业里通用的做法一般是以请求PV为基本维度,将各类特征相似的请求PV划分为一个簇,然后统计该簇的后验CTR作为所有划分到该簇里面PV的真实点击概率。这里我们认为特征相似的请求对应的用户行为也会比较类似,CTR上的表现也会比较一致。按照特征相似性我们可以将请求分为K个簇,分别统计每个簇的CTR。K不能太大,否则单个簇里面的数据就会很稀疏,我们需要保证单个簇内的数据量是置信的,当数据小于某一个阈值时我们就需要进行簇之间的合并。
当我们统计出Actr后,我们就可以基于Actr进行Pctr的纠偏了。下面介绍行业里比较常见的两种方法:
方法一:基于负样本采样率调整CTR
本文Part2里面提到预估CTR存在偏差一部分原因是因为正负样本有偏采样导致的,所以CTR校准中一种方法是基于负样本采样率来调整CTR。Facebook公开的论文《Practical Lessons from Predicting Clicks on Ads at Facebook》里面提到一种基于负采用率来进行CTR纠偏的计算公式,计算公式如下:

同时该论文还提到在Facebook的实际业务应用中负采样率为0.025时效果最好。
方法二:保序回归
保序回归法目前是业界最常用的校准方法。常见的算法是保序回归平滑校准算法(Smoothed Isotonic Regression,SIR)。整体执行步骤如下:
Step1—区间分桶
首先将Pctr值从小到大进行排序,然后按照区间分为K个桶。假设我们分为100个桶:(0,0.01], (0.01,0.02], (0.02,0.03],…, (0.99,1]。这里我们认为精排模型给出的Pctr值是具有参考意义的,同一个区间里的PV请求具有近似的真实点击率,每一个区间可作为一个合理的校准维度(分簇维度)。然后实际应用时,我们再统计每一个桶里的后验CTR值。比如今天线上一共有1000次预估的Pctr落在了桶 (0.02,0.03]之间,然后我们统计这1000个预估的后验CTR,假设后验CTR为0.23%。关于每个桶里Pctr和Actr平均值的计算公式如下:

Step2—桶间合并
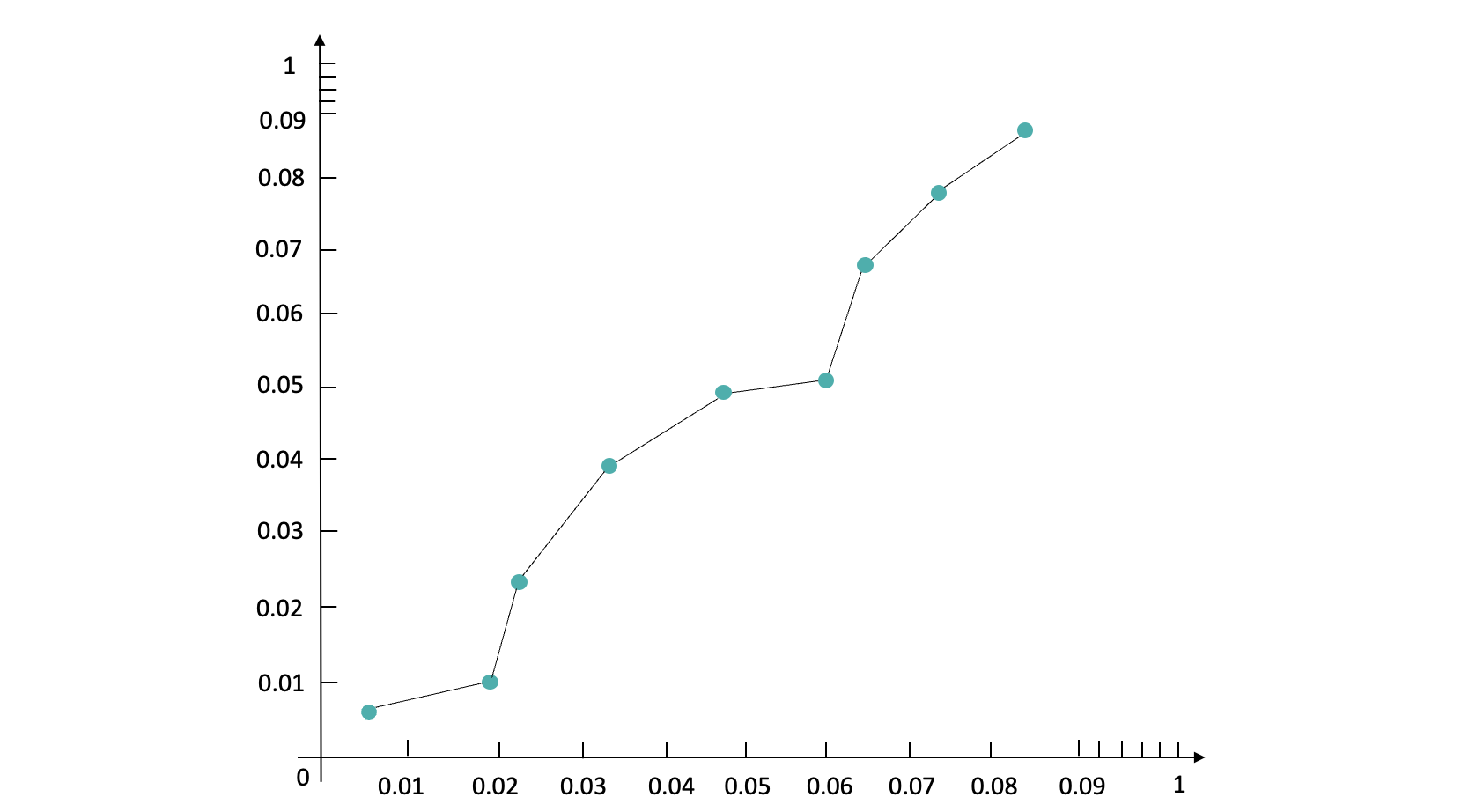
如果说后验CTR的值超出了对应分桶的PCTR取值区间怎么办?假如原本分桶在(0.02,0.03]之间结果的后验CTR为0.35%,这时已经进入到了下一个桶里了(0.03,0.04]。如果我们将原本Pctr在(0.02,0.03]桶里面的值往下一个桶里的区间值进行校准,这就破坏了原有桶之间的顺序,保序回归的基本逻辑是不能破坏原有Pctr的顺序。此时我们需要把(0.02,0.03]和(0.03,0.04]桶进行合并得到新的桶(0.02,0.04],再重新对落入两个桶里的数据进行后验CTR统计,得到新桶里面的 Actr和Pctr平均值。我们以Pctr为x轴,Actr为y轴,最终得到一个如下图所示单调递增的散点图:
Step3—桶间插值分段校准
我们需要基于上述散点图去构造一个校准函数,输入x值以后就可以输出校准后的y值。如果直接拟合一个y = kx + b函数,最终预估的结果不够平滑。目前业界的标准做法都是构造分段校准函数。
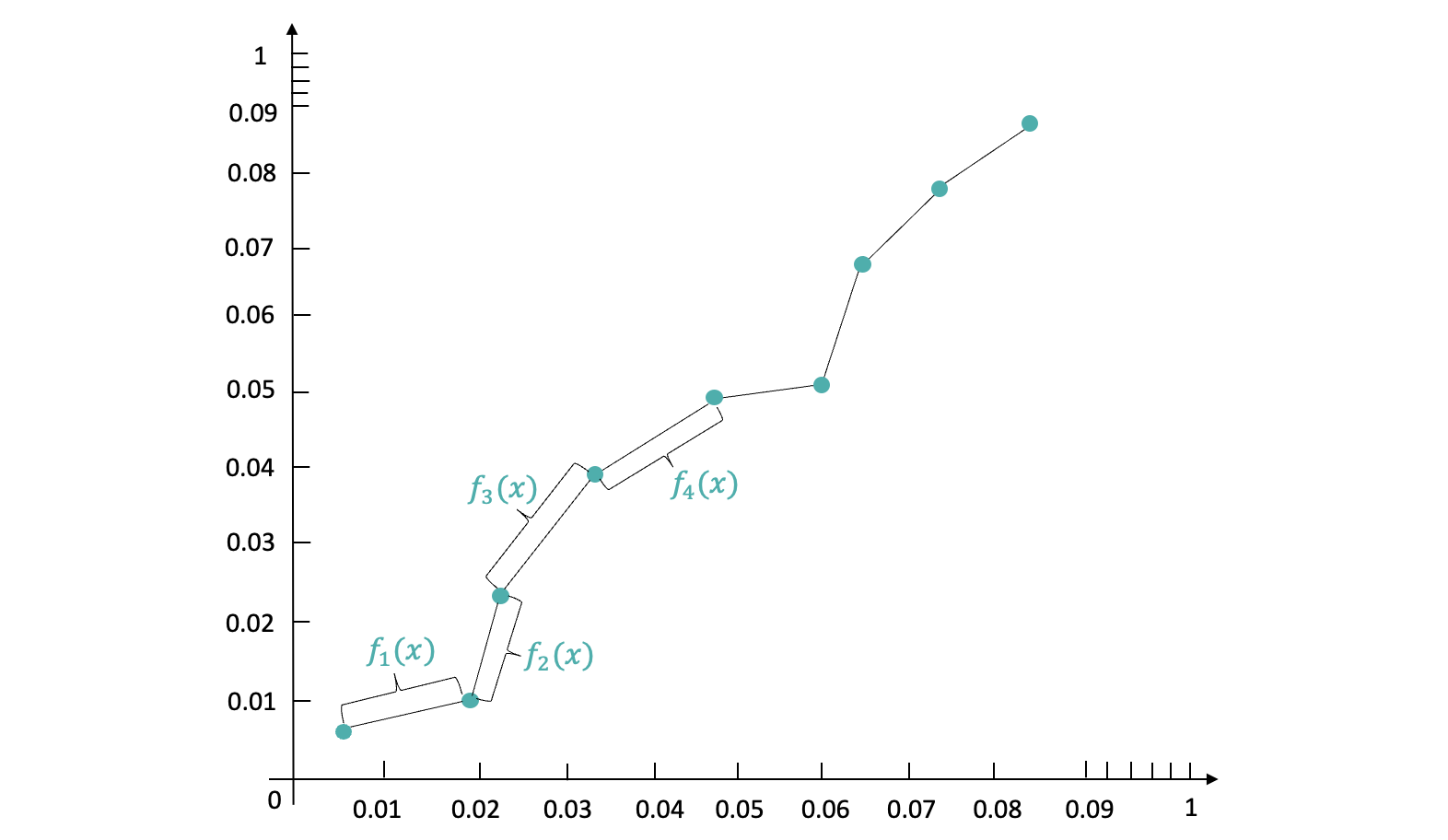
如上图所示,我们将两个桶之间坐标点连接起来,然后去构造一个分段的y = kx + b校准函数,假设Pctr一共分为了100个桶,那么最终就构造100个分段校准函数,这样既保证单调性,又保证平滑地校准。分段的校准函数如何得出,这里就是基础的初中数学知识,已知两点坐标计算对应的y = kx + b。
保序回归法的整体思想就是:不改变原有数据的Pctr排序,仅在原有Pctr的排序上进行纠偏。最终纠偏出来的CTR数据分布的单调性不变,AUC指标不变。
本身因为特征选择和样本采样导致的CTR偏差,需要基于先验知识的特征调整和基于负样本采样率的方法来对CTR进行纠偏。如果精排模型输出的Pctr和Actr差异很大,这种是无法依靠校准模块来进行纠偏的。
3. 校准评价指标
当我们使用上述的方法对CTR进行纠偏以后,我们使用什么指标来评估纠偏效果的好坏了?一般我们使用PCOC和Calibration-N两大指标。
PCOC(Predict Click Over Click)
PCOC = Pctr / Actr
PCOC指标越接近于1,意味着CTR预估的越准确。PCOC > 1,则代表CTR被高估;PCOC < 1,则代表CTR被低估。但PCOC指标是统计所有PV的Pctr和Actr效果,这里面可能会存在一定的统计偏差。假设样本里有50%PV的CTR被高估了,50%PV的CTR被低估了,最终二者汇总在一起时PCOC可能还是趋近于1。
Calibration-N
为了解决上述PCOC指标可能存在的统计偏差,我们使用一个新的指标Cal-N。首先将统计样本分为几个簇,然后按照簇分别去统计PCOC指标,再分别计算各个簇PCOC指标与标准值1之间的偏差,最后进行汇总。这种统计方式就可以避免单独的PCOC指标里可能存在的统计偏差。
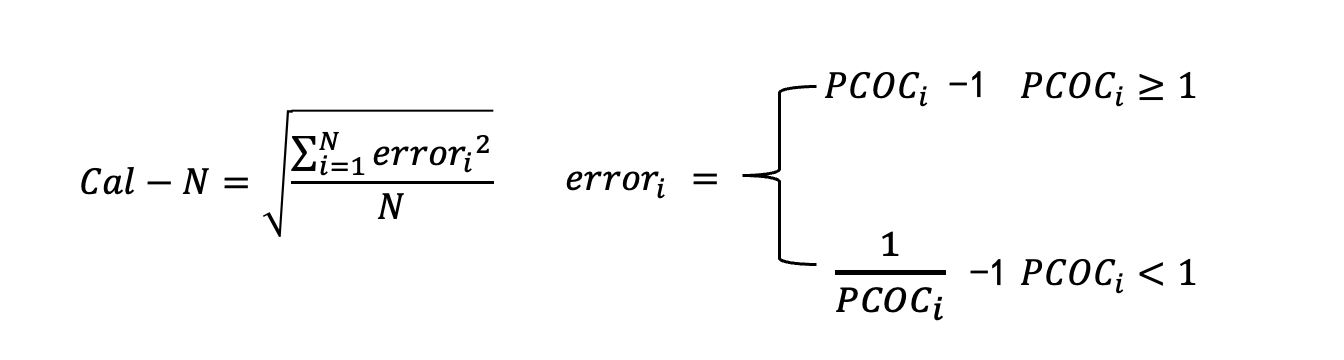
如何去将样本分簇?其实这里的分簇方法和Part2.2里面如何分簇去统计后验CTR的逻辑是一样的,二者保持一致即可。
同时在广告业务中,我们可以基于广告主已经帮我们分好的簇进行统计。因为广告业务中,整个广告层级是分为:计划 (Campaign)-单元(Group)-创意(Creative)。广告主一般都是在整个计划或单元维度观察整个效果,所以我们在进行PCOC指标统计时,就可以将每个投放单元视为一个簇。
本文由 @King James 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。







- 目前还没评论,等你发挥!









