
 起点课堂会员权益
起点课堂会员权益策略产品经理干货系列之推荐系统离线评估方法与指标介绍
不同的评估方法存在不同的优缺点,所以在进行推荐评估时,要详细了解其指标,选择合适的评估方法。本篇文章将分享推荐系统离线评估方法,帮助策略产品经理高效地完成工作。希望能对你有所帮助。

今天想就所有策略产品比较关注的推荐系统评估方法展开系列文章介绍,给大家从头到尾讲清楚推荐系统的评估度量衡,同时也是帮助大家明确作为策略如何基于不同的场景确认优化的标的方向。
本系列将基于离线评估、Replay方法、interleaving方法以及线上AB测试的视角来给大家从头到尾讲清楚策略产品对于推荐系统评估体系的搭建,各种评估方式的优缺点及其应用场景,让每一位策略产品对于评估效果的选择了然于心;欢迎大家对于本文进行讨论。
一、推荐系统的评估体系
核心要点:一个成熟的推荐系统评估体系应该综合考虑评估的效率和正确性,利用较少的资源位,快速筛选出效果更好的模型。
对于一个公司来说,最公正和合理的评估方法及时进行线上测试,评估模型是否能够更好达成公司或者团队的商业目标。
但是光使用线上A/B的测试方法要占用宝贵且有限的线上流量字眼,并且可能会对用户体验造成伤害。
所以,正是由于线上测试的种种限制,“离线测试”才成了策略产品退而其其次的选择。离线测试可以利用近乎无限的计算资源,快速得到评估结构,从而实现模型的快速迭代化。
所以,并不是一种单一的评估体系即可满足所有的评价场景和标准,作为策略产品,应该深刻的知晓和运用每一种评估方法去做到评测效率和正确性的平衡。
1. 推荐系统评估体系概述
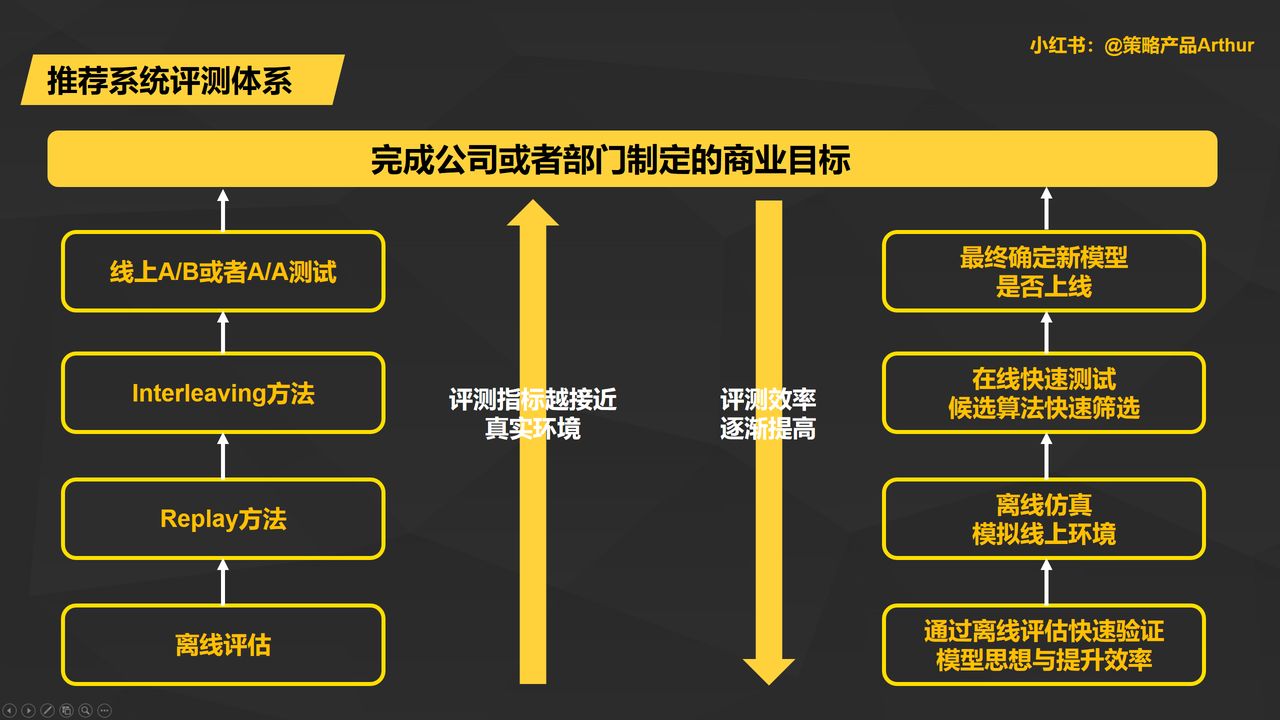
从上图可以看出,在线上A/B测试(最接近线上真实环境)和传统的离线评估(评测的效率最高)之间,还有Replay和Interleaving等测试方法。
- Replay方法是用来最大程度在离线状态下模拟线上环境的过程。
- Interleaving方法则可以建立快速的线上测试环境。
这种多层级的评估测试方法共同构成了完整的推荐系统评估体系,做到评测实现计算效率和线上真实性反馈的平衡。
2. 应用场景
1)评估效率适用场景
可以看的出来离线评估需要快速验证模型的思想和提升效率,因此存在更多筛选的模型和验证改正思想的时候。
由于数量巨大,“评估效率”就成为了最为关键的考虑因素,线上反馈的“真实性”就没有那么苛刻和高要求,这时候就应该选择效率更高的离线评估法则。
2)线上真实性反馈适用场景
候选模型被一层层筛选出来之后,接近正式上线接单,评估方法对于是否能够真实反馈线上环境更加重要。
在模型正式上线前就需要做最接近真实产品体验的A/B测试做模型评估,产生最具说服力的——业务商业指标,才能进行模型上线,完成模型迭代优化过程。
二、离线评估的方法
- 定位:在推荐系统评估当中,离线评估往往被当做是最常用也是最基本的评估方法。其核心是指在模型部署在线上环境之前,在离线的环境进行评估。
- 优点:1)由于不用部署到生产环境当中,离线评估就没有线上部署的工程风险,也不用浪费线上流量的资源;2)测试时间短、同时可以进行多种并行测试,能够利用丰富线下资源等优点。
- 能力要求:对于策略产品充分掌握离线评估的要点,需要掌握两个方面的知识:一是离线评估的方法有哪些;二是离线评估的指标有哪些。
离线评估的基本原理大家比较熟悉,主要是在离线环境当中,讲数据集分为“训练集”和“测试集”,用“训练集”来训练模型,用“测试集”来评估模型。
根据数据集划分方式不同,离线评估的方法可以分为Hold out检验、交叉检验和自助法。
1. Hold-out留出法
Holdout检验是基础的离线评估方法,其将原始的样本集合随机划分成训练集和测试集。
对于一个推荐模型来说,可以把样本按照90%-10%的比例随机划分成两个部分,90%用来做模型的训练集,10%用来做模型的评估测试集。

Holdout检验的方法会存在一定的缺点,也就是在验证集上计算出的评估指标与训练集和测试集的划分有直接的干系,如果进行少量的Holdout检验,则得到的结论会存在比较大的随机性。
所以,为了消除随机性影响,“交叉检验”法被提出。
2. 交叉检验法
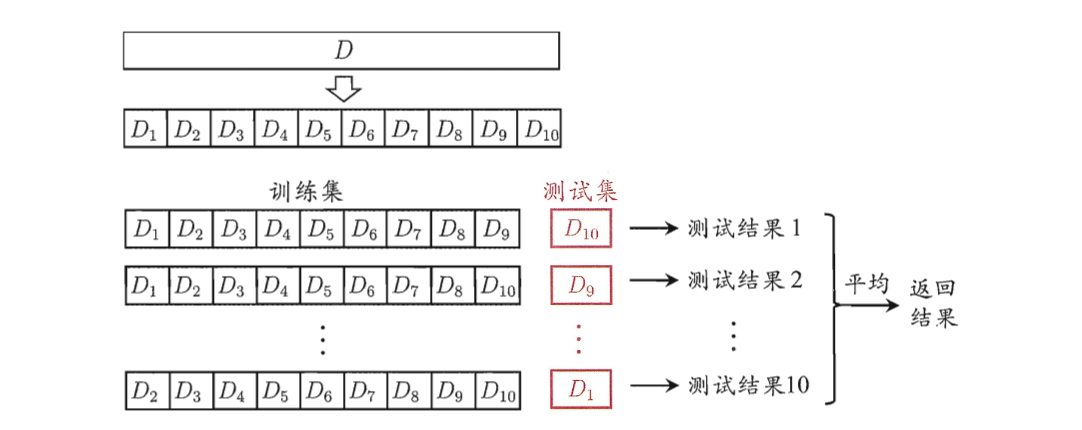
1)K-fold交叉验证法
把全部样本划分成K个大小相等的样本子集(K取决于样本集合总数,一般行业实验取10),依次遍历K个子集,每次会把当前的子集作为验证集,其余所有子集当做是训练集,进行模型的训练和评估。
最后把K次评估的指标的平均值作为最终的评估指标,这个在之前机器学习的章节有提到过。
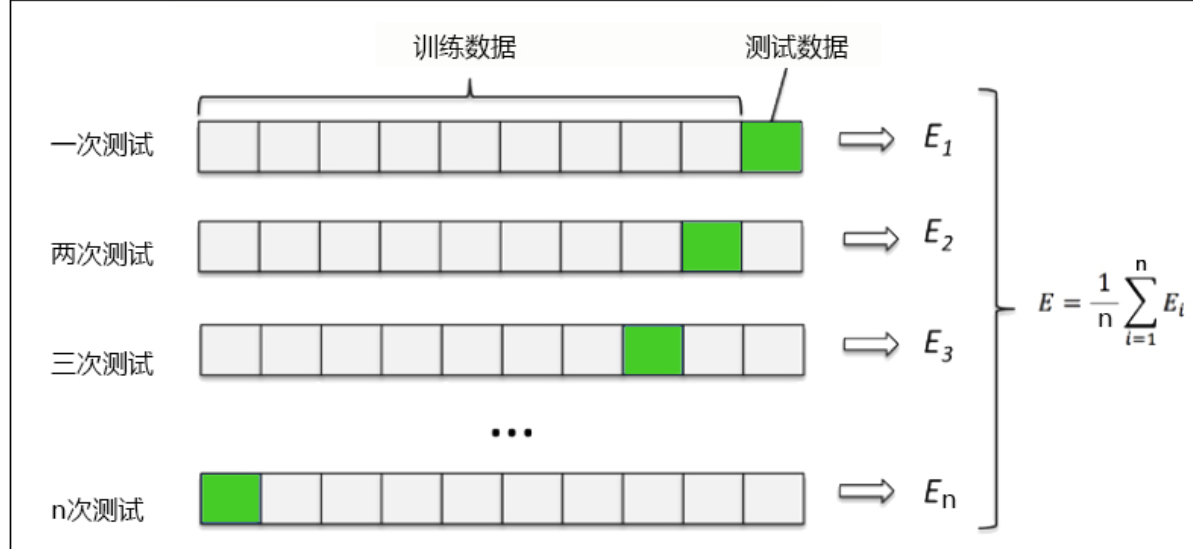
2)留一验证法
和K-fold交叉验证的思想比较类似,每次就留1个样本作为验证集,其余所有样本作为测试集。
样本总数n,依次遍历n个样本,进行n次验证,再将评估的指标进行平均求得最终指标。缺点就是样本多的情况下,验证的计算和时间成本很大。
事实上,留1验证是留p验证的一种特例。留p验证就是指代n个样本集合中每次留p个样本来做验证集。
3. 自助法Bootstrap
前面提到的关于Hold-out留存法,或者是交叉检验法都需要划分测试集和训练集进行模型评估。然而当样本规模比较小的时候,划分验证集会进一步让训练集减小,最终影响模型训练的效果。
所以诞生了自助法(Bootstrap)自助采样的检验方法:对于总数是n的样本集合来进行n次有放回的随机抽样,得到大小为n的训练集。
在n次采样的过程中,有的样本被重复采样,有的样本没有被抽样过,把这些没有被抽样的样本作为验证集合进行模型验证,这就是自助法验证过程。
三、离线评估的指标
要客观评估一个推荐模型的好坏,那么就需要有一个客观的度量衡指标来进行评估,并且需要多个角度的指标来评估推荐系统,从不同的视角来得到多个维度的结论。
以下是推荐系统在离线评估当中使用的比较多的指标,其实在之前介绍推荐系统排序模块的时候就有给大家概述性介绍,从混淆矩阵的视角出发说明准确率(Accuracy)、召回率(recall)和精确率(Precision),这里我们再详细介绍一下。

混淆矩阵说明
我们通过举例的方式让大家更加容易理解,首先,我们来理解混线矩阵当中的几个概念,用推荐系统举例方便大家理解。
- TP(True Positive)在混淆矩阵中的意思就是模型预测item被点击并且实际也被点击。
- FN(False Negetive)在混淆矩阵中的意思就是模型预测item不会被点击但是实际被点击。
- FP(False Positive)在混淆矩阵中的意思就是模型预测item会被点击但是实际不被点击。
- TN(True Negtive)在混淆矩阵的位置就是预测不被点击实际也是曝光未点击的结果。
1. 准确率(Accuracy)
准确率代表分类正确的样本占据总样本的个数比例,也就是:
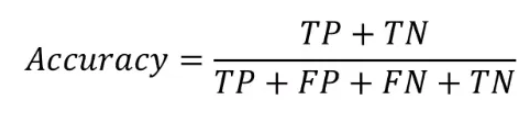
其中分母代表总样本数量,分子代表的是无论是预测会被点击还是不被点击,预测结果和实际结果保持一致的的样本数量。
准确率是分类任务当中比较直观的评价指标,虽然有比较强的可解释性,但是也存在明显缺陷。就是当不同分类的样本不均匀的时候,占比大的类别往往就成为了影响预估准确率的主要因素。
如果负样本占比是99%(即100个曝光后的样本都是未点击),那么把所有的样本去预测成负样本都可以获得99%的准确率。
如果把推荐问题当做是一个点击率预估方式的分类问题,在选定阈值进行正负样本区分的前提下,可以用准确率评估推荐模型。
而在实际场景当中更多是利用推荐模型得到一个推荐序列,因此更多用精确率和召回率指标来衡量好坏。
2. 召回率(Recall)与精确率(Precision)
召回率代表分类正确的正样本数占比所有真正的正样本数的比例,也就是:
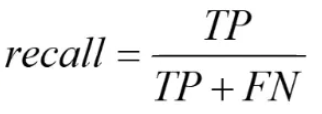
考察的是推荐系统模型当中在做分类任务时候把所有实际为正样本预测成正样本的能力,更多考察的就是对正样本的覆盖情况。
精确率是分类正确的正样本数量占比分类器判定成正样本的样本个数比例,也就是:
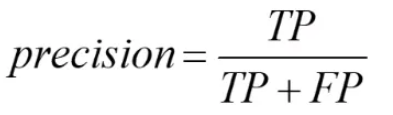
代表着推荐系统模型在做分类任务中分类预测正向样本的精准程度。
精确率和召回率是矛盾统一的两个指标:即为了提高精确率,分类器需要尽量在“更优把握的时候”才把预测样本预测为正样本,但是往往会因为过于保守的预估而漏掉很多“没有把握”的正样本,导致召回率变低。
所以为了综合的反映精确率和召回率的结果,可以采用F1-score,F1-score代表的是精确率和准确率的调和平均值。
其定义如下所示:
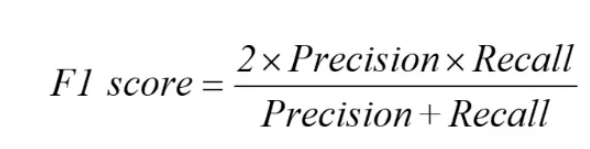
3. 均方根误差 RMSE & 绝对百分比误差 MAPE
均方根误差(Root Mean Square Error,RMSE)经常被用来衡量回归模型的好坏。
使用点击率预估模型构建推荐系统的时候,推荐系统预测的其实是样本为正样本的概率,就可以用RMSE来评估。
定义如下:
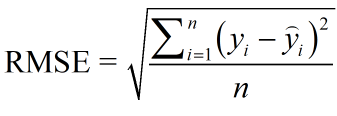
其中yi表示第i个样本点的真实值,而括号内的后者代表的是第i个点的预测值,n表示的是样本点的个数。一般情况下RMSE能够很友好的反映出预测值和真实值的偏离程度。
但是也存在一个明显的缺点,就是如果个别点的偏离程度非常大(俗称离群点),即使离群点非常的少,也会使得RMSE指标变得比较差。
所以为了解决这个问题,提出了鲁棒性更强的平均绝对百分比误差MAPE(Mean Absolute Percent Mape)。
MAPE的定义公式如下所示:
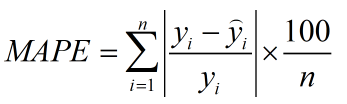
相比较RMSE,MAPE把每个点的误差做了归一化处理,降低了个别的离群点带来的绝对误差影响。
4. 对数损失函数LogLoss
对数损失函数LogLoss也经常在二分类问题用于离线评估使用的指数,LogLoss定义如下:

其中,yi为输入实例xi的真实类别,pi为预测输入实例xi是正样本的概率,N为样本总数。
其实LogLoss就是逻辑回归的损失函数,大量深度学习模型的输出层正是逻辑回归或者是softmax,因此采用LogLoss作为评估指标可以非常直观的反映模型的损失函数变化。
非常适用于观察模型收敛情况的评估指标。
四、关于离线评估方法与指标介绍
本篇主要是针对日常策略产品工作中推荐系统离线的常用评估方法和评估指标做了详尽的介绍。
离线评估是推荐系统评估效率最快的一种方式,但是其缺点也较为明显,即无法准确的反馈模型策略变更对于线上产生的影响效果,以及和业务场景结合的指标效果体现,这些都是离线评估方法的缺点。
但同时线上评估方法会存在诸多评估效率的问题。因此推荐系统策略产品需要明晓什么场景下应当选择使用什么类型的评估方法,来达到准确真实性和效率的平衡。
关于离线评估方法和对应的指标文章也介绍了对应的优势和缺点,复杂的推荐系统需要综合不同的指标来进行全貌了解。
希望本篇文章能够给大家引入对于推荐系统评估的方法论建议,有帮助还辛苦大家点赞、评论以及收藏三连。
本文由 @策略产品Arthur 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。









很经典的评估方法,只不过这个描述里面例子太少了,也不够巨像,这么写的话,除了那些做推荐或者做策略的同学,其他人恐怕都是一头雾水
感兴趣策略产品同学可以关注Arthur主页
没看懂,这个东西会用在什么地方吗?
这个主要是推荐系统策略产品用于离线评估推荐模型离线效果的衡量方法,属于垂直行业产品经理的工作经验文章分享。