
 起点课堂会员权益
起点课堂会员权益
指标管理系统从0到1,从规划到落地,这篇文章手把手教会你
 产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。
产品经理的不可取代的价值是能够准确发现和满足用户需求,把需求转化为产品,并协调资源推动产品落地,创造商业价值。为了做好指标管理,企业可能会落地一套指标管理系统以解决问题,但实际上,指标管理系统想做好可能并不如想象中的那么容易,这其中有很多坑需要我们提前避开。这篇文章里,作者就做了解读,一起来看看吧。

假如你所在的企业业务发展迅猛,在强调用好数据的当下,如果没有好用的系统,肯定都会逐渐碰到如下问题:
- 不知道有啥:企业数据资产多如牛毛,但知道和找到对的数据却困难重重;
- 需求满足慢:搞清楚自己该要啥该找啥,你会发现公司业务多变化快,需求多,取数人力不足;
- 指标对不齐:数据变更快,变更记录不及时,数据来源多、数据处理人员多、口径多,多份数据对不齐;
- 问题排查慢:系统数据出问题,数据加工链路长,碰到人员流动和交接,问题排查慢,修复耗时长。
发现数据问题,定位数据问题,解决数据问题,经常搞得基层员工焦头烂额(如果你在基层干过,真的而是叫天天不应叫地地不灵)。千里之堤溃于蚁穴,这些看似不起眼的小问题,慢慢就会积攒成大问题,甚至会严重影响到整个组织的日常工作、战术目标达成、战略愿景的实现,落后的生产力和需求严重不匹配时,当非技术出身的管理层、领导层都能感受到问题的严重性时,于是,就可以从上而下开展轰轰烈烈的优化治理专项。
这种企业信息化升级,往大了说,可以说是数据治理、数字化转型之路。一般来说,大家说的都是构建高效智能的数据中台,数据治理可能也提上了日程。数据治理的核心是什么?核心是统一数据口径。数据口径的抓手就是【指标】。
从产品的视角来看,指标管理最终的目标是:让大家能清楚看到、方便用到。
一、前期规划
市面上关于【如何建立指标体系】的方法论一搜一大堆,相对而言,讲如何构建指标管理系统的少了不少,不过只要耐心搜寻,大厂的竞品就等着你发掘,而且文档还比较全。等你拥有了这些参考信息,系统就实现了80%了,因为功能和界面交互都很好抄,就差工程师帮你把系统开发出来了。
但其实指标管理系统想做好并不容易,因为可能做完系统,进行指标管理落地时,更多问题会凸显出来,尤其是在业务已经发展起来的阶段。
作为一个有很多失败经验的老产品,接下来给你分享一些微不足道的经验。
第一,你要定位问题。
你要搞清楚,这个系统到底要解决什么问题,现状是怎么样的。谁在推动做指标管理、指标治理这件事情。
很多时候,推动这件事情的人,是带有研发背景、数据分析背景的领导,而这些领导规划做这件事,也不是很清楚呢。或许是因为看了一场其他同行的分享,被案例里的故事给说服了,然后开始未雨绸缪提前规划这件事情。但是,在你规划系统去解决问题之前,问题真的被定位了吗?可能也不好定量描述问题有多严重,当前的损耗有多大,那是否有人定性地进行了描述呢?
领导对这块问题的认知是什么,如果没啥认知,让我们解决的问题是什么呢?你可以把这些问题抛出来,问那个任命你来做这件事的人。这个问题是否在更高的层面拉通了认知,能争取到多少解决问题的时间窗口,多少资源。
世人都晓神仙好,惟有功名忘不了。“做好数据治理,科学管理指标,数据驱动业务”,大家都会喊口号,为的是做成之后拿好处,可是真正能落实的人,并不多。很多时候,我们不敢提问,不敢抛出问题,组织让我们做什么,我们就一股脑去做了。当这些问题并未暴露出来,我们都不清楚价值、意义就贸贸然开始做,那最后谁来认可咱们解决问题的价值呢?

第二,你要有抓手。
当你搞定了第一个问题定义和价值问题,你准备开始做了。而真正想要落地,你必须从全局出发,做一步,脑子要往后多推演几步。你要思考:假如我们要按照敏捷迭代的方式去做,第一个版本MVP应该是什么样子,我们要针对什么样的问题场景交付什么内容,用户能做什么样的应用。做这个系统的价值到底应该如何体现。
内容层面,你要考虑,应该将哪些指标纳入管理范围,这些指标怎么用起来?指标数据从何而来。应用层面,应用的场景是什么? 单纯地看指标的口径,还是说要快速地取指标数据?价值层面,如何评判这些指标真的被业务用起来了? 用户查询了多少次,用来做了多少次报表?我们要对自己掌握的信息有个把握。当下我们现在掌握了哪些信息,比如,现在,已经有哪些指标做成了看板了,哪些指标还没有。其次,还想掌握哪些信息?对于未来也要有所考量,公司的战略层面还有哪些业务,粗略情况如何,是否需要指标分析,这块我们只能基于业务情况进行粗浅的预估。
总的来说,动手之前,花个1-3天时间,深度搜集信息,制定策略,谋定而后动。
二、准备工作
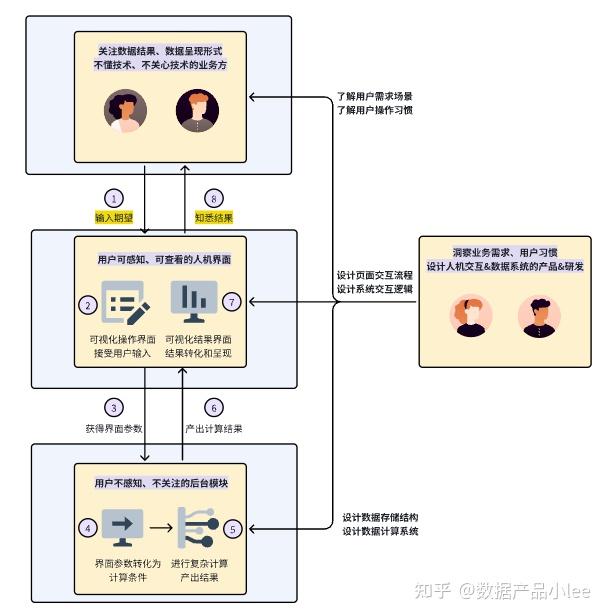
作为一名数据产品经理,你要面对的是关注数据结果及其呈现形式、但不懂技术或者没空关心技术的业务方。99%的人,尤其是做业务的人,不会关注数据怎么来的、数据怎么加工的,大家只会关注数据结果,取结果若碰到问题,直接会把问题抛出来让技术人员解决。
当我们发现在线表格已经无法满足公司管理需要时,我们开始规划指标管理系统。你要做几点:
- 洞察业务需求、目标用户习惯、明确系统价值;
- 了解组织的管理要求,设计人机交互和底层数据系统;
- 协调技术人员,传递需求场景,完成系统建设;
- 切入业务场景、运营和推广系统,并最终让业务用起来。
这里,提醒一下:在MVP阶段,甚至可以不做用于增删改查的后台管理,只需要做好数据初始化即可,也就是直接批量将数据录入数据库的方式。因为MVP阶段,一定是先让数据能用起来,而不是做一个非常完善的管理后台。
三、系统模块划分
两个模块之下,系统可以分为2个模块:面向业务应用的功能、用于后台管理的功能。
1. 面向业务应用的功能
当中核心包含2块:
- 自助指标取数;
- 指标查询。
指标取数和指标查询两者互为因果。因为想取数,要知道有什么指标;因为知道有什么指标,才知道如何取数。
早期,如果业务很单一,不用考虑复杂的业务域、数据域。也不用考虑指标体系。甚至,压根就不要做指标取数系统,因为找数据分析师、数据研发做一些SQL模板,在不同的情况下,换下输入的条件参数,执行下就OK了。当组织人数达到一定程度,研发人员已经无法快速响应业务各种复杂的看数需求,有了一定的复用性,组织架构也开始进行划分,数据权限也开始划分。指标取数是看数需求处理流程的SOP化、自动化。
2. 用于后台管理的功能
当中包括5个模块,分别是:
- 原子指标管理;
- 衍生/复合指标管理;
- 维度管理;
- 修饰词、修饰词类型管理;
- 业务域、数据域管理。
里面的第3、第5点,跟数据仓库建模是可以公用的,因为指标体系和基于业务构建的数据仓库表是密不可分的。再次强调,如果没有复杂的业务,没有非常多的指标需要从业务、技术、运维层面进行统一的管理,那真的是不需要构建指标管理系统。
四、功能详解
1. 面向业务应用的功能
1)指标取数
① 指标取数场景分析
以下两个场景,哪个更加适合用指标取数来解决呢?
场景A:产品设计了一个新功能,想看看这个新功能的曝光点击、转化效果等数据。
场景B:运营新挖了一个主播来平台直播,想看看这个主播、直播间的各种情况。
我个人认为,B更适合。A场景,其实要从功能规划阶段就要规划埋点,到上线之后能够通过点位、事件进行指标查看。针对功能的事件分析场景,一般来说,指标相对固定,人数、次数、比率。
指标取数,跟完全自助的探索分析是不同的,而更像是有固定指标目标,而只是单纯修改某些维度变量,里面对指标的覆盖就可以更广(可以来源于埋点的指标,也可以来源于业务统计指标)
② 指标取数流程分析
当业务提了如下需求:我想查看xxx直播间的活跃情况,DAU,还有新增用户、拉活用户。取数的一般流程是怎么样的呢?
a. 确认指标口径(维度、修饰词)
比如,业务说,我想看DAU,数据分析师会问:是整个平台,还是分端?(WEB端、移动端)。业务反馈想看新增用户数,数据分析师会基于实际情况反馈:目前新增用户包括了信息流(抖音、快手等)、非信息流(手机厂商应用商店),哪些渠道没接入,如果是新渠道,需要等渠道回传数据接入才能看。第一步,要确认指标的口径,一般就是维度和修饰词。
b. 确认数据及时性、数据范围
口径确认后,要确认数据的及时性(是实时还是离线,离线的级别是怎么样,小时、天、周?)除此以外,还会确认时间周期,看多长时间范围的数据,近1天、近7天、近30天、历史截止当前?
c. 确认结果交付方式和数据呈现形式
确认好数据后,接下来就是以什么方式来交付。到底是人工取数后导出Excel,比如,也就是日报、周报汇报给老板,还是说要支持自动化的自助查看,比如做成数据自动刷新的看板,还是做成支持用户输入参数的取数模板?
② 指标取数产品化
一般来说,当数据同事建设好了数仓底表,建设好了维度、修饰词,那就可以做自助指标取数就可以系统化、产品化了。交互流程可以参考如下:
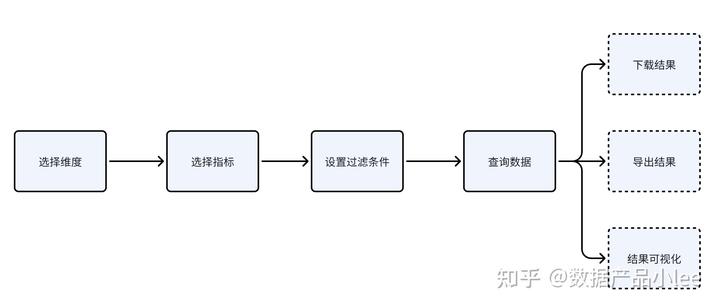
业务可以组合各种维度、修饰词、时间周期,自己设置查询条件。指标取数核心功能:能支持用户基于维度进行指标的挑选,然后进行即系查询,并能下载指标结果。后台系统需要做的就是,管控这些用户对应的维度、修饰词、时间周期的使用权限。
选择指标的界面可以参考如下:
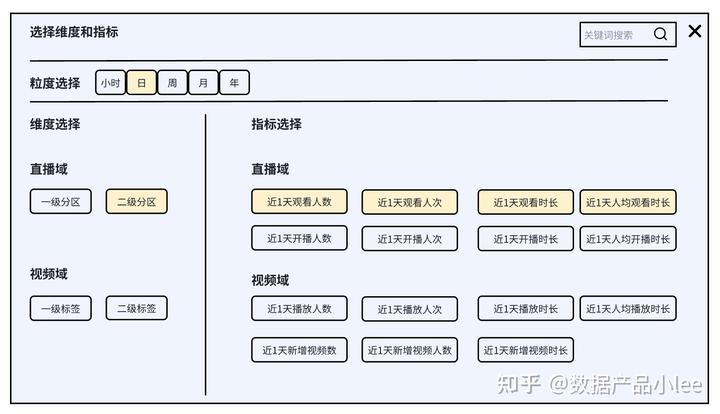
选择完维度和指标后,可以在取数界面点击查询进行取数。
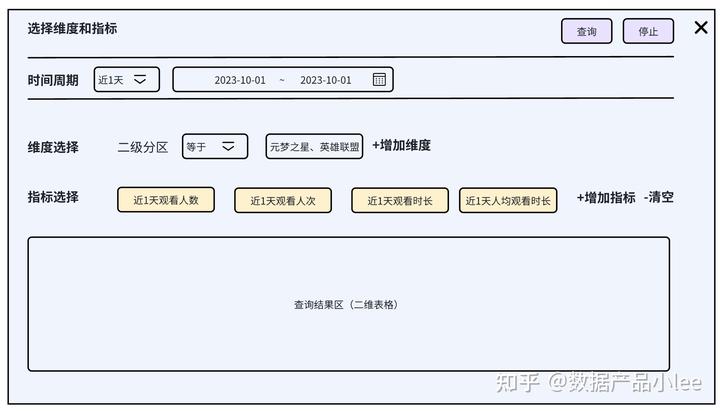
指标取数的产出结果案例如下:

如果还能跟BI系统打通,支持各种关联分析,比如,针对某个指标,制作折线图、柱状图,如果还能加上趋势预测等等自动分析功能,那就更好了。
对比指标取数,标签取数的道理是相同的。不过,标签取数的结果,都是人数。我们需要针对这群人,再进行下钻分析(后面再讲)
2)指标查询
指标查询,可以理解为一个商场的指引台。
当你到了一个大商场,你会不知道目标店铺在哪里,当你转得晕头转向的时候,有个向导告诉我们目标店铺在哪一层,哪个方向(左拐、右拐、直行,别讲什么东南西北)
指标查询也是如此,它能在以下几个场景发挥作用:
- 当你晕头转向时,告诉你系统中现在有哪些指标,对应的负责人是谁。
- 当你没指标权限时,基于系统反馈的指标负责人信息,你可以通过IM系统,找到对应的联系人。
- 当你发现数据有问题,指标有错误,系统有故障,你可以找对口的负责人进行排查。
比如,当你看到近1天观看时长这个指标,这个时长的单位是什么呢?如果指标的名称上没展示,那就可以通过指标的详情来了解,是小时,还是分钟,还是秒。
再比如,人均观看时长,分子分母分别是什么?分子是观看时长,那分母是平台近1天的全部活跃用户,还是有观看行为的用户,还是有有效观看的用户呢?这也是需要解释的。
比如,我们可以在数据地图中,让用户快捷查询指标。
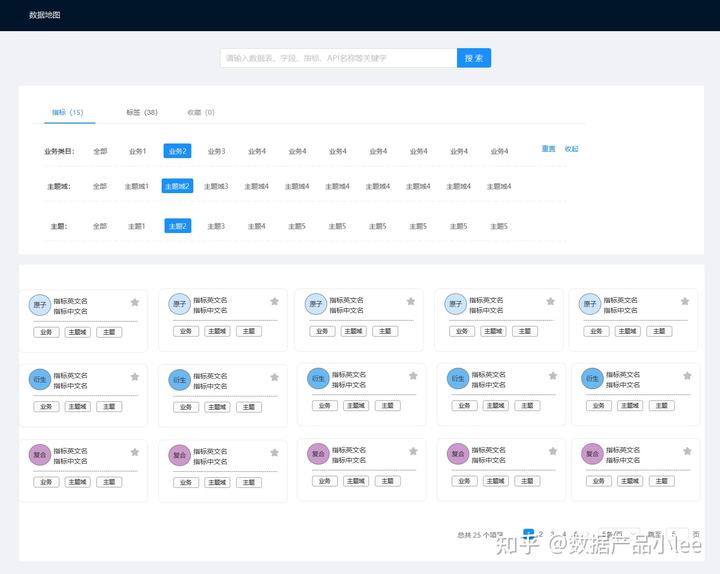
当然,我们也可以直接在取数的界面进行必要信息的展示和提示,这样就不必要再到另外的界面去查询。

对于业务来说,这种系统越简单越好,需要跳转的页面越少越好,甚至可以结合NLP系统对业务使用的业务语言,转化为技术语言,然后进行取数。
比如问,我想知道最近元梦之星的直播情况,请告诉我有哪些维度和指标。并直接帮我取数,按照Excel的形式给出结果。然后系统自动判断并执行即系查询操作,并按照Excel格式给出。
不过,如果系统底层数据没做好治理,也没积累案例,实现难度比较大。更加关键是,中型公司落地一个模型的收益,能不能覆盖投入的成本。
2. 用于后台管理的功能
设计完了面向业务应用的功能,接下来,我们再考虑用于管理、支撑的后台功能。
首先问自己一个问题:MVP阶段,需要复杂的管理功能吗?需要什么样的数据支持呢?回答这个问题,需要有点技术背景,但如果你不懂技术其实也没问题。
第一,指标能取数,那肯定需要有数据源,第二,业务人员进行的各种取数条件的设置,可能要能转化为从数据源里取数的语言(取数脚本)。
这里需要两个东西:具体的表数据(数据源)、以及解释取数配置的东西(生成取数脚本的逻辑)。有了这两项,只要提前在代码里配置好,哪怕没有管理功能,用户在界面上的操作也能取到结果。而设计功能,当我们的底层表、指标、维度、修饰词等等信息变得庞杂以后,能够更加方便地查询、管理。
接下来,我们再来看,要有哪些功能。
1)原子指标管理
这里,基于原子指标是否要指定来源的事实表,可以区分为两种做法。抛开这个点,我们先说公共的部分。
解释一个原子指标,需要告诉使用者:指标的中文名称、英文名称、指标的单位、指标的业务含义、业务的负责人。除此以外,我们还可以对指标进行分类,包含业务域、主题域、业务过程、数据域等。(我不建议划分太细,划太细其实也挺难找的)
接下来,我们再说两种不同的做法。
第一种,原子指标指定来源事实表。
这里,核心就是要指定指标的字段,是基于数仓中的哪个事实表中的哪个字段进行何种计算,最终的出来。
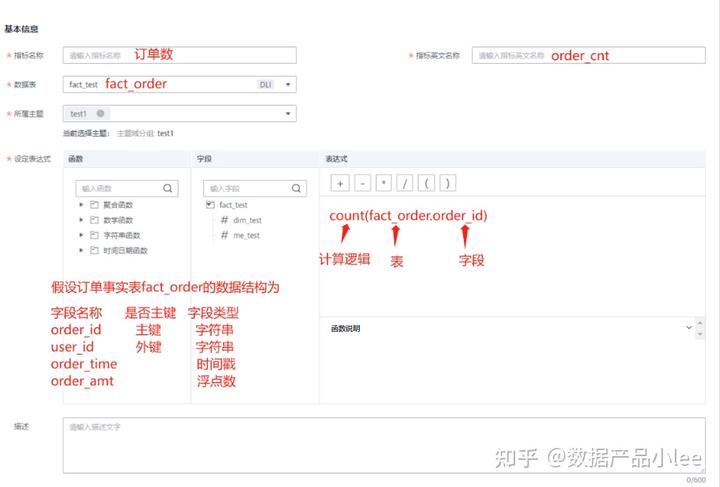
第二种,原子指标不指定来源事实表。
原子指标不记录和表之间的关系,纯粹就是做公共部分的记录。指标和表的绑定关系,放在衍生指标中进行设定。
下图是新增原子指标:

2)衍生/复合指标管理
对应的,也有两种管理方式。还是记住那个公式:衍生指标 = 维度 + 修饰词 + 时间周期 + 原子指标
第一种。通过原子指标来绑定表关系。衍生指标核心是增加维度、修饰词、时间周期等信息
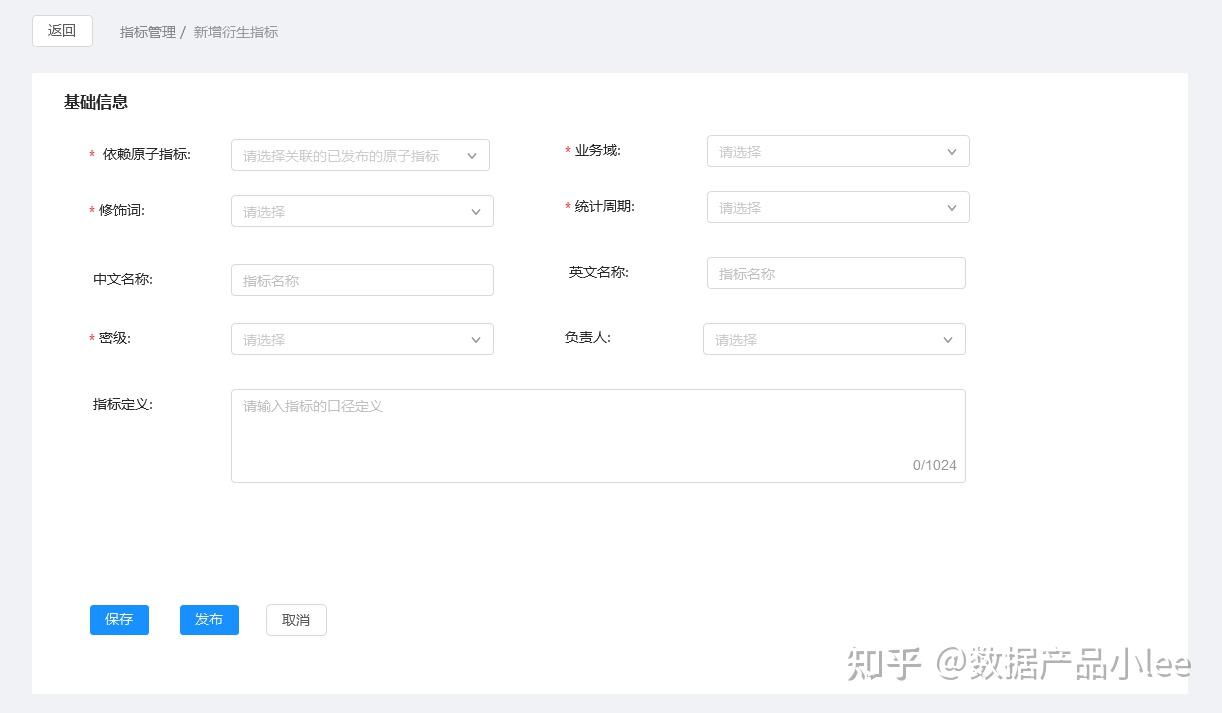
第二种。

这里管理的核心,是将具体事实表的一些字段记录下来,对应的是哪些衍生/复合指标。
既然有依赖关系,那么在衍生指标这块,就可以看到指标之间的血缘了,可以进行可视化呈现。
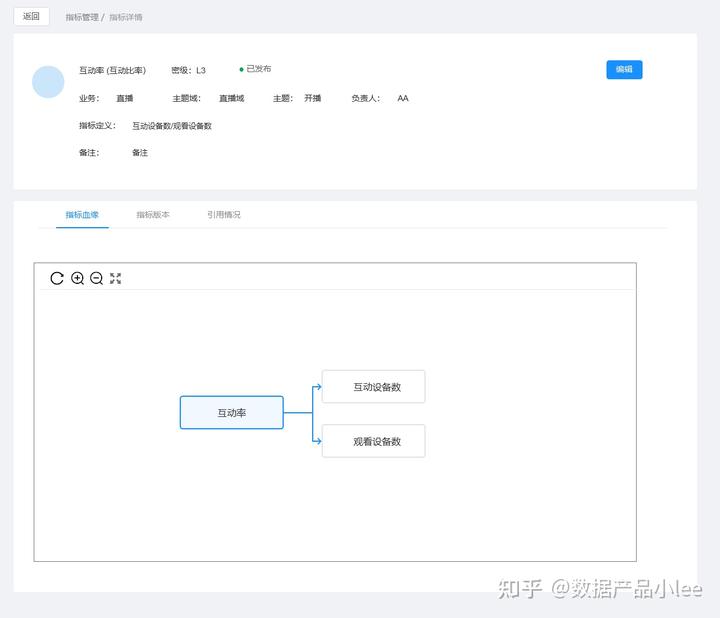
指标管理小结:
其实不管哪种方式,关键就是要告诉系统:指标要从哪个表中的哪个字段进行取数,也就是指标和表之间的关系。只有记录了这些信息,未来,才能基于这个逻辑关系去生成取数的脚本。
这里也照应前面文章里说的:表里面没有原子指标。原子指标只不过是定义指标的最基础的业务含义、取数方式、哪怕指定事实表,也只是定义技术语义下的指标口径是什么(也就是所谓的基于SQL的计算方式定义)。
3)维度管理
维度管理的核心,是将维度的逻辑和具体的维度物理表映射起来。
比如,数仓底层建了不同的品类,有对应的一个维度表。那么我们就可以录入品类的维度(或者是事实表里的维度属性字段)
用户想要查看不同分区的直播数据,选择了分区维度下的指标,比如品类观看时长,那么最终生成取数脚本的时候,会将维度属性字段放置到group by字段中。
比如,业务在最终筛选的时候,选择了王者荣耀和元梦之星这两个游戏(相当于是确定了维度的取值范围),在 where 匹配条件里,加了匹配符,比如,where tag_id = 1 or 2。
那么,最终的结果就是:

衍生指标 = 维度 + 时间周期 + 修饰词 + 原子指标。

那么,当我们构建了衍生指标之后,我们是能够通过维度反向筛选有哪些可选的衍生指标的。
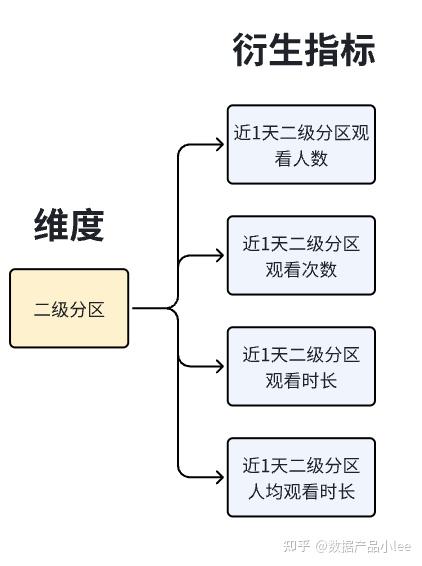
4)修饰词、修饰词类型管理
这块相当于词库管理,修饰词、修饰词类型的增删改查,然后用于构建衍生/复合指标的时候,进行关联。直播常见的修饰词有,有效观看、有效开播、礼物流水消费金额里面的礼物流水。
5)业务域、数据域管理
这块也相当于词库管理,业务域、数据域的增删改查,用于对指标进行分类。
比如,用户在筛选时,先有大致的一个业务划分,然后再去找维度和指标。

3. 指标管理功能总结
看完了这么多,感觉很复杂,是吧?化繁为简。先抛开修饰词、业务域、数据域,只关注指标和维度。我建议你从SQL(结构化查询语言)的角度去重新理解指标管理。
为什么数据产品经理要懂点技术,我认为核心是要懂点SQL。因为懂了SQL,才能从SQL(物理模型语言)的角度去理解这些一切一切。
其实SQL也不用掌握太深,只要看懂最简单的代码就够了。我们看看下面这段语句,其含义是:统计2023年12月12号当天不同支付类型的订单数量。
select dt as dt, pay_type as pay_type, count(order_id) as cnt from dwd_order where dt = 20231212 group by dt, pay_type
假如我们的支付方式有两种:wechat和alipay,那么最终的表格会如下:

看完SQL,我们再问问问题。
在SQL里维度是什么?在哪里?维度就是对应的group by的字段。这个字段是可以来源于事实表的主键,也可以是事实表关联维度表后取得维度表得字段。
指标是什么?在哪里?是count(order_id)吗?不,如果你只往查询系统里输入count(order_id),系统是没有执行结果的。只有当你指定了表,表取数的时间范围(时间周期),指定的维度,才能取到结果。如果不指定时间范围,那就是整个表全部的范围(也就是从有这张表的那天起的全部数据)。如果不指定维度,那就是全维度(也就是所有的订单总数)
如果,我们从刚刚的结果表里取数呢?指标是什么?
我们不需要定义count(order_id)了,我们的SQL可以这样写:
select dt as dt ,pay_type as pay_type ,cnt as from dwd_order where dt = 20231212
这就是为什么指标能有两种管理办法。因为不管哪种,只要最终生成的SQL能从物理表里取到正确的结果就行了。当你理解了SQL是如何取数,如何描述指标,那你就能理解为什么要构建所谓的原子指标管理、衍生指标管理、维度管理。
五、产品运营
1. MVP阶段就要考虑后续运营
前文说到,要MVP,要基于场景、用户需求去初始化我们的最小可用产品,第一个版本我们为了快速产生价值,很多地方是简陋的。但你要时刻牢记,正是因为舍弃,我们才有获得。
这套系统,相当于是将之前的业务提需求、开发开发报表的流程,进行了系统化,并且记录了过程信息(也就是指标、维度、事实表等等对象的元数据),当这套管理体系和对应的系统建设完成时,后续只需要进行日常的运营和维护。
当我们的产品功能上线以后,接下来就进入新的PDCA循环了,Plan(计划)、Do(执行)、Check(检查)和Act(处理)。不仅可以对系统的内容(数据资产)进行进一步的丰富,在交互和用户指引方面,也有很多工作可以做。
2. 在问题中迭代系统
当然,你也会面临一些内容和功能层面的问题。
比如,业务方希望你能在指标取数中增加新的指标。而这需要开发新的底层表,录入指标数据,直到丰富整体的指标体系。比如,当指标过多,用户不方便进行指标的搜索、查询时,要做一些必要的指标分类、说明文档、操作指引等。
再比如,因为公司规划原因,某些业务停滞,某些数据也不再需要了。如果公司对成本管控比较严,可以从数据的实际应用情况出发,基于指标体系、数仓表血缘等,对不再使用的报表及其整个调度任务体系进行下线处理。以便节约存储和计算的成本。
总而言之,这套系统完善之后,能解决50%以上的规范化的取数、看数问题就不错了。而针对特定场景的分析,还需要人工来支持。人工智能,先人工,才能智能。
当然,问题是解决不完的,人的需求是满足不完的~
六、总结和未来展望
1. 总结
从规划的注意事项,再到落地的功能规划和涉及介绍了很多,大致上为你描绘了指标管理。
不过,我想提醒你,那些能够落地指标管理的企业,都是天选企业,它们汇聚了优秀人才,跟随着时代的发展,基于技术和管理的创新,跨过了层层考验,在重重磨难之中成为大业务量的企业,拥有真正的大数据,真正地利用数据发挥价值,但凡少创了一个关,都到不了所谓数据驱动业务的阶段。
对于大多数实体业务经营型的企业来说,科学的指标管理是业务发展的助推器。数据和对应数据管理系统的发展,离不开强力的业务支撑,绝对不要为了做而做,管理指标的目标也不仅仅是为了更好地查看数据,其目标是做出更优质的决策,拿到更好的业务结果。
2. 未来展望
在生成式AI如火如荼进行的时候,我们可不可以利用AI来做更多呢?
AI能在哪些场景嵌入现有的工作流,改善当前工作流,做更加深入的落地呢?比如,业务方看完数据后,直接用语音、文字给AI发送指令,请给近30天没在平台消费的用户发送满30减5的消费券通知,并自动生成统计任务,在1小时候给我反馈通知发送的达到量、点击量,消费券的使用量,产生的交易金额。
人还是做主导,但是基于数据做决策、做动作、回收数据的整体链路更加高效。长路漫漫,道阻且长~
以上,感谢阅读~
专栏作家
Lee,公众号:数据产品小lee,人人都是产品经理专栏作家。关注直播、短视频和文娱领域、擅长数据架构、CDP及数据治理相关工作。
本文原创发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
















干货满满,值得学习!我理解,具体指标计算时,根据原子指标定义生成where,根据维度生成group by(维度选择是having),根据修饰词生成数学运算,包括几组统计结果的加减乘除、平均数等,还有一个时间周期是一个特殊的维度-时间维度。我对修饰词的概念还是有一些模糊,它和维度值有什么区别与联系。