
 起点课堂会员权益
起点课堂会员权益RAG实践篇(二):这些年,我们在测试中踩过的坑
RAG目前在企业级应用中是最优解,但实践中的坑点不少,今天分享我们在测试环节踩过的坑。

在大模型的企业级应用中,RAG应该是目前的最优解。不过,由于它和传统的软件开发项目存在很大的不同,实际落地时经常会存在意想不到的坑点和难点。有次和同样在探索RAG应用的朋友交流,大家都不约而同地发出“一周出demo,半年不好用”的吐槽。
这个实践系列就是我们在探索和吐槽中的产物。今天这篇,我们想专门聊聊在项目测试中踩过的坑,希望对同样在RAG摸爬滚打的伙伴有帮助。(上一篇:RAG实践篇(一):知识资产的“梯度”)
为什么从“测试”开始说?
- 和传统开发差异大:大语言模型的开发过程与传统应用软件存在显著差异,主要体现在其黑盒子特性和输出的不可控性。在传统应用软件中,产品经理可以明确地定义产品功能,输入/输出通常是确定的,通过验收标准很容易和开发、测试达成共识。然而,在AI产品的开发中,由于大语言模型所以无法完全预测在特定输入下的行为,输出也有着高度不确定性,这样如何找到有代表性的测试集也很有难度。
- 优化成本小,但有收益:大语言模型是一个不断自我学习和优化的过程。给到足够拟真的测试环境,并在测试后给到及时反馈,也是提升其表现性能的方式之一。而且相对成本较小。
一、RAG测试三大坑
在给企业做RAG落地应用的时候,我们发现很多企业需求从“知识问答”类的功能开始,比如公司规章制度/管理要求/文化建议等输入,或者基于某个专业领域的知识库进行私有化。由于泛用性广,也便于理解,我们就以“知识问答”为例来说明。
第一坑:如何做到测试集的覆盖度?
无论是RAG项目还是其他LLM的项目开发,最理想的测试集就是来自用户的真实数据。但实际中我们发现,很多企业其实并不具备这个条件,需要开发团队或者甲方自行“生产”测试集。无论由谁来准备,覆盖度原则是一个关键点。它指的是在测试集中应包含广泛的细分主题,以确保模型能够应对不同领域的查询,这样才有助于比较有效地评估RAG整体表现。以知识问答为例,通常会要求测试集尽量覆盖这个知识领域中所有子领域的代表性问题。其中,有两个点值得注意:
要意识到“知识”和“用户问题”之间的差距
在起初没经验的时候,我们往往就会直接按照知识库所代表这个专业知识领域的子分类进行细分。以产品经理的能力知识为例,我们曾依据“商业洞察”、“沟通与领导能力”、“需求分析能力”等进行测试集,结果上线后发现,用户真实挑战,不太可能像知识库那样分门别类,井井有条。甚至有些回答会需要横跨两个或多个子领域才能回答。
于是我们才意识到,很多领域的知识是一种经过经验提炼和梳理后的结构化产物,它能高效地将知识进行聚类和管理,但已经不是用户挑战的“原始状态”。
因此,覆盖度的第一个注意要点:请根据目标用户的真实情境来进行测试集的分类,而不是知识库本身分类。否则,可能与真实情况相去甚远。
不要忽略“形式”的覆盖度。
有些产品设计者或内容专家在准备测试集时,觉得内容上覆盖多领域就万事大吉了。但我们实践下来发现,其实“形式”上尽可能覆盖用户的真实使用的多种情况,也很重要。因为模型应对不同形式的输入,其性能表现会产生差异。
基于“知识问答”功能,同样是提一个关于产品经理“商业分析”相关的问题,用户完全可能有不同的问法,意味着背后的不同的用户意图。下图是我们当时做知识问答功能时,对问题形式的分类,供伙伴们参考。
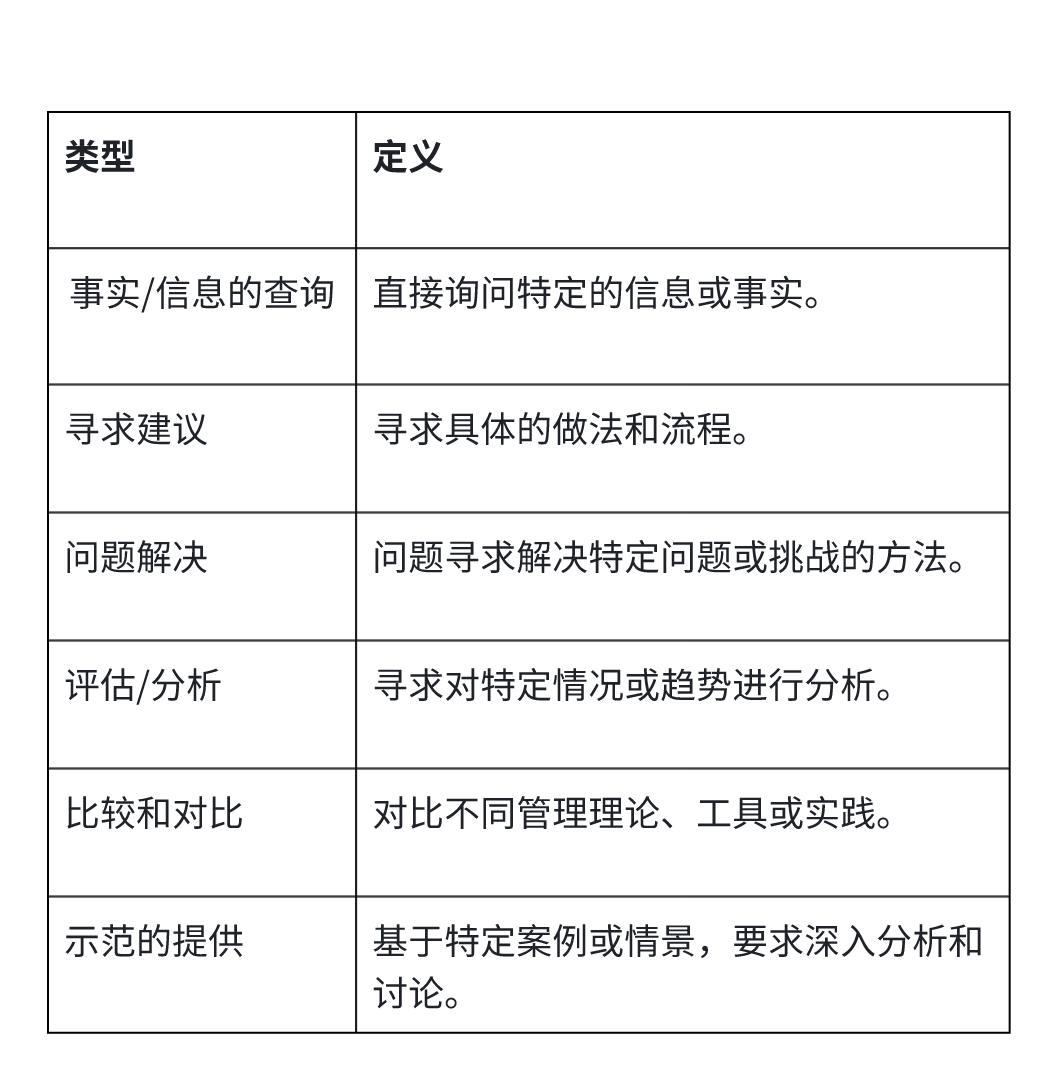
所以,第二个要点:在准备测试集中,除了对内容主题的覆盖度,“形式”覆盖度也是同样需要关注。
表达习惯的覆盖度
在知识问答类的功能中,用户的表达习惯也可以纳入考量。同样的“意图”,有不同语言习惯的用户会产生不同的表达,比如有些人习惯倒装,有些人习惯简略,所以在准备测试集中,也需要准备一些不同的表达习惯的提问(最好是真实用户输入)来确保LLM能够理解。
第二坑:衡量维度,细节决定成败
衡量标准的三板斧:准确性、充分性和相关性。接下来我们分别从三个维度来看看有没有坑。
“模糊”的准确性
如果精确地评估准确性是一个难点。由于大模型的自然语言特性,造成输出并不是每次都是确定的、可定量评估的内容。为了降低这种不可评估的问题,我们目前探索的解决方案是,将正确性的标准分成三类,增加评估的一致性:
- “必须正确”:对于大模型的输出内容,哪些是必须包含在其中的的“准确回答”,如果没有,就是bad case。(类似高考答案中的踩分点)
- “绝对错误”:对于大模型的输出内容,哪些是必须排除的错误答案。如果出现,必须算成bad case。
- “模糊地带”:除了以上这两类,其他如果再一些与预期不符的回答,但在可容忍的范围内的回答,可以算成good case。
充分性
目前没发现有坑。因为大语言模型真的太、能、说、了。不怕它不充分,就怕它过分。
相关性
我们原来以为的相关性bad case是问题跑偏。你问产品经理的商业分析A技巧怎么做,它回答你商业分析的B技巧。但实际碰到更多的情况是:大模型的流式输出中,10个要点里交杂着1、2个“谎言”(与问题无关的回答)。因此,请提前与你们的内容专家确定好相关性的标准。是需要每个要点都严格与问题相关,才算是good case;还是可以按比例进行,比如超过30%、50%与问题无关,才算是bad case。
第三坑:经常会遗忘的重要指标
在RAG测试中,有两个评估维度经常会被忽略:一致性和上下文。但这两个指标很重要。
一致性:大模型在多次使用同样的问题回答时,是否能给出相对一致的答案。“同一个问题能否保持一致性”其实对企业应用来说还是蛮关键的,毕竟大家都不希望同一个问题,企业员工A和B去问,得到的是截然不同的答案。
为什么重要:大型语言模型通过大量的文本数据训练,理论上应该能够为相似的问题提供相似的答案。然而,由于模型内部机制的复杂性(如随机初始化、训练过程中的随机性等),实际应用中可能仍会出现一定程度的不一致性。因此,一方面,持续优化模型以提高其输出的一致性是非常必要的;另外,在测试中进行多轮测试来验证其一致性也很重要。
上下文:当多轮次回答时,是否会对回答的准确性和相关性等产生影响。这种情况在用户的实际情况中很常见,但在测试中容易会忽略。
为什么重要:LLM在处理输入时,通常有一个固定的上下文窗口大小,这个窗口决定了模型能够“记住”的最近对话内容的长度。而上下文窗口大小确实与Token限制密切相关,超出Token限制可能会被遗忘或忽略。
以上,都是我们在RAG项目中的实践和真实感受。这个系列我们还持续更新,比如在文档(知识)解析、QA对召回、向量化等的注意要点和“坑”等等,我们会持续记录下项目实践和思考,当然,如果您有任何想法和经验想要分享,非常欢迎在评论区留言。
本文由 @AI 实践干货 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务






- 目前还没评论,等你发挥!


