
 起点课堂会员权益
起点课堂会员权益业务风控产品模型思考:解读业务模型的6个层级

如果把平台比喻为一颗树,那么需要投入足够的养分才能快速生长,而业务风险则是寄生于树木窃取养分的角色,只有能够充分抵御这种风险的才能成长为参天大树。这就是业务风险在平台发展中扮演的角色。
作为一名前业务风控产品经理,一直想找个机会说说我对业务风控的一些业务及产品上的理解。
由于业务敏感性,有些东西不能写的太详细,还请大家见谅~
业务风控重要性
如果把平台比喻为一颗树,那么需要投入足够的养分才能快速生长,而业务风险则是寄生于树木窃取养分的角色,只有能够充分抵御这种风险的才能成长为参天大树。这就是业务风险在平台发展中扮演的角色。
在大部分场景下,风控意味着阻断用户操作,在大部分人眼里与用户体验是背道而驰的存在。单就电商领域而言,竞争逐渐白热化,用户体验成为了吸引用户的重要因素,此时风控如何在尽可能少打扰到用户的情况下,能阻断尽可能多的恶意行为?这是一场善与恶的博弈,也是关乎生死存亡的博弈。
业务风控的原则
在这里,需要提出行业内一个著名的原则:轻管控,重检测,快响应,私以为基本能实现用户体验与风控需要的平衡。怎么来理解这个原则呢?个人认为:
轻管控:在出现风险,需要阻断用户操作时,阻断动作宜轻不宜重。能验证码校验就不短信校验,能短信校验就不禁访。同时被阻断后文案,下一步出口都需要照顾用户感受。看似简单,其实背后涉及到对用户风控行为以及对用户风控阻断动作的分层管理。
重检测:通过尽可能多的获取用户信息(包括静态及动态数据),由规则引擎进行实时或离线计算,来动态分析每个用户及采取行为的风险程度。这里需要尽量全的数据来源,以及非常强大的规则引擎,才可以实现良好的检测效果。
快响应:是指在检测出用户存在的风险后,如何快速的进行阻挡。这里的重点是快,则意味着对业务的理解要细,提前在关键动作进行布局,才可以做到尽可能减少损失。
业务风控的业务模型设计
说完了原则,我们怎么具体来看业务风控的业务模型设计呢?
在我理解,业务风控的业务模型主要分为六层,分别为数据输入层,数据计算层,数据输出层,运营管控层,业务接入层以及用户触达层。
大家可以看到,下面三层,是偏向于数据,研发的;上面三层,是偏向于业务,运营,产品的。做风控其实就是做数据,因此数据的接入、技术、处理是其中最核心的模块;但现阶段,由于算法模型的限制,还需要有人为的因素进行规则模型的校正,以及特殊样本的审理,因此会有运营层的存在;最上面的触达层,是拿结果的一层,产品的部分工作也在于对此进行良好的设计。
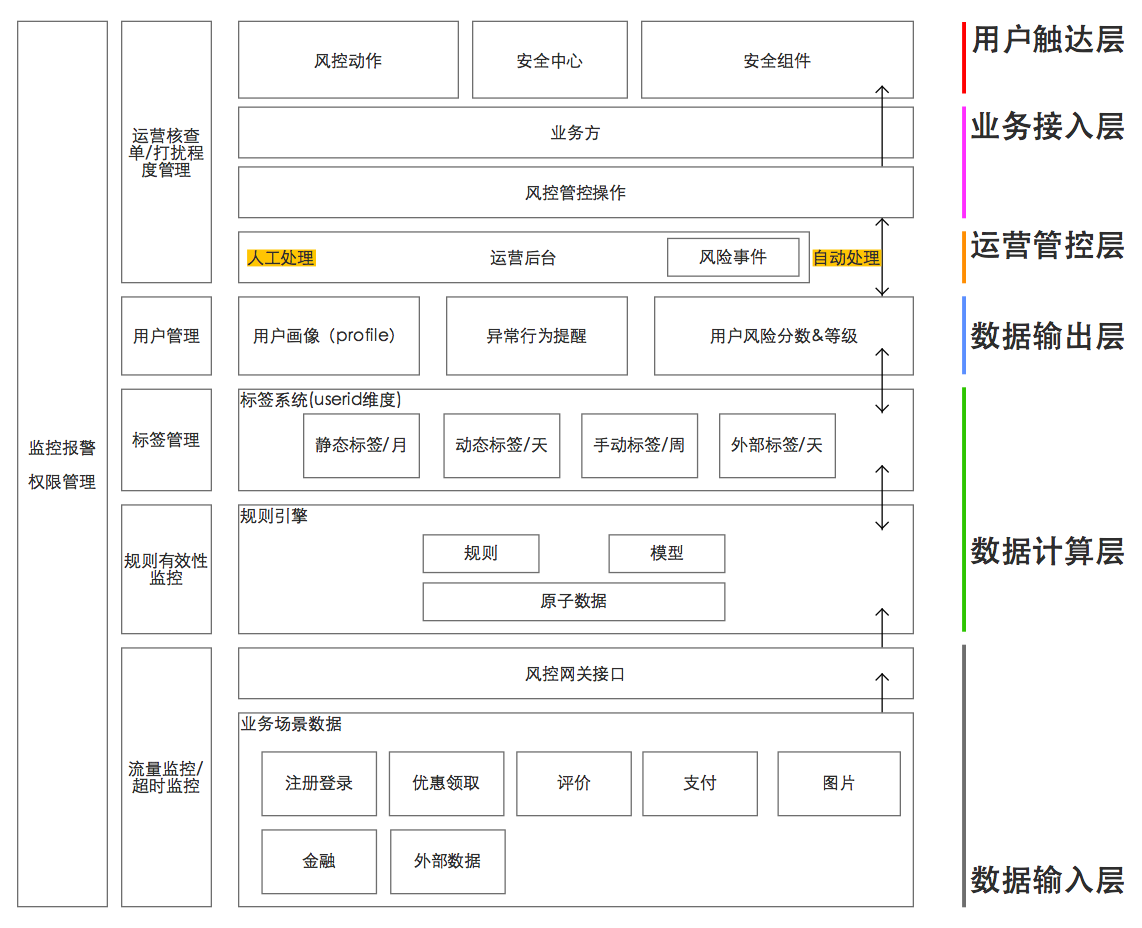
这六层侧重的点也各有不同,下面为大家简单说明:
一、数据输入层
如何获取数据?获取什么数据?数据准确性如何?这是数据输入层需要解决的三个问题。
1、获取数据方式
目前获取数据主要有两种方式,一种是主动获取,一种是被动获取。
1)主动方式
主动方式是自己去业务方数据库、日志里面去读,这样可以拿到最全的信息,而不用依赖消息报等被处理过的二手数据。有些比较成熟的公司有自己的消息总线,风控可以去实时的订阅信息然后作为数据源进行分析;但在公司没有消息总线的时候,风控可以发挥自己横向,跨业务的优势,建立自己的消息总线,去获取数据进行分析。这样的好处是对业务方依赖降低,数据来源最全,能进行深入的数据挖掘;坏处是建立难度较大,需要大量资源支持,适合较为成熟的公司。
2)被动方式
被动方式就是提供接口给业务研发,让业务把消息按格式标准传过来。这种配合周期非常长,但成本较低,可以按照标准来拿到高质量的信息,所以是比较常见的风控系统搭建方式。
2、获取数据种类
鉴于目前大部分公司都采用第二种方式,因此与业务方如何合作,获取高质量的数据就很重要了。对数据种类的要求是能全就全,能深就深。以笔者做过的账号安全业务为例:
1)数据全面程度
往往风控关心的信息比如IP地址、referer这些信息业务都是不关心的,但这些信息的缺失可能造成很多策略没法做,所以在采集信息开始的时候就要有个明确的信息列表。
2)数据详细程度
以注册登录行为为例对数据详细程度进行深入:
- 基础的登陆注册数据,就可以从频率、登陆注册特征来进行分析;
- 进一步拿到登录注册行为的上下文,比如登陆前访问了哪些页面,登陆后去访问了什么,就可以从访问行为轨迹来增加更多的分析维度,例如页面停留时间,是否有访问到必访问的页面;
- 用户的操作行为数据,比如鼠标移动的轨迹,键盘输入,进一步的从操作过程来增加分析维度,比如是不是输入密码的时候有过多次输入删除?是不是直接复制粘贴的账号密码?
3、获得的数据准确性
比较常见的例子:需要用户的访问IP,结果拿到的IP地址是内网的服务器IP;或者是想要用户名,结果传递过来的是UID。这点需要大量的前期沟通确认工作。
如何在日常工作中确保数据的准确性呢?
1、对采集回来的数据必须定期的对数据质量进行监控——
已经采集到的数据可能因为技术架构调整,代码更新等各类奇葩原因造成采集回来的数据不准了,如果无法及时发现可能造成后面一系列分析过程都出现错误。
2、采集点尽量选择稳定的业务点,比如采集登录日志,一次性在公共服务采集好,后面出现问题只要找一个点。但如果是去前端从WEB、移动端等各个调用登录服务的点去采集,出了问题要改动的工作就会成倍增加,还有可能出现新业务点的日志无法覆盖的情况。
数据输入原则:
- 宜早不宜晚,宜全不宜少;
- 数据分层处理:实时数据与离线数据分离。实时数据接入需要评估RT时间及准备一旦被降级的预案。
二、数据计算层
数据计算层是由各种规则、模型等算法形成的计算核心,一般都依附在一个强大的规则引擎之上。
为什么采用规则引擎?因为黑产的反应速度实在太快了。如果把风控规则都硬编码进业务代码中,那一旦规则被绕过,反应速度就会非常慢。规则引擎必须能把策略逻辑从业务逻辑中解藕出来,让防御者可以灵活配置规则在静默模式下验证和实时上线生效,并可以去随时调整。
虽然说数据技术层主要是研发和算法同学处理的,但作为产品可以做的,除了了解基本的规则,模型及实现原理外,还可以增加对规则的生命周期及健康度的评估,比如:
风控系统的规则有多少?哪些已经很久没有触发了?产生误判投诉的对应规则有哪些?
一个新规则在建立起初的效果肯定是最有效的(因为这时风险问题正在发生,而规则正好对应了风险),但随着时间其有效性是快速下降的,比如攻击者都知道网站三次输入密码错误触发验证码,那么他们会傻傻的尝试第三次猜测密码的概率有多大?那么是否有人在定期的去统计分析这些规则的效率就是风控产品的重要运营环节了,而运营风控产品所要付出的代价是往往大于常规互联网业务产品的,并且是保证项目能够持续产出价值并不断迭代进化的一个前提。
三、数据输出层
数据输出层是将数据计算层的计算结果转化为可以被下游使用的分数,主要的输出为用户的风险画像,风险分数及风险等级。
数据输出层主要的原则是数据可读性高(因为会直接被运营及下游业务方消费,需要降低使用方的使用成本,提高效率)以及可复用性(一个输出的数据,可以在多个场景下被使用。比如垃圾注册的数据可以同时被反欺诈,反作弊等场景使用)。由于用户分层及用户画像展开来说内容比较多,就不展开了,大家可以自行百度~
四、运营管控层
如果说上面三层主要靠技术的手段来实现风险管控,那么运营管控层主要是靠人为经验来对技术尚无法处理的风险进行管控。
技术尚无法进行处理的风险主要分为两种,一是样本较少,计算准确度不足,然而危害较大的风险行为,比如金融盗卡,诈骗等;二是人为,非机器行为的风险行为,比如工作室层次的大量人工刷单等。以上两种都是需要运营的经验来进行判断会更为合理。同时运营层的处理结果也会反馈到数据输出层,优化数据输出的准确性,也有利于为算法及模型提供较为准确的样本进行学习。
运营管控层主要是风控运营后台的设计,由于各个运营后台设计的特点不一而足,因此在这里只说明主要的涉及原则,主要包括可读性以及案件存档。
1.可读性:
让分析人员可以快速的查询原始日志:日志并不是简单的存下来,从风控分析的需求来看,通过IP、用户名、设备等维度在一个较长的跨度中搜索信息是非常高频的行为,同时还存在在特定类型日志,比如在订单日志或者支付日志中按特定条件搜索的需求。
机器语言转化为自然语言:这主要是为了能够让分析人员可以快速的还原风险CASE,例如从客服那边得到了一个被盗的案例,那么现在需要从日志中查询被盗时间段内这个用户做了什么,这个过程如果有一个界面可以去做查询,显然比让分析人员用grep在一大堆文件中查询要快的多,并且学习门槛也要低得多。
如果在日志做过标准化的前提下,也可以进行后续的业务语言转译,将晦涩难懂的日志字段转化为普通员工都能看得懂的业务语言,也能极大的提升分析师在还原CASE时阅读日志的速度。
2. 案件存档:
这里指将实时或离线的计算加工消息成变量&档案。例如在分析某个帐号被盗CASE的时候,往往需要把被盗期间登录的IP地址和用户历史常用的IP地址进行比对,即使我们现在可以快速的对原始日志进行查询,筛选一个用户的所有历史登录IP并察看被盗IP在历史中出现的比例也是一个非常耗时的工作。
再比如我们的风控引擎在自动判断用户当前登录IP是否为常用IP时,如果每次都去原始日志里面查询聚合做计算也是一个非常“贵”的行为。
那么,如果能预定义这些变量并提前计算好,就能为规则引擎和人工节省大量的时间了,而根据这些变量性质的不同,采取的计算方式也是不同的。不过还好我们有一个标准可以去辨别:频繁、对时效敏感的利用实时计算;而相对不频繁、对时效不敏感的利用离线计算,以这样的原则进行指导,就可以尽可能节省时间了。
五、业务接入层
风控的业务模型是环环相扣的,在已经具备了数据处理能力以及运营后台之后,如果没有业务方接入,那相当于只有内功而无法出拳,这样就只是风控内部的自娱自乐,无法为业务保驾护航。在风控与业务技术的合作中,由于业务为王,一切要以业务为重,因此风控在合作中,需要注意:尽可能避免给业务带来不必要的麻烦。
如何做到与业务进行良好的合作,主要从4点出发:
1、呈现给业务研发直白的判定结果
我们最终从数据中发现的报警和问题最终是要在业务逻辑中去阻拦的,在接入这些结果的时候,往往分析师觉得可以提供的信息有很多,比如命中了什么规则、这些规则是什么、什么时候命中的、什么时候过期,一个code list给他们说明对应希望做的操作,一定把中间结果等等包装成最终结果再给出去。
2、实时与离线计算分离,降低业务系统压力
因为T+0在接入的时候要额外承担很多计算成本,结果要现场算出来而延时要求又很高,所以一般都只在攻击者得手关键步骤采取实时判断(比如订单支付或者提现请求)。而对于其他场景可以选择T+1方式,比如登录或者提交订单等。
3、超时及降级预案准备
风控风险判断的最基本原则就是要不影响业务逻辑,所以超时机制在一开始就要严格约定并执行,一旦发现风控接口超过预计响应时间立马放行业务请求。
4、充分关注业务流量
平时可能流量很小的业务,突然因为某个活动(比如秒杀)流量大增,除了在接入之初要对风险判断请求有了解,对后续的活动也要提前准备,否则如果资源预估不足,突然又赶上这个点接了T+0接口有很多要现场计算的逻辑,那业务分分钟会把风控降级。
六、用户触达层
终于来到最后一层,用户触达层了。风控的用户触达,主要包括各种C端的安全中心,安全组件以及多样的风控阻断操作。在这一层,需要做的是细化管控手段,以及重视用户体验。
1、细化管控手段
风控管控手段需要丰富,包括图形验证码,语音验证码,实名校验,touchid校验,密保问题,禁访,禁买,禁言等,在不同场景下,采取对应的方式,而不是千遍一律。千遍一律的话,太轻会导致管控效果不佳;太重的话会极大影响用户体验。
2、重视用户体验
这点说起来容易做起来难。在获客成本高昂的今天,假设获客成本是100块,他可能因为被风控之后,文案的简单粗暴,缺少申诉出口或者流程难以继续而选择用脚投票,从而离开。而这些是产品可以做的事情。使用提醒式而非警告式的文案;在被风控后及时提示用户后续的操作;与客服同学加强沟通(
任何风控准确率都不是100%的,所以在和研发沟通好接入后一定要告诉一线同事们风控阻断可能出现的表象(文案提示),以及大致的原因,以避免一线客服们对风险拦截的投诉不知道如何解释,并给出具体的阻断回复措施(CRM后台增加白名单、删除黑名单权限等等)。)都是可以有效提高用户体验的方法。
以上就是我对业务安全风控业务模型的理解。因为风控涉及的东西较为敏感,所以上面的说法都脱敏处理了下,具体的规则、策略,用户画像的构造等均没有细说,大家可以自行百度~
感谢大家看完,是对我最大的支持,比心~
本文由 @启辰菌 原创发布于人人都是产品经理。未经许可,禁止转载。










您好,我是风控大数据猎头,我这里有四个互联网业务风控的案子,上海、杭州,薪资70-300万左右,可以加个微信么Sarah_liu1225。其他朋友也欢迎加我微信,着急,挠头 🙁
非常感谢,新手学到了很多知识。关于【超时机制】有个问题:如果放行的是风险行为呢?不就造成企业、用户的损失了?还是说,这是根据业务量(badcase量)和业务金额来判断是否“超时”直接放行呢?
写得很不错,很认真地看了。如果能有适当的案例分析就更完美了,不过现在案例一般都涉及到公司业务机密。
谢谢知识普及,新人产品学习借贷业务产品设计中…
写的很棒,新人刚入坑,受到了一些启发