
 起点课堂会员权益
起点课堂会员权益
五分钟了解搜索原理
 B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
B端产品经理需要进行售前演示、方案定制、合同签订等,而C端产品经理需要进行活动策划、内容运营、用户激励等
本篇文章是对于搜索系统工作原理一个整体的介绍,对于原理的理解,是设计系统举重若轻的基础。
1. 信息和信息量
在介绍搜索之前,先介绍两个概念:信息和信息量。
(采用的均是自以为比较通俗易懂的解释,如果感兴趣可以读相关书籍)
1.1 信息是减少不确定性的东西,信息也是增加确定性的东西。
前半句是香农信息定义,后半句是逆香农信息定义。举个栗子,回想下,和一个异性交往的过程。在你遇到TA之前,你不知道这个世界上有这个人的存在,后来你看到了TA的样子,后来你了解了TA的性格、口头禅,往事。然后一步一步,你对TA从丝毫不了解,到逐渐熟识。这期间就是一个你不断获取TA信息的过程,正是这些信息,让你从完全不确定TA是怎样的人,到完全确定TA很适合你。
1.2 信息量是一个信息能减少不确定性的度量,信息量也是一个信息能增加确定性的度量。
关于信息量,有很多数学的描述,但是通俗来讲,可以这么简单理解。举个栗子,证人描述嫌疑犯。A证人的信息是“他是个男人”。B证人的信息是“TA是个高中男生”,C证人的信息是“TA是个长发170左右的高中生。”D证人的信息是“我认识他,他是学校的扛把子陈浩南”。我们直觉能感受到信息量的大小关系为:A<B<C<D。显然这是正确的。
翻译为计算机可以理解的数学逻辑:当地男人的比例是50%,当地高中男生的比例为8%,当地长发170左右的高中男生的比例是4%,当地叫陈浩南的扛把子的比例是0.0001%。因为P(A)>P(B)>P(C)>P(D),所以信息量的大小关系为:A<B<C<D。
2. 搜索的产品逻辑
搜索满足了用户迅速找到自己感兴趣内容的需求。用户输入一个query,搜索系统根据用户的输入的信息,筛选出系统认为用户感兴趣的内容,同时按照系统认定的重要性进行排序展示。请注意这个表述,简单而言,搜索可以分为三步。
- Step1:对用户输入信息的解读
- Step2:根据用户输入信息对内容进行筛选
- Step3:对筛选后的结果进行排序
而要了解这三步怎么在搜索系统中完成,就需要先了解搜索的服务器怎么存储信息。
3. 搜索数据的存储原理
上一张图,假设我们做了一个新闻网站,那么它的结构就是下图。内容进行了简化,假设一个新闻,文本只有标题,导语,正文。数据只有阅读量,评论数,分享数。
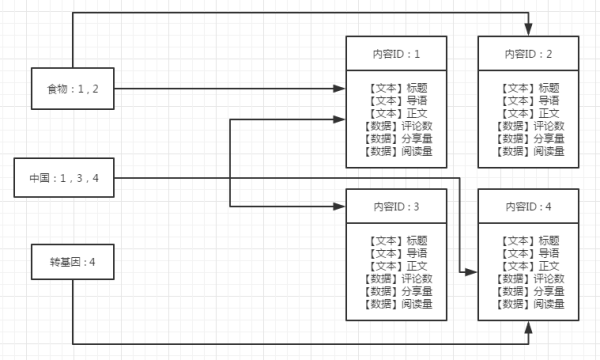
图1-1
差不多就是上图右边的这种结构。右边标识的是新闻内容的存储:就像图书馆的书一样,整整齐齐按顺序排好,方便查找(这个存储结构的名字叫做索引,就是来自于图书馆的用语)。左边是词库:只要一次搜索的输入词能匹配到词库,就可以快速的查找词库到对应的内容。
每个搜索系统都有自己的词库,无法对应到分词的搜索行为就会没有结果。每个搜索系统都会根据目标用户的不同,有对应的一套词库,就像字典一样,《冶金专业词典》和《生物学大辞典》收录的词条是不同的,知乎的词库和淘宝的词库也不同。搜索的很多优化都是集中在词库的优化上。
简单总结下,搜索的存储原理就是:一个系统词库,一个排列整齐的内容索引库,同时系统词库和内容索引库之间可以快速关联。
在这个搜索系统的储存结构的基础上,我们提到的搜索三步骤将依次展开。
4. Step1:对用户输入信息的解读
前面提到,搜索的词库是有限的,但是用户的输入却是没有限制的。那么怎么把无限制的搜索转化为有限的词库,并且匹配到对应的结果呢?这里需要介绍一个新的概念:分词,简单来说就是对输入字符串进行分拆。
同样以【图1-1】中的新闻搜索系统为例。如果用户输入的query为“中国的转基因食物”,系统中其实没有这个词。如果没有分词功能,这个搜索就会立即结束,即使系统里确实有对应的内容。分词的工作原理是在无法精确匹配的情况下,会对用户的输入进行进一步的拆分。于是我们得到了下面的结果。
“中国的转基因食物”——“中国”、“的”、“转基因”、“食物”。
并不是所有的词都有信息量,如果召回“的‘’的结果,那么几乎所有的新闻内容里面都会有这个字,召回这么多结果显然是不对的。比如这个query里的“的”,这个词实际上在分词系统中会被直接忽略掉。正是因为出现在内容中的概率不同,一个词出现的新闻越多,这个词的信息量就越小,信息量太小的词会被忽略,也就是停用词。同时包含信息量越大的词的新闻内容,会更更要。那么去掉停用词之后,结果就进一步简化。
“中国的转基因食物”——“中国”、“转基因”、“食物”。
经过处理,用户非标准的query就被转化为标准的词库,就可以快速找到对应的内容了。如【图1-1】所示。
5. Step2:根据用户输入信息对内容进行筛选
经过对用户的query解读之后,其实就得到了一些标准化的词,而这些词就会对应一些搜索目标内容,接下来就是对于内容的筛选。
用户进行了一次搜索,一部分结果被搜索了出来。那么所有的内容根据“内容是否相关”、“内容是否被召回”两个维度,就被分为了四部分。
- 召回的相关内容:搜索出来的内容中,和用户搜索相关的部分。
- 召回的不相关内容:搜索出来的内容中,和用户搜索不相关的部分。
- 未召回的相关内容:没有搜索出来的内容中,和用户搜索相关的部分。
- 未召回的不相关内容:没有搜索出来的内容中,和用户搜索不相关的部分。
搜索一般而言,决定是否筛选出来,会从两个角度衡量,准确率,和召回率。
准确率就是所有搜到的内容里面,相关的内容的比例。准确率:
![]()
召回率就是所有应该搜到的内容里面,真正被搜出来的比例。召回率:
![]()
准确率和召回率是一对存在矛盾的指标。需要权衡。最终衡量会取两个的调和平均数作为目标函数。即F值:
![]()
这三个概念在搜索优化中是关键性指标,牵扯到人工打分和更高级的优化。这里不展开更多。我们只需要记住一点:并不是所有的包含用户query关键词的结果都应该被召回。
6. Step3:对筛选后的结果进行排序
排序影响着搜索的结果质量,越往前的结果约容易获得用户的点击。好的搜索不仅仅是把应该搜索的内容尽可能的搜索出来,同时还要考虑应该把最容易吸引用户的内容展示在前面。
搜索排序比较大的基础逻辑是通用的:
用户输入一个文本转化为标准词库中的词,搜索系统根据每个具体内容是否包含这些词决定是否展示这些内容,同时搜索系统根据文本相关性给这些要展示的内容一个分数。而最终排序则根据每个内容的分数排序。
这个Lucene的的核心排序公式的原理,网上有介绍。但是实际的情况其实更为复杂。还是以我们之前提到的新闻搜索系统为例(方便理解,再贴一遍图)
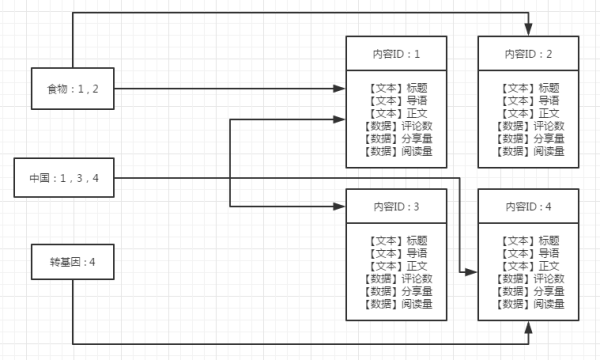
如果用户搜索“转基因”,那么这个转基因的文本出现在标题中,还是出现在导语中,还是出现在正文中,体现在分数上应该是不一样的。显然出现在标题中应该有更高的分数。同样也需要考虑业务数据,比如一个阅读量10万+的帖子和一个阅读量3的帖子相比,即使阅读量低的帖子文本相关性更强,但是显然10万+的帖子应该在前面。
其实所有的数据都可以分为两类,文本和数据。文本用于计算内容的相关性,这部分的打分交给Lucene成熟的算法解决,目前市面上也都有成型的开源解决方案。而怎么处理文本之间的关系,以及数据之间的关系,才是一个搜索系统设计最核心的部分。
以基于Lucene的Solr系统为例,文本和数据配置代码其实很简单。在<str name=”bf”>和<str name=”qf”>标签中只需要几行代码就能完成。
- <str name=”bf”>中是对于业务数据赋予权重。
- <str name=”qf”>中是对于文本数据赋予权重。
在研究过Solr系统这个机制之后,对Solr核心公式进行变形,就得到了一个公式:
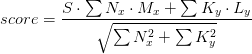
代表针对文本
,我们给出的文本分数权重。比如这个系统中有三种文本,标题,导语,正文。根据重要性,标题权重为10,导语权重为5,正文权重为1。
代表针对文本
代表针对数据
,我们给出的数据权重。比如这个系统中有三种数据,评论量,分享数,阅读量。根据重要性,标题评论数权重为100,分享数权重为200,阅读量权重为1。(一般而言会引入
时间衰减性,这里暂不讨论)
代表针对数据
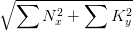 代表归一化系数,意味着权重可以给的非常大,最后总的分值也会在一个合理的范围内。
代表归一化系数,意味着权重可以给的非常大,最后总的分值也会在一个合理的范围内。是本次根据算法索引判断出的。代表本次打分,用户输入query提供信息的信息量大小。如果输入query提供了越多的信息,则S越大。
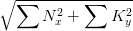 不变,
不变,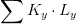 之前的系数不变,
之前的系数不变,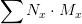 之前的系数增加。而
之前的系数增加。而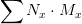 代表文本数据的对整体分数的贡献,则
代表文本数据的对整体分数的贡献,则
所以我们可以看到,其实最终影响排序的,是我们对于文本数据和业务数据的赋予的权重,即: 代表针对文本
的权重,和
代表针对数据
的权重。
这两组数据,影响了搜索最终的排序,而这组数据的赋值,正是搜索系统的对业务的理解。
7. 小结
本篇文章是对于搜索系统工作原理一个整体的介绍,对于原理的理解,是设计系统举重若轻的基础。
在这些基础原理之上,搜索系统还有很多标准功能。那么一个比较完备的搜索系统应该具备怎样的标准功能?这些功能又有着怎么的原理?移动时代,搜索前端设计应该如何规划?欢迎关注专栏,继续收看下期。
#专栏作家#
潘一鸣,公众号:产品逻辑之美,人人都是产品经理专栏作家。毕业于清华大学,畅销书《产品逻辑之美》作者;先后在多家互联网公司从事产品经理工作,有很多复杂系统的构建实践经验。
本文原创发布于人人都是产品经理。未经许可,禁止转载。


















这篇文章 准确率与精准率的概念没有说清楚,文章中错把精准率混为了准确率,
这是干货无疑了,有视频么。求详解
不错
我感觉,分词之后,分为 中国 转基因 食物 这三块时,进行相关词的索引的时候,应该还要考虑一个是不同词搜索结果与其余词的匹配度,还有一个是TF-IDF值吧
f值用来干嘛的
5分钟,呵呵
在高级搜索中,全部关键词、任意关键词、不包含关键词输入后,会怎么处理?也同样会被这么分词吗?
会被分词
你这里的“准确率”和“召回率”指的是全局的,是针对所有搜索的结果来说的,那么可以推断出目标函数F也是一个全局的结果。我特别好奇的是如何判断一篇文章是否被召回呢?
人工判定
计算准确率 和召回率中A/B/C分别代表什么?
据我理解,是搜索结果根据“是否召回”和“是否相关”两个维度分类而产生的四部分内容。
写得清晰