
 起点课堂会员权益
起点课堂会员权益一篇文章了解机器学习

最近正在做一个机器学习相关的项目,在这之前自己也没有接触过机器学习。可谓边做边学,在这里把自己的学习理解记录下来,同时也希望感兴趣的同学可以通过这篇文章对机器学习有一个大致的了解。这篇文章没有专业的技术语言,旨在让机器学习之外的人能够对这门技术有一个初步的认识。
背景
机器学习(Machine Learning)是一门专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的学科。1959年美国的塞缪尔(Samuel)设计了一个下棋程序,这个程序具有学习能力,它可以在不断的对弈中改善自己的棋艺。4年后,这个程序战胜了设计者本人。又过了3年,这个程序战胜了美国一个保持8年之久的常胜不败的冠军。这个程序向人们展示了机器学习的能力。
机器学习的定义
机器学习,顾名思义就是让机器进行“学习”,这个名字使用了拟人的手法。
但是计算机是死的,怎么可能像人一样学习呢?
传统的计算机程序,都是我们输入一串指令后,它按照这个指令一步步的执行,最终输出一个明确的结果,具有明确的因果关系。但是机器学习却完全不一样,没有明确的因果关系。它会根据你输入的数据而不是指令来进行学习和输出结果,相关而不是因果的概念是机器学习的核心概念。
因此我们说,机器学习是一种让计算机利用数据而不是指令来进行各种工作的方法。
它是人工智能的核心,是使计算机智能化的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。
基于机器学习的文本分类
文本分析一直是科学研究较为活跃的领域。毕竟创造所有人类知识(文本表示)不是一项轻松的工作。
下面我通过机器学习在文本数据分析方面的应用为例来简单的阐明具体什么是机器学习。如果你想简单的了解一下什么是机器学习,那么看完这篇文章就足够了。如果你想深入了解机器学习和人工智能,就需要多下功夫进行研究和思考了。
文本分析,即是让计算机对输入的文本数据进行分析,得到这篇文章的分析结果(如文本分类、正负情绪等)。进行分析的前提是,使用算法对文本数据进行分词和关键词提取,同时系统建立一个语料库。流程是,输入文本数据后,系统对文本数据进行分词和关键词的提取(关于分词和关键词提取的原理就不在这里展开说了,后续会抽时间进行分享),得到关键词数据后,与语料库的数据进行匹配,然后将匹配数据传输至分析引擎,得出分析结果。
这是目前行业中最基本的文本分析流程,这个流程本身是没有任何问题的,但是问题就出在计算机没有“自我”的意识,不懂得如何根据实际环境等因素进行灵活的变通,所以这样分析出来的结果可能会出现不准确的情况。举一个简单的例子,比如有一句话话“资本主义好?呵呵!”如果直接让计算机分析的话,也许得出的结果就是歌颂资本主义。但实际的情况却是批评资本主义。可以看到,在这种特定的环境下的分析判断,展现出会思考的人类的强大之处。
基于这样的情况,我们需要引入机器学习的概念。传统的计算机系统,都是输入A,得到的答案一定是B。但是通过机器不断的学习后,同样输入A,但是得到的答案可能会是B1B2或者BC。这就是机器学习后带来的变化,也正是机器学习的魅力所在。
先上一个关于文本分类的机器学习架构图。
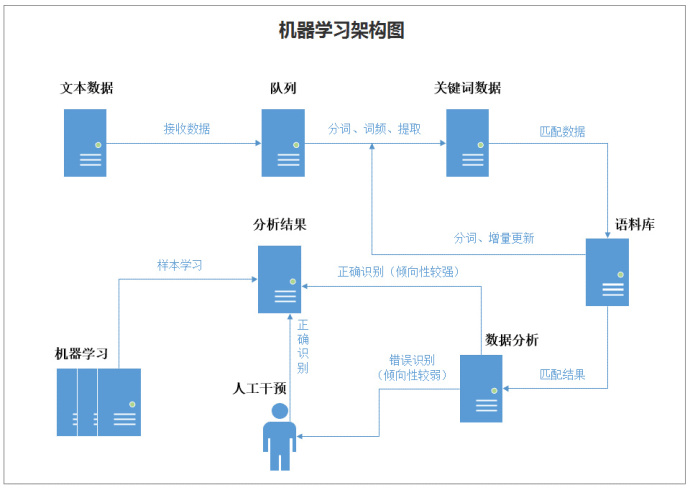
在图中可以看到,对于分析引擎可以正确识别的将会直接输出分析结果。对于分析引擎不能正确识别的,将通过人工干预的方式对分析结果进行校正后再将正确结果进行输出。而机器学习引擎将对所有的这些历史样本数据进行存储。接着,我们将这些数据通过机器学习算法进行处理,这个过程在机器学习中叫做“训练”,处理的结果可以被我们用来训练“模型”,当输入新的数据时,我们即可以通过“模型”对这部分数据进行处理。对新数据的处理过程在机器学习中叫做“预测”。“训练”与“预测”是机器学习的两个过程,“模型”则是过程的中间输出结果,“训练”产生“模型”,“模型”指导 “预测”。
下面这张图就是机器学习的过程与人类归纳经验的对比:

可见,机器学习中的“训练”与“预测”过程可以对应到人类的“归纳”和“推测”过程。机器的“模型”通过历史数据的积累学习具有了对新的问题和具体情境给出判断的能力,这正如人类通过过往的生活经验不断归纳整理得出一定的规律而具有了利用这些知识对新的问题进行判断能力。通过这样的对应,我们可以发现,机器学习的思想并不复杂,仅仅是对人类在生活中学习成长的一个模拟。由于机器学习不是基于编程形成的结果,因此它的处理过程不是因果的逻辑,而是通过归纳思想得出的相关性结论。
小结
机器学习即是用某些算法指导计算机利用已知的历史数据得出适当的模型,并利用此模型对新的情境给出判断的过程。
以上,为个人理解,愿与大家多多交流!
本文由 @Yonwon 原创发布于人人都是产品经理。未经许可,禁止转载。






- 目前还没评论,等你发挥!


