
 起点课堂会员权益
起点课堂会员权益
电商个性化推荐系统:协同过滤算法方案解析
 B端产品经理需要更多地关注客户的商业需求、痛点、预算、决策流程等,而C端产品经理需要更多地关注用户的个人需求
B端产品经理需要更多地关注客户的商业需求、痛点、预算、决策流程等,而C端产品经理需要更多地关注用户的个人需求
协同过滤推荐算法是诞生最早且较为著名的推荐算法,其主要的功能是预测和推荐。
算法简介
在网络资讯和电子商务信息爆炸式的增长,繁杂的信息中容易造成流失,再次背景下用户的个性化推荐系统显得尤为重要,对电子商务平台和社交信息平台产生了质的影响。
协同过滤推荐算法是诞生最早,并且较为著名的推荐算法。主要的功能是预测和推荐。算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。
其主要价值体现在:
- 将潜在用户转化为支付用户;
- 提升电子商务平台交叉销售能力;
- 提升客户对网站的忠诚度;
- 提升广告渠道转化效率;
- 提升用户个性化体验。
协同过滤算法分类
- 基于用户的协同过滤算法(user-based collaboratIve filtering,简称:ucf)
- 基于物品的协同过滤算法(item-based collaborative filtering,简称:icf)
算法阶段性工作内容
第一阶段
建立用户行为评分权重模型,达到对用户行为数据化和可视化,。
以电子商品平台为例:
- 某用户进入商品下单页权重2%;
- 点击详情权重8%;
- 收藏15%;
- 支付20%;
- 分享15%;
- 好评20%;
- 评分20%;
- 差评即分数为负数(向量为反方向)。
第二阶段
建立测试集和训练集。
- 训练集:用于模型构建;
- 测试集:用于检测模型构建,此数据只在模型检验时使用,用于评估模型的准确率。
测试集和训练集的建立是为了防止模型的构建过度拟合,更是为了监测模型的准确性和可行性,方便对模型进一步修正。
例如:在班级内按身高、腰围定制了衣服,衣服制作后全班同学穿上很适合,但当这个做衣服标准推行到全校时,制作的衣服很多同学穿不了,原因可能是没有考虑到肩宽、臂展等。此处本班是训练集,其他班是测试集。
第三阶段
建立合理的数据监控,监视召回率、准确率和覆盖率。为模型后期修正提供依据。
计算公式
欧几里德距离公式
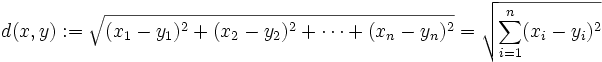
(为方便控制可取倒数,使结果分布在0—1之间)
![]()
余弦定理计算公式(N维空间)
![]()
(此处V1和V2为向量)
计算流程

应用实例
【余弦公式和ICF为例】以用户实际评分为起点,建立商品评分矩阵(如下表)
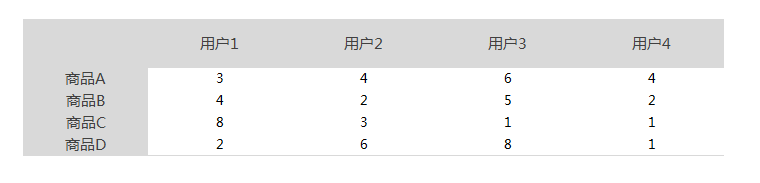
- 通过计算4个用户(四维空间中)对4件商品的评分我们获得了用户间的相关性数据(如下表)。
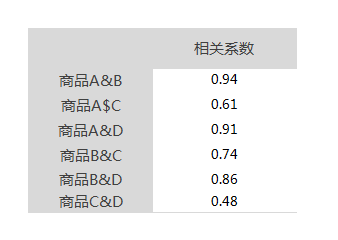
系数浮动区间在-1~1之间,系数越靠近1,向量夹角越小,两件商品的相关性越高,由此可见A&B、A&D的相关性最高,C&D相关性很弱。
相关系数:
- 强:0.8—1.0;
- 较强:0.6—0.8;
- 一般:0.4—0.6;
- 弱/不相关: 0—0.4;
- 不推荐:-1.0—0;
2、利用用户对某商品产生过的记录计算其相关性。
【例如】:某用户对商品A和商品B的行为得分为权重,对商品C和商品D进行加权排序,得分高者优先推荐。
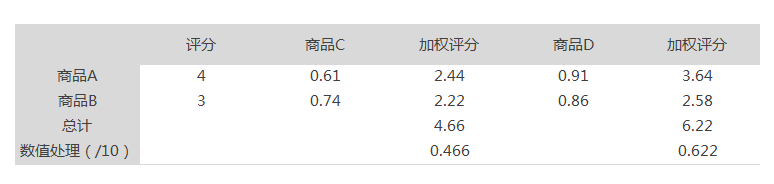
根据相关性和加权评分后,商品C优先被推荐。
数据去噪修正
- 对大众化,一线流程产品进行剔除,原因是本来具有超高曝光率和知名度的产品,不推荐用户才能很快触达,不必进行不需要的推荐。
- 对用户浏览和购买过的商品进行剔除,以免造成重复性。
- 对商品归一分类,避免商品的跨类别推荐,造成用户并不需要此类商品。
【 例如】:对某用户买衣服A,经过算法的综合排名,发现排第一的是方便面,排第六的才是衣服B,结果推荐了方便面岂不闹了笑话。但是对商品进行了归一分类,服装类商品只限推荐服装,这样服装B就会优先推荐。
- 对商品类别间建立合理的加分机制,并对低频商品建立合理的惩罚分值,使其推荐其他周边商品。
【例如】:家具类商品为低频商品,用户长时间内只需要买一件,购买后再次推荐也无法提升支付率。但是可以在用户支付下单后,通过计算,推荐家具的其它周边商品(例如:饰物、窗帘等)。由于设定合理的惩罚分值和相关商品类别的加分机制,可以一定程度上提高周边商品的推荐率,降低低频商品的推荐率,从而由侧面提升支付转化率。
方案弊端
数据稀疏性。由于此类协同过滤的模型需要有训练数据支撑,而在冷启动期间用户不会在数据模型中完成所有项目,所以数据会有稀疏性。
【解决思路】:可以按该类别商品的用户平均水平进行推荐(项目冷启动期间的方案待探讨)。
可扩展性。协同过滤算法能够容易地为千万记用户提供量化的推荐,但是对于电子商务网站,往往需要给成千上万的用户提供推荐,这就一方面需要提高响应速度,能够为用户实时地进行推荐;另一方面还应考虑到存储空间的要求,尽量减少推荐系统运行对系统的负担。
【解决思路】:划定计算范围,对无记录和类别相关性差距较大的商品、无操作记录的用户进行剔除性。由此减少计算压力。同时为提升用户体验,可以在离线期间对推荐数据进行训练和计算。但以上方案会在一定程度上影响到推荐的精确
以上解决思路需进一步探讨,欢迎大家一起进行交流~~
结语
真正完善的个性推荐系统需要进行基于物品的协同过滤、基于内容的协同过滤和基于模型的协同过滤组合使用,并结合平台自身的商业模式、业务模式特性、召回率、覆盖率和转化率进行不断的优化,建立各种辅助模型才能达到最优。
希望各位朋友来提提想法,有好想法大家一起探讨交流。
本文由 @呵哈嘿~ 原创发布于人人都是产品经理。未经许可,禁止转载。

















如何优化
权重比例的依据是什么?拉取K个相邻商品评分,相邻的商品怎么定义?K是个什么数值,有什么要求?
有个为题,为什么进入下单页权重才2%
您好针对,权重这块我不是太理解,您方便留下微信,请教一下您
不是商品D优先被推荐?
是D ,笔误了~
沙发