
 起点课堂会员权益
起点课堂会员权益如何获得更好的内容推荐体验?Netflix的《捍卫者联盟》实验有些答案

最近广受期待的漫威剧《捍卫者联盟》在Netflix放出之后,Netflix官方展示了他们基于这部剧做的内容推荐尝试与数据实验。以此为契机,我们或许可以一窥“别人家的推荐引擎”。
Netflix在互联网时代的成功,是一件非常值得回味的事。
作为一家以租赁起家,以流媒体平台这种不算很新锐的企业特征,获得了世界科技领域的普遍认同,甚至能够与巨头一较高下。Netflix显然不止是在内容和品牌宣传上作对了一些事情。
比如说,有长期使用Netflix经验的朋友(虽然目前在国内有点难),肯定会对Netflix的个性推荐系统留有深刻印象。事实上,Netflix在内容推荐上的技术实力与效率一直广泛受到业界认同
根据Netflix提供的官方数据,使用个性推荐系统之后,其平台用户的观看率提升了3到4倍,而基于个性推荐系统打开的视频数量,是从最受欢迎列表打开数量的4倍。
在国内,“千人千面”“内容找人”近两年也是很热门的话题。但很少有人分析内容推荐系统的内部逻辑,以及更好的内容推荐系统需要哪些因素。
最近广受期待的漫威剧《捍卫者联盟》在Netflix放出之后,Netflix官方展示了他们基于这部剧做的内容推荐尝试与数据实验。以此为契机,我们或许可以一窥“别人家的推荐引擎”。
懂算法的同时要懂内容
《捍卫者联盟》之所以特别,原因在于它就像《复仇者联盟》一样(好多联盟啊),是几个各自有独立剧集的超级英雄组合到一起的“混合剧”。
对于Netflix来说,这部剧的价值在于这四位英雄有各自的受众群体(铁拳应该没有中国受众吧),而组合起来的人设与故事是否能覆盖各自人群之和,还是应该推向新的人群呢?

(四个独立英雄受众有不同的观影喜好和关键词标记 )
针对这个问题,Netflix将《捍卫者联盟》当做了一块试验田,他们将密切关注这部剧的数据走向,并且对不同身份标识的用户实行不同的推荐策略。测试结果将形成新的机制,用来确定如何向不同的兴趣组提供“混搭剧”推荐,同时也可以根据反馈来确定以后是否要制作更多不同剧集人物的组合剧。
相比于国内的主流内容推荐引擎(无论是信息、短视频还是视频)通常采取以用户为中心,根据用户浏览、收藏、付费等行为来建构个性化推荐体系,Netflix让我们看到了另一种可能:以内容特征为中心,去分析不同内容可以推荐给谁,如何推荐,甚至是否要调整内容。“更懂内容的个性推荐”不仅建立在对内容文本特征的把握上,更重要的是技术能力足够支撑这种创造力。
否则从用户、内容双向互动来匹配推荐机制,将是一个工作量巨大且错误率高企的任务。那么问题来了,站在Netflix推荐系统背后的,究竟是一个什么样的技术体系呢?
好戏的基础,是一个足够大的舞台
简单来描绘的话,Netflix个性内容推荐机制的特色,就是要在保证用户使用流畅的前提下,不遗余力的装备更多、更复杂的算法组合。
具体的算法我们一会再聊。首先要弄清楚的问题是Netflix内容推荐系统的底层基础是什么。
假设我们认为,更多的算法和技术,可以带来更巧妙的运算和结果,并且相互制约出趋向合理的结论。那么平台的第一要务就是要保证运算能力可以负担复杂的算法与数据挖掘技术运行,并且保证平台可以敏捷轻松的加入后续越来越多的算法。
那么第一个问题就是运算能力的保证。我们知道,人工智能的多元算法要求的运算力特别高,传统的CPU+服务器模式在成本上很难满足复杂的AI系统运行。
而Netflix是最先尝试在AWS上使用GPU实现分布式神经网络的企业之一。虽然今天这种组合正在逐渐成为标配,但在几年前使用GPU代替大型集群的CPU作为平台支撑是一个创举。
这样不仅保证了计算力的稳定,还为更多的人工智能投入平台运用提供了契机。另外Netflix还率先把大量运算任务交给了云端,在AWS上进行分配式计算,确保了运算的高效率。
另外,我们可以注意到,Netflix在进行内容推荐运算的时候使用的是三种计算方式相结合:在线计算、离线计算和接近在线计算。
之所以要进行分工,是要保证运算复杂度和运算效率稳定统一。其中在线计算用来响应必须即刻完成的交互行为,确保用户指令得到实时响应。而离线计算因为没有时间限制,可以在运算平台上完成更复杂的算法运行和更大的数据量处理。这种运算的工作模式是系统从用户处收集数据,然后回到后端进行运算分析,再通过后期的交互表现在内容推荐上。
处于二者之间的是接近在线计算,这种运算承担的任务可以有延迟,但是也需要快速分析。把数据和任务进行区分,进行归类式学习与运算,是Netflix保证运算能力和使用体验达成平衡的关键。但是这种模式并不容易,关键在于要有精准的个性化架构,对三种计算模式进行无缝结合,统一规划在线和离线计算的过程。
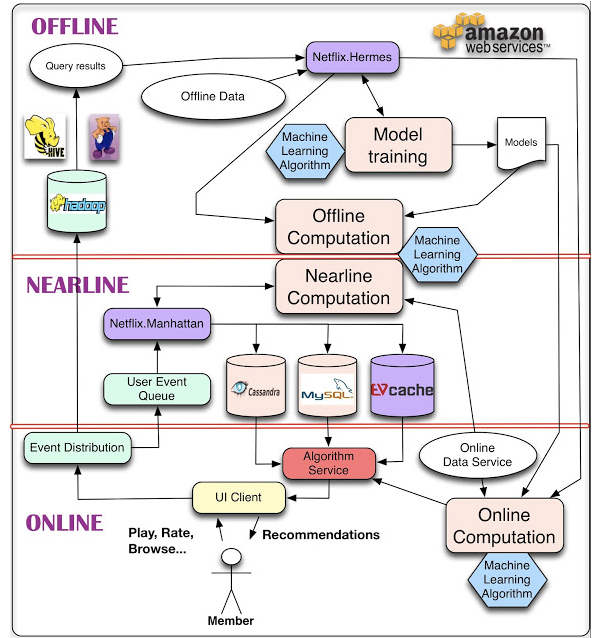
(Netflix内容推荐系统框架图,可以看到整个运算分为三种计算方式,而且其中主要组件包括多种机器学习算法)
在满足运算区分的同时,系统的架构还需要保证灵活的接入能力。因为新的算法可能随时加入进来,架构必须保证即插即用和可在原基础上进行开发。
从Netflix平台的运营经验来看,使用人工智能达成精准个性化服务的前提是保证平台的运算能力可以满足复杂的算法执行、处理大量数据,并且架构有很高的兼容性。
尤其重要的一点,是必须控制算法的部署成本与效率指数。
Netflix绝不是一个为了技术不顾成本的公司,比如在他们的架构中深度学习只占据很小一部分,核心原因并非深度学习类算法效果不好,而是因为深度学习会占据大量的运算力并且成本高昂。
有了足够大的舞台,人工智能才能闪转腾挪,巧妙的表演自己的本领。从几次公布的Netflix内容推荐系统中看,他们非常乐于用AI算法构建一个迷宫。
算法迷宫
高阶的内容平台的推荐引擎并不容易达成,因为在保证精准度的同时,必须实时外界内容和用户的数据变化,这样才能保证推荐结果最大化。
Netflix认为,相比于重于数据的搜索引擎,推荐引擎注重的是对知识的理解和运用,这让推荐引擎对算法的需求大大提升。因为既要满足用户画像模型的精准,又要对多种内容排列机制给出决策运算结果。
这就要求需求分析、技术选择、推荐算法质量三者达成有效平衡。而Netflix的解决方案是把多种算法和多端运算进行组合。
仅仅Netflix个性推荐系统中运用到的机器学习算法,就有线性回归(Linear Regression)、逻辑斯特回归(Logistic Regression)、弹性网络(Elastic Nets)、奇异值分解(SVD : Singular Value Decomposition)、(Restricted Boltzmann Machines)、马尔科夫链(Markov Chains)、LDA(Latent Dirichlet Allocation)、关联规则(Association Rules)、GBDT(Gradient Boosted Decision Trees)、随机森林(Random Forests)、矩阵分解(Matrix Factoriza),并且名单还在不断增加。
这里不讨论每一种算法具体给内容推荐带来的价值,但是想表明两点:没有能解决所有问题的算法,组合才是硬道理;算法模型间的结果互制,是确保Netflix推荐质量高的秘诀。
总结一下Netflix对机器学习等AI算法的态度,可以归为三点:
1.对新算法保持敏感和饥渴,对已有算法创新保持乐观。
2.愿意在多个产品功能树上以使用算法矩阵。
3.严格的算法测试。
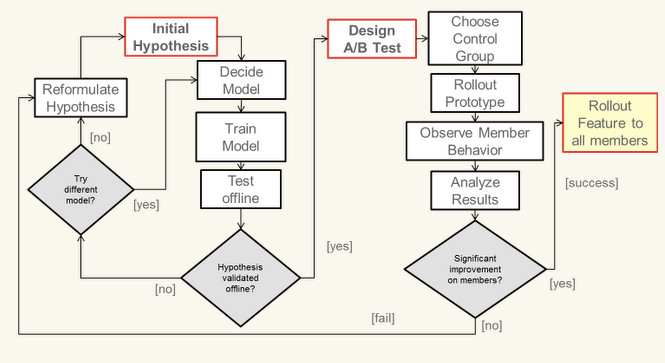
(Netflix测试内容推荐类算法的结构逻辑)
当然Netflix的推荐引擎绝非完美,还是经常有各种bug出现,但其构造推荐引擎的整个故事还是值得我们多想一些。
在具体技术之外的产品战略层面,Netflix带给AI产品应用的启示在于,“有AI”和“有很好用的AI”真的是两码事。
大量的硬件部署、运算支撑、框架开发、算法创新、应用测试以及对整个体系严苛的检验,都是巨大的投入成本。AI虽然能解决问题,但目前情况下还不能“很便宜”的解决问题。真的要投身AI,必须要对成本和投入有足够正确的认知。
具体到内容推荐引擎上,“根据你刚刚点击的关键词推荐”和“根据你推荐”,也是两码事。
好了,现在笔者要去回顾一遍《复联》,等等《蜘蛛侠》,刷刷《惩罚者》的消息了——希望这些可以减缓《捍卫者》带给我的打击与伤害…..
作者:风辞远
来源:微信公众号:脑极体(ID:unity007)
本文由 @脑极体 授权发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自PEXELS,基于CC0协议









“更懂内容的个性推荐”不仅建立在对内容文本特征的把握上,更重要的是技术能力足够支撑这种创造力。
可以再拓展讲讲前半部分对内容文本特征的把握上吗
很酷。