
 起点课堂会员权益
起点课堂会员权益资源防采集:产品如何进行防采集处理?

作者对资源窃取进行了一定的介绍分析,并分享了一些防护措施,希望对你有益。
近一两年中,“内容为王”被越来越多的互联网人所提及,就连BAT这些大佬级别的公司,也开始在内容领域投入大量的人力财力,各种资源内容层出不穷。但在这个时期,很多产品因风控意识不强、版权意识不足等问题,导致了大量核心资源外泄。今天我们就来简单聊聊如何防止这些“无形的偷盗者”。(此篇非技术篇,技术大神们手下留情)
偷盗者常用的盗窃手段
在文章开始,我们先简单聊聊我理解的恶意采集。所谓的恶意采集,就是将别家网站的图片、文字、视频、音频等资源下载至自家服务器,经简单处理后放入自家网站使用的过程。从这个定义中,我们可以看到,恶意采集是一种损人利己的行为。但是类似于百度蜘蛛、google蜘蛛这种可以带来流量的采集,我们不将他计入恶意采集的范畴。
接下来进入正题,我们来看看采集者通常是通过什么手段来采集我们的资源的。
盗取下载链接
这种盗取方式很好理解,在很多下载网站中(如百度文库、道客巴巴、21世纪教育网),当用户去请求下载的时候,服务器通常会返回一个下载链接给浏览器,用于下载。在这个过程中,采集者会将链接拦截下来,进行相应的解析,再通过脚本执行自动下载。喝杯茶的功夫,资源已经被采集走了。
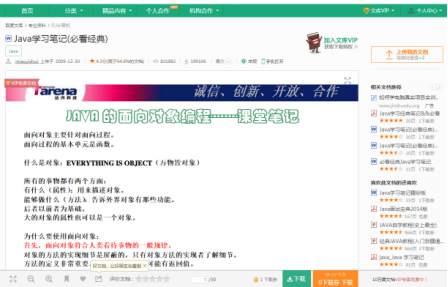
百度文库资源下载页面
盗取页面的内容
很多网站为了用户体验,通常会将一部分想看到的数据,直接加载在页面上,让用户进行查看。这时候采集者只需要解析页面的html结构,就能将页面的信息全部采集下来。百度爬虫、快照、页面采集基本上都是用了这个原理。
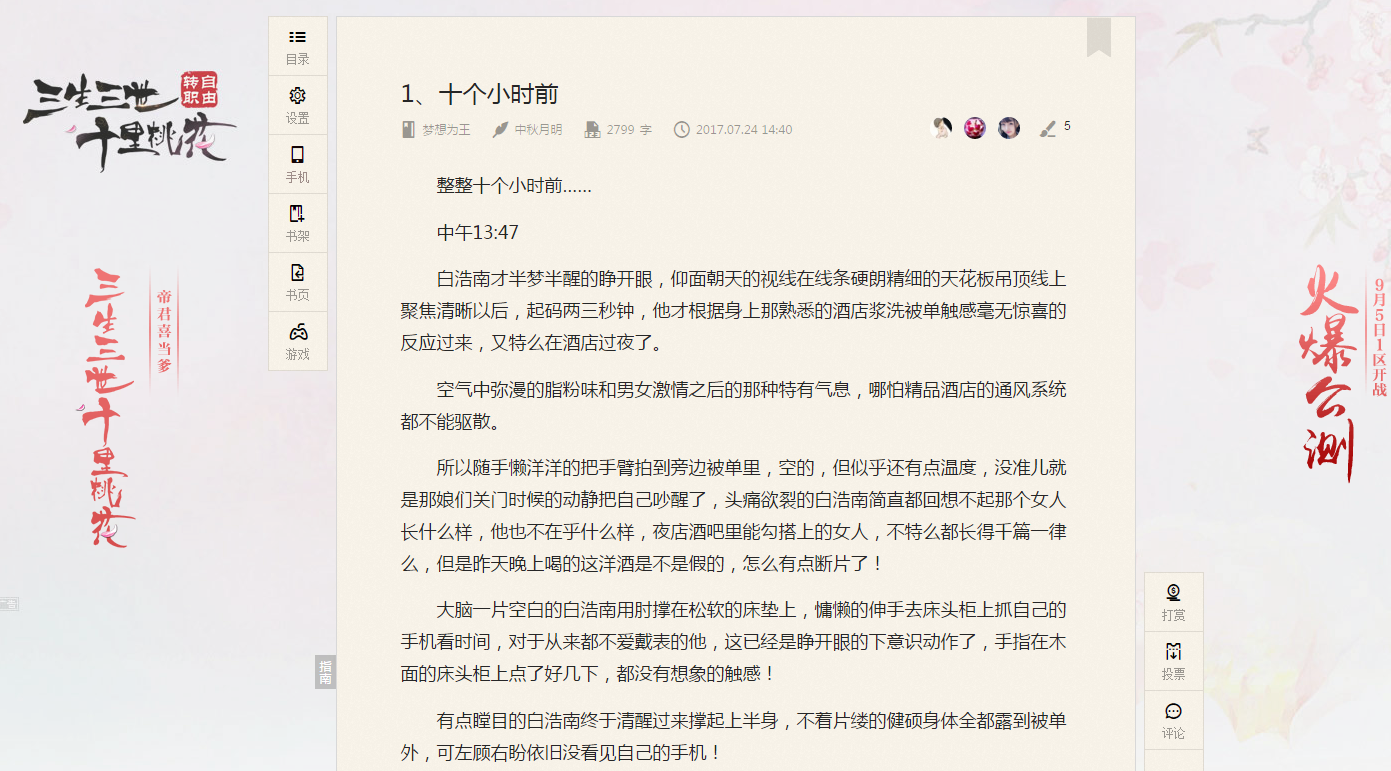
起点中文网
直接盗取web数据库
这个就比较高级了,采集者通常会编写一个爬虫,让爬虫自动发现网站上的查询接口,并且模拟接口的数据标准,向接口传输相应的查询指令,最后将返回的数据进行整理处理,就完成了相应的资源采集。
手动采集
手动采集从字面上理解,就是通过人工进行资源的采集,这种方式适用范围比较灵活,可以通过资源下载、复制等人工方式进行资源的采集。这种方式看着很low,效率很低。但往往这种采集方式,让人无比头疼。
PS:1个用户在A网站下载了一份word资料,经过简单编辑后,上传到自己的网站上进行使用。这个过程就无法通过技术手段进行跟踪(整个过程全是用户的真实操作),即使发现了这种现象,也无法确定对方盗取了自己的资源,因为你没有切实可行的证据。此处大家可以思考一下,百度文库的一部分内容是怎么来的。
防采集方法策略
上文中简单介绍了部分采集者的采集手段,接下来我们聊聊该如何进行防采集处理。
应对下载链接泄露的策略

上图为一份资料的下载流程,通过这个流程,我们发现,如果采集者可以直接拿到步骤3的下载链接,是可以不需要经过步骤2的验证,直接下载资源。这样我们就清楚了,要防止这种采集方式的话,我们的重点在于不让用户拿到资源的下载链接。那我们就可以按照下面的方式进行处理:
将下载链接进行加密
程序猿在开发过程中,基本都会进行下载链接的加密处理。加密就好比一把钥匙,没有钥匙就开不了锁,加密一样的,不知道解密方式,是无法破解你的下载链接,这样便实现了资源的防采集。
解密是需要知道加密规则的,所以在做加密处理的时候,最好不要使用第三方机加密规则,自己做最安全。定期维护加密规则,也是有必要的。
防止采集者拦截下载链接
有一部分采集者,会在步骤3与步骤4之间,拦截传输出去的下载链接。这样他不需要经过步骤2,一样能拿到我们返回的下载链接进行下载。遇到这种情况的时候,我们可以考虑在下载url加入用户验证。在浏览器解析url的时候,验证当前用户是否是我们的下载用户,达到防采集的目的。除非用户能拿到我们的账户信息,否则是不能采集到我们的内容。但是这种方法无法支持断点下载。
告诉你一个秘密,将网站升级升https协议,可有效的防止数据的拦截哦。
应对页面采集的策略

上图为一个页面完成显示的过程,在这个过程中,我们可以发现,采集者如果要拿到这个页面中的数据,必须进行第1步与第3步。所以我们需要在这两步对采集者进行防范,具体的方式如下:
限制请求数量
我们可以通过限制关键数据的请求次数来限制采集者采集数据。这个很好理解,当用户请求数据超过多少次的时候,再次请求,我们将不给他提供相应的数据。这个方法简单粗暴,但是很有效果。在进行限制请求数据的时候,我们需要注意以下几点:
- 判断数据请求次数时,必须通过用户名(用户ID)进行判断,不能通过IP地址。IP地址可以伪造,实现1次请求换1个IP都是可以的,所以通过IP地址判断的话,基本没什么效果。
- 保证账号的注册难度。很多产品仅开放了通过手机注册账号,即使使用第三方登录,也需要绑定相应的手机号码。这大大增加了采集者获取账号的难度。
- 评估用户每日浏览这些关键数据的次数。尽量不影响用户的正常使用。
- 提供无法直接使用的数据
页面中加载的所有内容,采集下来都是可以直接使用的,那怎样提供无法直接使用的数据呢?这里就不绕圈子了,所谓无法直接使用的数据,是因为采集的资源带有部分版权,或者格式必须经过转换才能使用。这样便增加了采集的成本,在一定程度上预防了数据擦剂。
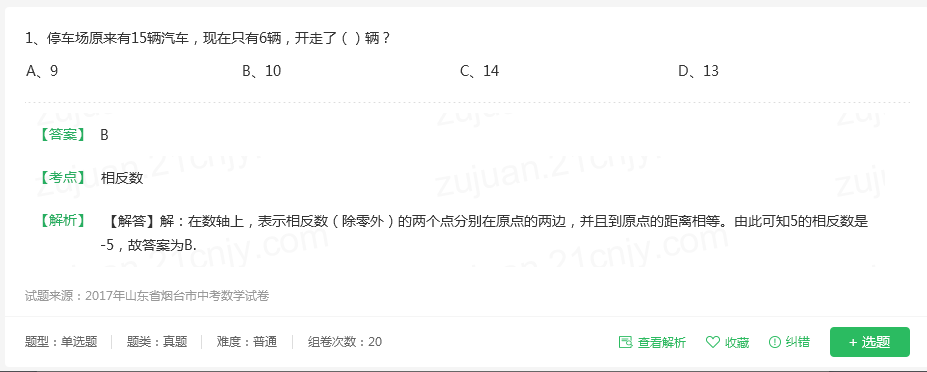
上图是一个题库产品的试题展示,他把试题中关键的部分(答案解析)用带水印的图片进行代替。当采集者发现要使用这些数据的话,需要将图片记性处理,而且处理难度较大,成本较高。那还会采吗?
加入干扰数据
将关键数据的html代码中,加入错误/混乱的数据,利用爬虫采集数据的规则,将干扰(混乱)的信息提供采集爬虫,实现防采集的目的。这种方式会对网站的seo造成影响。
提供错误数据
当用户请求数据的次数超过一定频率的时候,再次请求时,可以传输错误的数据给采集者。采集者收录到错误的数据后,会对整批采集的数据都抱有怀疑态度,而不敢使用此批资源。这种采集方式会对seo与用户造成一定的影响,慎用。
通过用户行为分析来防止采集
随着技术越来越发达,对用户行为的分析也逐渐成熟。我们可以将这项技术放在我们防采集领域,通过行为分析,判断用户是机器还是正常用户。是机器的话,我们可以根据情况,弹出验证码进行验证,也可以提供错误的数据。
上述的5种方式,是可以同时进行使用的,例如(1)与(2)合并在一起,在用户未登录的时候提供方案(2),用户已登录时,提供体验更好的方案(1)。更多的组合方式,可以自行进行组合。
应对页面采集时,需要考虑到seo的问题,千万不要将错误信息提供给爬虫(百度、谷歌等爬虫)。所以如果发现是这些“益虫”在采集数据的时候,尽量提供完整且正确的数据给它们吧。
应对手动采集的策略
前文说过,手动采集是最难防的,但是也不是没有应对方式,但是从根本上杜绝,也是很麻烦的。下面我们介绍几种方式:
- 、页面内容防复制。通过防复制处理,可避免普通用户复制页面内容,但是稍微懂点技术的人员,此功能是形同虚设的。
- 、限制用户每天的下载量。
- 、下载的文件中,带有产品的版权信息。视频中带有logo;文件中带水印;文件本身中增加不影响文件使用的标识。当我们的内容被上传到别的网站后,我们可以通过这些标识来维权,并要求对方下架相关资源。
- 采用人工检测,封号。
应对直接攻击web数据库的策略
程序猿知道这个如何去做,相信你的小组成员,让他去解决吧!
总结
此篇文章主要是抛砖引玉,希望通过我的分享,能让大家对防采集有个初步的认识,并应用到相应的产品规划中,增加产品的安全性。
作者:李英杰,二一教育高级产品经理,3年互联网产品设计经验,主要负责题库类产品的规划与运营工作。
本文由 @李英杰 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议









写的特别好,我就想问:停车场那道题为什么选B 😯
对,本文的重点没讲。。为啥选B
不是选A吗?怎么选B呢