
 起点课堂会员权益
起点课堂会员权益淘宝推荐系统:从千人一面到千人千面逻辑和算法(上篇)

应广大朋友的要求,本人对本篇文章进行一次更新,将推荐系统的底层逻辑和部分算法模型进行整合归纳,由于内容篇幅较长,分为上下两篇,请分别浏览!
互联网技术的高速发展,给我们带来了十足的便利性,回顾整个互联网的发展历程,从PC时代转移到移动互联网时代,从移动互联网时代转向IOT时代,从IOT时代又即将迈入AI时代,这些飞速发展的背后,其实是数据的采集,传输和处理的大变革。
而以我们当下为例,移动互联网技术和智能手机的发展,让采集用户数据的能力变得空前强大,无时无刻,无所不在,而一旦拥有这些数据之后全行业的个性化推荐技术变得更加容易实现,不论是今日头条的,还是淘宝美团的,无疑是这个时代的最大受益者。
不同于个人PC机,手机可以唯一锚定一个具体的自然人,而手机这类私人的专属物品是与其他人很难共用的,那么你手机的型号,在手机上的浏览、交易等行为数据,就具有了极高的分析价值。
从电商平台的角度来讲,个性化推荐技术的本质是将当前最有可能成交的产品优先推荐给消费者,使流量得到更加充分的利用,最大限度的提高转化效率。而推荐技术也随着用户个人数据的不断丰富,在逐渐升级,从最基础的千人一面,慢慢演化到千人千面,下面我就沿着这个演化史给大家具体介绍一下相关的推荐逻辑和模型算法。
NO1.千人一面的逻辑基础和推荐算法
- 核心逻辑:物以类聚,也即推荐和当前商品相似、相关或其他维度的产品,每个人进来看到的商品推荐其实是完全一致的,俗称千人一面;
- 使用环境:当前基本没有什么用户数据,但是商品数据丰富到足够支持起所需的推荐逻辑。
1. 根据商品的分类或其他基础属性进行推荐(相似性推荐)
对于某一个商品来说,这是一种替代性的推荐方式,也即用户不想买它的时候,还可以有其他的选择。就比如说用户正在浏览一个斯伯丁的篮球,看完描述之后发现不是自己理想的款式,规格材质不太对,但是在这个单品下方,出现了一个同类型的耐磨材质的篮球,OK!那么这个用户可能就会把这个推荐的篮球带回家。
这个例子中仅仅是依据商品的分类进行推荐,当然我们还可以根据实际情况加入商品的更多基础属性进行加权取值,算最后得分来进行推荐。
主要应用【加权求和法】
也就是选取商品的某些属性,并且针对各种属性的对于用户选择的重要性进行一个主观的评估,然后赋上权值,进行累加计算,得出每种商品和其他商品的相似性,案例如下:
水杯类目中选择三个属性【材质】【样式】【颜色】,其中【材质】重要等级为3,【样式】重要等级为2,【颜色】重要等级为1
- 商品A(塑料,大肚杯,透明色)
- 商品B(陶瓷,直筒杯,透明色)
- 商品C(玻璃,直筒杯,白色)
比对的两个商品每种属性的相似度关系值:
- 材质是否相同(不同为0,相同为1)
- 样式是否相同(不同为0,相同为1)
- 颜色是否相同(不同为0,相同为1)
在根据加权累加的公式,可以得到如下表格
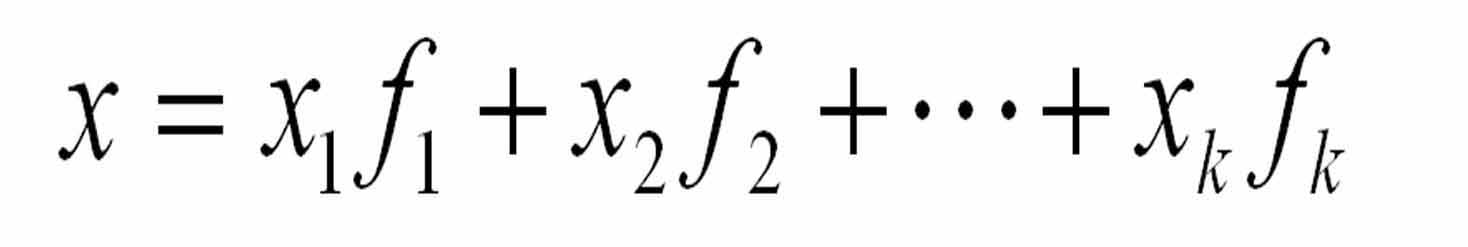
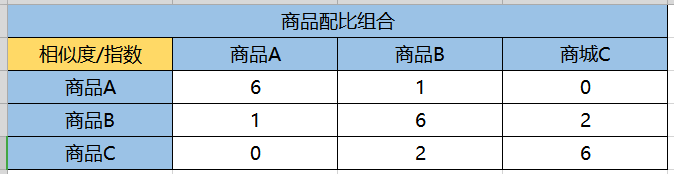
那么之后我们就可以在A商品之后,推荐这个相似度分数比较高的其他同类目下的商品了,当然自身就不需要重复推荐了,以及长期推荐点击量不高的产品,后面可以进行动态优化。
2. 根据商品的被动销售级属性进行推荐(相关性推荐)
根据商品最终在订单中出现的概率来判断商品间的相关性,目前还可以依赖于其他几个维度来参考一同做判断(被同时浏览的几率,被同时加入购物车的几率,被同时购买的几率),以下采取订单中是否通知购买来讲解算法模型,简单解释一下就是想买A的人还可能想买C。
主要应用【置信度】等指标算法
商品的关联性可以通过”置信度“,”支持度“,”提升度“三个指标来衡量。
难度较大的是从一个销售记录集中计算所有商品两两/三三之间的关联性,以下范例以两个商品之间的关联性来讲解。
- 计算A→B支持度,购买A还购买B这个组合的订单占所有订单的百分比。
- 计算A→B置信度,购买A还购买B这个组合的订单占所有购买A的订单的百分比。
- 计算A→B提升度,购买A还购买B的概率同不购买A只购买B商品的概率之商。
那么根据相关度算法,先从所有订单中找出包含A商品的订单个数N1,然后再查询A的所有订单中出现B的个数N2,则置信度X=N2/N1。
总订单为3000单,其中包含A的订单有1200单,B的订单800单,C的订单1500单,D的订单600单,E的订单 1000单
A的1200单中(包含B的有300单,包含C的有600单,包含D的有400单,包含E的有200单)

则C商品对于A的置信度最高,那么就可以优先推荐C商品,买了A商品的人最有可能还去买C,其实通常情况下,我们不可能仅仅单独看置信度这一个指标,三个指标都需要综合起来看,提升度大于1,具有强置信度(30%以上)和较高支持度(10%)的规则可以认为是比较合理靠谱的规则,计算其它2个指标的值就不在此赘述了。
NO2.千人十面的逻辑基础和推荐算法
- 核心逻辑:人以群分,将有相似的属性,相似行为的用户分为一类人,然后这一类中的人某一个人喜欢A产品,那么其他人也有极大的可能喜欢A产品
- 使用环境:当前积累了一定的用户数据之后,可以开始试试用这种模式
1、根据用户基础信息进行推荐
用户注册和后期行为过程中系统可以收集分析出一些固定数据,这类数据是长期稳定的,可以刻画成一些人群特征,我们俗称标签,而整个推荐系统中最牛的位置,也在于标签的大范围深度应用,其中基础标签可能就是年龄标签、性别、收入范围、兴趣爱好、星座、生活区域等,那么标签完全相同的这一类人就极有可能有相同的喜好(一般还会把行为加入一起来判断相似性)
比如一个用户的标签组成为:20—35之间、女性、低收入人群、爱宠人士、双鱼座……,最近刚好购买了一袋X品牌的狗粮,那么则另外一个标签与她相符的人,也可能在某个时间段产生这个需求。
2、根据用户行为数据进行推荐
比如在电商的场景下,常见的用户行为就会有搜索、浏览、咨询、加购、支付、收藏、评价、分享等等,那么通过记录这些用户行为数据,我们就可以对应进行推荐了。
①基于搜索关键词进行推荐
对于一个新注册的买家来购物,这时候大部分数据都全无,咋办?因为这个买家除了具备一些基本的人群属性外,购物行为和购物偏好方面是空的。好,这时候我们可以根据他搜索的关键词来进行跟踪推荐,依据搜索同样关键词的其他用户最后达成的商品成交概率来进行合理推荐。
举个例子:如连衣裙这个产品,在风格上有韩版的、欧美的、田园风格的等等。那么搜索引擎通过分析以前搜索“连衣裙”这个关键词的其他消费者,发现70%以上的消费者最终都购买了“韩版”的,那么韩版就是一个高概率成交风格。所以,展现这一类型的商品在这个新用户面前的。
②基于浏览记录进行推荐
对于淘宝这种大型系统来说,在整个网站中和app中的所有浏览记录的时间脉络,它是全部有记录,完全能够做到判断你在何时看到什么商品,同时浏览的行为背后即代表这关注,表明用户对此商品感兴趣,那么我们完全可以根据这一类商品的相似度进行关联推荐,用户所有浏览行为都是商品推荐的重要依据。
举个例子:每次你搜索并且看完一些宝贝后,关闭淘宝,过一段时间再打开淘宝,你就可以看到在“猜你喜欢”模块中出现之前浏览过的同类商品。
③基于购买记录的推荐
其实这是很好理解的,因为你已经购买了,所以这证明了你对产品的认可,甚至是对这个店铺的认可,尤其是在一些比如说衣服、视频、鞋子、宠物用品等复购率较高的商品中。如果你在这个店铺里面买过,那么你在搜索相关的关键词的时候,这个店铺符合要求的商品就会被优先展现(尤其是新上架的商品),方式是:购买过的店铺。
举个例子:淘宝中,你收藏的店铺、浏览过的店铺等等,都会以一种强个性化的方式得到优先推荐,而且还会给你添上标签“购买过的店铺”。在绝大多数类目里面,这种最高级别的推荐都是非常明显的。
喜好度评分、向量余弦公式
基于用户的协同过滤(user-based CF),通过用户对不同类型的商品的喜好度进行评分,然后根据每类商品的喜好度评分构建一个多维向量,使用余弦公式有来评测用户之间喜好度的相似性,基于此将其他相似用户非常喜欢而该用户还没有了解的产品进行推荐。这部分推荐本质上是给用户推荐其他相似用户喜欢的内容,一句话概括:和你类似的人也喜欢这些商品。
关于喜好度的计算,先将用户行为的权值定义清楚,假设定义如下:
- 搜索权值为1;
- 点击流量权值为1;
- 加购权值为2;
- 咨询权值为1;
- 完成支付权值为3;
- 好评权值为2;
- 分享权值为3;
那么在系统中加入埋点,产生用户行为数据之后,我们将可以获得用户关于某类商品的喜好度具体分值,加权平均后分值区间为【0,13】
在假设商城类仅有5类商品:
- 对食品类目的商品喜好度(0~13分)
- 对家居类目的商品喜好度(0~13分)
- 对玩具类目的商品喜好度(0~13分)
- 对图书类目的商品喜好度(0~13分)
- 对游戏类目的商品喜好度(0~13分)
一个用户A:对食品的喜好度为3,对家居的喜好度为1,对玩具的喜好度为4,对图书的喜好度为5,对游戏的喜好度为0,用户A可以用向量表示为
一个用户B:对食品的喜好度为3,对家居的喜好度为4,对玩具的喜好度为5,对图书的喜好度为0,对游戏的喜好度为2,用户A可以用向量表示为
接下来就要使用的【余弦函数】了,这边要和大家解释一下向量的概念(可能很多人高中数学已经忘记了),向量是空间中带箭头的线段,2个向量之间的夹角越小,表明它们的相似度越相近,多个属性的向量表示为![]() 。
。
对于用户A的对于所有类目商品的喜好度向量![]() 和用户B的向量
和用户B的向量![]() 而言,他们的在多维空间的夹角可以用向量余弦公式计算:
而言,他们的在多维空间的夹角可以用向量余弦公式计算:
![]()
余弦值的值域在【-1,1】之间,0表示完全垂直90°,-1表示夹角180°,1表示夹角为0°,系数越靠近1,向量夹角越小,两件商品的相关性越高,。就刚才用户A和用户B的例子而言,我们可以知道他们的相似度为:
![]()
相似度系数推荐说明:
- 非常相似:0.8—1.0;
- 比较相似:0.6—0.8;
- 一般:0.4—0.6;
- 不太相似: 0—0.4;
- 完全不相似:-1.0—0;
那么根据这个余弦值的结果,我们会发现用户A和B在商品的喜好度上是比较相似的,所以在给A推荐商品时,我们就可以依照B喜欢的而A却从未浏览过的商品进行推荐,或者是其他B喜欢的商品等。
总结
目前大部分推荐都是多重算法结合的,以上介绍为了逻辑清晰,所以都是单一说明,没有进行组合,而现实中可能会依据相同标签相似喜好度的人推荐同类型的产品等,接下来的【下篇】,我会重点为大家介绍关于区别于给用户标签化的推荐方法,更高阶的是给商品、服务、店铺等全方位的标签化,同时还会介绍到标签的标签,比如标签的场景失效,标签的热度衰减等!
#专栏作家#
囧囧有神(个人微信公众号:jspvision),人人都是产品经理【2018年度最受欢迎】专栏作家,起点学院导师,成均馆大学企业讲师,混沌大学创新翰林。10年互联网经验,产品运营专家,Team Leader。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议










请问下篇在哪
快4年了,下篇呢???
快4年了,下篇呢???
三年过去了,说好的下篇呢
这都三年过去了 你说的下篇呢?
对食品类目的商品喜好度(0~13分),这个一定要是13吗,即所有权重只和。常规情况下采用5分制或者10分制,这两种有什么区别,谢谢!
楼主大大,这块总结起来应该是基于物和基于人的协同,能不能再介绍下比如在画像上的一些深耕的应用呢?
期待下篇
您好,这里有一个问题,相关度,如何算出来的。感觉重要程度 3 2 1, 是否相同是 1 0 的话,那么相关性 A对A 应该是6啊。。
抱歉 我的锅,已经修改和调整了过来~
出下篇呗
请问用户对某类商品的喜好度评分是怎么打出来的?
就没有了下篇吗。。