
 起点课堂会员权益
起点课堂会员权益初识推荐系统

文章为作者对推荐系统的一些理解,整理成文与大家分享,希望可以给你带来一些启发。
亚马逊的“与您浏览过的商品相关的推荐“、天猫首页的”猜你喜欢“、网易云音乐的”私人FM“等功能将一个词带入大家的视野:推荐系统。通过大家的使用及体会,更加感觉推荐系统的重要性。以下就是笔者对推荐系统的一些粗浅的理解,整理成文,供参考。
1.推荐系统为什么存在
正所谓”知其然,更需知其所以然“,在聊“推荐系统是什么”这个问题之前,我们更应该聊一下“推荐系统为什么存在”。
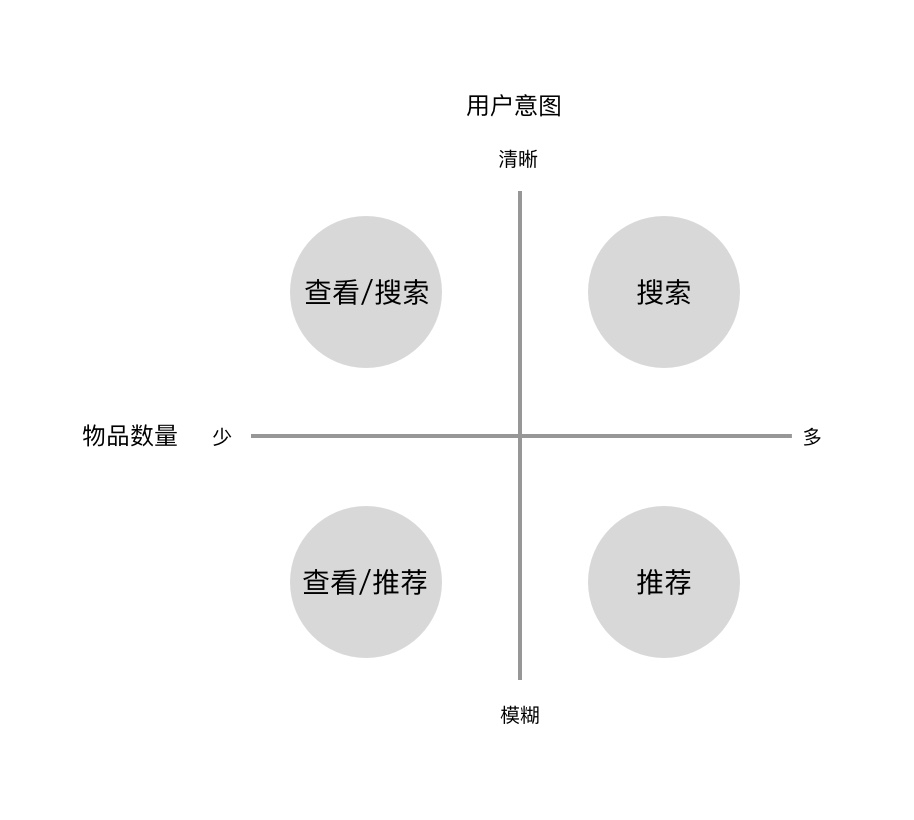
推荐系统解决的是人与物品(商品、信息等)间的问题,而这个问题受到物品数量和用户意图两个维度影响,下面以一个吃货的故事为例,来尝试说明此问题。
假设有一个用户特别喜欢吃面包,现在就从面包种类的数量、用户对自己口味的清晰程度来说明这个问题。
- 数量少、意图清晰
用户知道自己喜欢的是法棍,但是周围方圆500里就只有两种面包买,只有菠萝包和羊角包,没有法棍,那么这个用户要如何选择?要么选择不吃面包了,要么在菠萝包和羊角包中间选一个。
- 数量少、意图模糊
用户只是想吃面包,对口感和成分没什么要求,方圆500里还是那两种面包,用户去了看一看、尝一尝,再决定是不吃,吃菠萝包,还是吃羊角包。
- 数量多,意图清晰
用户知道自己想吃的是法棍,而且方圆500里买面包的实在太多,那这个时候用户要怎么办哪?可以问问警察叔叔那里有法棍买,或者打的问出租车司机,或者拿出地图或者大众点评上搜索下再去,或者进入一家店直接问店员有没有法棍买。
- 数量多,意图模糊
用户知道喜欢吃有嚼劲、全麦、无奶油的面包,而且此时方圆500里买面包的也实在太多了,那这个用户该怎么办哪?找一家面包店,把自己的需求告诉店员,让店员给推荐一款面包。
以上者四种情况对应下图的四个象限,当物品数量少时,其实用户都可以用查看的方式解决问题,因为数量少,查看的成本很低;但是当物品数量多,查看的成本就很高,所以当意图清晰明确时,就用搜索来直达结果;而当物品数量多,用户意图模糊时,就需要推荐系统了。这就是推荐系统的“所以然”,而我们现在就生活在一个物品/信息过剩的时代,一个很难判断自己到底需要什么的时代,一个大部分时间不愿去寻找的时代。
2.推荐系统所需数据构成
在上面吃货的例子中,如果用户进入一家面包店,但是也不说话,也不进行任何信息的交流,那么店员怎么判断用户的喜好哪?所以这个时候需要交流,也就是需要“信息的输入与输出”,也就是店员需要掌握用户的喜好数据,然后才能去进行推荐。
而用户的数据可以从两个大的维度来区分:
- 反馈数据是正向还是负向;
- 反馈数据是显性还是隐性;
- 如果用户很确定的说我喜欢吃口感松软的面包,这个就是正向反馈;
- 如果用户说我不喜欢吃口感松软的,这个对口感维度来说就是负向反馈;
- 如果你问用户是否喜欢吃口感松软的面包,用户斩钉截铁的说是,这就是显性反馈;
- 如果同样的问题,用户是皱眉、沉默,那么就是一个隐性反馈,而且是一个隐性负反馈;
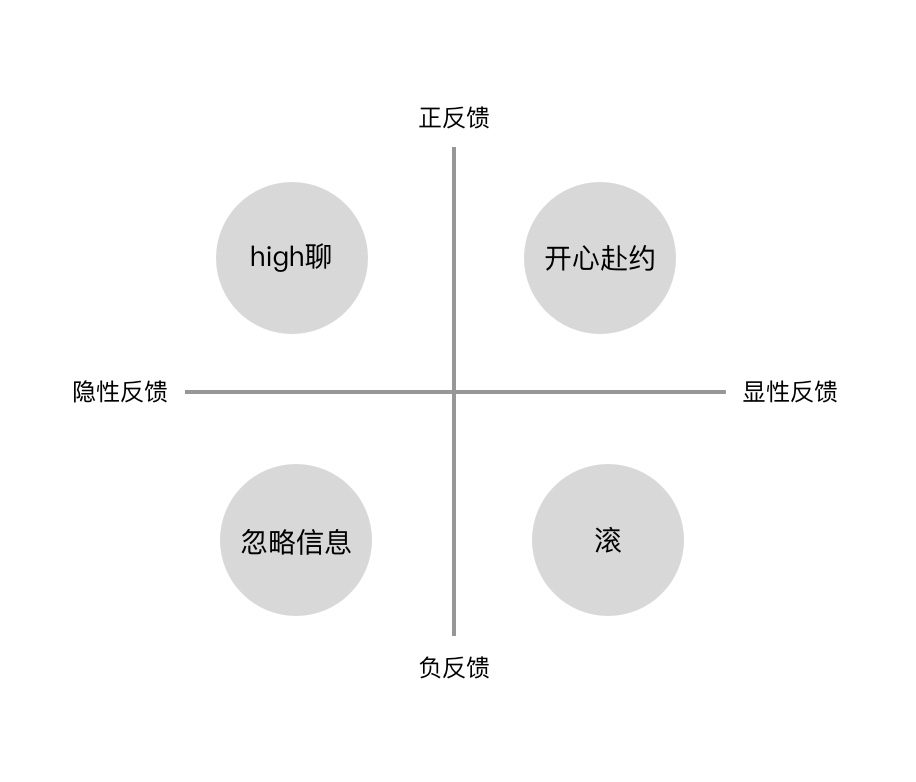
我们再以男生追女生举个例子,男主人公准备好鲜花美酒夜光杯,邀女主一起对影成双对,而女主的表现哪?
- 女主开心赴约,席间眉来眼去、笑得惬意,这就是明显在告诉男主:我同意了,你继续,非常显性的正向反馈;
- 如果女主接到邀约,直接微信回复;滚。这就是明显在告诉男主:我对你没意思,你不是我的菜,显性的负反馈;
- 如果女主既不回绝,也不同意,反复顾左右而言他的high聊,这大概率就是隐形的正反馈,因为女主不好意思直接同意;
- 如果女主直接忽略男主这条消息,而是从新篇章开始聊天,那就是隐形的负反馈,冷处理这个问题,让男主知难而退。
3.推荐系统的经典算法概述
数据已经准备就绪,接下来就是将数据充分利用起来,此时算法登场。在推荐系统里最经典的算法就是基于邻域的算法,其中又可以分为两类:基于用户的协同过滤算法(UserCF)、基于物品的协同过滤算法(ItemCF)。
3-1 基于用户的协同过滤算法(UserCF)
- 是否和我们相处关系越好的朋友,他们推荐的物品/内容,我们更容易接受?
- 是否和我们有共同业余爱好的同事,他们推荐的物品/内容,我们更容易接受?
- 是否在线下兴趣小组认识的陌生人,他们推荐的物品/内容,我们更容易接受?
以上的例子还可以举出很多,而这些例子中的关键点不是我们和这些人的关系多么亲密,而是我们和这些人在某方面的“共同点”有多大相关度。和我们关系越好的朋友,在某方面兴趣爱好的相关度越大(我们暂且不讨论相关度与关系好的因果关系),业余爱好相同、线下小组认识的朋友本身也在传递:我们之间在某方面的兴趣爱好相关度很大。而在某方面的兴趣爱好相关度越大,那么对方给我们推荐的物品/内容被我们喜欢的概率就越大。所以此处还需要强调一点:推荐系统推荐的东西是尽可能的推荐用户喜欢的物品/内容,尽可能的意思就是更高的概率,越趋近于1越好的状态。
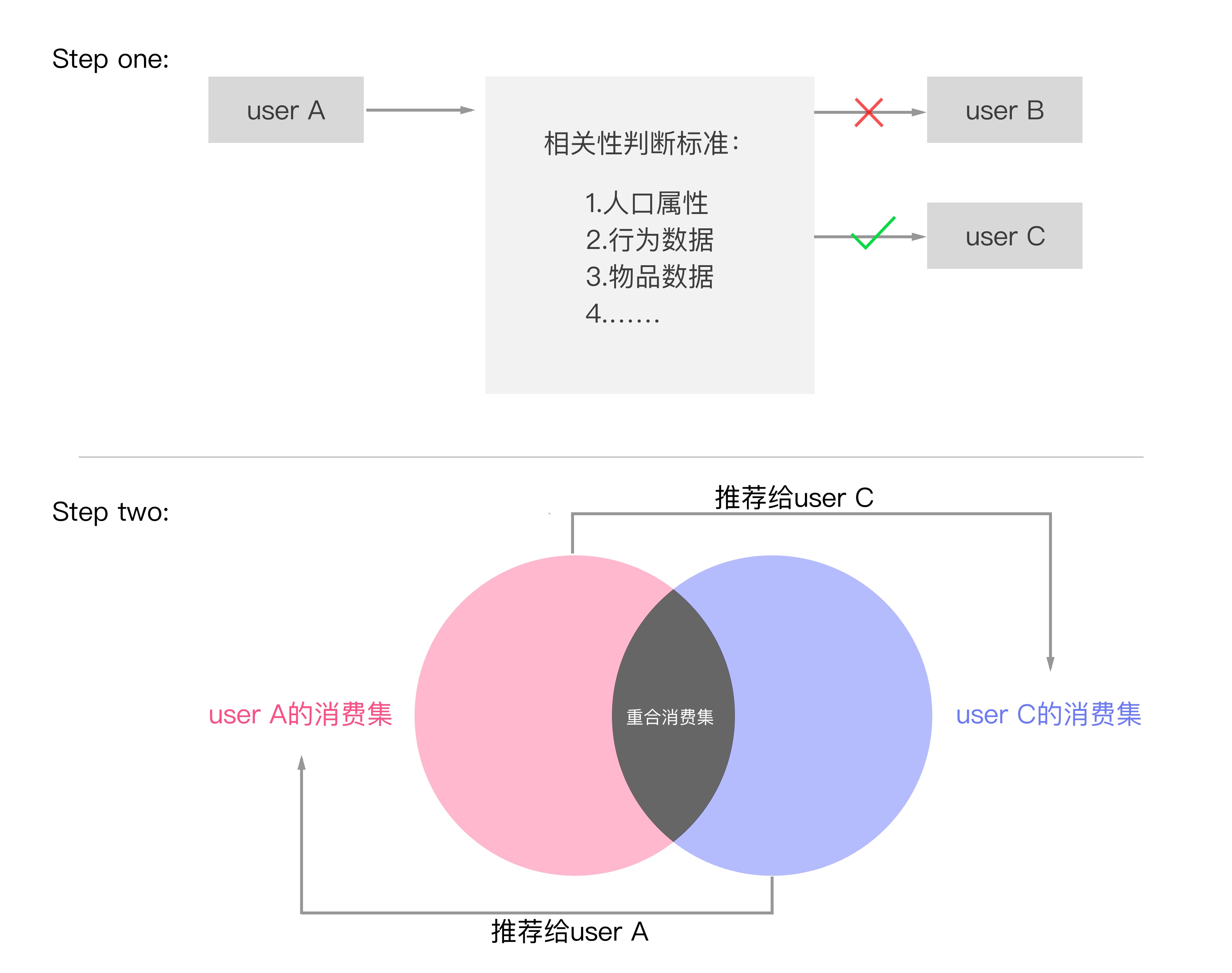
如下图片所示,我们通过人口属性、行为数据、物品的消费历史等,推荐系统发现user A与user C的相似度更高,那么推荐系统就会将user A的消费集中存在,但是user C的消费集中不存在的物品推荐给user C,对user C的消费集也会做同样的处理。
所以UserCF的关键点就是找到和“你”兴趣爱好相关度更高的用户群,然后将该用户群喜欢的、但是你并不知道、没消费过的物品/内容推荐给“你”。
3-2 基于物品的协同过滤算法(ItemCF)
UserCF是基于相关的用户找到应该推荐的物品/内容,而ItemCF是基于用户已经消费的物品/内容来寻找其可能喜欢的物品/内容。
- 如果我们买了一本东野圭吾的《白夜行》,商家为我们推荐一本柯南道尔的《福尔摩斯探案全集》,我们是否更容易购买?
- 如果我们买了一张陈奕迅的CD《十年》,商家为我们推荐一张陈奕迅的CD《K歌之王》,我们是否更容易购买?
- 如果我们买了一张重庆火锅的代金券,商家推荐一张我们湘菜的代金券,我们是否更容易购买?
以上的例子也可以举出很多,而这些例子中的关键点是根据用户的当前消费行为的对象,来寻找其可能喜欢的物品/内容。而此时就需要发现物品/内容间的相关性,其相关性越高,推荐后被喜欢的可能性上就越大。
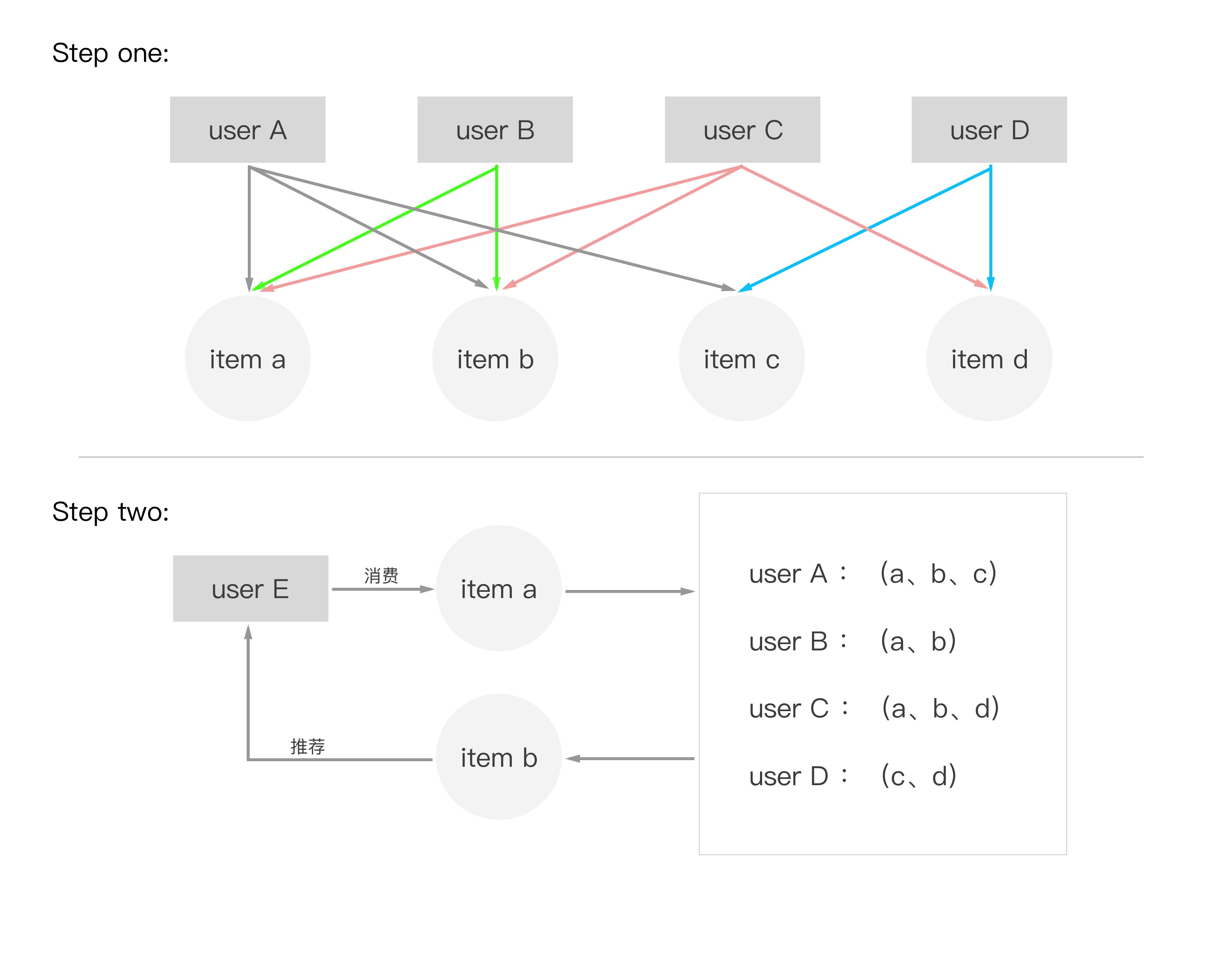
那么问题来了:如何判断哪些物品与用户当前消费的商品相关性高哪?通过其他用户的历史消费行为,当用户中大部分用户在购买了A商品时,也购买了B商品,那么证明A商品和B商品的相关性就高,当再有用户购买A商品时,我们便可以推荐B商品给该用户。
如图所示,当user E消费物品a时,推荐系统寻找与物品a关联消费最高的物品,由已有用户的消费行为可见,有3/4的用户同时消费物品a和物品b,所以推荐系统将物品b推荐给user E。
3-3 相关度
我们分别在UserCF中寻找用户间的相关度,在ItemCF中物品/内容间的相关度,那么这个相关度是如何寻找哪?在算法上有很多种,接下来我们主要聊聊其背后的思想。
首先说下UserCF中的相关度,我们在上学的时候,经常会参加老乡会,老乡会就是一个根据相关度而形成的团体,相关的指标是:我们的老家在一个地方。那么当我们通过更多的指标间相关度来判断的话,用户间的相关度将更加的高。比如当对比两个用户的听歌历史时,发现其重合度很高,那么将一方收听过、但是不在对方收听历史中的歌曲进行推荐,那么被喜欢的概率是否更高?
所以在UserCF中,相关度就是用户人口属性数据、历史行为数据等的重合度。但是ItemCF中是寻找相关的物品时,物品本身没有历史行为,那么该如何寻找相关度哪?此时需要引入用户,用户会对物品产生行为,而当用户对多个物品产生行为时,我们便可以知道物品间的相关度。比如买钢笔用户中,很多用户都一起下单买了钢笔水,那么当有用户买钢笔时,我们就可以推荐其钢笔水。
3-4 数据
以上的相关度分析都需要数据支持,而数据需要进行埋点,而在埋点前有个更重要的事情需要想清楚:
- 我们的目的是什么;
- 我们需要哪些数据;
- 这些数据是否真的有必要;
- 这些数据是否可以被某个已有数据替代;
- 是否可以用更加简单的方式来统计数据;
- 数据间如何关联可以方便后续的清理及分析;
然后可以将用户的点击、浏览、下单、路径、行为时长等数据尽可能全的记录,将这些数据作为原材料喂给数据模型,等待数据模型产出结果。
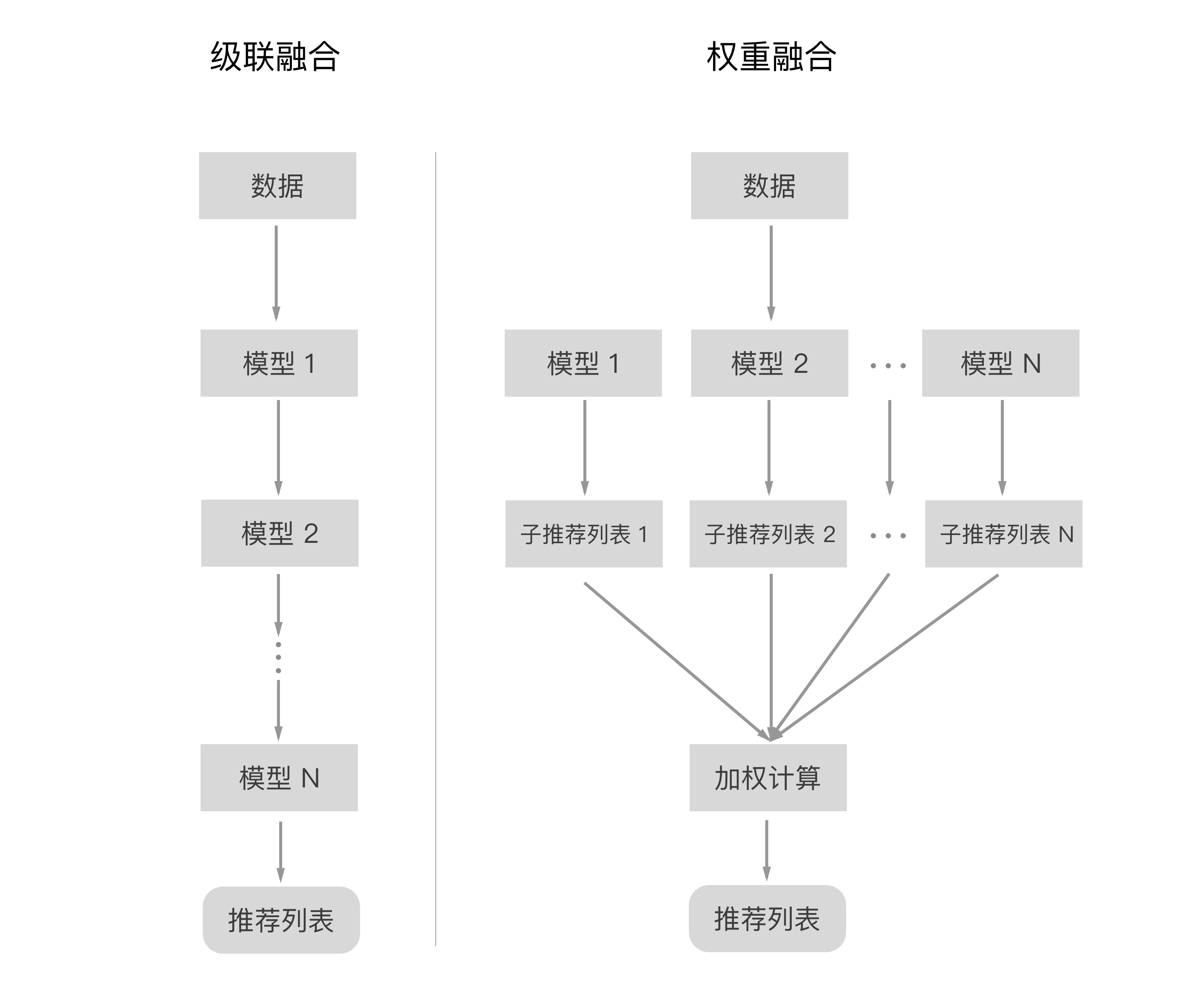
4.推荐系统的级联融合和权重融合
单兵作战的能力毕竟有限,不是所有士兵都是《战狼》里的冷锋,同样的道理,在模型中也是需要相互配合,而配合的方式有两个大类:级联融合、权重融合。下面通过两个类比来解释下两种配合方式的原理。
级联融合有点像净水器,将水进行逐层的过滤净化,然后输出我们希望得到的干干净净的饮用水,而推荐系统中的级联融合是将数据直接给到模型,而模型经过一层一层的过滤,最后反馈某个/某类用户的推荐物品/内容列表。
权重融合有点像麻辣烫,将各种吃食加热煮熟后,按照某种比例将他们与调味料进行混合,成为美味可口的麻辣烫,而推荐系统中的权重融合就是将数据直接给到模型,而模型中分为好多个子的模型,通过子模型算出给某个/某类用户的推荐物品/内容的列表,而此列表包含顺序因素,越靠前的内容被喜欢的可能性就越大,然后将各个子模型的列表按照某个权重进行加权,最后得到整个父模型的推荐列表,也就是该推荐系统给到用户的推荐物品/内容列表。
以上关于推荐系统的粗浅描述,只是推荐系统的一小小部分,关于推荐系统的上下文关系、实验方法、评价标准、冷启动问题等,暂不做论述,有机会再另行成文。对上面所述,笔者也不敢言之凿凿,望大家多交流指正。谢谢。
#专栏作家#
代成龙(微信号dcl_utopia),人人都是产品经理专栏作家,智能硬件创业公司产品狗,从视频巨头公司到玩智能硬件的公司,继续产品设计工作。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议









具体算法呢
我们的目的是什么;
我们需要哪些数据;
这些数据是否真的有必要;
这些数据是否可以被某个已有数据替代;
是否可以用更加简单的方式来统计数据;
数据间如何关联可以方便后续的清理及分析;
楼主能分享下你提出的这一连串问题的背后原理(逻辑)是什么呢,感觉很不错的样子,授人以渔哈哈
楼主现在是在设计推荐系统吗?