
 起点课堂会员权益
起点课堂会员权益企业级监控告警产品专题(2):IaaS层监控设计概述

本文作为监控告警产品的专题系列的第二篇文章,主要讨论的是IAAS层的监控(服务器状态与性能、网络设备状态与性能、网络流量分析等等),从前文所述的监控类型来说,IAAS层一般来说属于基础监控层面
庖丁解牛
IaaS
IaaS、PaaS、SaaS这三个概念想必大家是耳熟能详了,其实就是云计算的三个分层,Infrastructure-as-a-Service(IaaS)基础设施即服务,Platform-as-a- Service(PaaS)平台即服务,Software-as-a-Service(SaaS)软件即服务。
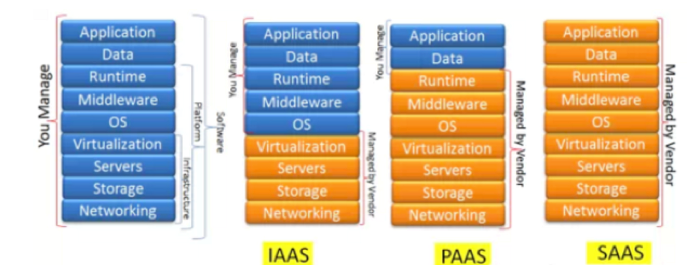
IaaS层其实就是一些显性可见的资源对象,如运维小伙伴经常接触的服务器、网络设备与存储设备等等。用一座大厦类比的话IAAS层就好比是负责了最基础的水电通信等能力。上层的服务都是依赖于IaaS层,假定IaaS层管理不好,那么PaaS与SaaS的高效与可控管理其实也是非常难了,甚至可以说空谈了。IaaSI层的不稳定会直接导致企业对外的服务质量大打折扣。笔者以前在负责手机QQ业务运维的时候,名下有4k多的机器,如果没有一套高效与可度量的管理平台,光凭人肉去管理4K多的机器,那基本和噩梦差不多了。
IaaS的监控
对于IaaS层的监控,本质来说就是监控组成IaaS层的各个资源对象,那么资源对象代表什么呢? 例如物理服务器、交换机、一条专线与一个公网IP等等都是一个个资源对象。通常来说对于资源对象的监控可以分为以下4个维度。

- 状态的监控:通指设备的的状态,如设备的存活状态、网络设备的端口状态、电源、风扇状态等。
- 性能监控:通指设备内存大小,端口流量包量、CPU利用率 等等
- 质量监控:通指设备的丢包率、错包率、网络访问的延时等等
- 容量监控:通指设备的负载使用率、专线带宽使用率、网络设备的负载使用率、服务器的负载使用率等等。
监控产品的分层结构
对于绝大多数主流商用或者开源监控告警产品来说,一般都是采用这种类似的分层方式,当然这里是一种高度抽象后的产品分层架构。
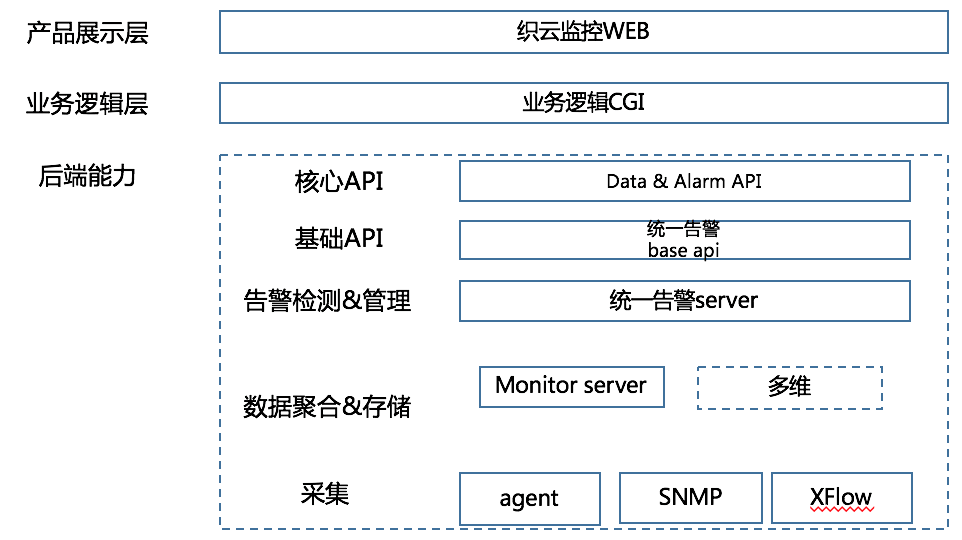
位于最底层的就是数据采集,采集到的原始数据是监控的最初的输入。
数据采集
通常来说企业级的监控系统应该是支持多种采集方式与多种采集对象的,例如可以用Agent主动上报、也要能支持SNMP、Xflow、IPMI等多种协议。而针对于IaaS层具体支持的采集对象应该不少于 物理服务器、操作系统指标(linux&windows)、网络设备、网络内会话信息、物理专线、网络出口等等。不同的采集对象采用的采集方式也是不同的,例如 服务器系统指标可以用Agent上报、网络设备状态、流量、包量可以用SNMP采集等,具体采用哪种采集方式要看业务场景与所需场景的数据量与类别而定。织云同样也是支持多种采集方式与多种采集对象。
在大数据的时代背景下,数据采集这部分建议针对某一个具体的对象尽量采集的大而全,可能有些数据暂时看采集上来没有直接用途,但是随着数据量级与数据间关联性的变化,对大量的原始数据,清洗、分析、加工后便能催生更多的数据消费场景。
基础概念
监控告警是对某一个具化的对象做采集、存储、分析、展示、告警、处理的过程。
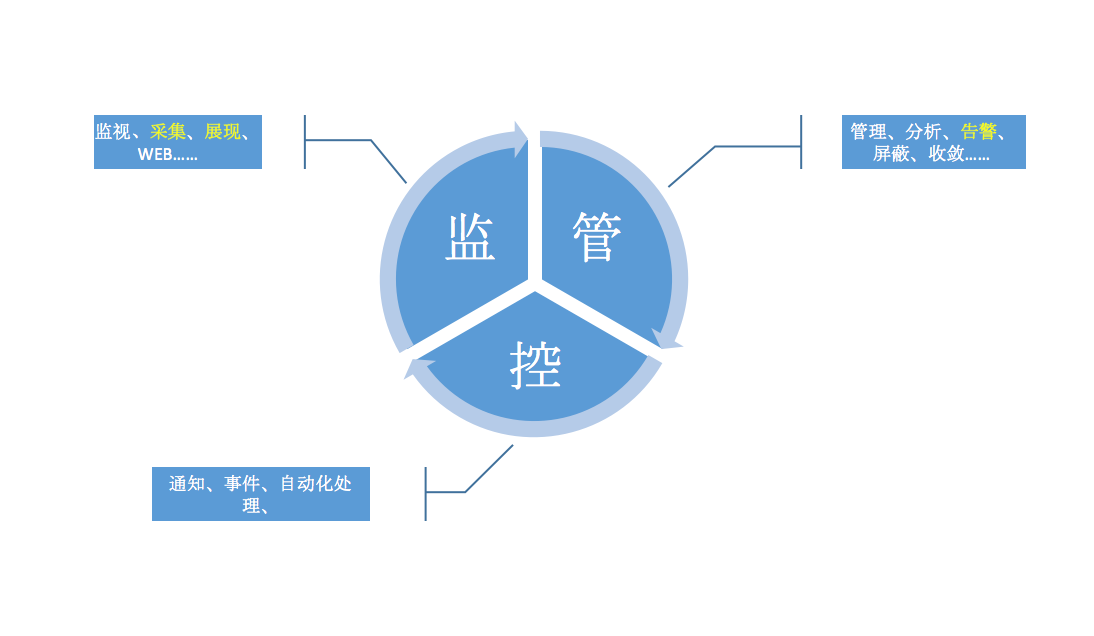
为了便于读者对于后文与后续系列文章的理解,这里笔者先集中描述一下设计织云监控告警平台时应用的一些概念。对于监控告警织云的理念是先纳管对象在监控对象,这也是海量运维的最佳实践。
告警(监控)对象
- 定义:CMDB中管理的一个具体资源对象或者是一个自定义逻辑CI
- 示例:一台物理服务器、一个三级业务、一个TDSQL实例,这些均是对象
- 备注:对象与对象之间也有是关联、包含、继承等关系
告警(监控)指标
- 定义:一个或多个特性id(或特性间的四则运算产生的结果)的集合
- 示例:CPU使用率、内存使用率均是特性id; 而 例如 成功率=(成功的请求总数/总请求数)*100 这个就是多个特性id的四则运算。
- 备注:并不是所有监控指标都可以用来做有效的告警指标,这部分是按需所用。
告警(监控)类型
- 定义:确定了一部分的告警对象的告警指标采取一类的算法计算
- 示例:单机性能告警(就包含了多个针对于服务器这个对象的监控告警指标,如 cpu使用率、内存使用率、应用程序内容使用量等)
告警规则
- 定义:告警对象+告警指标+告警产生条件+告警通知收敛规则(阈值、发生次数、统计时长等等),应用于告警策略
- 示例:例如对某台交换机创建了,cpu使用率>80时的告警规则
告警策略
- 定义:告警对象+告警类型+告警规则(可多个) 对应一个告警策略
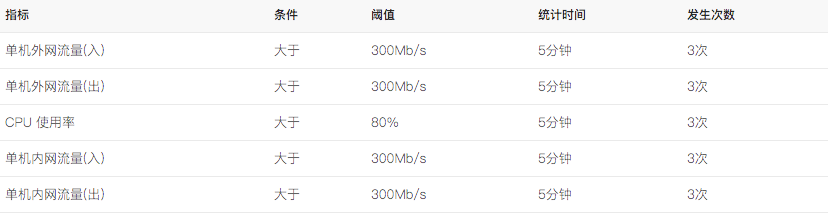
- 示例:对一个三级业务下的全量服务器创建了一条基础告警策略,下图中的每一条都是一个告警规则,
备注:对于告警策略,织云的理念的是对象精简化,为什么会这样说?在实际的生产环境汇中,一个运维同学负责几十个业务是常态,如果这几十个业务对应的不同的告警策略有上百个,在实际的运维过程中其实是不可量化的管理的。 所以告警策略要同时包含不同的告警类型与具备可继承性。
告警
- 定义:告警对象的告警指标满足告警产生条件后产生的对象
- 示例:[腾讯织云] [ping告警] [15:38:10] [Ping 192.192.192.192 不可达]
限于篇幅这里先介绍以上最基础的概念,后续随着讨论的逐步深入,会在介绍告警分级、告警收敛、告警恢复、告警事件、告警订阅、告警合并等概念,下面主要讨论下网络设备监控、网络流量分析与服务器监控这几个业务运维同学们强关注的运维对象。
网络流量
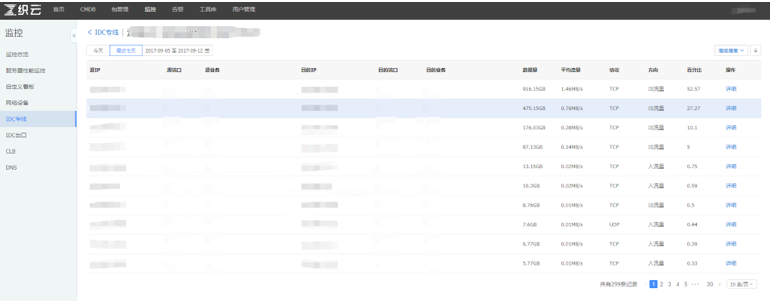
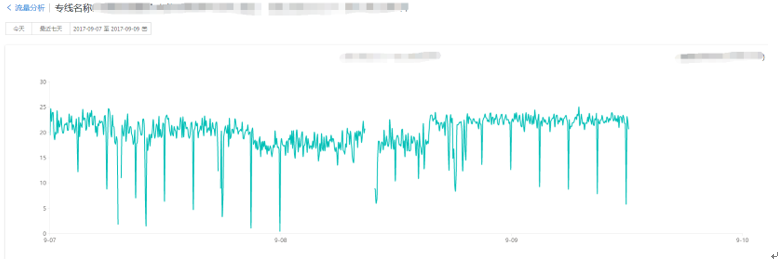
对于网络出口与网络专线的有效监控与分析,即能有效的协助业务运维同学有效的定位业务异常、评估业务服务质量等,也能有效的度量业务整体运营成本,毕竟现在带宽的使用成本在整体运营成本中也是占比越来越大。相信运维同学多少都会遇到下面的场景
- 例如这条专线当前利用率多少?
- 在已经使用的流量中,某个ip使用了多少流量?
- 这些所产生的流量是基于什么协议与方向?
- 专线与网络出口的丢包率与时延是怎么样的?
- 每条专线中主要是哪些务在用?哪个是“”地主客户“”?
等等较高频的使用场景。对于网络流量的监控与分析来说主要依靠的FLOW。
那么什么是FLOW呢?
Flow是一种数据交换方式,其工作原理是:Flow利用标准的交换模式处理数据流的第一个IP包数据,生成Flow 缓存,随后同样的数据基于缓存信息在同一个数据流中进行传输,不再匹配相关的访问控制等策略,Flow缓存同时包含了随后数据流的统计信息。
一个Flow流定义为在一个源IP地址和目的IP地址间传输的单向数据包流,且所有数据包具有共同的传输层源、目的端口号。
相对于会话(“Session”)而言,“Flow”具备更细致的标识特征,在传统的TCP/IP五元组的基础上增加了一些新的域值,至少包括以下几个字段: | 源IP地址 | 目的IP地址 | 源端口 | 目的端口 | IP层协议类型 | ToS服务类型(dscp) | 输入物理端口(ifindex) | 以上七个字段可以唯一地确定任意一个数据包属于哪个特定的Flow,换而言之任何一个字段出现了差异都意味着一个新Flow的发生
对于FLOW的分析展示同样也是要基于多维度的,ip(目的与源)、port(目的与源)、业务、网络架构、城市、IDC等等众多的维度,具体所需的维度依赖于自己的业务场景。
FLOW是厂商的私有协议,业界也有多种的Flow格式。例如CISCO、华为、juniper等等的主流厂商的flow也是均有一定差异性与优劣的,所以这部分的后台能力是需要有异构性的,织云基于腾云复杂的网络运维经验,目前是支持CISCO、华为、juniper 的不同FLOW。
网络设备
对于网络设备的监控,也一般从设备性能、质量、状态等维度入手。对于每台网络设备来说运维同学一般会关注如下场景:
- 网络设备的运行状态Syslog(设备运行日志)的监控与告警
- 设备堆叠状态下的(例如交换机堆叠)的监控与告警
- 网络设备上每个物理端口的、流量、包量、错包与端口状态的监控与告警。
- 网络设备上逻辑端口(物理端口组合)的性能与状态
- ……………
等等高频场景。
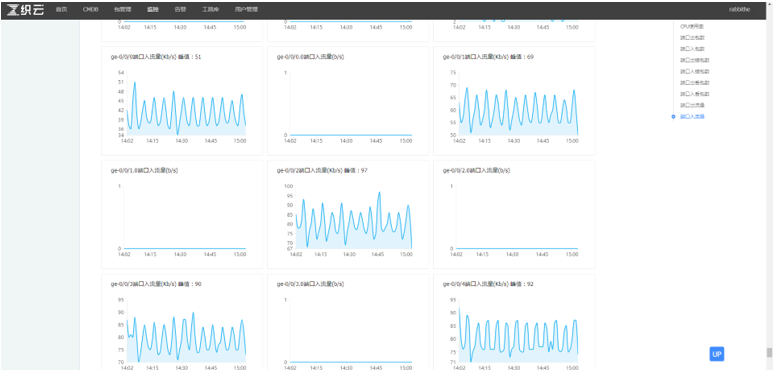
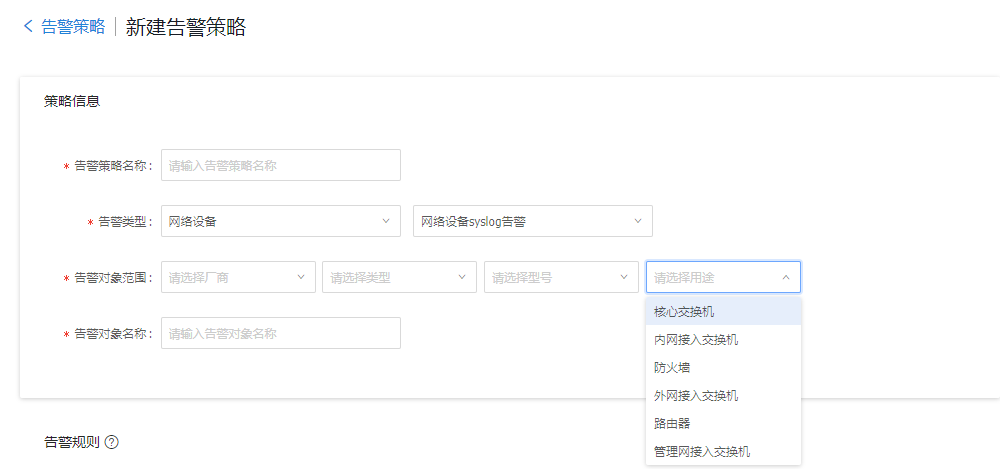
对于网络设备的syslog告警来说,同样也会面临不同的厂商、设备类型与设备型号日志标准不统一,所以对于网络设备syslog监控告警来说,首先是将众多的网络设备进行逻辑分组,以便于在一个分组内的设备均可以响应同一个告警关键字,并且这个分组粒度建议较细,这样才能保障告警关键字的有效性与独立性。在这里根据多年的运维经验,建议syslog告警的分组模型由四个维度组成厂商+类型+型号+用途,例如 CISCO+交换机+EX43000-24T+内网接入层交换机,通过这个公式就描述出一个设备的逻辑分组。
服务器
对于服务器的监控同样也是从状态、性能与容量这几个维度入手。虽然SNMP也可以用于服务器监控,但相对于agent主动上报指标与数据会少很多。服务器的状态监控主要包含 服务器是否ping的通、agent上报是否超时与电源运行状态等等。对于性能与容量这两类维度,主要依赖当前OS的数据捕获,一般来说对于服务器监控来说在通用场景下主要关注cpu、内存、流量与包量这四个指标即可,但是别的指标也建议尽量捕获。 单个监控对象的数据丰富了会有如下好处。
- 避免对象的监控盲点
- 不同的监控数据点可以部分对应出该服务器所承载的业务特性指标,例如存储类业务也会关注 disk_total_read、svctm_time_max、await_time_max等等系统指标
- 生产的数据足够丰富能够催生出更加丰富的运维数据消费场景。
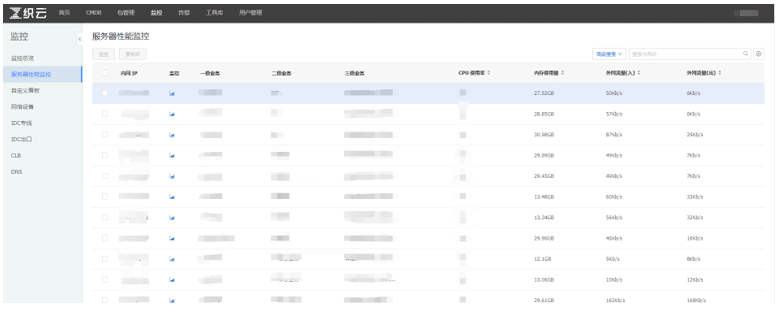
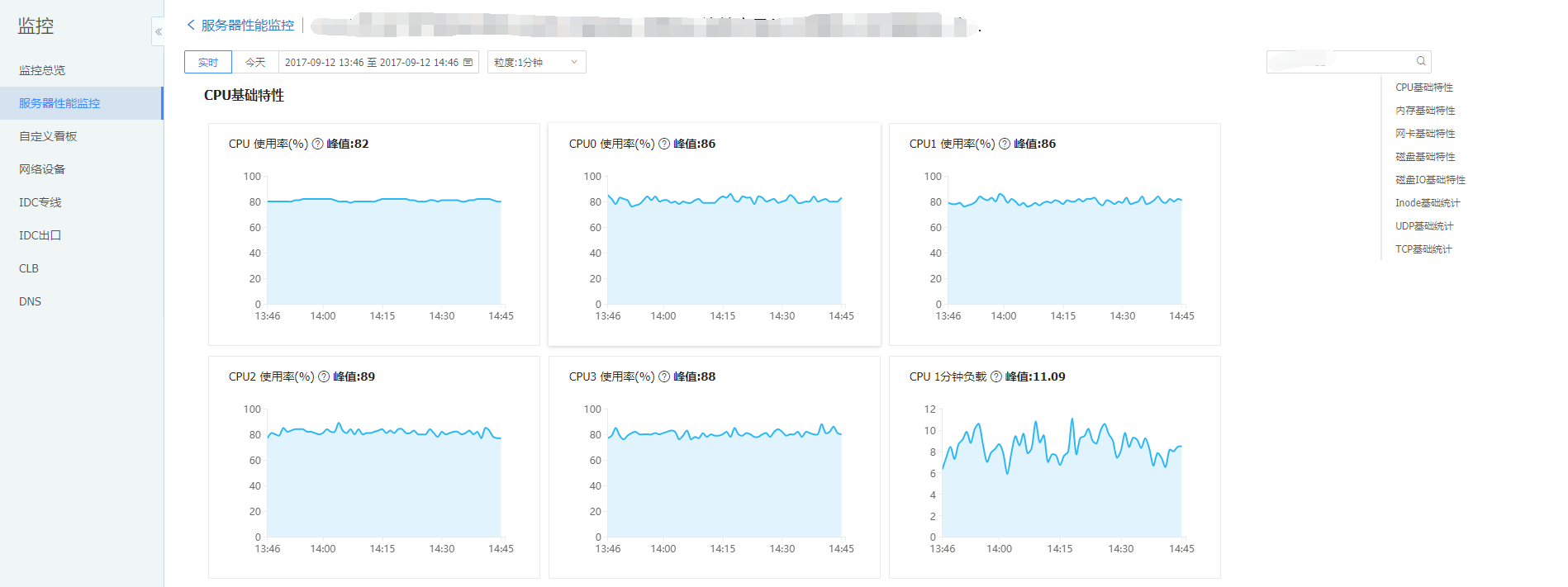
服务器监控相对是很标准的监控模型,针对于物理服务器与虚拟机都有共性指标。这部分主要做到采集的数据丰富与上报的准确性(算法准确)。
后续文章主题预告
- 数据银行CMDB的建设
- 形态各异的公有云组件通用监控模型建设之路
总结
IAAS层的监控从IAAS层的组成这个维度来说,可以分为一个个独立的资源对象来分类监控,针对每一类对象可以分别从状态、性能、容量、质量这几个维度描述,将不同的数据综合为开发与运维的统一视角。监控告警产品的建设是任重而道远的过程,坑也非常多。要考虑多种因素,技术后台能力只是其中的一部分。例如在DevOps的文化下,需要从更高的层面来统一视角(开发视角&运维视角)避免将监控做成”开发的监控”与”运维的监控”。也需要更多的考虑监控产品使用的双态(用户态&系统态)与不同的权限(行业属性)如何分类设计。
相关阅读
本文由 @李光 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议









为啥不更新了。。哭泣
大厂监控新人产品来报道了😹😹
点个赞
图表怎么制作的呢
阅读量少正常,毕竟做监控的产品少,求作者继续写
你做过监控这块吗?可以加个好友交流一下
没做过,但是预感即将要做,补充下知识
作者你2018年一整年都哪去了?很期待你的文章啊!!!
希望作者赶紧更新啊
为什么没再更新呢?很适合监控产品小白入门看!