
 起点课堂会员权益
起点课堂会员权益以 Facebook 的 wit.ai 为例,讲解机器人对话平台(Bot Framework)

本篇文章将会从理解和对话两个方面去讲解 wit.ai。enjoy~
什么是 Bot Framework ?
按照微软的讲法:”The Bot Framework is a platform for building, connecting, testing, and deploying powerful and intelligent bots.” 简单的说,Bot Framework 就是一个用于搭建、链接、测试、和部署智能机器人的平台。
什么是 wit.ai?
Wit.ai 是 Facebook 推出的用于将自然语言转化为可处理指令的 API 平台,其目的是为了帮助开发者便捷的打造类 Siri 语音对话应用或设备。
为什么是 wit.ai?
前些日子,云栖大会上,阿里的资深技术专家海青在介绍阿里 ALIME 团队的 Bot Framework 时提到了 Google 的 api.ai 和 Facebook 的 wit.ai,所以我希望了解一下,对于我在做业务时遇到的问题、有过的想法,国外一线大厂是怎样处理的。
为什么不是 api.ai?
因为页面打不开…
本篇文章将会从理解和对话两个方面去讲解 wit.ai,主要参考资料为 wit.ai 的英文原版文档: https://wit.ai/docs/recipes 。
一、理解
1、意图(话题)识别
(1)问题
我们需要对用户的意图进行区分,但问题在于用户表达同一意图的说法可能是无限的。
(2)方案
(注:如果看不清下图,可以点击放大来看)
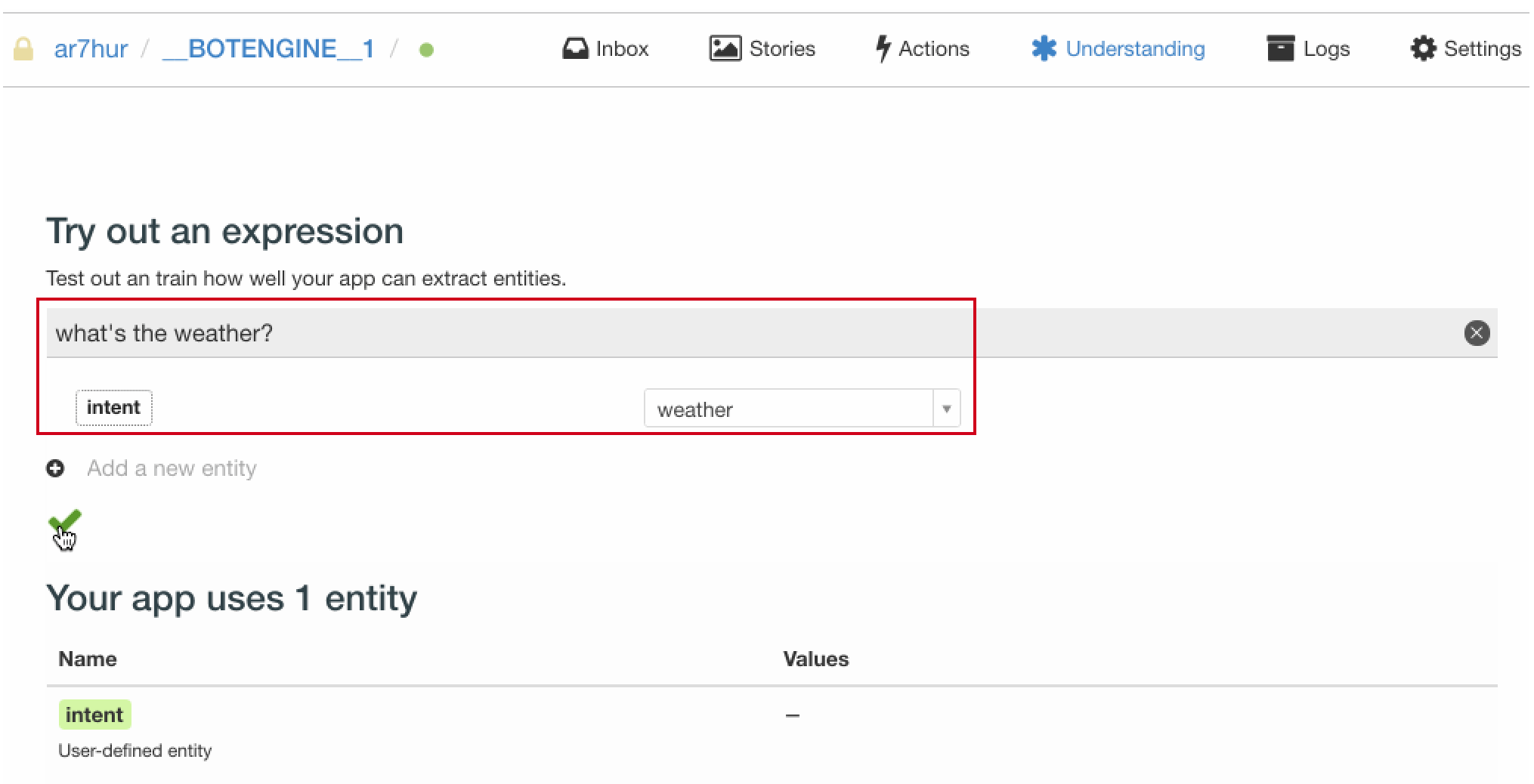
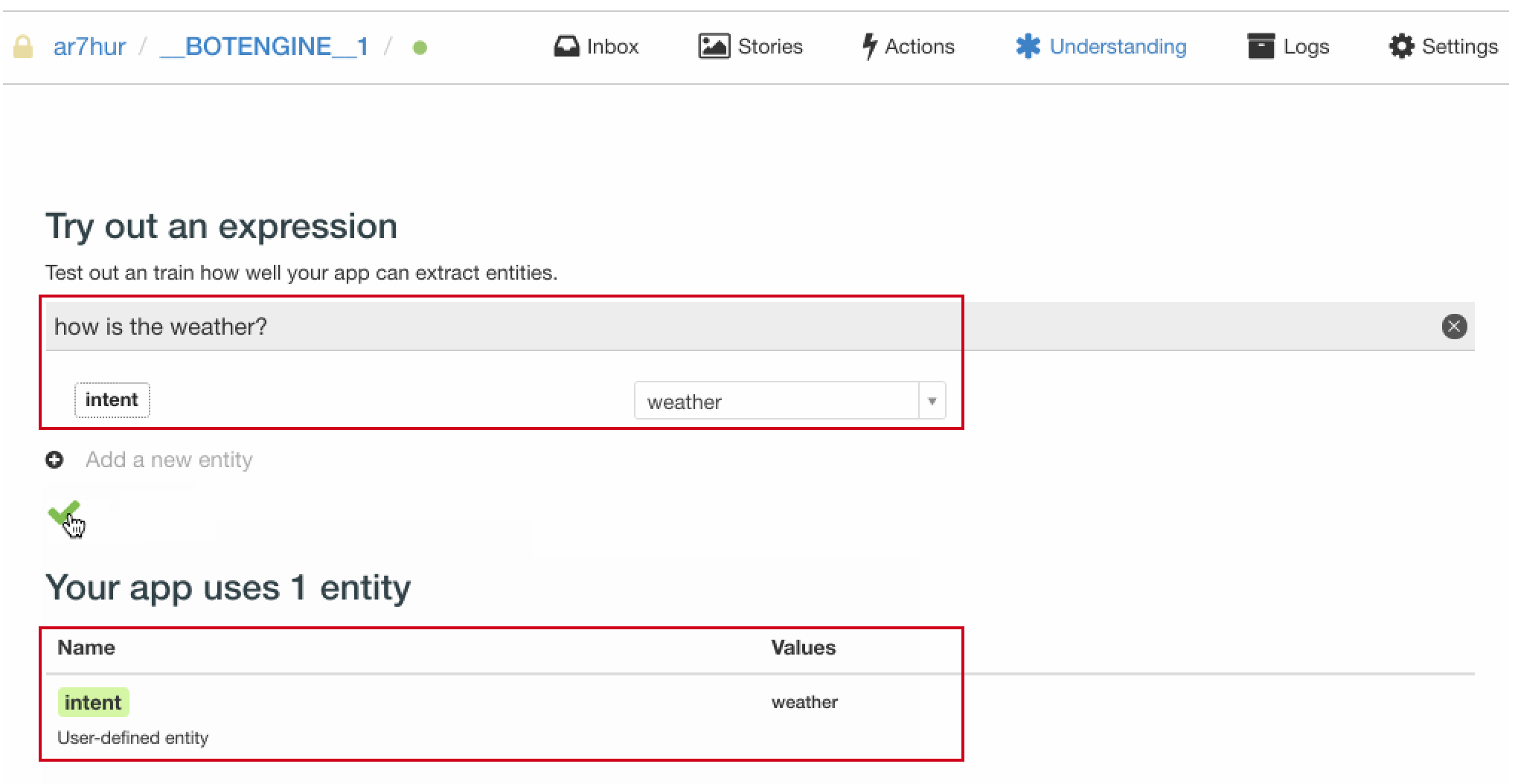
我们在 Wit.ai 的 Understanding 模块,输入一条用户问句 “what’s the weather”,然后选择添加一个叫做 intent(也即意图)的 entity(也即实体),将其意图值置为 weather,也即我们完成了对该条用户问句的意图标注。
我们为此意图标注的用户问句越多,该意图实体的抽取也就越准确。
2、实体抽取(填槽)
(1)问题
我们希望能够从用户的原始问句中抽出我们需要的关键信息。
(2)方案
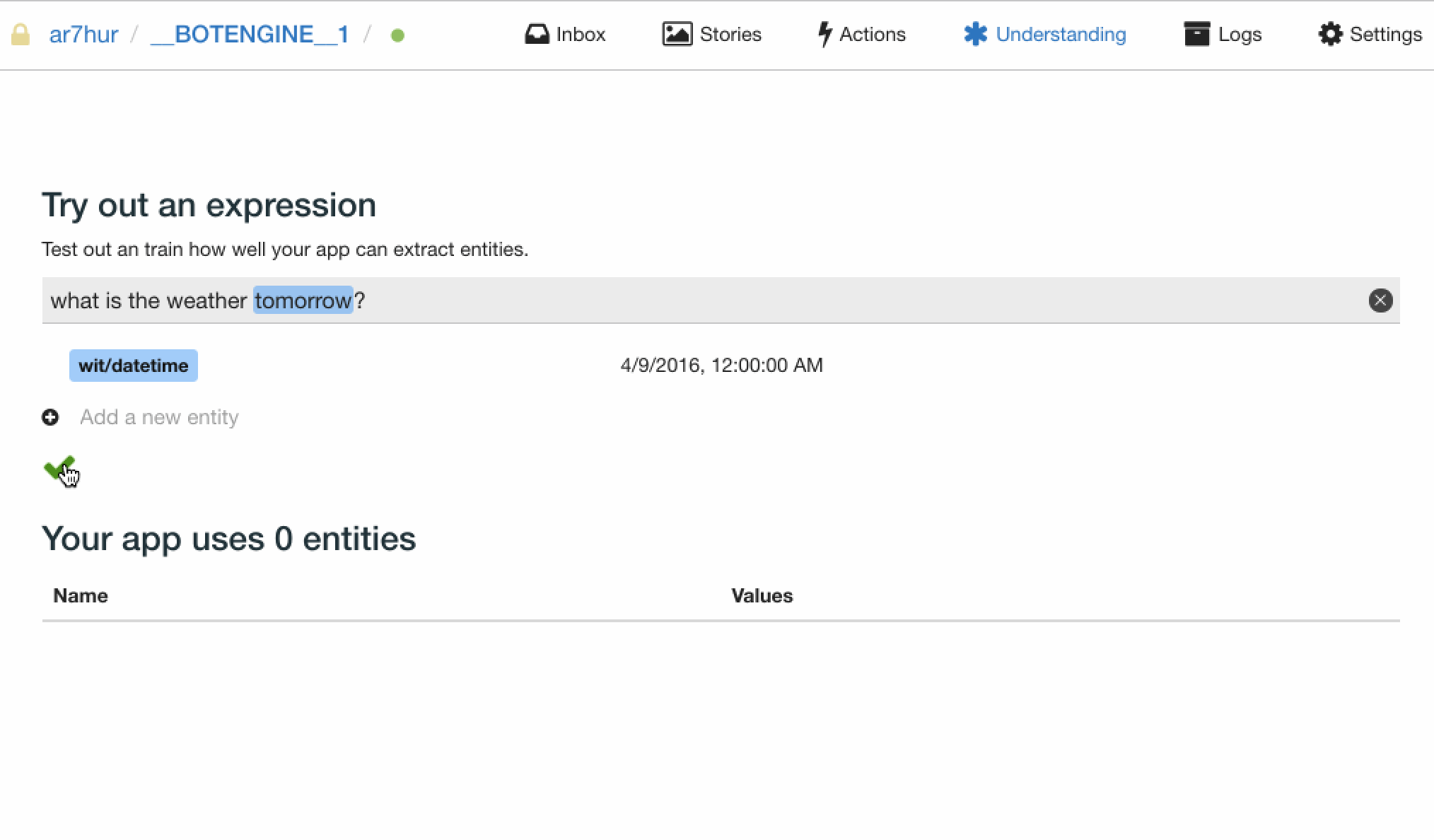
我们输入一条用户问句 “what is the weather tomorrow”,然后选择添加实体,可以看到 wit/datetime 这个系统内置的实体,选中之后,可以发现这个实体自动识别了句子中的 tomorrow,并自动填写好了值。
wit.ai 内置了一些常用实体,这些内置实体不必通过用户的标注就能够完成实体识别。不过具体的业务场景下,我们还会用到一些自定义实体。如果需要 wit.ai 完成这些自定义实体的识别,就需要进行适当的用户问句标注。
3、有限关键词实体抽取
(1)问题
有些情况下,我们希望抽取的实体值是可枚举的,也即我们能够处理的实体值是一个有限的词典。
(2)方案
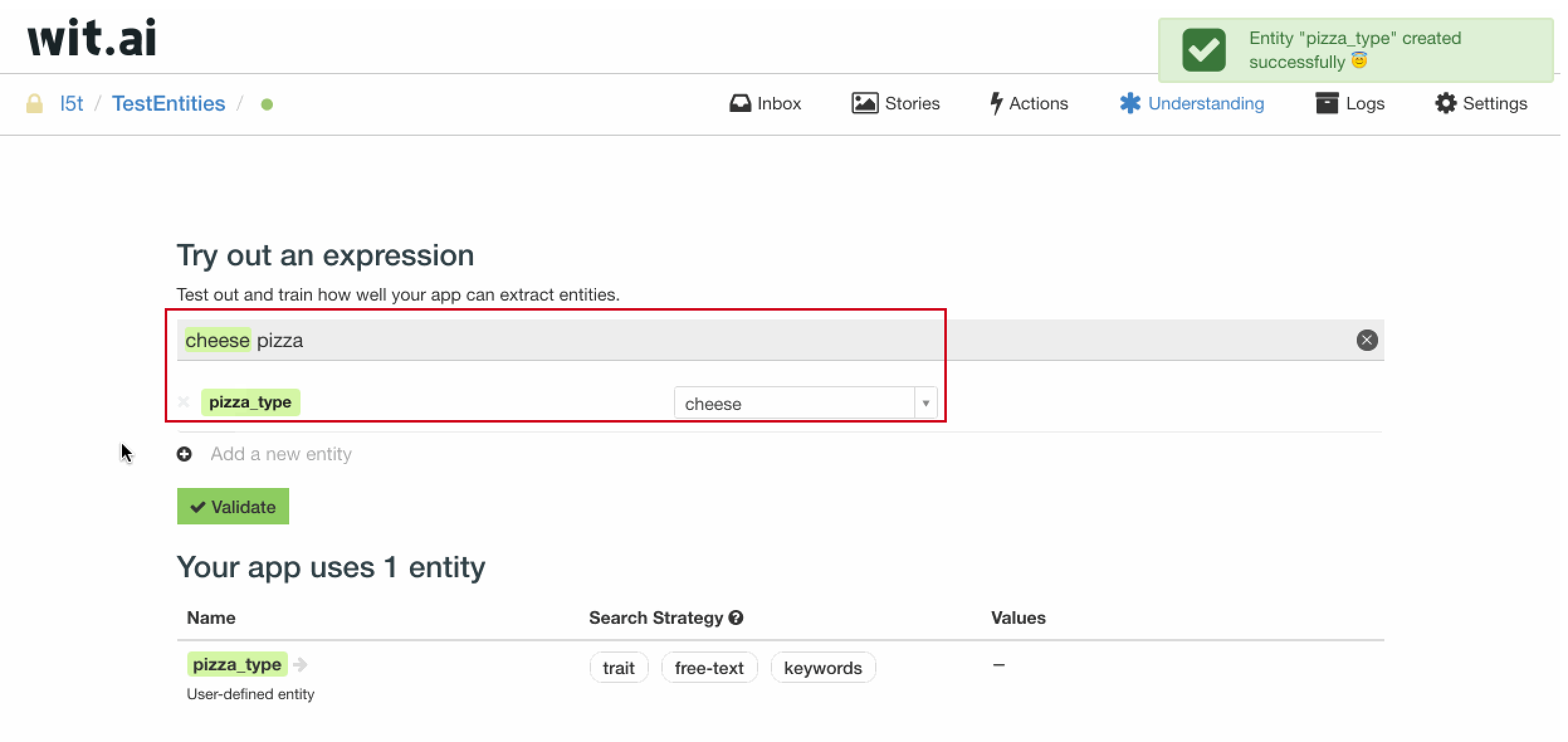
举个例子,在这里,我们自定义一个名为 pizza_type 的实体,并将用户问句 cheese pizza 中的 cheese 标注为 pizza_type 的实体值。
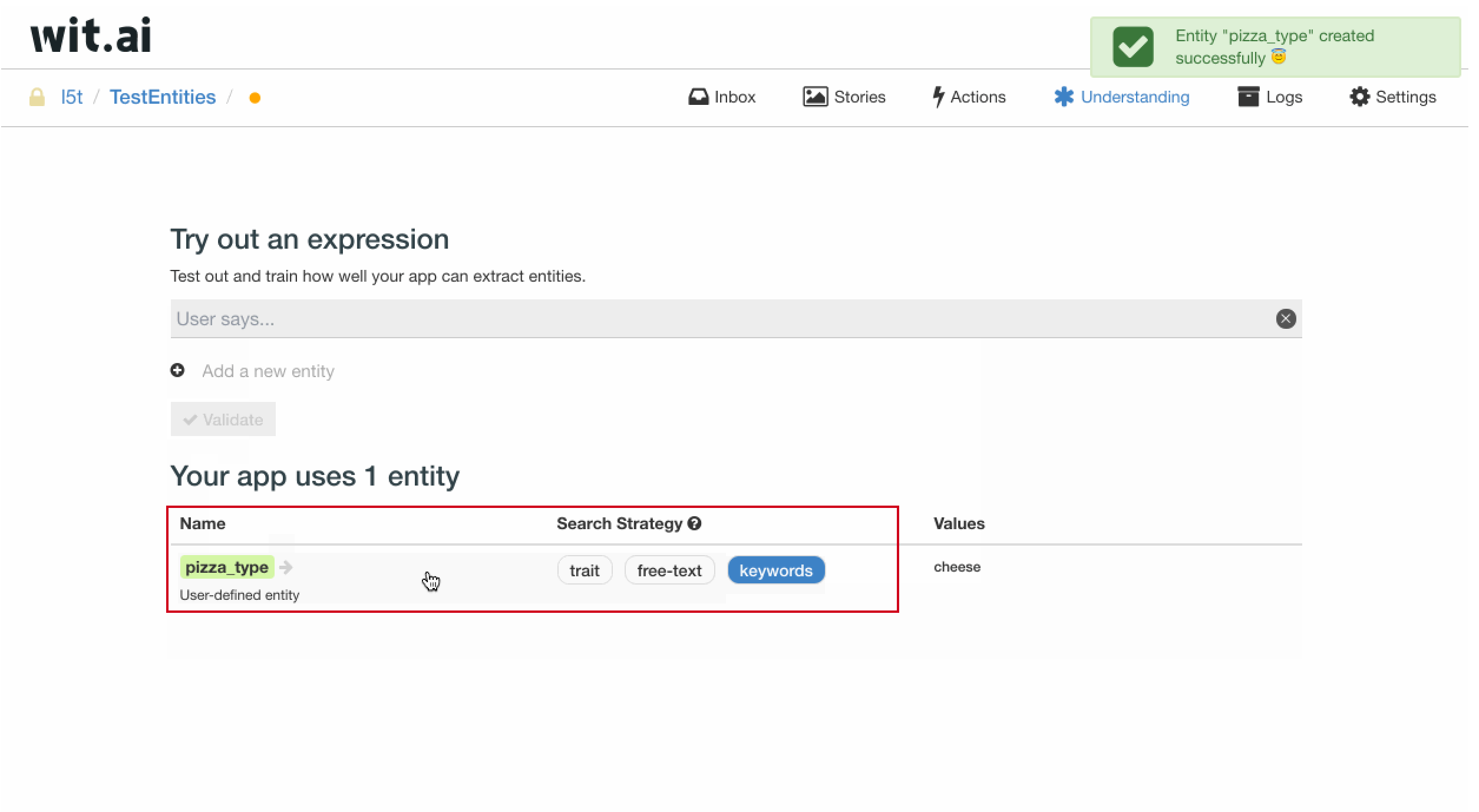
在下方的实体栏目中,我们可以看到 pizza_type 这个实体,将它的搜索策略选为 keywords,也即关键词,之后,便得到了一个可以识别 pizza 前 cheese 的实体 pizza_type。
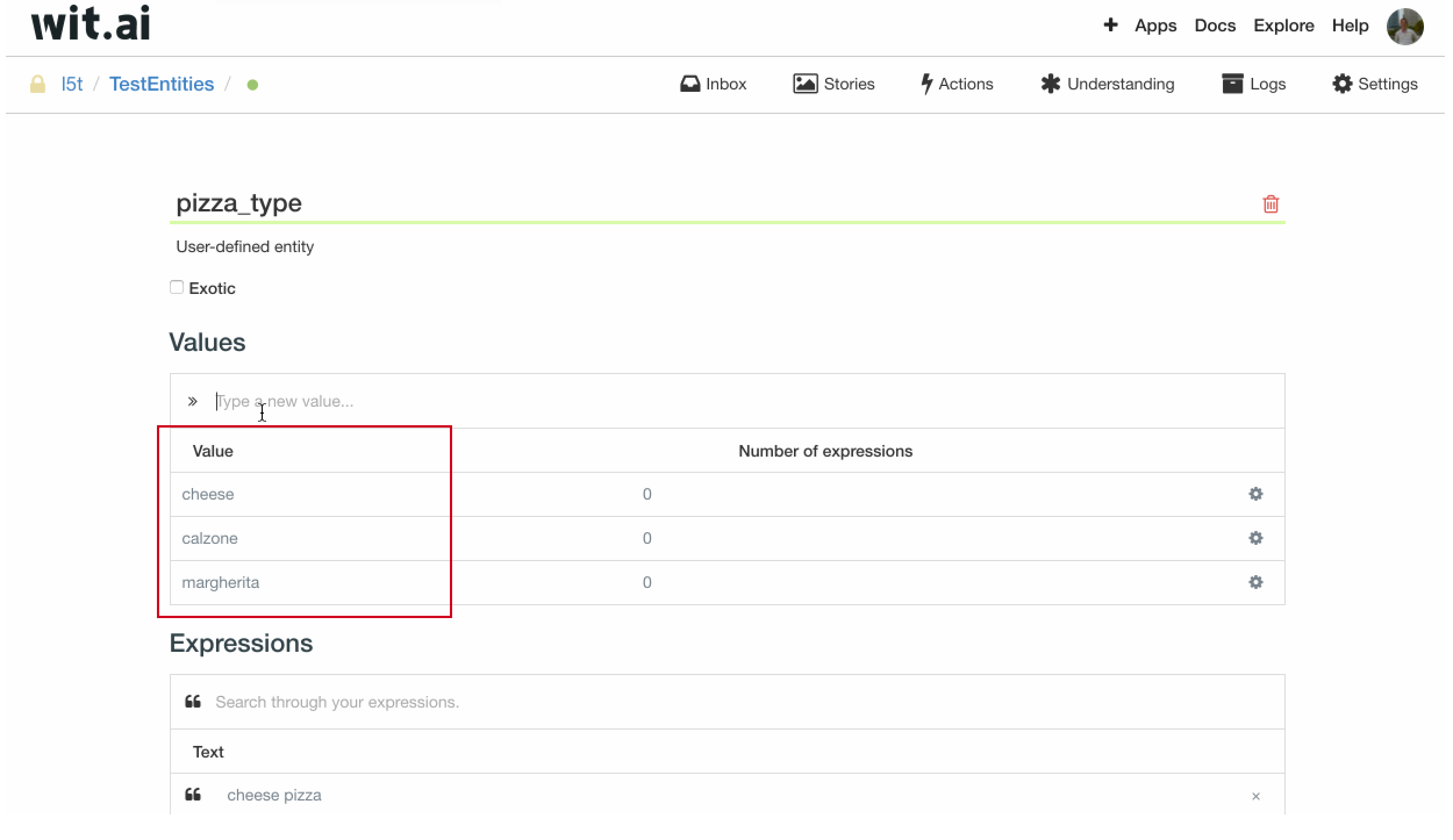
我们当然不止希望 pizza_type 只识别 cheese,可以通过图示的方式为这个实体增加可识别的 pizza_type 实体值,添加完成后,可以尝试在 expression 中输入 [新的实体值] + pizza,发现我们新增的 pizza_type 实体值,是可以被自动识别的。不过,识别范围也仅限于我们在 pizza_type 中添加的 keywords。
4、非有限关键词实体抽取
(1)问题
很多情况下,我们也希望能对有限词典之外的词进行识别,比如上例中的 pizza_type,当然,我们能处理的只有配置好的 pizza_type 实体值,但并不意味着当用户需要其他类型的 pizza 时,我们就无法作答。
(2)方案
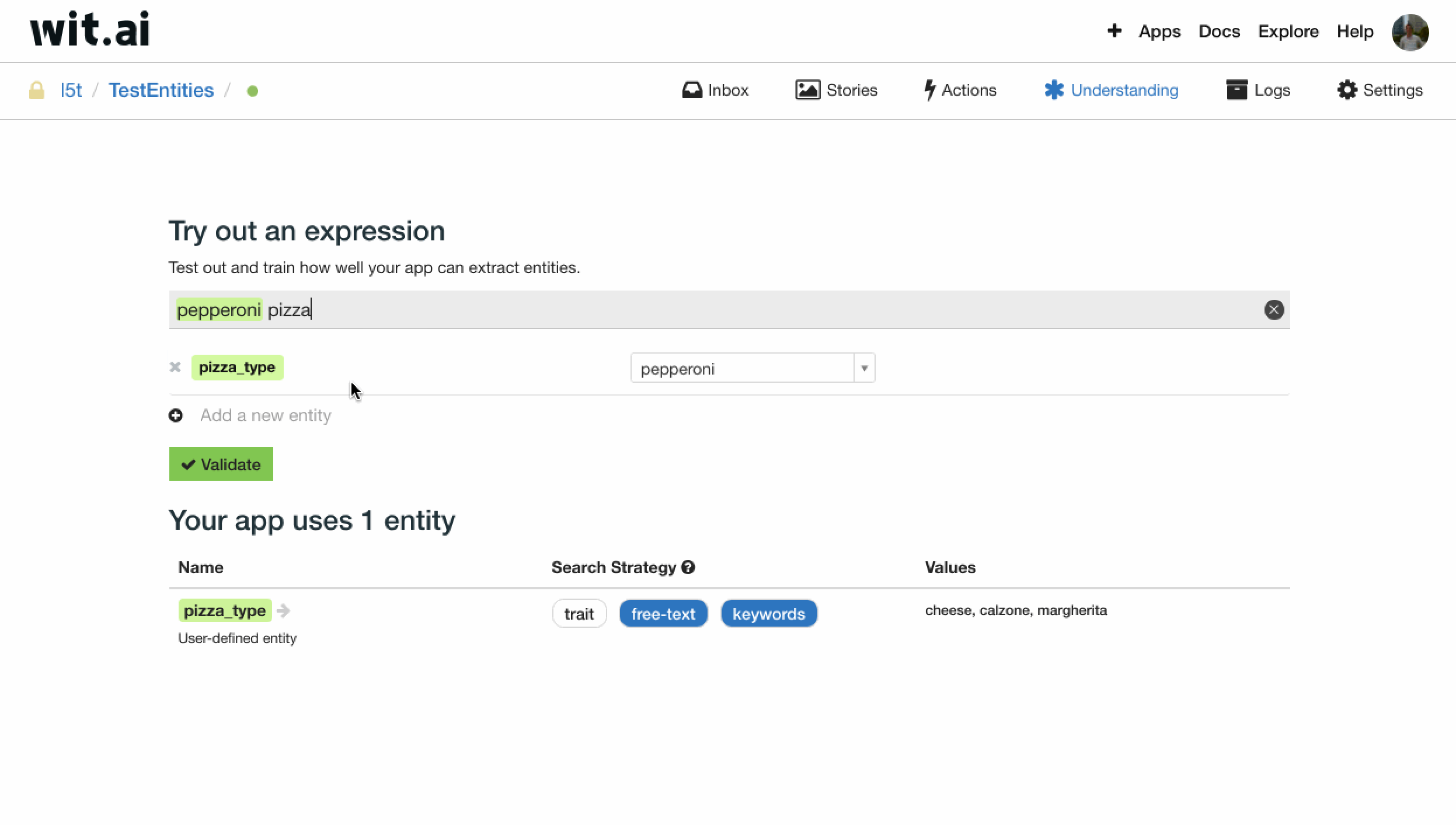
如图所示,我们修改 pizza_type 的搜索策略为 free-text + keywords,这意味着,当用户在 pizza 前使用词典内 keywords 之外的词时,也能够被识别。也即我们可以得知用户选择了其他类型的 pizza。
5、子串实体抽取
(1)问题
在一些业务场景下,我们需要抽取用户问句中的一个子串作为实体值,比如 “Tell Jordan that I will be home in ten minutes” 句中的 “I will be home in ten minutes” 就是我们需要抽取的实体值。
(2)方案
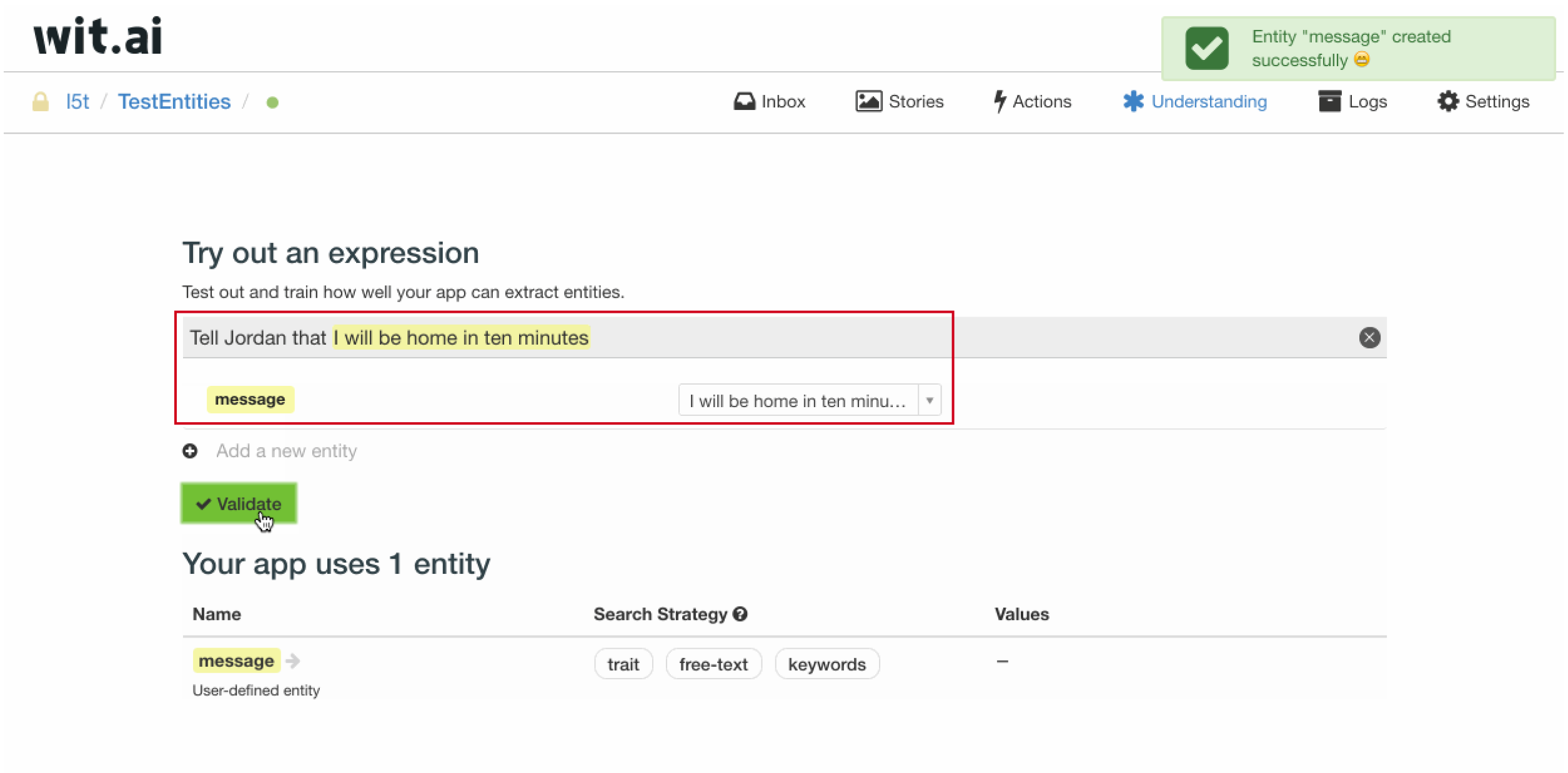
我们可以在 expression 中输入 “Tell Jordan that I will be home in ten minutes”,随后新增一个 message 实体,然后将 “I will be home in ten minutes” 作为 message 实体的标注结果。之后将 message 的搜索策略选为 free-text + keywords,message 实体就具有了从用户问句中抽取 message 子串的能力。
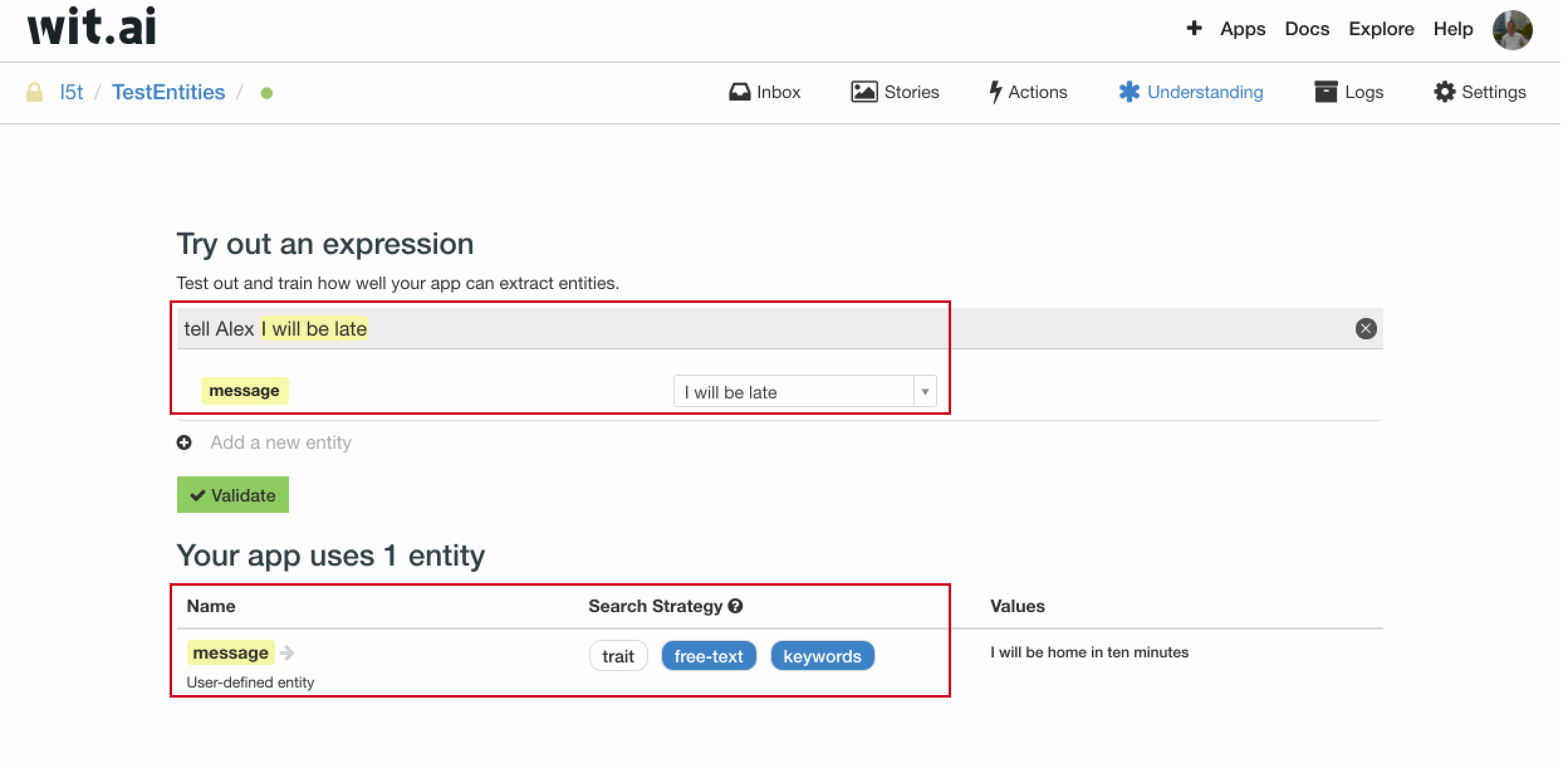
如图所示,尝试输入 “tell Alex I will be late” 后,wit.ai 也能将其中的 “I will be late” 抽取到 message 中。
6、搜索策略选择
在上面的例子中,我们可以看到,实体的搜索策略有三种可选,分别是 trait、free-text 和 keywords。它们的区别在于:
- trait 策略不会尝试去抽取用户问句中的某个词或是某个短语,而是会将整个句子作为一个整体来理解,比如意图、情感等,通过分析整个用户问句来得到实体值。
- free-text 策略被用来抽取用户问句中的子串,这些子串通常不会包含在预定义的实体值词典中。
- keywords 策略用于处理需要抽取的实体值可枚举的情况,我们为实体准备好一个预定义的实体值词典,该实体的抽取就通过使用实体值词典做匹配来完成。
7、区分不同位置的同类实体
(1)问题
在一些经典的场景(比如订票)中,按照上文的定义,实体的抽取确实应该使用 keywords 策略,但如果同一条用户问句中需要抽取多个同类实体呢?建立起同类实体与多个词典内实体值之间的对应关系就成了需要解决的问题。
(2)方案
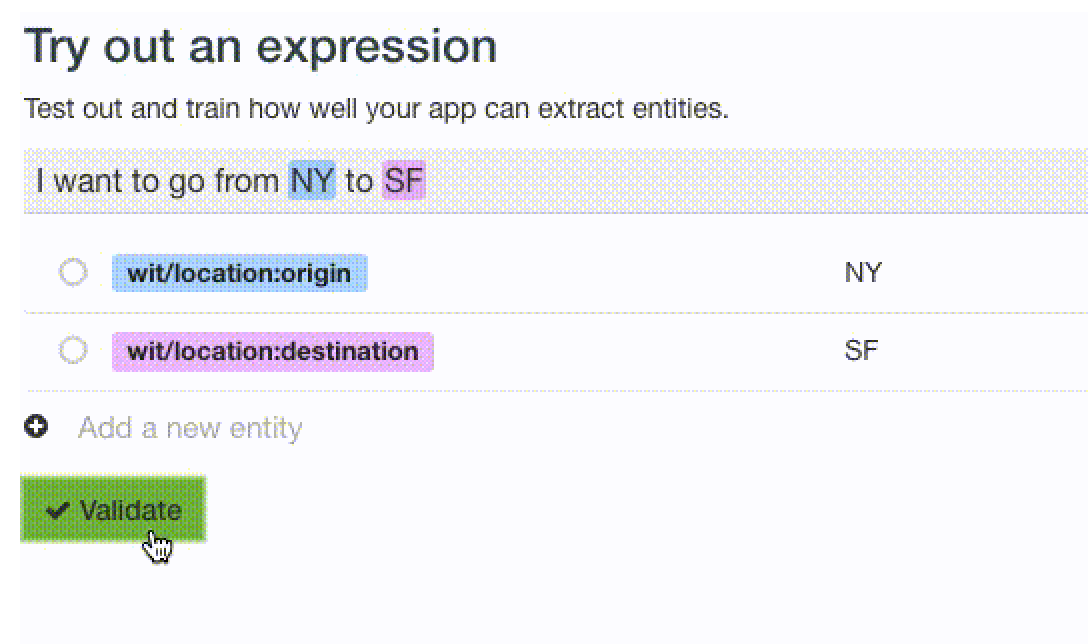
wit.ai 中通过设定 role 来解决这个问题。
举个例子,expression 为 “I want go from NY to SF”,其中 NY 和 SF 均为 wit/location 实体中的值。在这样的业务场景下,我们需要同时抽取出两个 wit/location 实体,值分别为 NY 和 SF,并且区分好 NY 是出发点,而 SF 是目的地。
我们在选择实体时,设置抽取 NY 的 wit/location 实体的 role 为 origin,抽取 SF 的 wit/location 实体的 role 为 destination。
8、情感分析
(1)问题
我们想要知道用户问句中的情感,是积极或消极。
(2)方案
可以按照上文中的方法进行 expression 的标注,区别在于,需要新增一个 sentiment 的 实体,将它的搜索策略选为 trait,值标注为为 positive 或 negative。
9、置信度下限选择
(1)问题
对于每个抽取出的实体,wit.ai 都会提供一个置信度,当置信度足够低时,或许我们应当采用特殊的处理方式,比如进行确认或直接丢弃。
但如何定义置信度的『足够低』呢?
(2)方案
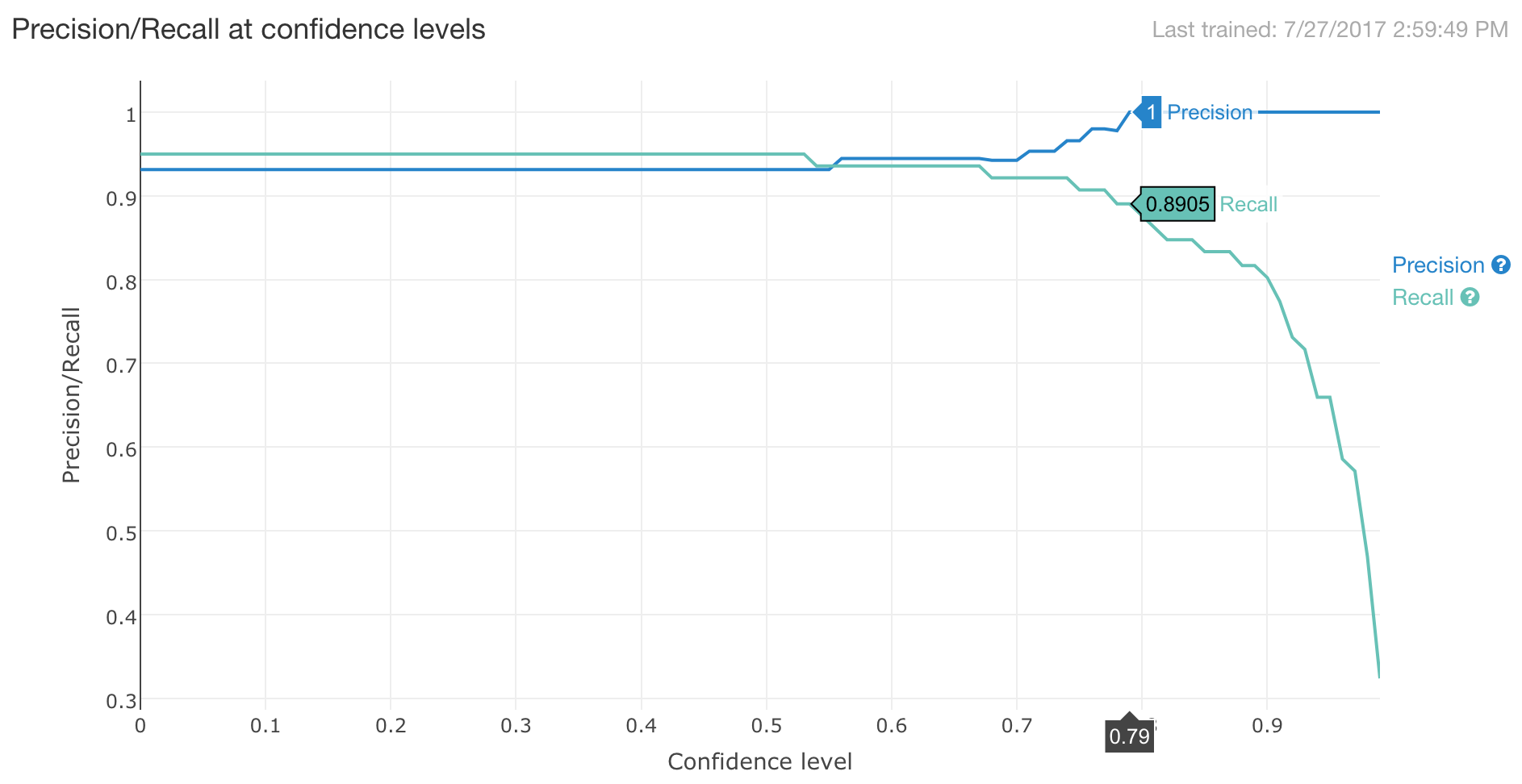
在实体页的 Insights 模块,我们能够看到该实体抽取的置信度与准确率和召回率的关系,选择不同的置信度能够得到相对应的准确率和召回率。
如上图,如果我们需要当准确率未达到1时进行特殊处理,那么我们就应该选取置信度为0.79,然后对置信度低于0.79的实体抽取情况进行特殊处理。
小结
由此看来:
- 规则未必都需要对应一个 intent,同一条规则在不同场景下应该会存在共用关系。
- 规则的使用是自始至终的,从识别 intent 到后续的对话过程。
- 规则应当有抽取非可枚举值,也即子串的能力。
- intent 与通常意义的槽可以看做是平级的实体,只是搜索策略不同。
- 规则应当分为共用和非共用,不同业务方应当使用不同的规则域。因为同一位置的同一个词可能会被不同规则抽取到不同的实体中,不同业务方之间不应相互影响,同一业务方在编写规则时也应当注意通用性。
- 规则应当有能力根据位置/角色识别同类实体。
- 相似问句语料的提供可以通过与规则编写相同的方式进行,搜索策略采用 trait 即可。
- 模型的训练是实时的且不可见的,通过 expression 可以即时验证结果。
还不了解的是:
- 如果一次标注中抽取了多个实体,那么在用户问句不完整的情况下,能否将原标注结果中全部实体的一个子集抽取出来。也即抽取的粒度,是一个实体,还是一次完整的标注?推测为一个实体,但当出现冲突时,与完整标注更接近的应当拥有更高的优先级。
二、对话
1、实体的抽取与使用
(1)问题
当用户讲 “Where can I see Pulp Fiction?” 时,我们也许会需要将 Pulp Fiction 抽出来,去调用 Movie API,并将它保存在 context 中以供后续机器人时回答使用。
(2)方案
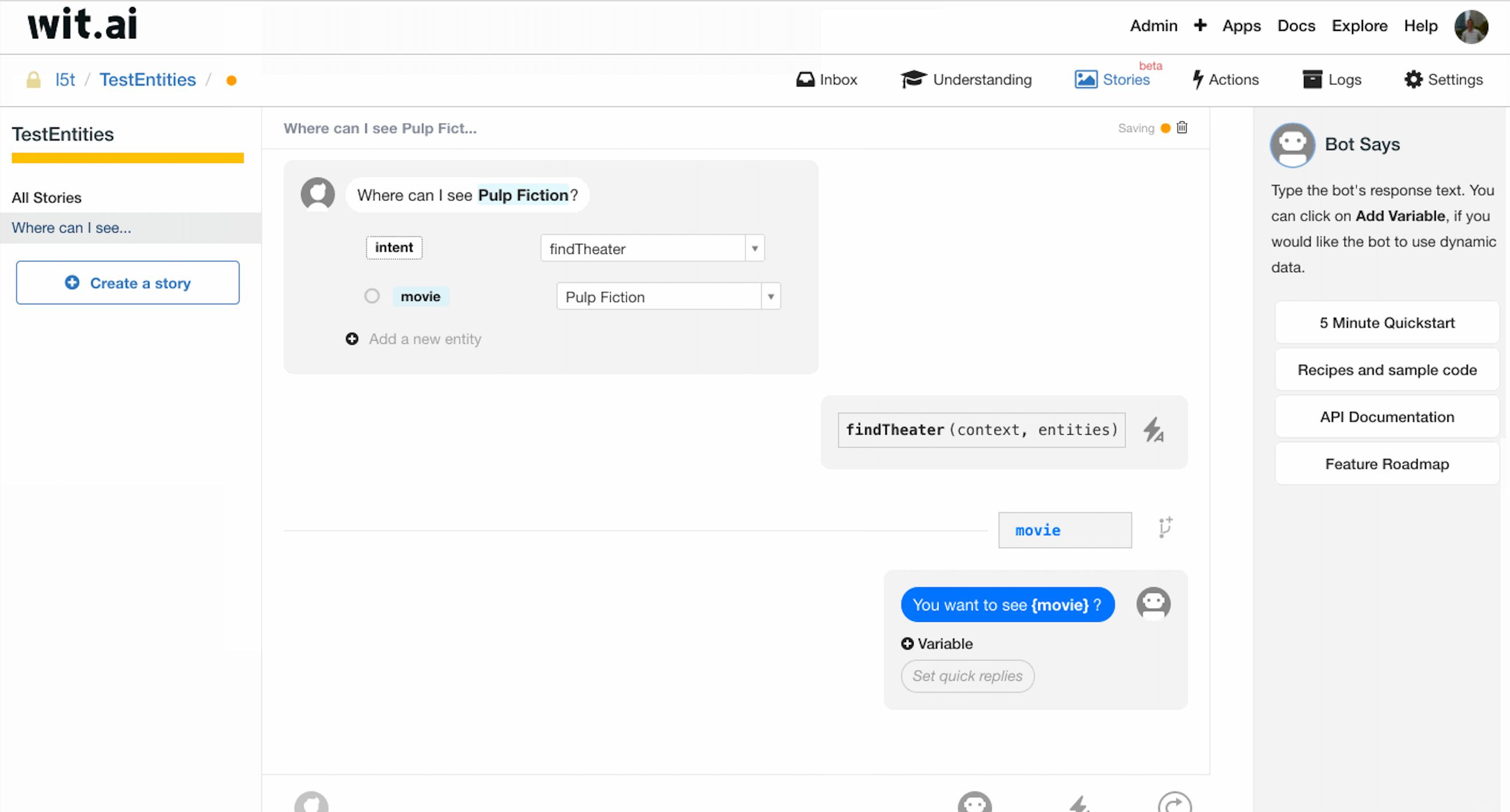
如图所示,我们先输入用户问句,随后标注问句的实体抽取方式:标注 intent 为 findTheater,以及标注好需要使用的其他实体。
随后采用 Bot executes 调用 findTheater 函数,findTheater 以原 context 和抽取出的 entity 作为输入,对 context 进行编辑,通过 add a context branch 可以对 findTheater 的输出进行处理。
之后利用 context-key 拿到 movie 实体的实体值,使用 {} 在 bot sends 中引用。
2、基于槽的机器人(slot-based bot)
(1)问题
在大多数业务场景下,明确用户指令所需的实体都不止一个,只有当用户提供完整的实体信息之后,才能进行指令的执行;而信息不全时,就应当根据实体的缺失情况进行追问。
(2)方案
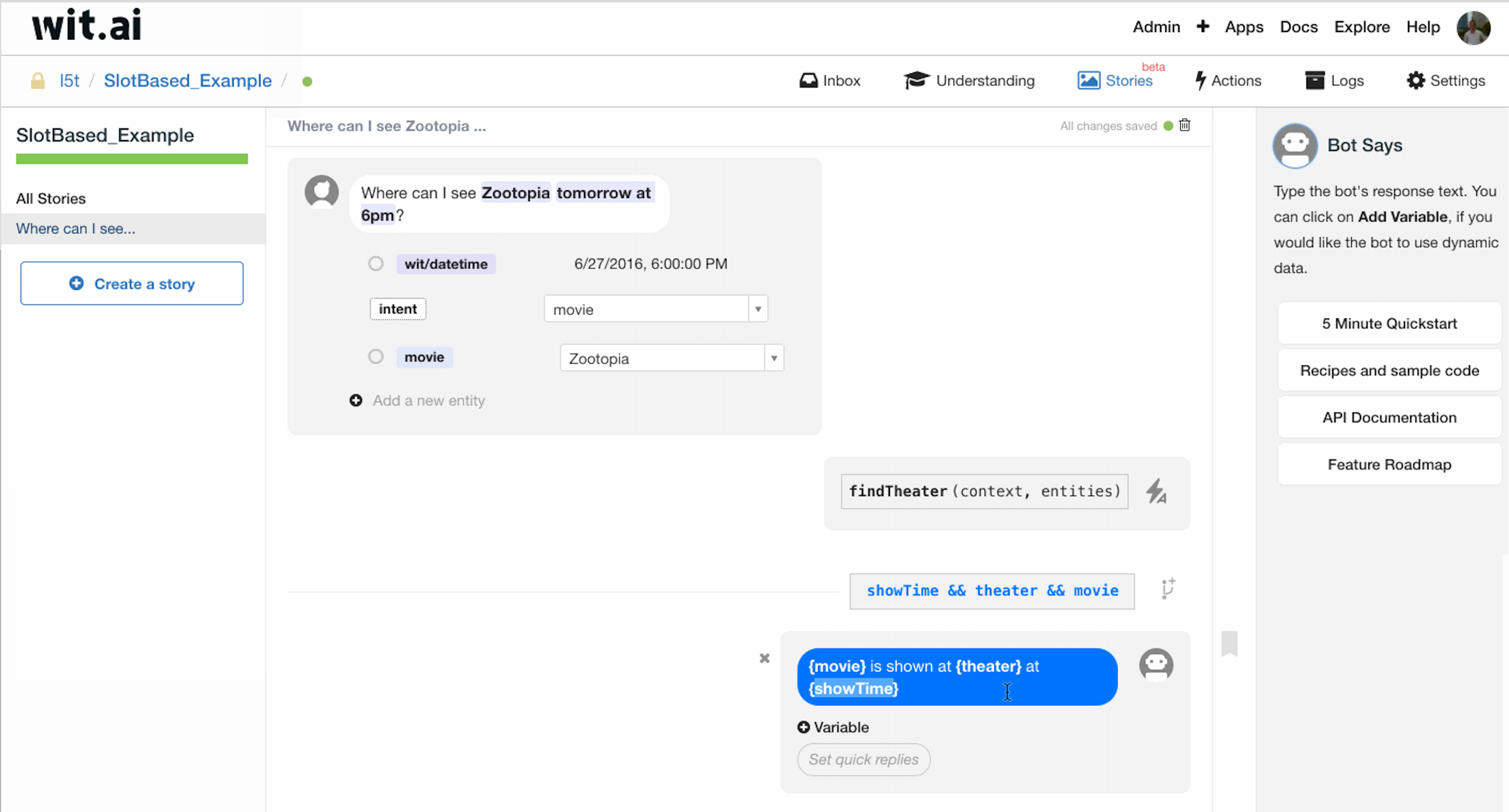
既然存在多种情况,我们就应当分多条分支进行处理。
首先我们处理信息完整的情况,如图所示,我们按照上文讲过的方式利用 context-key 同时拿到 showTime、theater、movie,然后将其拼装成 Bot sends.
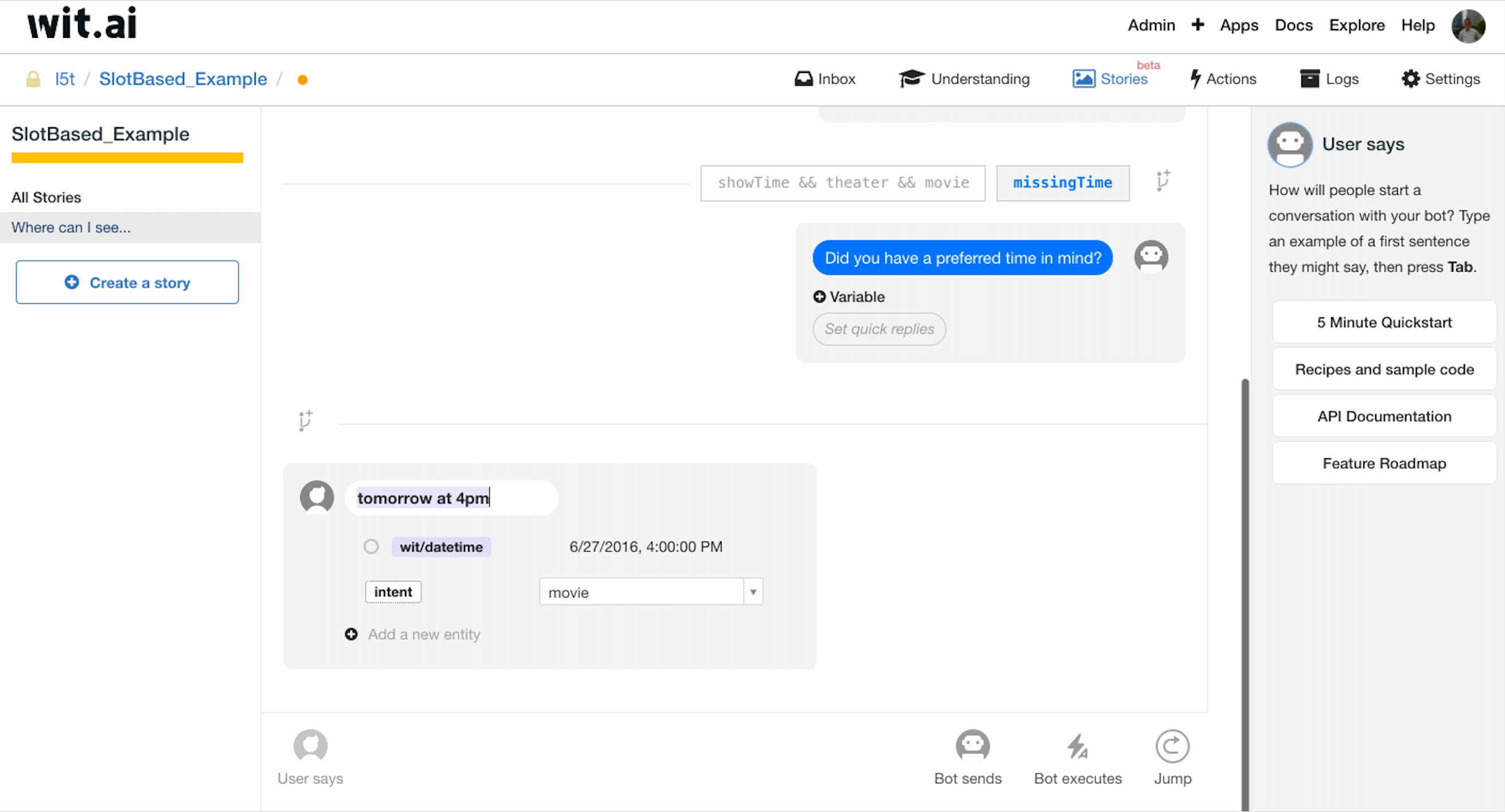
当用户问句中缺失时间实体时,findTheater 函数应当返回 missingTime,由此新建一个多轮对话分支,该分支下,Bot sends 会追问用户,系统用户补全时间实体。
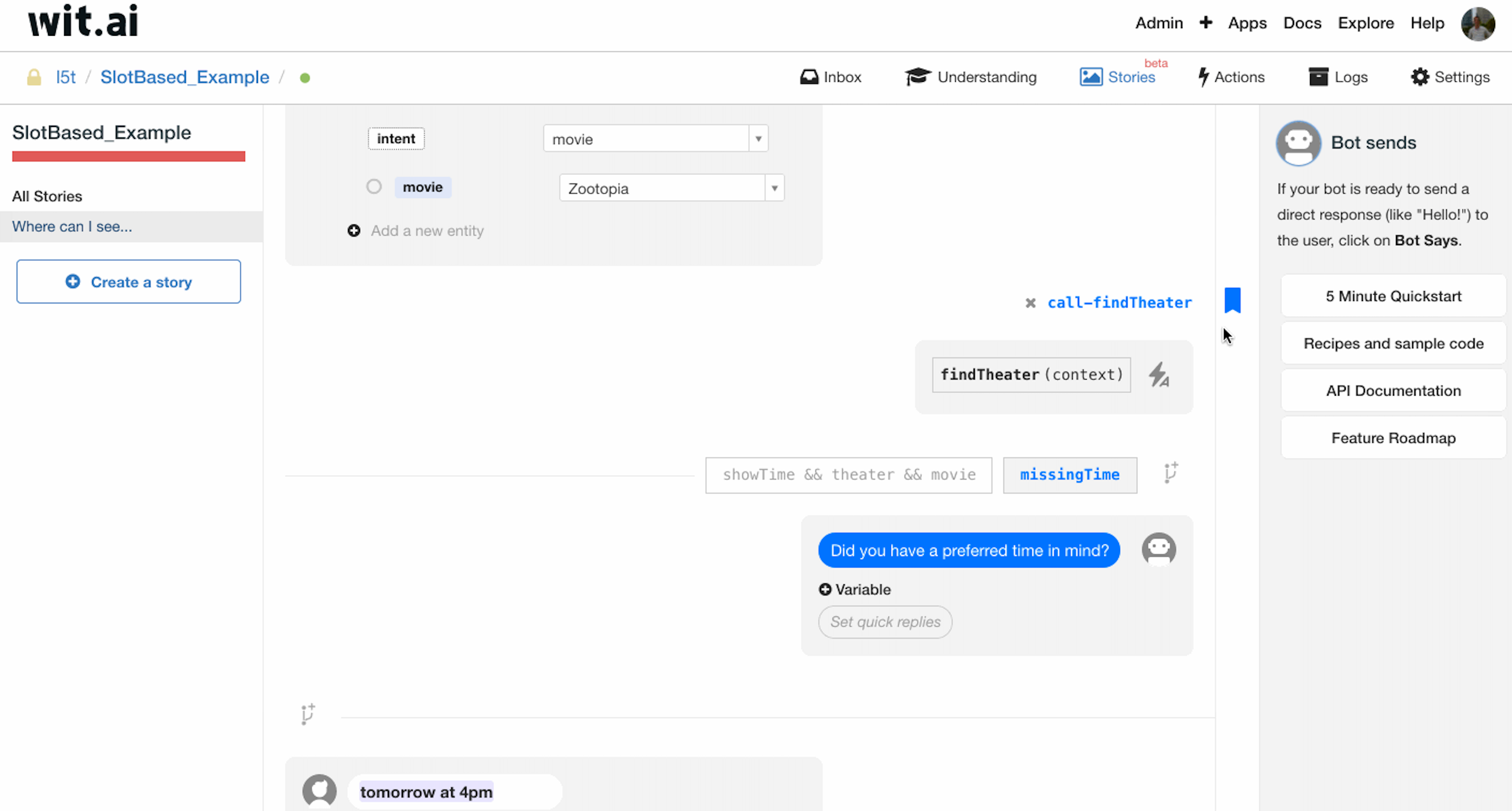
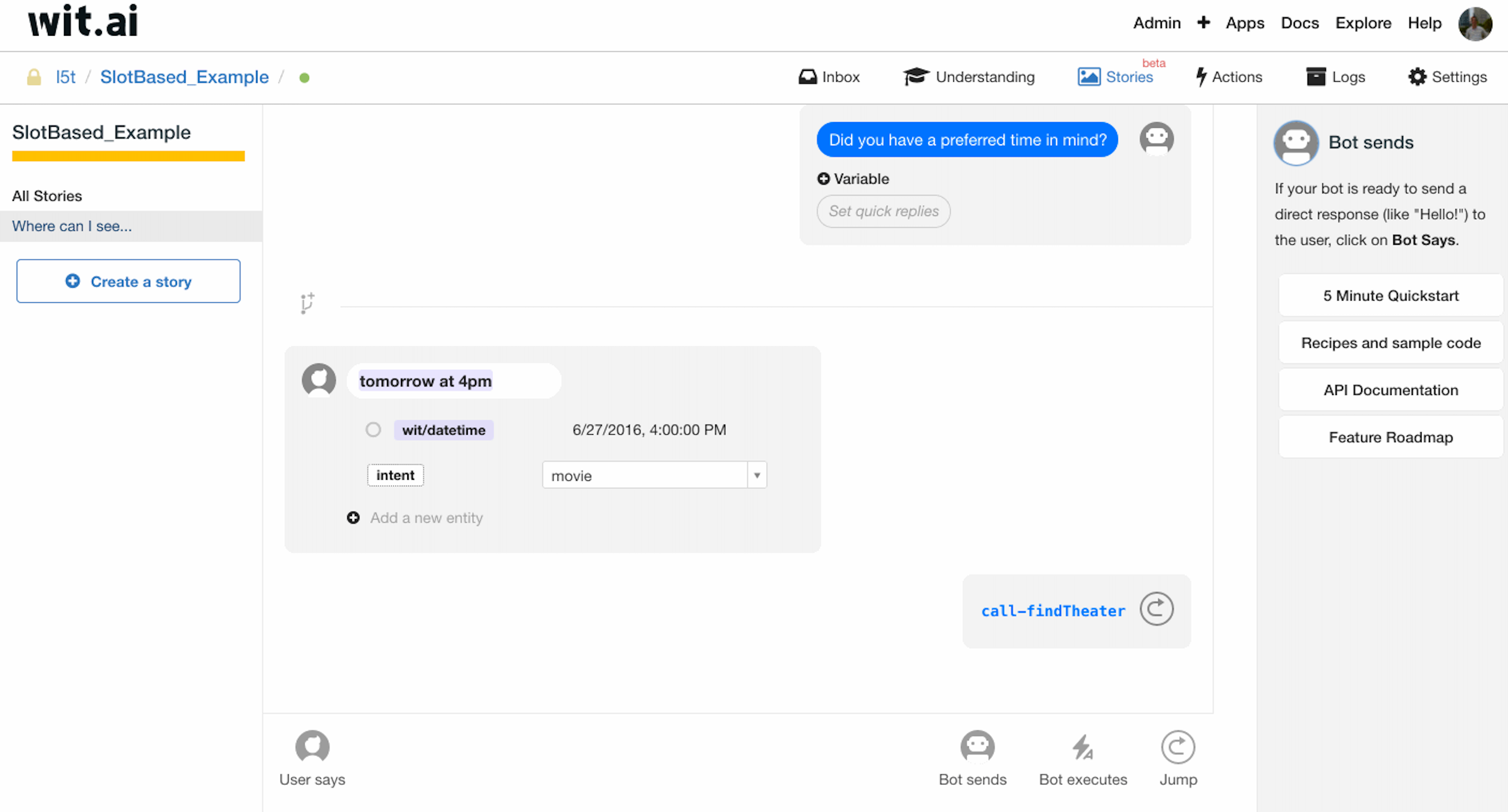
当用户补全时间实体后,业务上应当等同于用户一次提供完整信息的情况。
wit.ai 采用 bookmark 来做这种情况的处理。如图所示,我们在 findTheater 函数的调用前添加一个 call-findTheater 的 bookmark,当用户补全时间实体后,我们便利用 Jump 跳转到 call-findTheater,随之进行 findTheater 函数的调用,改走信息完整的分支。
3、处理是/非意图
(1)问题
当我们向用户确认问题时,用户说『是』或『不是』大多数情况下会影响到后续的对话过程。我们需要做两个不同的多轮对话分支来处理『是』和『不是』的情况。
(2)方案
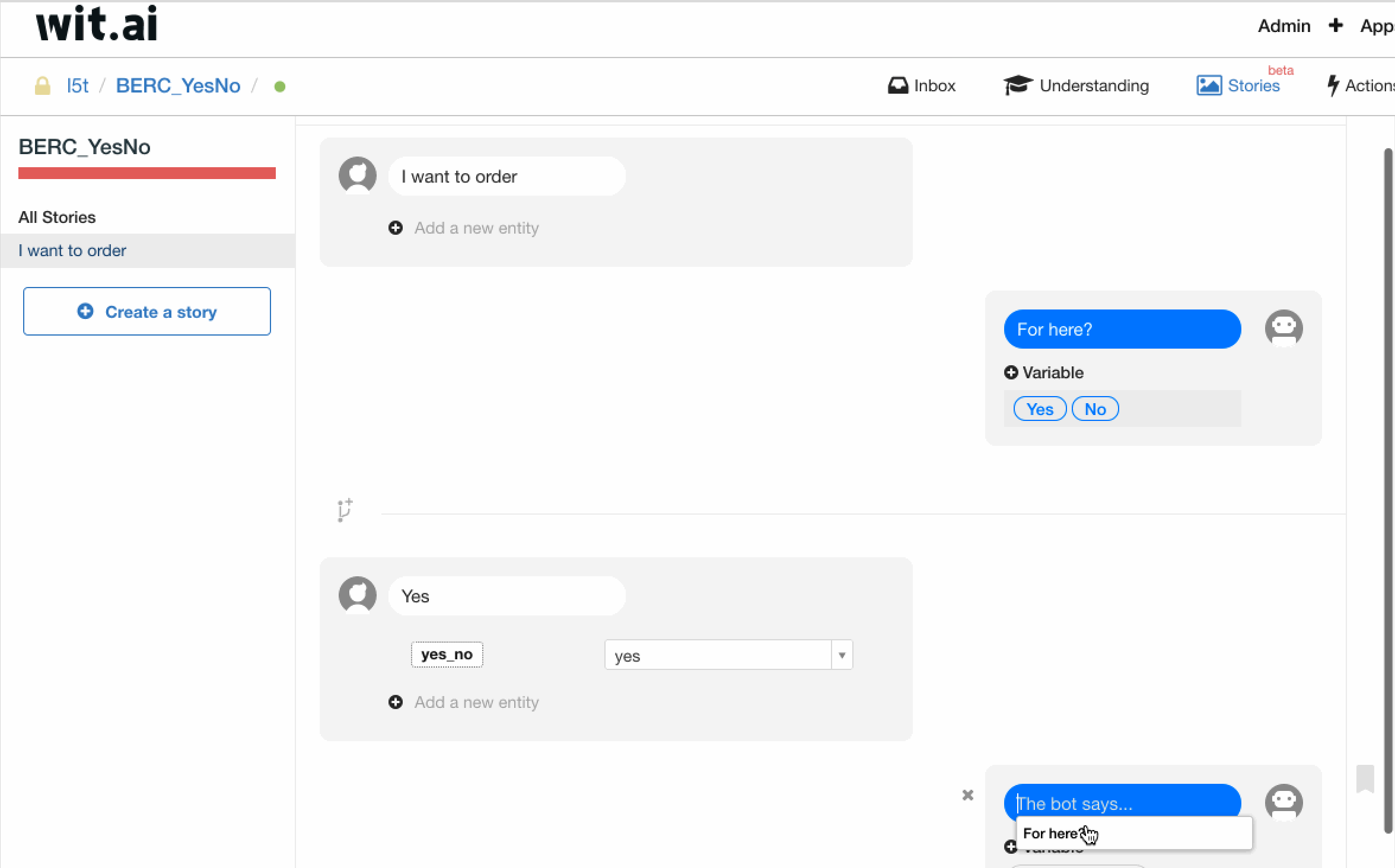
具体操作如图所示,与上文做多轮对话分支的方法基本相同,我们会新增一个实体 yes_no,并根据用户的不同回答走不同的多轮对话分支。(quick replies 会在下文提到)
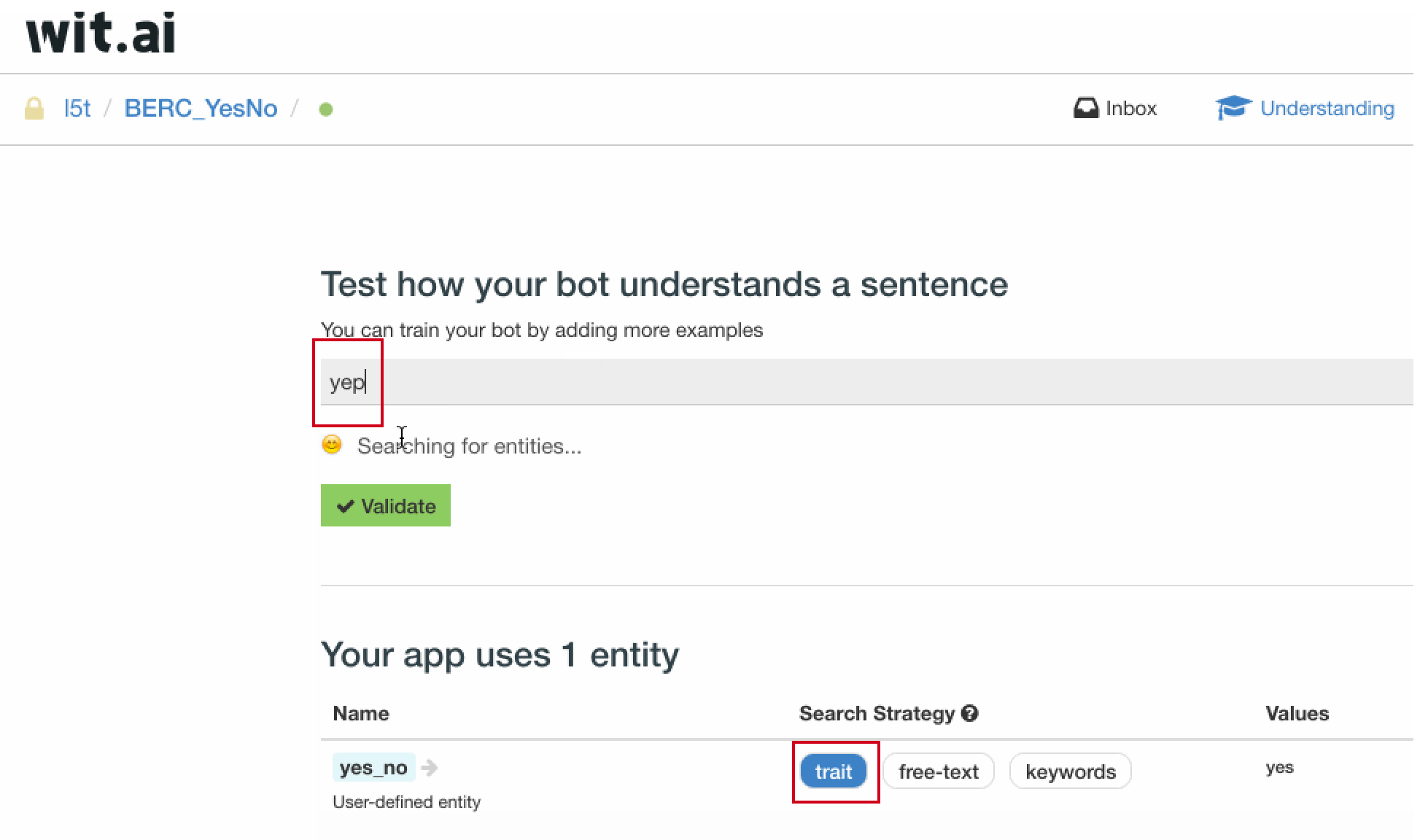
同时,我们当然希望不止能够识别用户的 yes,与之同意图的 yep、yeah 等也应当被认定为是用户的肯定回答。相对的,否定意图除了 no 之外,也应当包含 nope 等其他实体值。
另外需要特别注意的是,yes_no 的搜索策略应当选为 trait,也即我们需要通过整句话来判定用户的 intent,而不是某几个词。
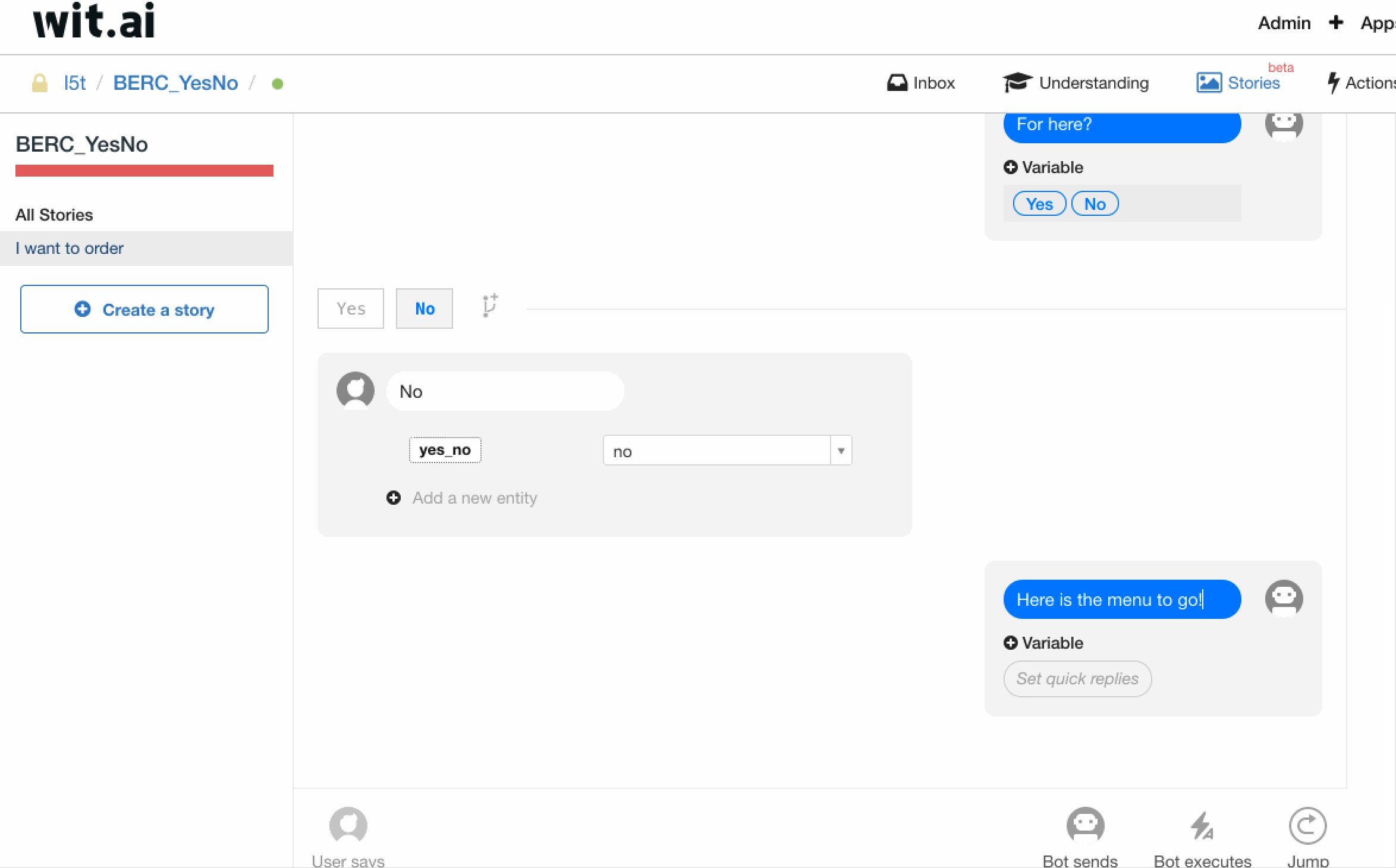
同样的,如图所示,我们新增一个 branch 来处理用户意图为 no 的情况。
4、基于流的机器人(flow-based bot)
(1)问题
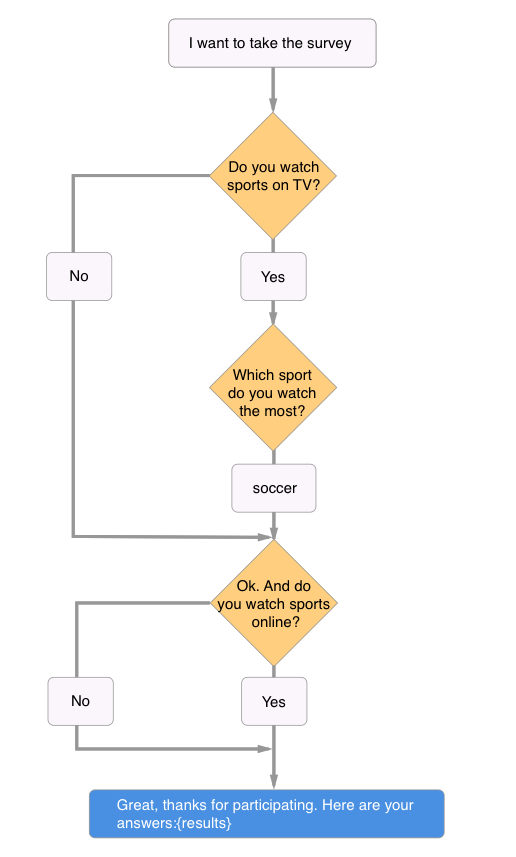
如上图所示,如果我们的机器人需要做一个包含两个问题的调查,特别的,根据第一个问题答案的不同,机器人会额外询问一个附加问题。这样的例子,就叫做基于流的对话。也即后续的对话路径依赖于前序的实体值。
(2)方案
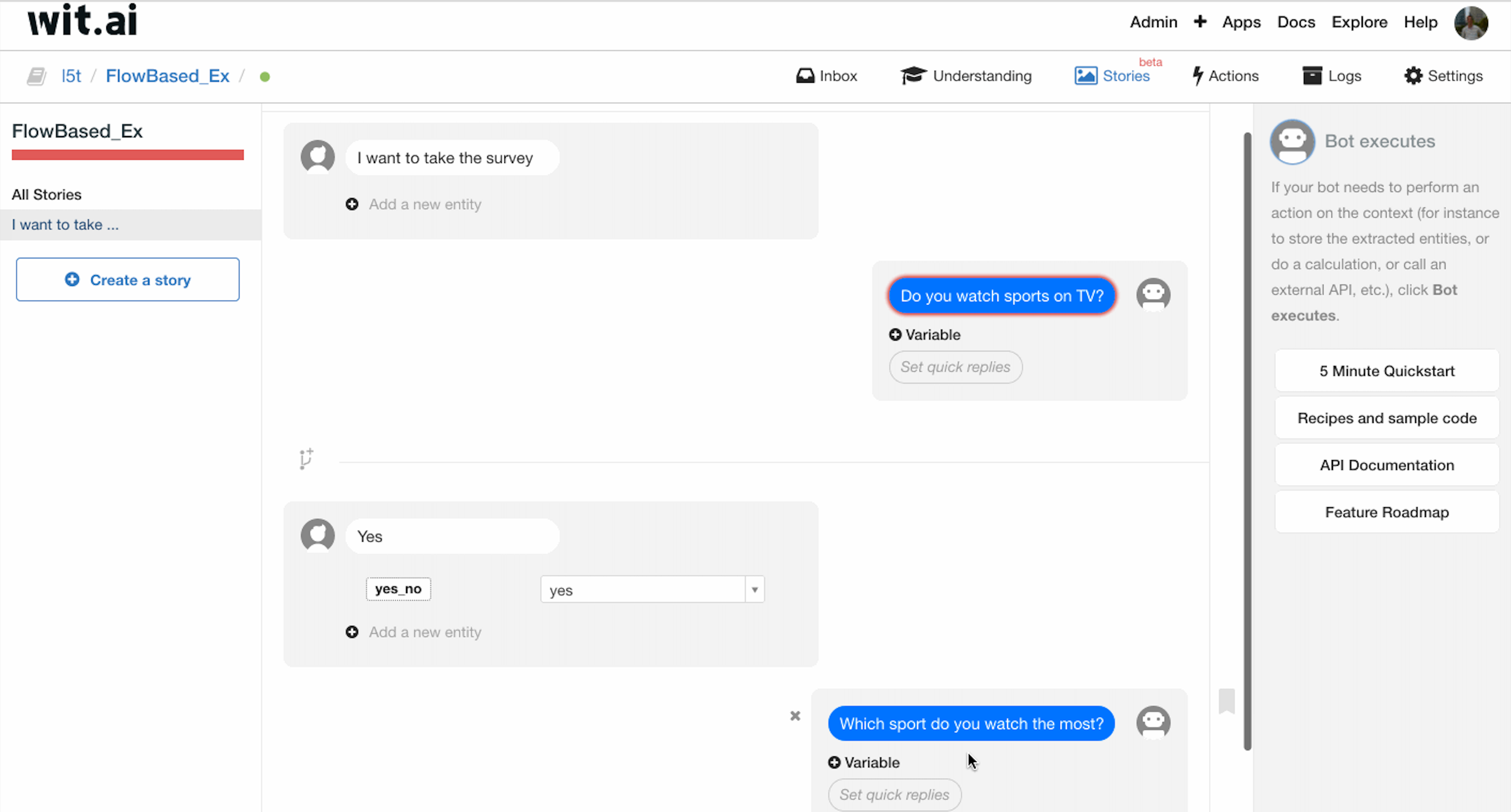
先处理第一种情况,用户问句首先为:”I want to take the survey”,随后机器人问第一个问题:”Do you watch sports on TV?”
这种情况下,如果用户回答的意图为 yes(处理方式上文中已经提到过),我们会追问一个额外的问题:”Which sports do you watch the most?”
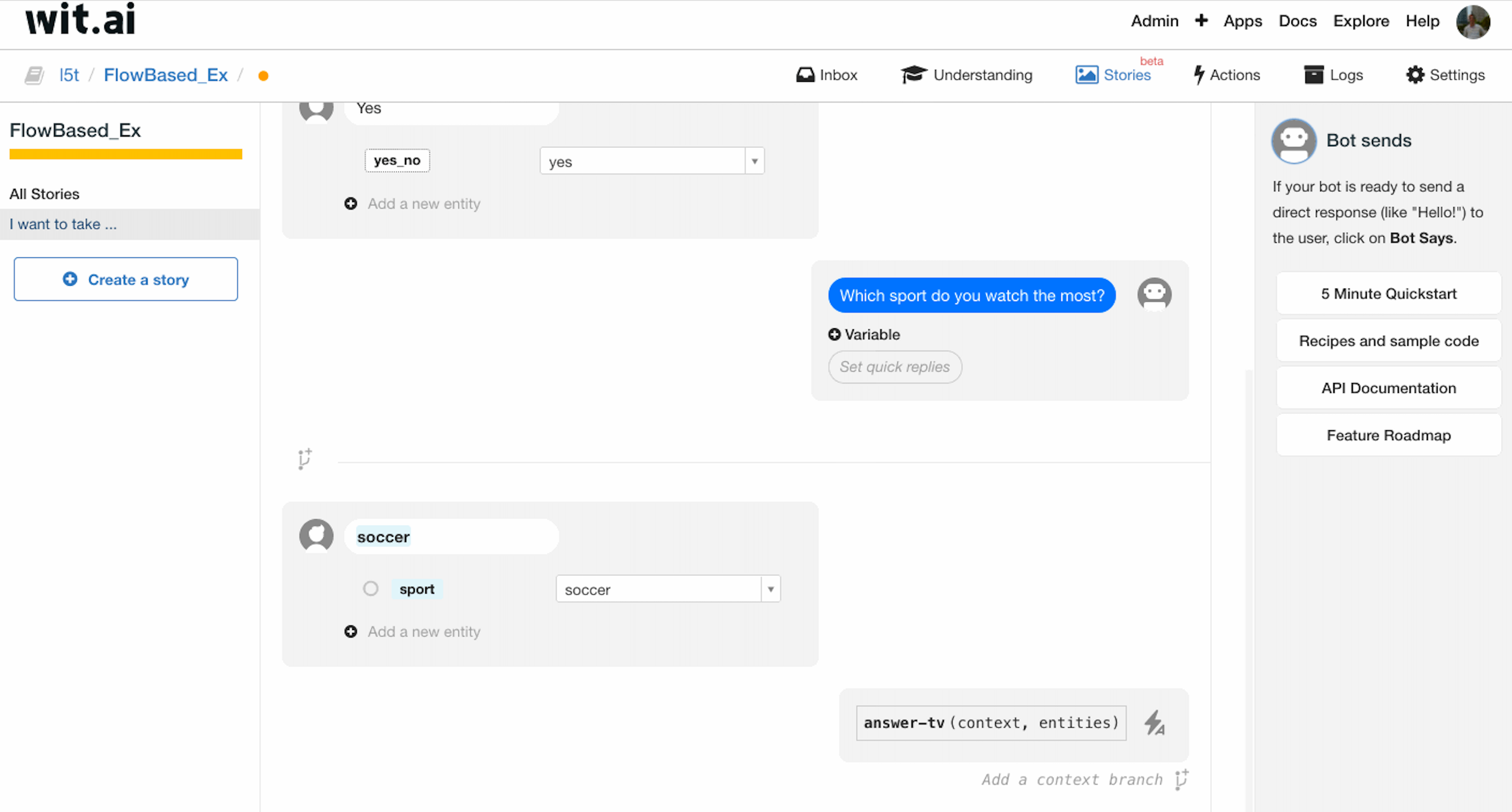
接收到用户的回复之后,首先进行 sport 实体的抽取,随后调用 answer-tv 函数进行处理,此时调查的第一部分结束。
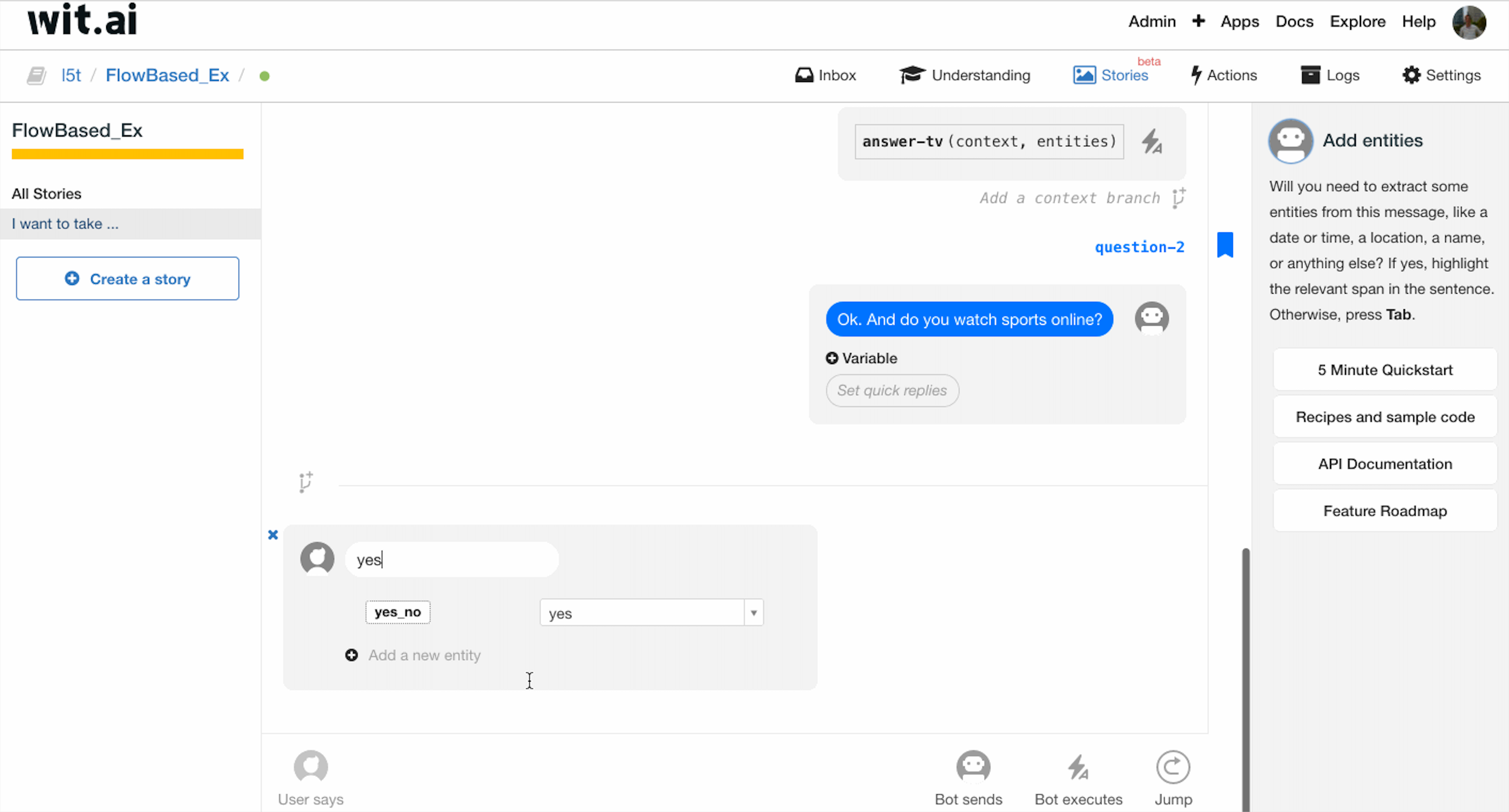
在调查的第二部分开始之前,我们先做一个 question-2 的 bookmark,为第一个问题 intent 为 no 的处理做准备。
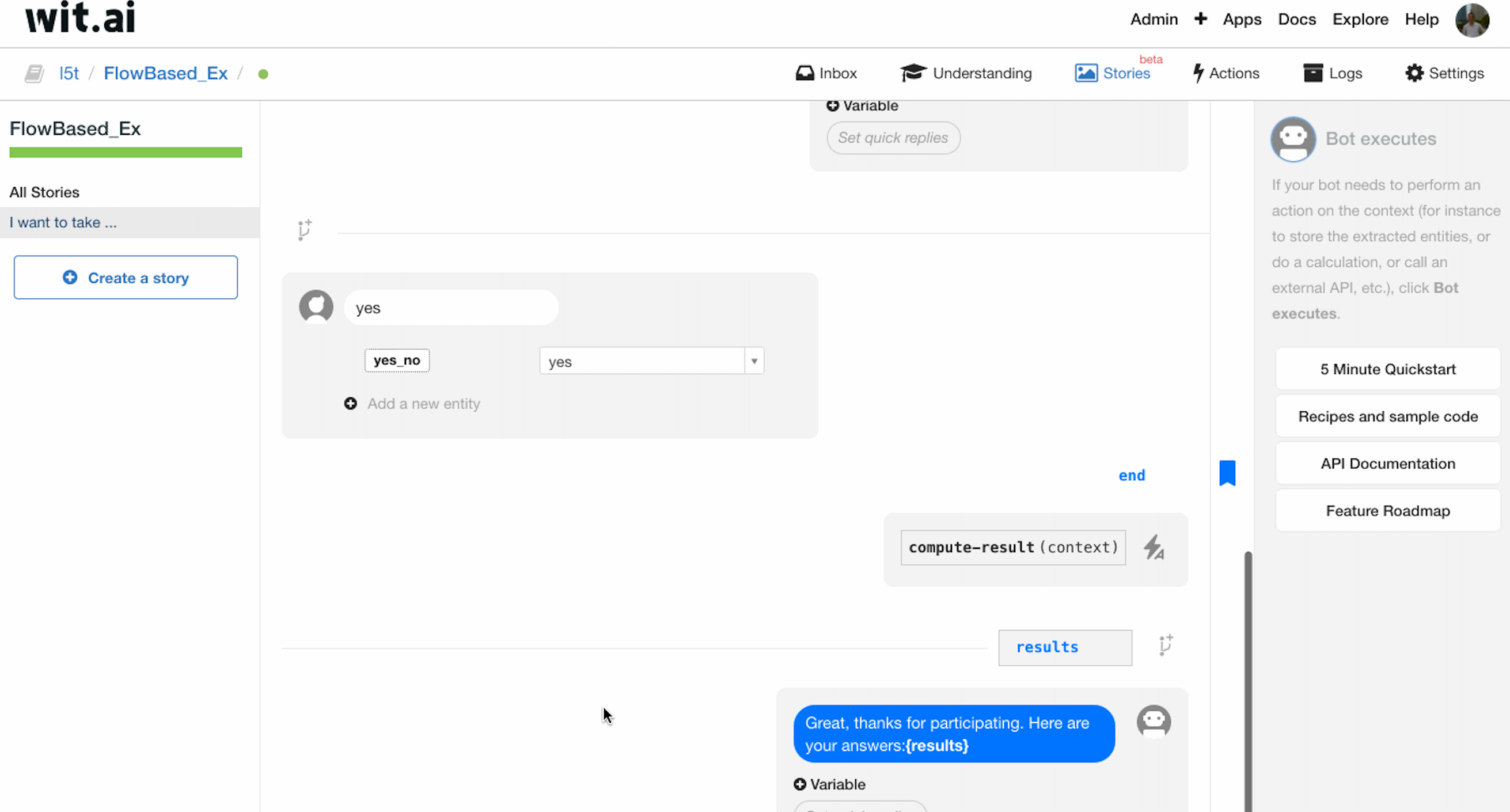
之后进行第二个问题回答的处理,询问用户:”Ok. And do you watch sport online?”,当用户回答的 intent 为 yes 时,调用 computer-result 函数,给出 result 作为返回值,拼装成最后的 Bot sends. 同时在函数调用之前增加一个 end 的 bookmark.
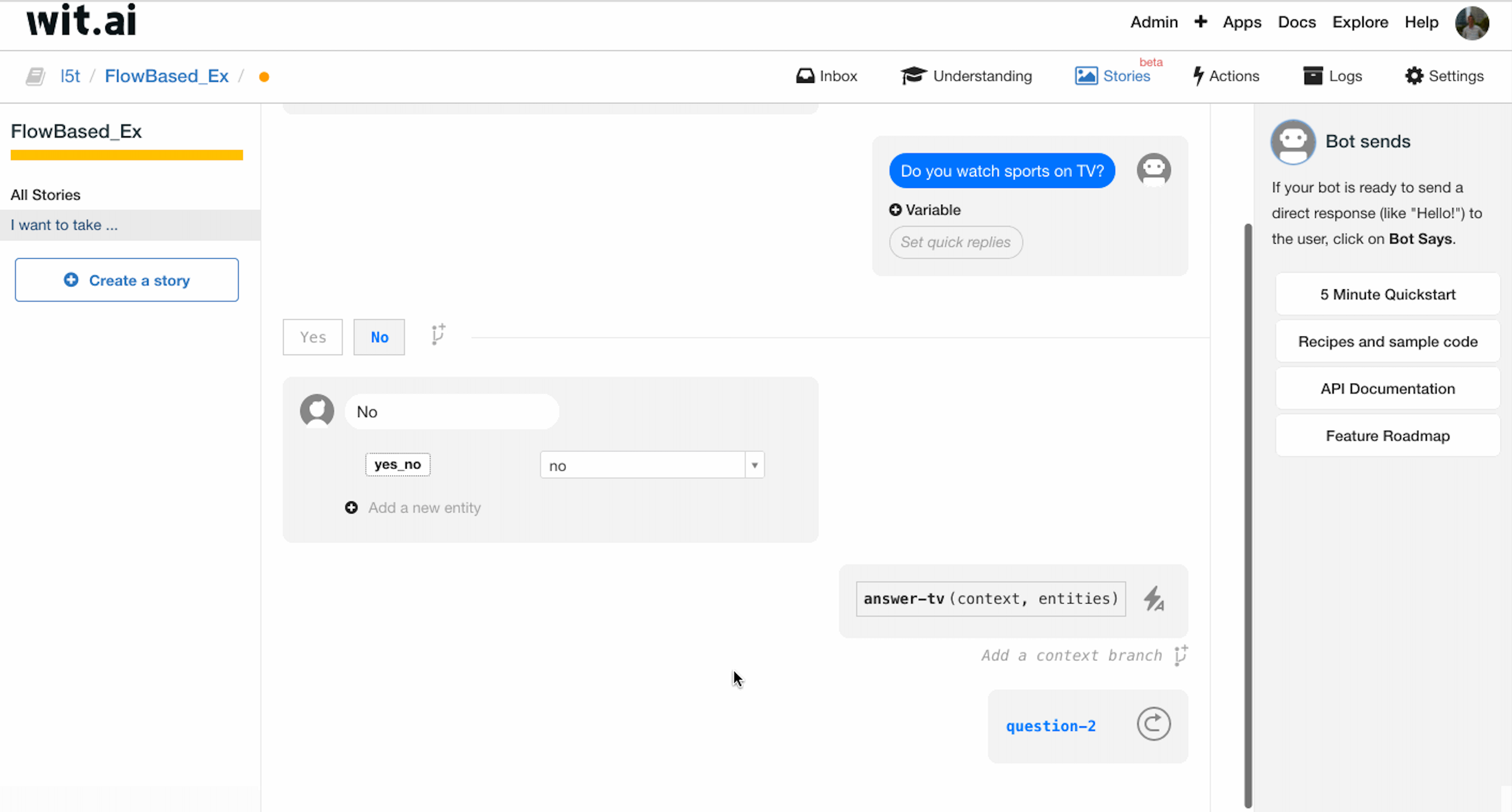
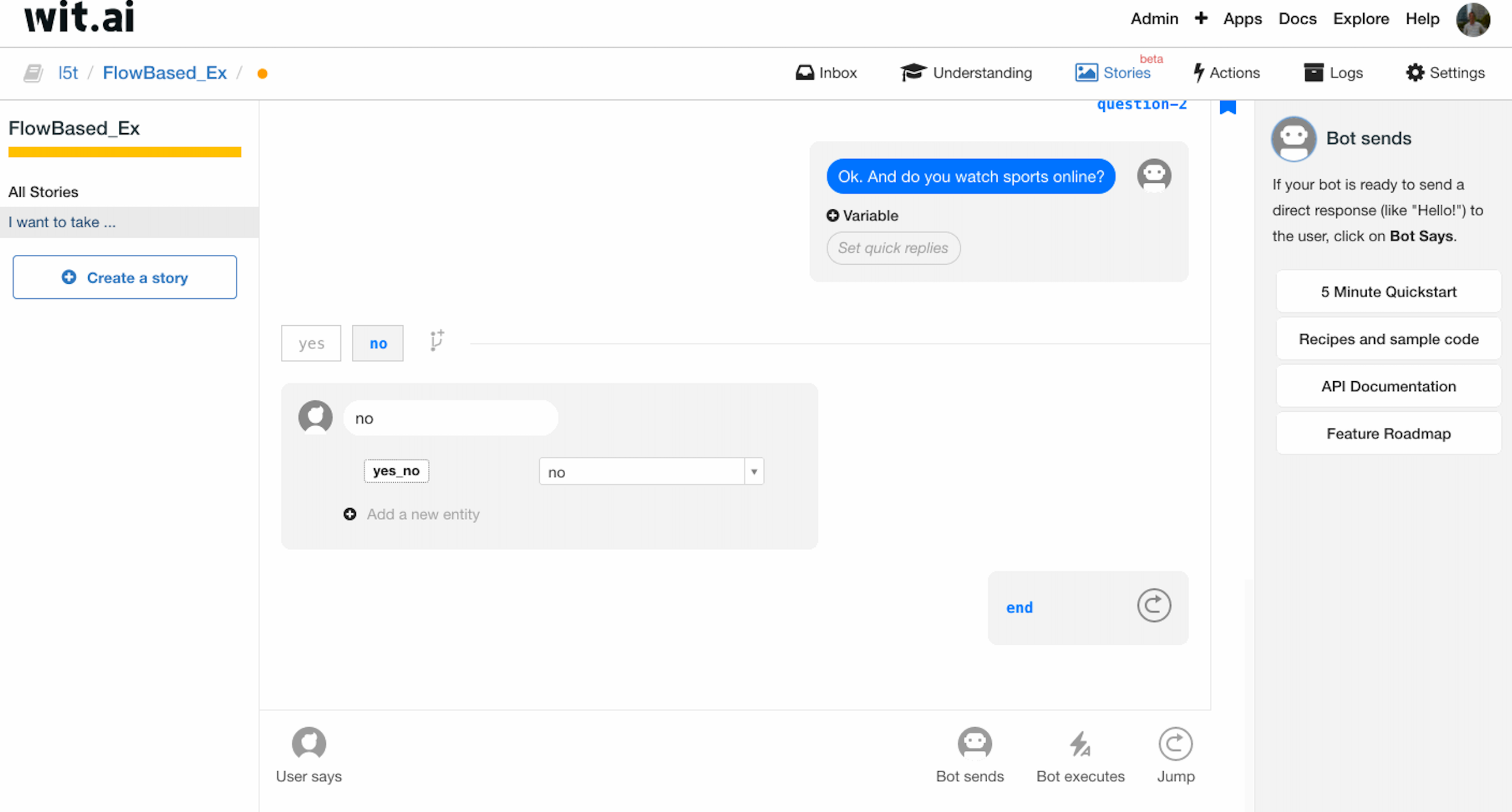
之后我们来处理两个问题 intent 均为 no 的情况。
按照之前的流程图,当第一个问题的 intent 为 no 时,应当直接跳转到第二个问题;当第二个问题的 intent 为 no 时,应当直接结束。
我们利用 bookmark 进行处理:当第一个 intent 为 no 时,我们使用 Jump 跳转到 question-2 的 bookmark,直接开始第二个问题的询问;当第二个 intent 为 no 时,我们同样利用 Jump 跳转到 end 的 bookmark,结束询问。补全了整个对话过程。
5、了解 Context 和 Session ID
(1)问题
我不明白 Context 和 Session ID 的关系。
(2)方案
context 是用于追踪当前对话状态的对象,由我们自己的函数进行管理,用于帮助 wit.ai 预测接下来的行为。通常一个 Session 中只有一个 context 对象。
session_id 是我们自己产生的,用于标记与同一个用户一次对话全部内容的唯一 ID. 需要注意的是,即便是同一个用户,不同的对话也应当拥有不同的 session_id。
6、添加快速回复
(1)问题
我们希望能够提供选项给用户,使得用户可以点选,以避免用户主动输入了我们无法处理的问句。
(2)方案
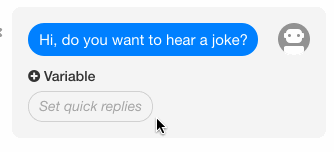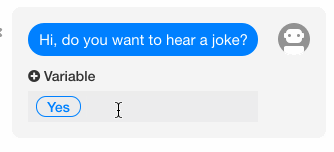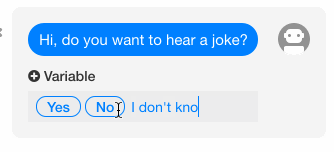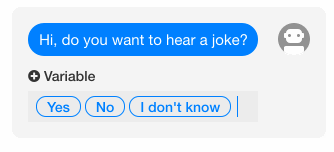
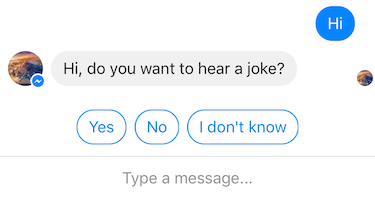
在 wit.ai 中,当我们在 Bot sends 下面的 Set quick replies 处填写了若干个选项后,这些选项将会在实际对话时出现在用户输入框的上方,提供给用户备选。
7、删除回复和动作
(1)问题
我想要删除我设置的一些回复和动作。
(2)方案
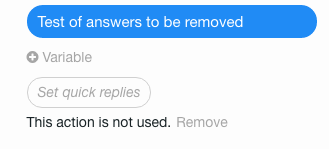
可以按照如图所示的方式操作。
小结
由此看来:
- Bot 的回复应当能够使用从用户问句中抽取过的实体值。
- slot-based bot 的实体之间是平级关系,flow-based bot 的实体之间是依赖关系。
- 槽的必填/非必填、单值/多值、值的使用方式都被隐藏在调用的函数中。
- 对话状态追踪(DST)通过函数对 context 的管理来完成,候选动作排序也在函数内部处理完成,并以 context-key 的方式作用于后续对话。
- 与百度 UNIT 平台相比,传入 context 并由函数进行 DST 和 policy 的方式要比为答案提供设置准入条件的方法要更加灵活。
- 目前的 wit.ai 中似乎没有反映出多轮过程与答案系统分离的思想,还是较为原始的,从头至尾,非叶子节点中的 Bot sends 算作多轮过程,叶子节点的 Bot sends 作为答案。
- Facebook 也发现对话系统能够利用的不应该只局限于用户问句中提供的信息,推出了 Bot engine,可以使用用户画像以及场景信息;意识到答案也不应当只局限于简单的文本,推出了 Built-in NLP for Messager,可以调用丰富的前端样式来做答案的展示。 并准备于2018年2月1日废弃掉对话部分所讲的 Stories UI.
- 对话系统应当具有节点间跳转的能力,wit.ai 采用 bookmark 来完成。阿里小蜜的在订票场景下的『换出发地』应当也是相同的原理;商品推荐时的『换一换』推测是通过该方法重复进入相同的推荐节点,但 context 中会记录该节点的进入次数,进而展示不同的结果。
- 常用的肯定、否定、请求更多等用户动作应被当做 intent 来处理,同时要注意不能只将其看做一些词的合集来处理,而是采用 trait 策略整体看待以识别意图。
- bookmark 是可以跨 branch 访问的。
- 同一个 Session 中,通常只有一个 context,这个context 由我们自己的函数维护,根据 context 的不同做出不同回应,返回不同的值,而后续的对话过程又依赖于函数调用的返回值来做多轮对话的分支。
- quick replies 可以每次单独设置,但也可以尝试把 keywords 类型实体的实体值词典利用起来。
还不了解的是:废弃现有的 Stories UI 后,用户画像以及场景信息由 context 传递,由函数来做 DST,应当是没有疑问的。但前端模板的调用是由函数来做,还是由当前的 Bot sends 模块改进得到?我个人倾向于由函数来做,一是更为灵活,二是可以将多轮过程与答案系统分离,Bot sends 只起到澄清以及推进对话的作用,而不是同时兼具答案提供的功能。
(完)
作者:我偏笑 ,AI产品经理大本营”成员,“AI研习小分队”的分享嘉宾之一
本文由人人都是产品经理专栏作家 @黄钊 授权发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自 Pixabay,基于 CC0 协议









没用过的话有点难看懂这篇文章,反正我是没看懂