
 起点课堂会员权益
起点课堂会员权益实战案例:AI产品经理如何介绍“计算机视觉”?

作者根据亲身经理的项目案例和平时所学,从产品实践的角度,谈谈计算机视觉,希望对你有所帮助。
计算机视觉(Computer Vision)对我来说也算是老朋友了,我最开始接触人工智能就是计算机视觉相关的知识。最近受益于老大每日带我去旁听的算法例会,又加上看了徐立(商汤)的《计算机视觉的完整链条,从成像到早期视觉再到识别理解》,发现很多信息,当时不觉得有什么,现在想想,每一步都是有意义的。
今天,我会根据亲身经理的项目案例和平时所学,从产品实践的角度,谈谈计算机视觉。
一、前言
计算机视觉(computer vision)是使用计算机以及相关设备对生物视觉的一种模拟。它主要任务是通过对采集的图片或视频进行处理以获得相应场景的三维信息。
在徐立的分享中,将计算机视觉的完整链条分为了三部分:
- 成像(image)
- 早期视觉(early vision)
- 识别理解(Recognition)
本文也将根据徐立对整个链条的三部分分类,分别用实际例子结合谈谈产品在三部分中可以关注的内容。
二、成像(image)
成像就是模拟的相机原理,就是在解决怎样把拍摄照片的质量进行提升的问题。
我们在实际工业运用中,经常发现实际数据和实验室数据相差过大,实验数据的质量远远差于实验室数据。更甚者在最开始训练模型的时候,我们会发现实验室模型在实际场景毫无效用。
经过多次试验测试,我们发现影响图像质量的因素大概有以下几类:
光照影响
过暗或过亮等非正常光照环境,会对模型的效果产生很大干扰。在解决光照影响这个问题上,我想可以通过两种方式:
1)从产品角度控制:
a.在用户可以更换环境的前提下(比如手机自拍等),可语音/界面提示用户目前环境不理想,建议换一个环境。
b.用户不能控制更换环境的情况下(比如人脸识别、车辆识别等摄像头固定的场景),只能通过调试硬件设施弥补这个问题。
- 夜晚:在工业上我们碰到过曝或者过暗的情况更多都是在晚上,由于摄像头在晚上会自动切换到黑夜场景(从图片上看就是从彩色切换为黑白),因此在晚上强光下(例如车灯照射)图像就会过曝,这样的情况我们可以通过强制设置摄像头环境为白天(图像为彩色)来避免。过暗的情况从节省成本角度看,我们可以在摄像头旁边增加一个光线发散、功率不高的灯来弥补。当然这两个问题也可以通过购买高质量的摄像头解决,但这样做也意味着更高的成本。
- 白日:白天也会出现光线过亮的情况,这种情况可以考虑用滤光片等等。
2)算法角度控制
用算法将图片进行处理,可以将图片恢复得让人眼看清的程度。徐立在文中举例了这样一张图片:

这张图片从暗到明,经过算法的处理我们可以显而易见地观察到整个图片的内容。这个办法非常灵活,但也对公司的算法提出了更高的要求。我们知道每一次算法的过滤时间是非常重要的,如果在对时间要求非常严格的场景(人脸识别、车辆识别),这样在识别之前还要对图片进行转化,无疑是增加了输出结果的时间。技术实力不那么强的公司可能是需要权衡一下的。
模糊(blur)
模糊也是工业中经常遇到且令人十分头痛的问题。这里我们先将模糊分下类:
- 运动模糊:人体移动、车辆移动
- 对焦模糊:摄像头距离等因素构成,类似近视眼,图像中低频存在,高频缺失。所以需要用算法设法补齐高频部分。
- 低分辨率差值模糊:小图放大等,图像中低频存在,高频缺失。所以需要用算法设法补齐高频部分。
- 混合模糊:多种模糊类型共同存在
对于模糊产品上能控制的场景比较少,仅针对于第一种运动模糊且产品和用户有交互的情况下才能做到。其他类型的模糊均需要采用算法进行处理。
我们发现大多数模型(包括face++等技术比较前沿公司的模型),也会出现大量正常图像被判为模糊。从算法角度讲这可能不是很理想,但从工业角度讲这是可以被接受的,被误判为模糊图像的正常图像会被过滤掉或者经过算法处理后再识别,这对用户来说不会造成使用上的不适。而且我们也能保证阈值以上的图都是正常图片,对模型训练来说也是有利的。所以,产品需要关注的精确率和召回率在某种特定情况下可以降低要求。
影响图像质量的因素除了光照、模糊还有很多比如噪声、分辨率等等问题,这些问题大多也是从算法和硬件上去优化,值得注意的是我之前提过的,需要考虑到时间和成本的权衡。
三、早期视觉(early vision)
early vision这部分其实我之前没有总的概念,看了徐立的分享,回头来才发现“哦!原来大家当时做的是这个部分的内容”。
early vision主要是做哪些工作呢?主要是图像分割、边缘求取、运动和深度的估计。这些内容其实没有直接的结果应用,是一个“中间状态”。

图像分割是指将特定的影像分割成【区域内部属性一致】而【区域间不一致】的技术,是图像处理中最基础和最重要的领域之一。
图像分割方法有很多种,比如灰度阈值分割的方法、边缘检测法和区域跟踪等方法。很多种类的图像或景物都有相对应的分割方式对其分割,但同时有些分割方法也仅限于某些特殊类型的图像分割。
拿边缘检测来说,其目的是找到图像中亮度变化剧烈的像素点构成的集合,表现出来就是轮廓。

徐立提出了early vision现目前的两个问题:
- 结果不精确
- 需要长时间的知识沉淀才能做到
第一个问题的解决办法是用端到端的方式,第二个问题的解决办法可以依靠数据驱动。
这部分产品介入的比较少吧,平时跟算法同事沟通听见比较偏多的反馈是在图像分割上有一些缺陷。像徐立说的“怎么样用这种中间的结果去得到更好的应用,至今来说觉得这都是一个比较难回答的问题”,因此产品或许可以去考虑早期视觉直接应用的场景。
四、识别理解(Recognition)
识别理解是需要把一张(输入)图对应到一张(输出)图,或者说一张(输入)图对应到一个中间结果。简单来说就是把一张图对应到一个文字或标签。这其中有两个重要的因素:标签、数据。这两个因素广度和精度越高,针对模型最后的识别效果就越好。
标签
标签的定义其实也就是规则的定义,我在上一篇文章《AI产品经理需要了解的数据标注工作》里有提过,越精确的标签肯定对模型的结果有利,但同时越精确的标签意味着这类标签下的数据量就会越少,产品也需要考虑到这个因素。
还有一些会被主观因素影响的标签定义,比如颜值,每个人对颜值的评价都是不一样的。徐立说在他们的颜值模型里会分为“漂亮”“不漂亮”两个标签,主要是靠社交网站上的评分和明星与大众的区别来标注。其实我以前也跟过颜值的模型,在我的模型里对颜值更加细化了:有好看、普通、丑。除了根据社交网站打分、明星打分这种方式,我的经验是关注数据的场景类型,很多数据被归为一类都是场景相似的。比如如花,我们觉得丑吧?大多数男扮女的装扮也都会被定义为丑。
另外更细的标签细分会有更多的落地可能性,我印象最深的就是以前颜值模型有一个节日运营活动,主题是扮丑,办得越丑的人还会有小礼品,这个活动上线后在友商的用户圈内引起了很高的关注度。当时我接到这个活动的时候思想其实是被颠覆的,因为我最开始认为颜值模型可能存在的场景主要是去识别美的人,比如在直播等平台中去区分主播的颜值,推荐更优质的主播上首页等等后端的应用,没有想过还能反着用。经过这个活动的启发,后来我们也发现颜值模型在娱乐性上可以有更多挖掘的可能性。
这样看来由于我们的模型多了一个标签定义,就多了一种落地的可能性,标签的重要性也就不言而喻了。
数据优化
数据的数量和质量对模型来说举足重轻。最近刚接收到的重磅消息:阿法狗的弟弟阿法元没有任何先验知识的前提下,通过完全的自学,打败了由数据训练出来的阿法狗。我相信以后这个技术肯定会越来越多的应用,说不定以后确实在某些领域不利用海量数据也能完成模型训练。但是就目前而言,在计算机视觉领域,数据的大量性是重中之重的。
我们大家肯定都知道,数据优化可以使模型越来越好。什么类型的功能表现得不好,就要填补那些对应的数据。而除了这个常识外,其实数据优化还可以用来解决我们经常在训练过程中出现的问题:过拟合。
什么是过拟合?

通常来讲是模型把数据学习过深,数据中的细节和噪音也学习进去了,这样就导致模型泛化的性能变差。过拟合的表现是,一个模型(一个假设)在训练集上表现得很好,但是在测试集上表现的确不是很好。
那该如何通过数据限制过拟合呢?
- 重新清洗数据。数据的噪音太多会影响到模型效果,清洗数据能够把由于这个因素造成的过拟合问题规避
- 增加训练集的数据量。如果训练集占总数据的比例太少,也会造成过拟合。
当然也能通过算法限制这个问题的,比如正则化方法和dropout法,以后有空我们可以再深入讨论。
五、项目实践 (以车型识别举例)
车辆检测系统下有很多CV相关的应用,比如车型识别、车牌识别、车颜色识别等等。我们从车型识别这一个例子着手,探索项目的具体流程。
项目前期准备
1.数据准备:
车型这个主题说大不大,说小不小。全世界的车辆品牌数目大约三四百个,每个品牌下面又有几十种车系。我们从0开始立项,至少需要把常见的车辆车系都包含。像大众、丰田、奔驰、宝马、奥迪、现代等等热门车辆品牌更是需要拿全数据。每一种车型至少有车头、车尾、车身三种基础数据。
比如奔驰C200:
这三张图片代表了三种数据,不同场景下这三种数据的重要性大为不同。在项目前期假设我们定下来识别车型这个需求主要应用场景是“停车场识别车辆”,那车头这个数据相对而言就更加重要,需要花更多心思收集。为什么呢?我们可以想象,停车场的车辆识别摄像头为了捕捉车牌号,一般会将摄像头正对车辆,摄像头传上来的数据很少会有纯侧面车身的数据甚至车尾数据。我们为了项目更快地应用落地,其他类型数据比较缺少的情况是可以暂时放下后期再做优化的。

在数据准备的过程中,首先需要爬虫从网上爬取数据,再由人工筛选过滤到不可用的数据,将数据统一整合,才能进行下一步工作。
2.文档准备
A)数据标注文档,包括我们项目一共所含多少钟车型、每一种车型分别对应什么样式。数据标注中需要注意的问题,多辆车的图片、角度刁钻的图片是否需要舍弃等等。
B)产品文档,包括落地场景说明、需求说明文档等常规文档。这里拿工业车辆识别需求分析下系统设计:
- 算法需求描述(识别的种类、范围、速度、准确率、稳定性等等)
- 摄像头设备硬件需求描述、环境描述、数据传送描述、摄像头配置描述
- 平台程序设计(车辆识别系统平台前后端设计)
- 数据关联描述(车辆信息分析统计关联)
如果摄像头在局域网,且有布控功能(识别车辆黑名单的需求)还需要:
- 下发程序(考虑云端到本地的图像特征下发)
- 点播程序设计(可以从互联网查看本地摄像头)
项目流程跟踪
1.软硬件端:按照常规的软硬件项目跟踪开发
2.算法:车型识别的流程基本如下:

车型图像上传:通过过摄像头/web上传
图像预处理:包含了上文成像部分中的模糊图像恢复处理(运动模糊有快速算法去模糊:通过已知速度V、位移S,确定图像中任意点的值)

early vision中的图像分割(将目标图像从背景图中标识出来,便于图像识别,可以考虑边缘检测方法)、图像二值化(将图像中的像素点的灰度值设置为0或者255,使用轮廓跟踪让目标轮廓更为凸显)
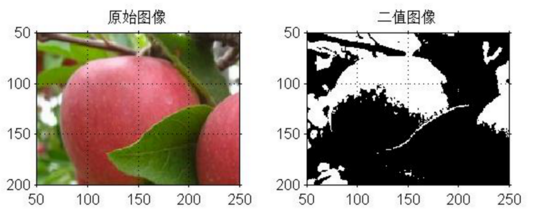
图像特征提取
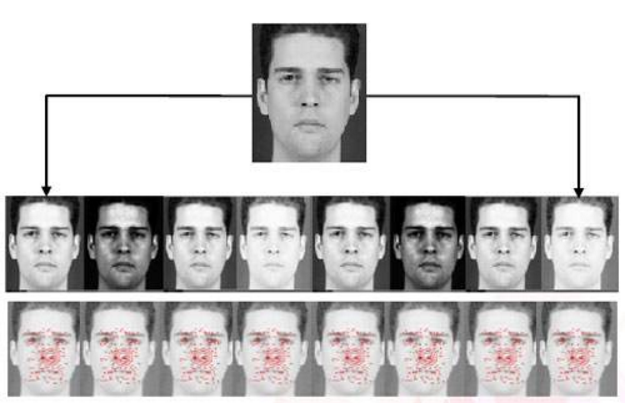
特征比对
项目测试
- 摄像头测试
- 摄像头与点播程序测试
- 点播程序(可实时查看摄像头的程序)与平台后台程序测试
- 算法与平台后台测试、备用接口测试
- 模型识别时间测试
- 模型识别准确率、召回率测试
- 服务器稳定性测试
- 网络带宽限制测试
- 正反向测试
- 其他平台、硬件产品常规测试
- 项目验收
产品按照流程功能逐一验收
六、后记
今天从产品实践角度梳理了下计算机视觉的链条,里面可能不怎么涉及到算法知识,我更多的是想通过分享我个人经历给大家,能产生更多在产品上的碰撞。
当然在整个流程中还有很多有意思的事,大家可以多了解相关的知识,有想法也可以和我多多交流.
本文由 @Jasmine 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自PEXELS,基于CC0协议






- 目前还没评论,等你发挥!


