
 起点课堂会员权益
起点课堂会员权益AI PM老司机带你认识声音黑科技:声纹识别

同属于生物识别技术,与火爆的人脸识别相比,声纹识别表现得很低调,然而这并不影响这一黑科技魅力的散发,本文将带你认识一下声音黑科技-声纹识别,让你了解真正的“闻声识人”。
本文将从如下方面为你一一解读:
- 什么是声纹?
- 声纹识别的原理
- 声纹识别算法的技术指标
- 影响声纹识别水平的因素
- 声纹识别的应用流程
- 声纹识别的应用场景
一、什么是声纹?
声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱,是由波长、频率以及强度等百余种特征维度组成的生物特征,具有稳定性、可测量性、唯一性等特点。
- 人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,发声器官–舌、牙齿、喉头、肺、鼻腔在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异。
- 每个人的语音声学特征既有相对稳定性,又有变异性,不是一成不变的。这种变异可来自生理、病理、心理、模拟、伪装,也与环境干扰有关。
- 尽管如此,由于每个人的发音器官都不尽相同,因此在一般情况下,人们仍能区别不同的人的声音或判断是否是同一人的声音。
声纹不如图像那样直观展现,在实际分析中,可通过波形图和语谱图进行展现,如下所示:
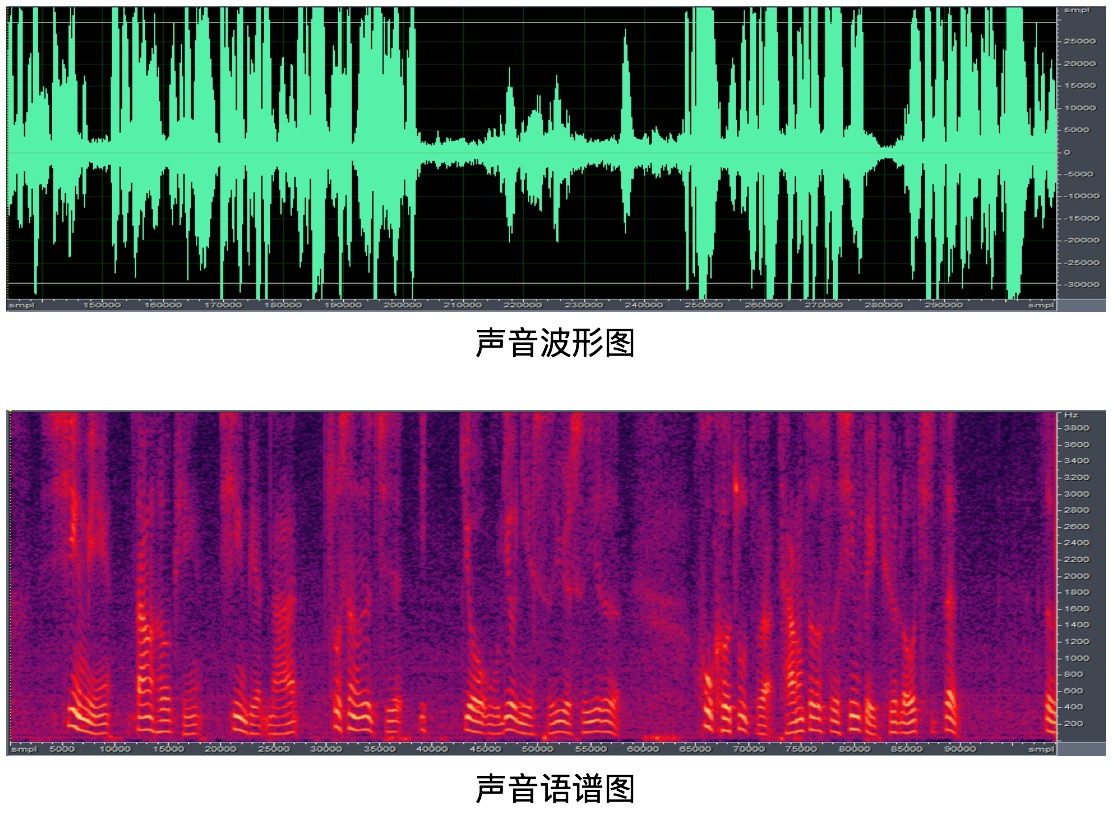
二、声纹识别的原理
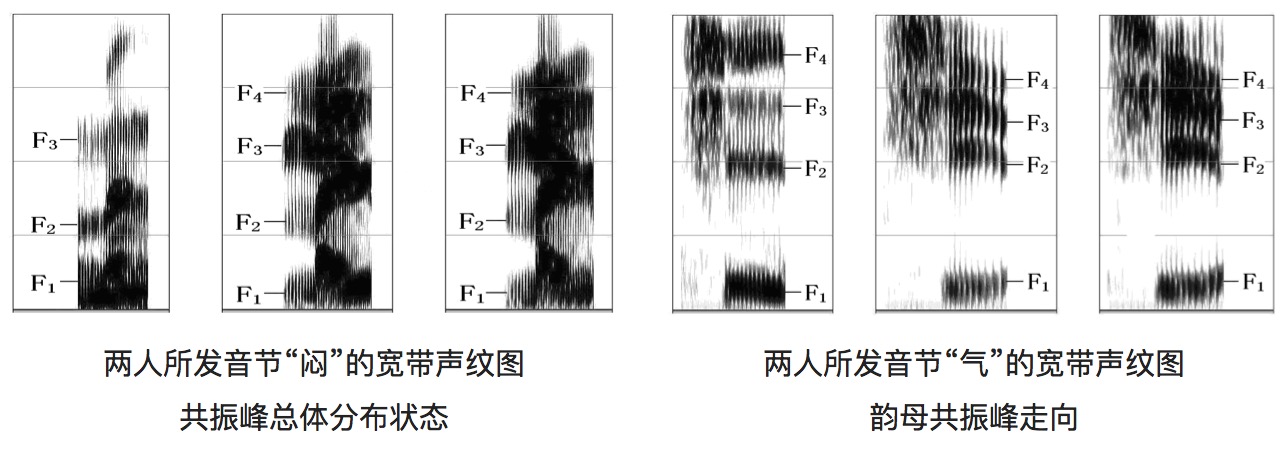
人在讲话时使用的发声器官在尺寸和形态方面每个人的差异很大,所以任何两个人的声纹图谱都有差异,主要体现在如下方面:
- 共鸣方式特征:咽腔共鸣、鼻腔共鸣和口腔共鸣
- 嗓音纯度特征:不同人的嗓音,纯度一般是不一样的,粗略地可分为高纯度(明亮)、低纯度(沙哑)和中等纯度三个等级
- 平均音高特征:平均音高的高低就是一般所说的嗓音是高亢还是低沉
- 音域特征:音域的高低就是通常所说的声音饱满还是干瘪
不同人的声音在语谱图中共振峰的分布情况不同,声纹识别正是通过比对两段语音的说话人在相同音素上的发声来判断是否为同一个人,从而实现“闻声识人”的功能。
三、声纹识别算法的技术指标
声纹识别在算法层面可通过如下基本的技术指标来判断其性能,除此之外还有其它的一些指标,如:信道鲁棒性、时变鲁棒性、假冒攻击鲁棒性、群体普适性等指标,这部分后续于详细展开讲解。
- 错误拒绝率(False Rejection Rate, FRR) :分类问题中,若两个样本为同类(同一个人),却被系统误认为异类(非同一个人),则为错误拒绝案例。错误拒绝率为错误拒绝案例在所有同类匹配案例的比例。
- 错误接受率(False Acceptance Rate, FAR) :分类问题中,若两个样本为异类(非同一个人),却被系统误认为同类(同一个人),则为错误接受案例。错误接受率为错误接受案例在所有异类匹配案例的比例。
- 等错误率(Equal Error Rate,EER):调整阈值,使得误拒绝率(False Rejection Rate,FRR)等于误接受率 (False Acceptance Rate,FAR),此时的FAR与FRR的值称为等错误率。
- 准确率(Accuracy,ACC):调整阈值,使得FAR+FRR最小,1减去这个值即为识别准确率,即ACC=1 – min(FAR+FRR)
- 速度:(提取速度:提取声纹速度与音频时长有关、验证比对速度):Real Time Factor 实时比(衡量提取时间跟音频时长的关系,比如:1秒能够处理80s的音频,那么实时比就是1:80)。验证比对速度是指平均每秒钟能进行的声纹比对次数。
- ROC曲线:描述FAR与FRR之间相互变化关系的曲线,X轴为FAR的值,Y轴为FRR的值。从左到右,当阈值增长期间,每一个时刻都有一对FAR和FRR的值,将这些值在图上描点连成一条曲线,就是ROC曲线。
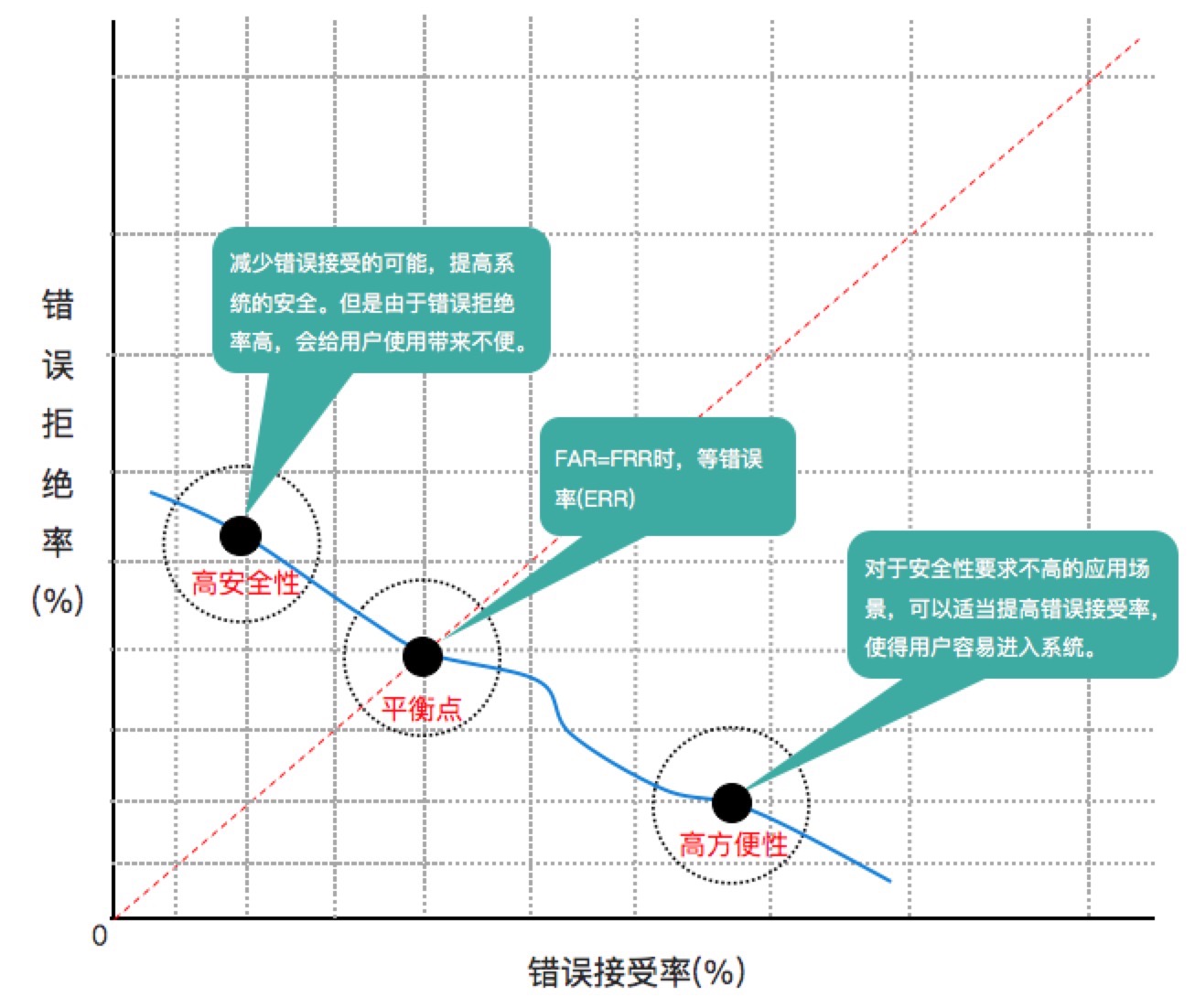
- 阈值:在接受/拒绝二元分类系统中,通常会设定一个阈值,分数超过该值时才做出接受决定。调节阈值可以根据业务需求平衡FAR与FRR。 当设定高阈值时,系统做出接受决定的得分要求较为严格,FAR降低,FRR升高;当设定低阈值时,系统做出接受决定的得分要求较为宽松,FAR升高,FRR降低。在不同应用场景下,调整不同的阈值,则可在安全性和方便性间平平衡,如下图所示:
四、影响声纹识别水平的因素
训练数据和算法是影响声纹识别水平的两个重要因素,在应用落地过程中,还会受很多因素的影响。
声源采样率
- 人类语音的频段集中于50Hz ~ 8KHz之间,尤其在4KHz以下频段
- 离散信号覆盖频段为信号采样率的一半(奈奎斯特采样定理)
- 采样率越高,信息量越大
- 常用采样率:8KHz (即0 ~ 4KHz频段),16KHz(即0 ~ 8KHz频段)
信噪比(SNR)
- 信噪比衡量一段音频中语音信号与噪声的能量比,即语音的干净程度
- 15dB以上(基本干净),6dB(嘈杂),0dB(非常吵)
信道
- 不同的采集设备,以及通信过程会引入不同的失真
- 声纹识别算法与模型需要覆盖尽可能多的信道
- 手机麦克风、桌面麦克风、固话、移动通信(CDMA, TD-LTE等)、微信……
语音时长
- 语音时长(包括注册语音条数)会影响声纹识别的精度
- 有效语音时长越长,算法得到的数据越多,精度也会越高
- 短语音(1~3s)
- 长语音(20s+)
文本内容
- 通俗地说,声纹识别系统通过比对两段语音的说话人在相同音素上的发声来判断是否为同一个人
- 固定文本:注册与验证内容相同
- 半固定文本:内容一样但顺序不同;文本属于固定集合
- 自由文本
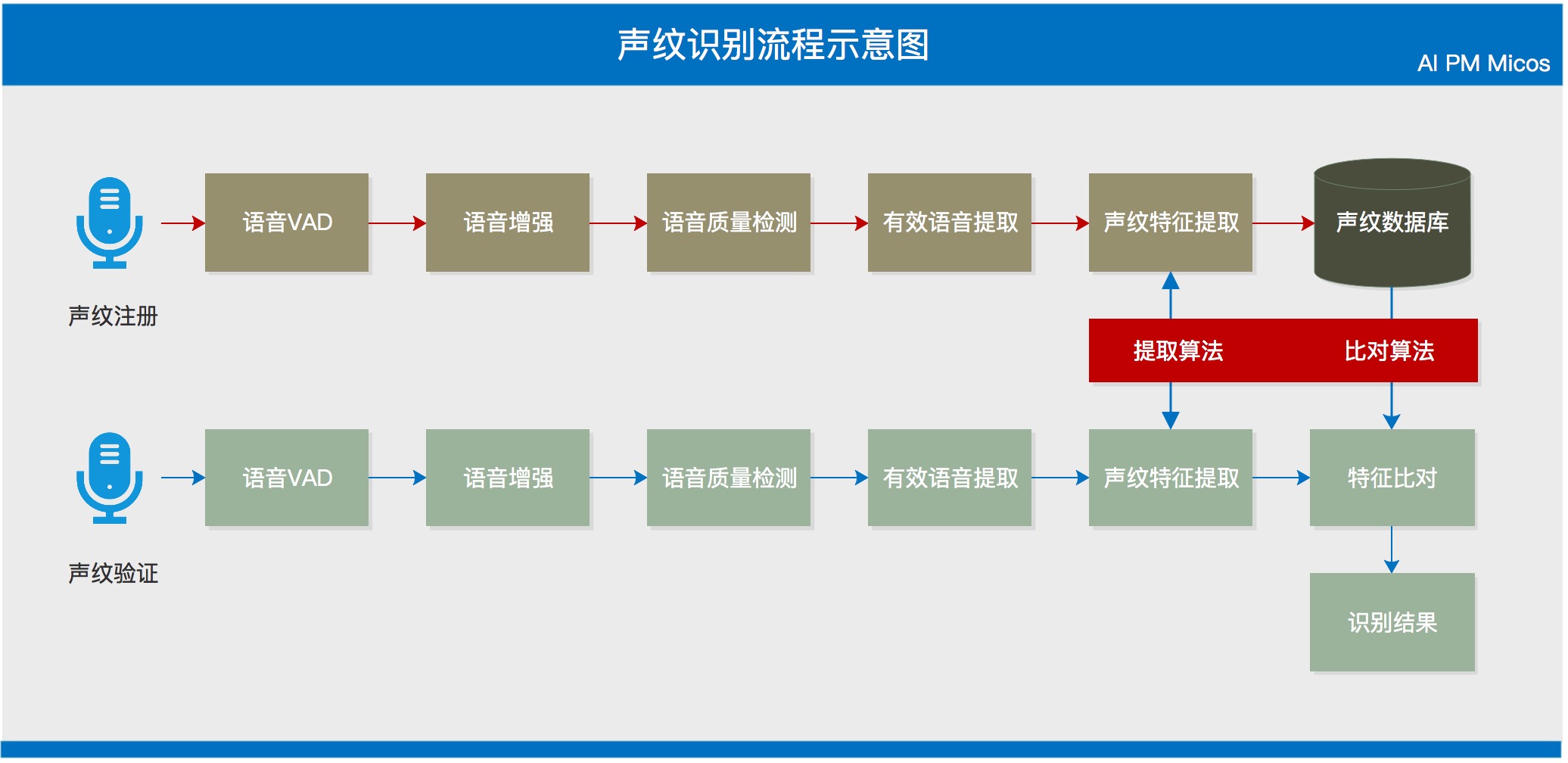
五、声纹识别的应用流程
声纹识别(VPR) ,生物识别技术的一种,也称为说话人识别 ,是从说话人发出的语音信号中提取声纹信息,从应用上看,可分为:
- 说话人辨认(Speaker Identification):用以判断某段语音是若干人中的哪一个所说的,是“多选一”问题;
- 说话人确认(Speaker Verification):用以确认某段语音是否是指定的某个人所说的,是“一对一判别”问题。
声纹识别在应用中分注册和验证两个主流程,根据不同的应用中,部分处理流程会存在差异,一般的声纹识别应用流程如下图所示:
六、声纹识别的应用场景
声纹识别作为生物识别技术的一种,有非常多好的应用场景,根据声音的特性,下面从公共安全、金融、社保、智能硬件四个领域介绍声纹识别的应用。
1、公安领域
声纹作为一种生物特征,最早在刑侦和鉴识领域成功应用。
近年来,由于互联网的发展,语音案件也呈现出井喷的趋势,在这些语音案件中,声纹识别成了唯一一种有效的技术侦破手段,通过的声纹识别和声纹大数据技术进行重点人员监管、反电信诈骗、反恐、刑事案件侦破、身份查询与核验,助力公安有效遏制与打击犯罪,构建和强化安全的社会公众环境。
2、金融
针对银行、互联网金融等各类金融及服务机构,通过声纹识别技术,提供了用户注册、远程验证、金融生物识别解决方案,大幅提高金融机构的风险防范系统安全性,强化风控能力,增加用户的安全性,防范身份欺诈。
另外在电话客服系统中,通过声纹识别技术,可实时识别出用户的身份,从而提供个性化的客户服务。
3、社保
我国针对离退休人员,每年至少需要进行一次生存状态验证,并以此为依据进行养老金的发放,目前可通过到指定社保大厅或自助终端进行生存验证,对于一些行动不便的老人家,这种方式也是非常不便利。声纹识别技术在远程身份验证中有着天然的优势,只需要一个电话(手机或固话都可以),即可完成生存验证,为参保人员提供了便利,同时也为国家节省大量成本,避免养老金流失。
4、智能硬件
在智能硬件产品中,声纹识别解决了当前智能产品只能识别用户所说的内容,而不能区分说话人身份的问题,让智能产品能够区分不同的角色,实现“听声识人”。
让系统针对性对每个人提供不同的内容与服务,让人机交互更加简单,让用户享受更轻松、更具个性化、更安全的产品体验。
七、总结
声纹识别作为最前沿的生物识别技术,随着技术的成熟,将会在越来越多的应用场景下落地,我们相信在不久的将来,在第三代身份证上,声纹将成为继指纹、人像后又一个新增的公民身份ID。声音将在我们未来的科技生活中扮演眼越来越重要的角色。
作者:Micos,昵称:不知道,在人工智能浪潮中推波助澜的产品经理,致力于用智能语音实现人与机器最自然的交互方式。
本文由 @Micos 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自unsplash,基于CC0协议









能否说明下语音识别和文本相关声纹识别流程
如何联系作者,想深入咨询一下,谢谢
社保生存验证,如果提前录音呢
声纹识别有防录音攻击算法!