
 起点课堂会员权益
起点课堂会员权益一淘网技术简介

一淘网( www.etao.com )于2010年10月9日10:39正式上线,很多同学和同行对一淘的系统架构和面临的关键技术问题都很感兴趣,这篇短文希望能给予简要的介绍。
系统架构
一淘的系统架构如上图所示。可以看到,一淘有三个数据来源:互联网、外部合作方和淘宝主站。其中,互联网数据通过crawl的方式获得,而后两者则通过feed的方式提供。
抓取系统的功能包括:网页抓取、抓取调度、域名解析、死链检测、JavaScript执行等。目前,一淘的资讯、话题、问答combo中的大部分数据都是通过抓取系统从互联网获得的。它是一淘一个重要的“原料厂”。
离线处理系统是一个功能众多、可灵活定制的Pipeline,其主要功能有:网页编码识别与转换、网页解析与内容抽取、购物相关站点发现、列表页识别、网页分类与消重、链接提取与合并、关键词提取、众多网页静态feature的提取。它是一淘的“加工厂”。
存储系统负责存储抓取系统和离线处理系统的产出,同时向这两个“厂”提供高性能、大容量的存取服务。目前我们采用的是Hadoop+HBase的体系结构,将网页、链接、图片进行了分类存放。存储系统是一淘存放原料、半成品的“核心仓库”。
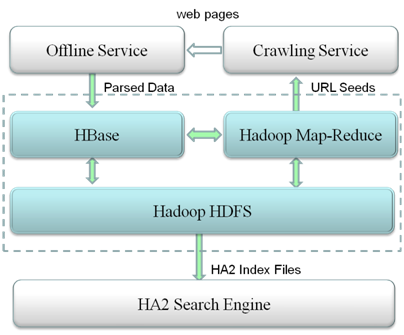
在线引擎负责对一淘前端搜索请求返回查询结果,它生成索引的数据来自存储系统。在线引擎是一淘面向用户的“成品生产车间”。值得一提的是,一淘采用了阿里集团新一代的HA2引擎技术,HA2结合了开源引擎和阿里上一代引擎技术的设计优点,在支持全文检索的同时,兼备了商品搜索的各种功能。它目前提供的主要特性有:
- 数据规模:支持的数据规模从一台机器(partition)到几百台机器;
- 更新速度:支持全量数据更新,以及最快支持分钟级的增量更新;
- 数据类型:允许用户定义各种的数据类型,从单字段到几十个字段。字段的类型可以是text, string, number等;
- 查询语法:支持简单的单一条件查询, 以及复杂的各种条件组合查询、过滤;
- 相关性计算:支持最多三阶段相关性计算,提供丰富的信息供用户自定义每一个阶段的算分方法;
- 统计导航:支持对检索到的结果做灵活的分组统计和智能导航。
一淘前端负责向终端用户展现搜索结果页,它是一淘的“门店”,设有各式各样橱窗:商品、淘吧、资讯、论坛、问答、图片、网页等。保证这个门店正常运转的机制包括:
- Bootstrap:负责查询词合法性检查、编码识别与转换、停止词和违禁词过滤。
- Query Planner:负责查询词重写(Query Rewrite)、主辅词识别、商品类目预测、Combo排序、大小写转换、同义词和多义词,等等。
- RMOD:负责向各类后端服务接口发起并发请求,并将返回结果进行整合用于页面展现。
- Cache:负责分布式缓存搜索结果数据,从而缩短响应时间,提高前端系统的吞吐量。
此外,为了一淘团队的运营效率,我们还在构建一套“从收集Query和Click日志开始,进行数据统计、关联分析、异常报警和人工调整等相关流程”的以Query为中心的运营工具。
一淘的小二们深知:如何使我们打造的这些橱窗所展现的内容具有越来越精准的 “导购相关性”,是一淘面向用户的核心价值。如何进入朝这个方向持续发展的正循环呢?我们目前的思路是:构建一套结合“Query分析”和“网页分析”的多层次排序模型,在保证相关性的前提下,灵活快速地调整模型结构以适应变化的业务需求。
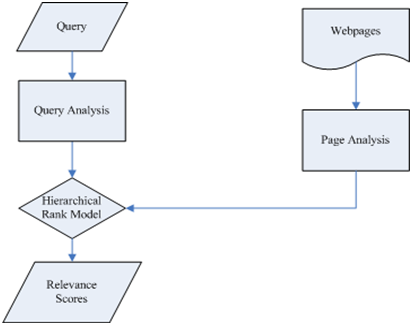
Query分析的目的是理解用户的查询意图,并将此意图转化成排序时可用的信息影响最终排序结果,如:
- 浏览型:没有明确的购物对象和意图,边看边买,用户比较随意和感性。Query例如:”2010年10大香水排行”,”2010年流行毛衣”, “zippo有多少种类?”;
- 查询型:有一定的购物意图,体现在对属性的要求上。Query例如:”适合老人用的手机”,”500元 手表”;
- 对比型:已经缩小了购物意图,具体到了某几个产品。Query例如:”诺基亚E71 E63″,”akg k450 px200″;
- 确定型:已经做了基本决定,重点考察某个对象。Query例如:”诺基亚N97″,”IBM T60″。
随着一淘用户越来越多,我们也会进一步挖掘用户查询需求,拓展意图分析种类。

网页分析期望得到:网页质量、所在站点的权威度、内容的主题词、是否为购物类文章等。这些信息将和Query分析的产出合并,一起在不同层次参与搜索结果相关性的排序过程。
一淘正在建立一套“用户行为/模型提升”的自循环体系,这其中以用户行为为主、辅以完善模型改进流程和丰富相关平台工具,期望这样可以越来越自动化地、持续地提升相关性效果,更加智能地满足用户的搜索意图。
与淘宝的关系
就淘宝目前绝对领先的市场占用率而言,能充分利用好淘宝的站内数据,对一淘来说无疑是很重要、也很幸运的。
从系统架构上讲,一淘有很多大数据量的离线计算任务是在淘宝上千台基于Hadoop的分布式计算平台上完成的,在其上获取淘宝的商品、交易和用户数据是一件非常便捷的事情,平台强大的计算和存储能力也进一步激发了一淘工程师们的想象力和创造力。比如:一淘首次将淘宝用户的搜索查询词和直接购买的宝贝相关联,并实现了分钟级别的引擎更新,这为用户们提供了最及时导购风向标。此外,一淘还直接调用了很多线上服务的接口,例如:宝贝搜索、产品搜索、合并同款等。
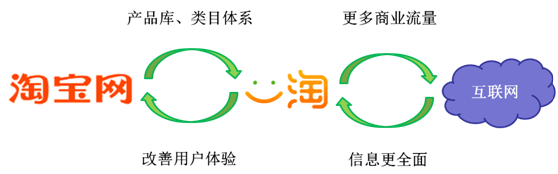
从产品服务上讲,一淘是淘宝主站与全网电子商务网站联系的重要纽带。简单地讲,淘宝站内数据(如:产品库、类目体系)可以保障一淘的导购搜索相关性有非常正向的促进作用;一淘通过Open Search和外网商品信息抓取,也可以为其他电子商务网站带去更多高质量的商业流量;而互联网的商品、资讯、论坛等信息又有助于一淘的搜索结果更全面、信息更权威;一淘搜索质量的提高反过来可以帮助改善淘宝的用户体验(如:无结果页、购前调研),一淘的用户行为分析和趋势预测也可以作为淘宝运营收集反馈信息的重要通道。
结束语
通过上面的介绍,我们不难理解一淘对于所采用技术的实用性、高效性和扩展性方面都会有业界领先的要求。这其中主要涉及的领域包括:
- 海量网页的抓取和抽取
- 分布式存储和计算平台
- 大规模数据(网页/商品)处理与分析
- 购物搜索相关性体系
- 高性能可定制的全文检索引擎
- 快速响应业务需求的前端架构
这些技术方向,我们会在今后的Blog中进行进一步的展开、更深入的阐述。
来源:http://www.searchtb.com/2010/11/etao-tech-overview.html






- 目前还没评论,等你发挥!


