
 起点课堂会员权益
起点课堂会员权益基于内容、位置与关系的探索模式

信噪比,是指有用信息与无用信息的比值。如果信息能够有效过滤,信噪比高(甚至非常高),那么信息爆炸不仅不是坏事,反而还将大大拓展我们的眼界,提高生活的深度。
Flickr探索
与此同时,我们越来越倾向于一个彻底个性化,同时做好隐私保护的综合平台。喜新厌旧是人的天性,这就注定了“个性化”不能只停留在“定制”的范畴,还应该包括“探索”。
社交网络的现状
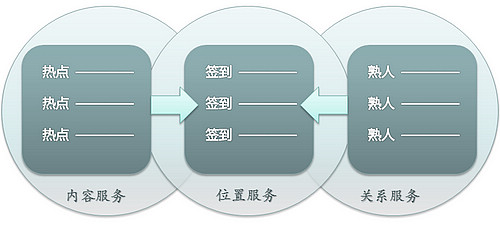
社会化网络服务
三层服务
在线社区经过这几年的沉淀,目前有以下三种层次的服务:
– 内容服务 基于内容的获取与筛选,形成圈子,实现价值,达成共鸣。
– 位置服务 通过移动互联网进行签到,分享即时地理信息。
– 关系服务 通过互联网构建与增强人际关系。
服务特征
很明显,三者都具有不可比拟的代表性。不过可以看到,它们之间又有着如下特征:
– 相互孤立 我喜欢摄影,但不知道周末在朋友(关系)家旁的公园(位置)有一个摄影小组(内容)的聚会。
– 紧密相联 同学(关系)在武汉广场(位置)看见一条不错的男式运动裤,发布到微博(内容)上,正在武广吃饭的我也想过去看看。
– 各自矛盾 友邻在豆瓣(内容)上发起了同城活动(位置)参与PHP语言初级讨论,不在同城的我好心分享出去,结果人人网上的同学(关系)抱怨我“刷屏”。
多维分析
信息一多,自然存在过滤的问题。但我认为,与其过滤,不如直接显示相关信息。随着时间的推移,相关信息也必然膨胀;这时应该毫不犹豫、大刀阔斧地砍掉,只显示最相关的信息。
豆瓣有各种有意思的小组,坐拥无数后,面对海量帖子,头都是大的。那么,为什么不把最相关、最热门的提取出来?比如,附上一份“晚间精选话题(5个)”。即便是随便看看首页,不打算进一步浏览,看到喜欢的话题,也不能阻止你充满好奇的手吧。
标签分析
新浪微博的标签分析
经过用户亲自提取的“个性化标签”当之无愧成为最具分析价值的数据。但目前新浪微博里“感兴趣的人”的推荐显然只做了第一步,没有在发文量、粉丝数量、名人与否、原创比例上进行相关性匹配。
关键词分析
一种是语境(语义、环境)分析。最好的例子莫过于谷歌关键词广告,随处可见,精确度也在不断提高。以前每每在外文网站看到中文总是兴奋不已,可惜是谷歌广告。
另一种是词频分析;基于用户的内容不愁没有文字。那么,结合新闻热点抓住它们,进行词频统计,自然能分析出用户说话的口味。毫无疑问,臭味总是相投的。
关键词分析依赖对自然语言的处理,也是标签分析之外强有力的助推器。
群组分析
互联网是虚拟的,但我们每个人都是独立的。我们面对不同的人群以不同的面孔,一来强化身份,二来避免尴尬。我们的每个面孔都是真实的,但分享给不同的人群显然也是不合适的。

新浪微博的分组
给联系人分组不仅能有过滤话唠的疗效,也能立体地展现其不同的角色。
互动程度分析
互动的人一定比其他人更亲密,有关你的新鲜事他(她)理所当然希望成为尝鲜第一人。
转发分析
人人网上几乎都是分享让我们厌恶,因为我们想了解关于他们自己的信息;而微博转发力量的强大,缘于对内容的钟爱。由此来看,转发中所涉及的人、事和博主都可以成为分析对象。
新版豆瓣采纳了分组,而取消了“书影音”的分类,正是如此。
时间线分析
正如谷歌阅读器里的“神奇排序”一样,把疏密的时间线整合为一条均匀的故事情节。这样,在时间有限的情况下,不会漏过好友的最近消息。此办法不适合新闻媒体。
其他元数据分析

搜搜问问的推荐
尽可能地共享平台信息。比如我在QQ空间的个人资料里提及“羽毛球”,在搜搜问问里,推荐我订阅该词条。
必要准备
多维分析后,已经尽可能搜集了用户的想法与口味,接下来,进行准备工作。
反向分析
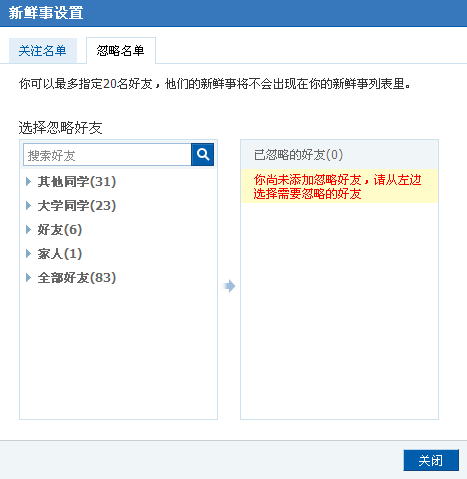
人人网的忽略名单
通过主动标记“不喜欢”来过滤冗余信息。这些信息的类型包括:
– 某人 出于个中原因,不希望该人出现在时间线上。
– 某事 比如,男生对“化妆品”不感兴趣,屏蔽此类讯息。
– 话题 比如,对“360大战腾讯”毫无兴趣,屏蔽之。
– 某类 比如,对“非原创” 无爱,屏蔽之。
就大量的友邻反馈,豆瓣电台的“垃圾桶”是个不错案例。
隐私保护
以腾讯微博为例
月光博客解读说,QQ上78%的用户本心是拒绝双向关注的,或者说78%的时候,人们不希望双向关注。从结论来看,尽管腾讯拥有了着无敌的用户基数,他可以让每个QQ号都是成为微博用户,但是腾讯本身覆盖的相互关系反而会成为用户的心理阻碍。在超过3/4的时候,人们对此有所顾虑。
看来,垄断和捆绑对于利基市场而言可能并不是一件好事,如果抛不开沉重的隐私包袱。
以脸谱为例

脸谱的群组功能
随着脸谱用户好友的数量呈几何上涨趋势,身份角色也一直困扰着用户。面对这种情况,脸谱改进了“群组”功能,能有选择地与朋友分享信息。这样,请“病假”出去约会的消息,上级就不得而知了(好吧,这不是个好例子)。
群组本身的隐私保护也做得相当完善,包括开放、封闭和隐秘三种模式,详见文末参考资料7。
选择性开放
拿地理信息来说,对于不同的关系,不同的场景,提供位置的精度是不一样的。国内来说,最大的单位是省份,其次是城市、区、街道。任何跨距大的签到信息,对于收到接受人来说,都是冗余。比如,常居武汉的张三和常居杭州的李四是老朋友,他们之间的任何签到都没有具体意义;只有当一方去对方城市做客时,才能体现价值。可惜,位置服务仍在不加区分、不遗余力地到处散播地理信息,就我个人而言,是不甚反感的。
Live中令人困惑的隐私设置
当然,就隐私保护精度来讲,正如《一路求实》所言,能不把选项抛给用户,就尽量不要徒增麻烦。
跨服务探索
探索模式
目前已有的探索不在少数,比如谷歌阅读器、Flickr、人人网等。可惜,它们探索的内容仅仅局限于特定服务:内容的探索内容,关系的探索关系。豆瓣同城点亮了“探索”的光芒,内容与位置服务得以结合,发掘出更有意思的模式。
“单向关注越高的平台,社交属性越低,而双向关注越高,社交属性越高”,这条规律与位置关系联系起来,或许正好适合跨服务探索。
朋友总是不嫌多的,而人们的社交活动范围往往局限在常居城市。同时,相互关注的好友往往更加亲密。因此,在同城范围内,相互关注的好友的线上线下交互应该更为频繁,成为传统社会上的“朋友”(而不仅仅是网友)的几率更大。结合多维分析中提到有关的交互条目,可以得到一份具体的“神奇好友名单”。
以神奇名单为本,通过位置把内容和好友联系起来,探索的内容将十分丰富。

豆瓣猜
“探索”可以以分组或者单页(比如豆瓣猜)的形成呈现;同样,务必保持简洁。宗旨应该是不求数量,只求你喜欢。
商业价值
所有的广告都有价值,因为每个选择都有价值;只有无关、无用和劣质的广告让人反感。我们满大街购物时,最喜于乐见的莫过广告了(特别是打折广告)。当我们的雄心不得壮志时,除了政治,还可以大侃各种品牌。
根据ROI Research在今年4月对推特用户进行的调研得出,33%的用户每周至少谈一次品牌。同时,网络营销,尤其是微博营销也在不断加强,这些都可以反映广告(品牌)的价值。
自己说自己好,别人是不信甚至不屑的;水军这种东西也越来越容易发现并惹人厌恶。品牌最忠臣的推广员永远都是客户自己;而用户最信任的推销人员莫过于亲朋好友。据此,营销人员大可以收集已有客户的良好反馈,插播到探索模式中来。
打个比方,我觉得花格子羊毛衫很有范儿(内容)。在探索模式下,社区里的好友,更或者我的朋友(关系)提出,就在我上班地点附近实体店(位置)的羊毛衫正在打折,而且质量不错。由于羊毛衫的信息本身是真实的(来自于客户的反馈),我收到的信息来源是可靠的(不信朋友信谁?),该信息也正好满足我的需求。如此,天时地利人和,我购买的可能性相对较大。
实体店和服务商如何分成,我的朋友能享受到怎样的实惠,则待具体考究了。
参考资料
1 MiniJuly 《社会化网络:关系or内容》 http://www.minijuly.com/?p=884
2 范路 《LBS中的信息服务》 http://lukefan.com/?p=271
3 月光博客 《杂谈新浪微博、腾讯微博、百度说吧》 http://www.williamlong.info/archives/2337.html
4 《成功营销》杂志10月刊文 《4Food汉堡:你定制,你推广》 http://www.marketing-life.cn/?p=3273
5 royaland 《社会化网络设计的10大要点(案例)》 http://hi.baidu.com/royaland/blog/item/8c33540ab5a08e1094ca6b62.html
6 张悟空爱美丽的微博 http://t.sina.com.cn/1809845301/zF0t1varba
7 脸谱官方网站 帮助中心 《群组》条目 http://www.facebook.com/help/?page=1193
来源:http://cuikai-wh.com/archives/951






- 目前还没评论,等你发挥!


