
 起点课堂会员权益
起点课堂会员权益三分钟了解协同过滤算法

计算用户/物品相似度,以相似度作为权重,对不同物品进行评分预测,从而实现物品。
什么是协同过滤
先举个生活中的场景,你想听歌却不知道听什么的时候,会向你身边与你品位类似的朋友求助,从而获得他的推荐。协同过滤(Collaborative Filtering,简称CF)就像与你品味相近的朋友,通过对大量结构化数据进行计算,找出与你相似的其他用户(user)或与你喜欢的物品(item)相似的物品,从而实现物品推荐。
协同过滤分为两类:基于用户的协同过滤(User-Based CF)和基于物品的协同过滤(Item-Based CF)。结合前文的介绍便不难理解分别的应用场景。
计算相似度之前需要先准备一些如下表所示的数据集:
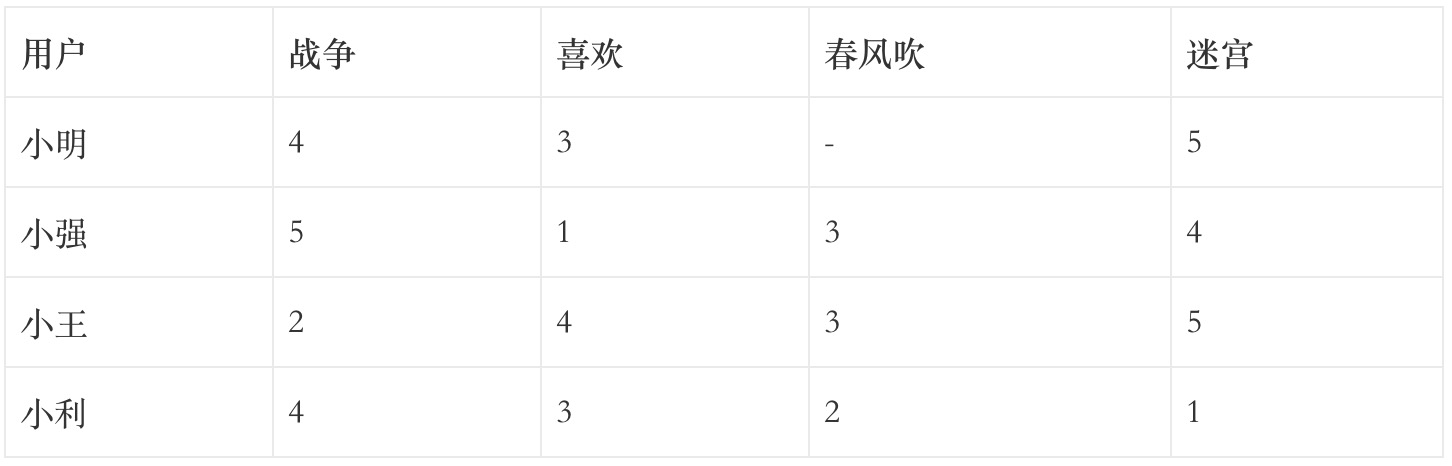
它是一种表达不同人对不同物品偏好的方式,例如音乐应用可以用0和1表示喜欢不喜欢和喜欢。
User-Based CF
如果你和小明对于音乐的品位相似,假如小明喜欢听Adele,那么你也有可能喜欢听。好了,问题来了:
- 如何衡量两个用户是否相似?
- 如何根据相似用户推荐物品?
相似度计算
相似度通过如下公式计算得到:
y = f(data, user1, user2)
其中,data就是前文提到的数据集,user1和user2表示要比较的两个用户或物品。书中主要介绍了两种相似度计算函数:欧几里得距离评价、皮尔逊相关度评价。
(1)欧几里得距离
它以经过人们一致评价的物品为坐标轴,然后将参与评价的人绘制到图上,并考察他们彼此间的距离远近。输出满足y∈[0,1],1表示user1和user2具有相同的偏好,0表示user1和user2偏好不同。
(2)皮尔逊相关度
它是比欧几里得距离更复杂的一种表示相似度的方法。用于判断两组数据与某一直线拟合程度,在数据不是很规范的时候(比如,影评者对影片的评价总是相对于平均水平偏离很大时),会倾向于给出更好的结果。皮尔逊可以简单理解为cos(x)函数,所以其输出满足y∈[-1,1],1表示user1和user2具有相同的偏好,0表示user1和user2偏好不同,-1表示user1和user2偏好负相关。如果难以理解可以参考:如何理解皮尔逊相关系数(Pearson Correlation Coefficient)?
由于本人高数上下都是勉强及格,对于这两个函数理解的也不深,所以没办法深入浅出的解释,不过只要知道每种计算方法的适应范围和局限性就好了。
推荐物品
第一个问题解决了,来看看如何推荐物品。如果只是把相似用户喜欢的物品推荐给被推荐者,未免过于草率,而且又该如何选择相似用户呢。
(1)推荐算法
结合前文数据集进行说明:
- 计算出所有用户两两之间的相似度;
- 指定一个被推荐者:小明;
- 找出其他用户评价过且被推荐者未评价的物品:春风吹;
- 以被推荐者与他人的相似度作为权,将权与其他用户对该物品的评分相乘;
- 【x春风吹】一列值之和除以相似度一列值之和,最终结果(2.875)便为预测的小明对于春风吹的评分。
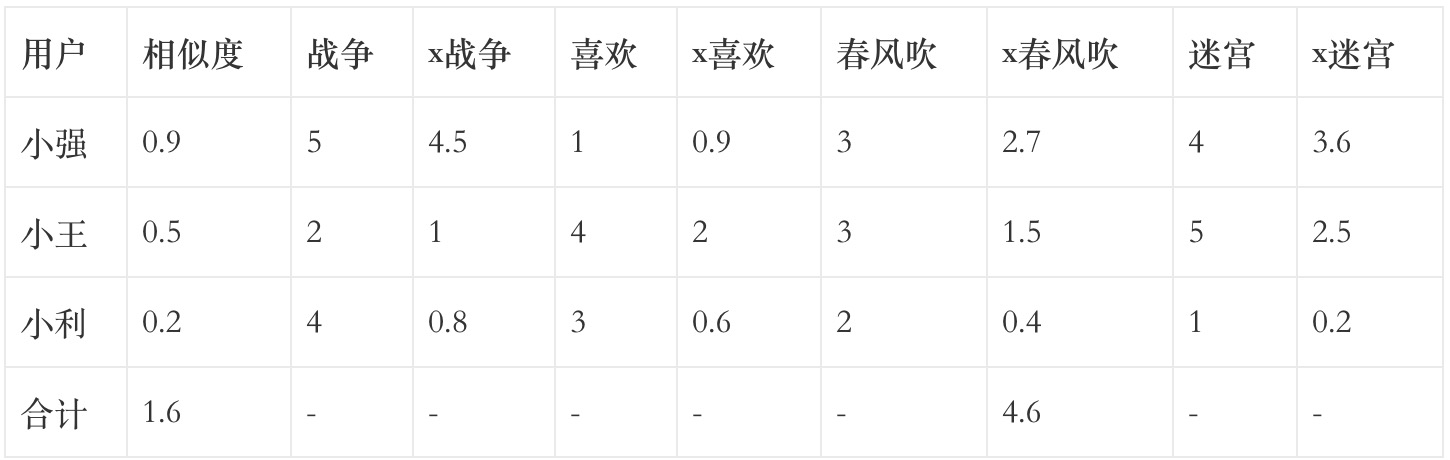
注:相似度随便写的,并非计算所得。
至此可以给出推荐算法公式:
y = f(data, user, sim)
其中,data就是前文提到的数据集,user为被推荐者,sim为相似度计算函数,可以根据场景不同选择不同的计算函数。从输出总选择评分较高的物品推荐给用户,从而实现物品推荐。
Item-Based CF
基于物品的推荐思路是:根据你评价过的物品,找出与其相似的物品。
相似度计算
方法与User CF相同,只是我们需要把前文数据集进行转置,并计算所有物品两两之间的相似度。
推荐物品
如同User CF,我们不能简单的推荐与我们偏好物品类似的物品。
(1)推荐算法
- 计算出所有物品两两之间的相似度;
- 指定一个被推荐者;
- 找出被推荐者评价过的物品;
- 以被推荐者评价过的物品与其他物品的相似度作为权,将权与被推荐者对该物品的评分相乘;
- 【xXX】一列值之和除以相似度一列值之和,最终结果便为预测的被推荐者对于其未评价过物品的评分。
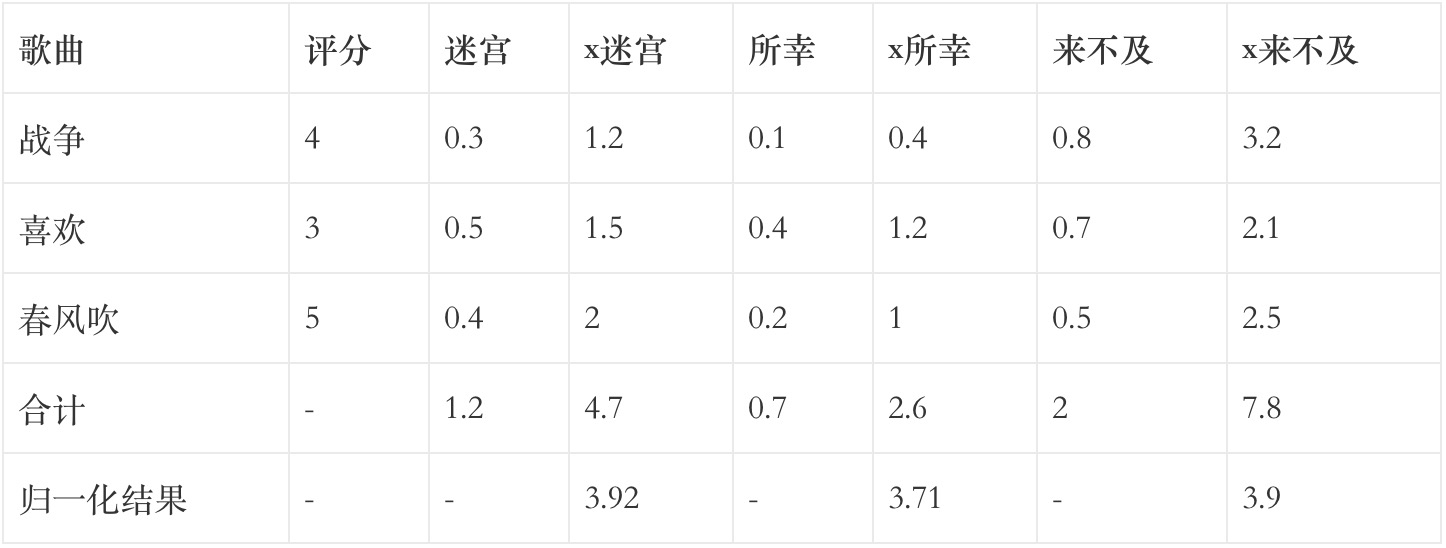
注:相似度随便写的,并非计算所得;并且根据说明需要增加了一些音乐。
至此可以给出推荐算法公式:
y = f(data, itemMatch, user)
其中,data就是前文提到的数据集,user为被推荐者,itemMatch为所有物品两两之间相似度的数据集,计算itemMatch时,可以根据场景不同选择不同的计算函数。从输出总选择评分较高的物品推荐给用户,从而实现基于物品的物品推荐。
如何选择?
1. 基于物品进行过滤的方式要过于基于用户的方式,不过它需要维护物品相似度表的额外开销,这也是它快的原因;
2. 对于稀疏数据集,Item-Based CF效果优于User-Based CF;
3. 对于密集数据集,两者效果几乎相同;
4. 最重要的是,结合应用场景选择合适的方法。
一句话心得
我对于协同过滤的理解是:
计算用户/物品相似度,以相似度作为权重,对不同物品进行评分预测,从而实现物品。
本文由 @会编程的狗 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议






- 目前还没评论,等你发挥!


