
 起点课堂会员权益
起点课堂会员权益智能搜索联想的需求分析以及解决方案
在一些特殊行业,如果可以在特定场景下进行智能搜索和联想的改造,那将能提高工作的效率。那么应该怎么搭建对话机器人,重点输入智能联想功能呢?
人机交互无非文字、语音、图像。现如今对话机器人越来越普及,各类智能音箱也如雨后春笋般上市,图像识别最多的还是处于手势指令阶段。最超前的猜想是机器人能够和人心有灵犀,识别人的思维想法,能够想我所想,这样人就可以随心所欲了。
当然这个实现过程还很长,但是如果能够实现提前预知人的想法那就会更智能一些。
看如下药品名称:诺氟沙星、甲氧氯普胺、氢氧化铝、多潘立酮、硫酸沙丁胺醇、喷托维林,字虽然不难写,但是用拼音打字要一个个打。这对于医生来说,每天要打上数百遍,就比较浪费时间了。
今年5月9日下午,搜狗输入法正式推出医生版。这款输入法专为广大医务工作者打造,就是为了帮助广大医生群体实现高效输入而生,拥有海量医疗词库,与医疗场景进行精准匹配,很大程度的提高了医生的输入效率。
如下图所示:

搜狗输入法医生版具有强大的超级联想功能,可以提供多个医疗专用名词,无论是专业医生还是护士、药剂师等医务工作人员,再复杂的专业词汇都能通过搜狗输入法一气呵成。
比如:输入“zuoyang”后,候选词汇中就会出现“左氧氟沙星”、“左氧氟沙星注射液”等词,然后一键选择快速输入,节省很多选字时间。
同理,在一些特殊行业完全可以在特定场景下进行智能搜索和联想的改造。
例如:以下保险产品名称,对于在人机对话型智能保险机器人中出现的频率是比较多的。
- 国寿福禄宝宝两全保险(分红型);
- 国寿康宁定期健康保障计划;
- 康健一生(多倍保)终身重大疾病保险;
- 同方全球“康健一生”终身重大疾病保险;
- 史带“众悦人生”白领健康保障计划;
- 泰康e顺女性疾病保险;
- 安联“致青春”重疾保险计划。
那么应该怎么搭建对话机器人重点输入智能联想功能呢?
其实对话型机器人,就是一个现代型的智能搜索引擎,要想变得更智能,必须建立更好的建模搜索结果的语义相关性和更直接地给用户答案。
我们先说语义相关性,就是不论查询词是否包含在相应文档中,只要查询词与文档拥有语义相关性,就能将其找到。就是用户在搜索框里只是输入单个汉字、单词、拼音简写、拼音以及一段文字时系统自动给出用户更加准确的关键词,让用户可以快速的知道自己要搜索的主题。
为了让用户更快速的输入自己想要了解的保险产品的相关问题,可以基于solrcloud实现保险产品智能搜索联想模块。可以用一种基于solr前缀匹配,查询关键字智能提示(Suggestion)实现。
所以解决以上问题,我们可以用以下解决方案来实现:
需求分析
(1)支持前缀匹配原则
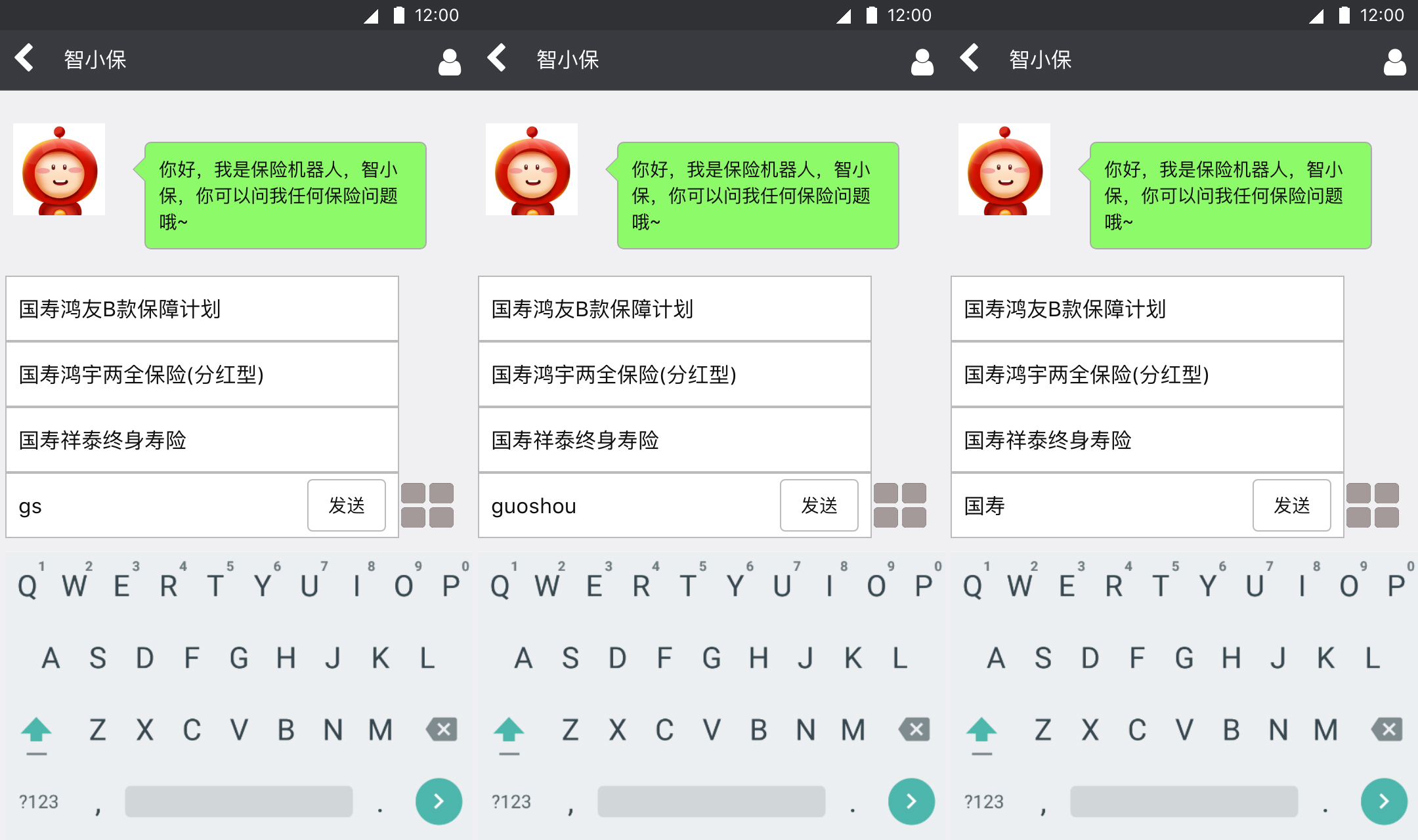
在搜索框中输入“国寿”,搜索框下面会以同方为前缀,展示“国寿祥泰终身寿险”、“国寿鸿宇两全保险(分红型)”、“国寿鸿友B款保障计划”等等搜索词;输入“太平”,会提示“太平福运金生B款年金保险”、“太平福盈一生终身年金保险”、“太平康爱卫士老年防癌疾病保险”等搜索词。
(2)同时支持汉字、拼音输入
由于中文的特点,如果搜索自动提示可以支持拼音的话,会给用户带来更大的方便,免得切换输入法。比如:输入“renshou”提示的关键字和输入“人寿”提示的一样,输入“太平”与输入“太平”提示的关键字一样。
(3)支持大小写输入提示
比如:输入“e生保”或者“E生保”都能提示出“平安“e生保”2017版”。
(4)支持拼音缩写输入
对于较长关键字,为了提高输入效率,有必要提供拼音缩写输入。比如:输入“rs”应该能提示出“人寿”相似的关键字,输入“tp”也一样能提示出“太平”关键字。
(5)基于用户的历史搜索行为,按照关键字热度进行排序
为了提供suggest关键字的准确度,最终查询结果,根据用户查询关键字的频率进行排序,如:输入[太平,taiping,tp,] —> [“太平福运金生B款年金保险“(f1)”太平福盈一生终身年金保险“(f2)”太平康爱卫士老年防癌疾病保险”(f3)…],查询频率f1 > f2 > f3。
解决方案
(1)关键字收集
当用户输入一个前缀时,碰到提示的候选词很多的时候,如何取舍,哪些展示在前面,哪些展示在后面?
这就是一个搜索热度的问题。用户在使用对话框询问问题时,会输入大量的关键字,每一次输入就是对关键字的一次投票,那么关键字被输入的次数越多,它对应的查询就比较热门,所以需要把查询的关键字记录下来,并且统计出每个关键字的频率,方便提示结果按照频率排序。
搜索引擎会通过日志文件,把用户每次检索使用的所有检索串,都记录下来,每个查询串的长度为1-255字节。
(2)汉字转拼音
用户输入的关键字可能是汉字、数字、英文、拼音、特殊字符等等,由于需要实现拼音提示,我们需要把汉字转换成拼音,java中考虑使用pinyin4j组件实现转换。
(3)拼音缩写提取
考虑到需要支持拼音缩写,汉字转换拼音的过程中,顺便提取出拼音缩写,如:“taiping”—>”tp”。
(4)技术方案: Trie树 + TopK算法
Trie树即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。
它有3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同。
它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。Trie是一颗存储多个字符串的树,相邻节点间的边代表一个字符,这样树的每条分支代表一则子串,而树的叶节点则代表完整的字符串。和普通树不同的地方是,相同的字符串前缀共享同一条分支。
例如:给出一组单词inn,int,at,age,adv,ant,我们可以得到下面的Trie:

从上图可知,当用户输入前缀i的时候,搜索框可能会展示以i为前缀的“in”,“inn”,“int”等关键词,再当用户输入前缀a的时候,搜索框里面可能会提示以a为前缀的“ate”等关键词。如此,实现搜索引擎智能提示suggestion的第一个步骤便清晰了,即用trie树存储大量字符串,当前缀固定时,存储相对来说比较热的后缀。
TopK算法用于解决统计热词的问题。解决TopK问题主要有两种策略:hashMap统计+排序、堆排序。
hashmap统计:先对这批海量数据预处理。
具体方法是:维护一个Key为Query字串,Value为该Query出现次数的HashTable,即hash_map(Query,Value),每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可,最终在O(N)的时间复杂度内用Hash表完成了统计。
我们也可以为关键字建立一个索引collection,利用solr前缀查询实现。solr中的copyField能很好解决我们同时索引多个字段(汉字、pinyin、abbre)的需求,且field的multiValued属性设置为true时能解决同一个关键字的多音字组合问题。
效果如下图所示:
作者:老张,宜信集团保险事业部智能保险产品负责人,运营军师联盟创始人之一,《运营实战手册》作者之一。
本文由 @老张 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议









随着日志数据的增加,前缀树性能问题就凸显出来了。这个方式比较low
K-top算符没太看懂,是不是要有代码基础才行?
厉害厉害。。