
 起点课堂会员权益
起点课堂会员权益AI产品经理需了解的技术知识:语音识别技术(2)

本文章主要介绍了语音识别技术语的算法包括动态时间调整、隐马尔可夫模型、BP神经网络,目的是帮助PM了解语音技术方面的知识,有助于语音类相关产品的设计~
语音信号是一种短时平稳信号,即时变的,十分复杂,同时也携带了很多有用信息,包括个人信息、语义等。因此特征参数提取的准确率,直接影响语音识别结果的好坏。
信号的预处理就是为了保障特征参数提取准确性的前期工作,这部分的介绍见上一篇文章 :AI产品经理需了解的技术知识:语音识别技术(1)。
语音识别算法
语音识别系统的本质是模式识别系统,而语音识别的过程就是根据模式匹配原则,按照一定的相似度法则,使未知的模型和模型库中的某一个参考模型获得最大匹配度的过程。
常见的语音识别算法主要有:模版匹配法,如动态时间规整(DTW);随机模型法,如隐马尔可夫模型(HMM);基于人工神经网络(ANN)的算法。
1. 动态时间规整
在孤立词识别中,最为简单有效的方法就是采用DTW算法,这个方法解决了相同词但发音长短不同时的匹配问题。
首先,孤立词是什么?
我个人的理解就像是自然语言处理中的分词,即把一段文字划分为若干单词去模板库匹配。区别在于:一个是文字,一个是语音。
文字是依据句法、语法、语义划分,而语音则是通过端点检测算法确定语音的起点和终点(端点检测算法见上一篇文章)。
其次,得到孤立词后,会出现一个问题,如A同学“你好”中的“你”字发音拖长,B同学“再见”的“再”字的发音很短。那么该如何匹配到参考裤中的“你好”和“再见”呢?
这个例子就好比下图(手手工示意图,大家看看就好):
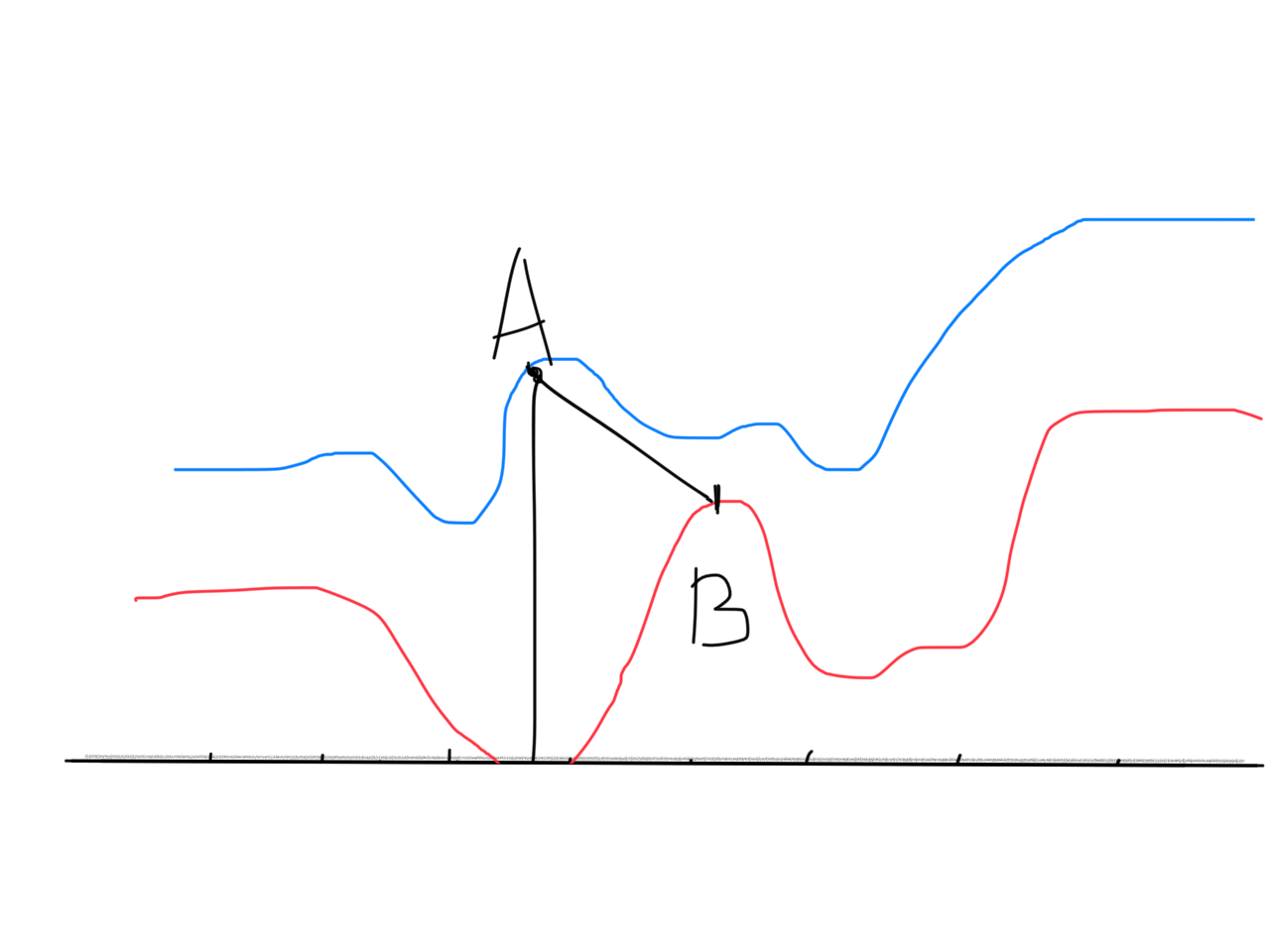
很显然,对于说话速度差异的限制,不符合实际语音的发展情况,需要一种更加符合实际情况的语音时间规整方法。DTW就是通过把时间序列进行延伸和错单,来计算两个时间序列之间的相似性。
2. 隐马尔可夫模型(HMM)
隐马尔可夫模型是一种统计模型,在语音识别、自然语言处理问题广泛应用。语音信号可看作一个可观察序列,微观上它在足够小时间段上的特性近似于稳定,宏观上可看作一次从相对稳定的某一特性过渡到另一特性,如:A->B->C->D。
假设产生一个语音时,分别经历4个状态,分别是A- >B->B-C-D-A-D。所有的状态可以看作是x=状态,y=时间的矩阵Q[4][6],通过概率算法,计算出在4096(4*4*4*4*4*4)种情况中的最佳路径ABBCDAD。
3. 人工神经网络(ANN)
人工神经网络是计算智能中的重要部分之一,是有大量简单的基本元件-神经元相互连接,模拟人的大脑神经处理信息的方式,进行信息并行处理和非线性变换的复杂网络系统。
基于ANN的语音识别系统通常由神经元、训练算法、网络结构三大要素构成,具有高速的信息处理能力,并且有着较强的适应和自动调节能力,在训练过程中能不断调整自身的参数权值和拓扑结构,这也是AI产品与传统互联网产品的的区别。
下面以BP神经网路为例:
(1)什么是BP神经网络?
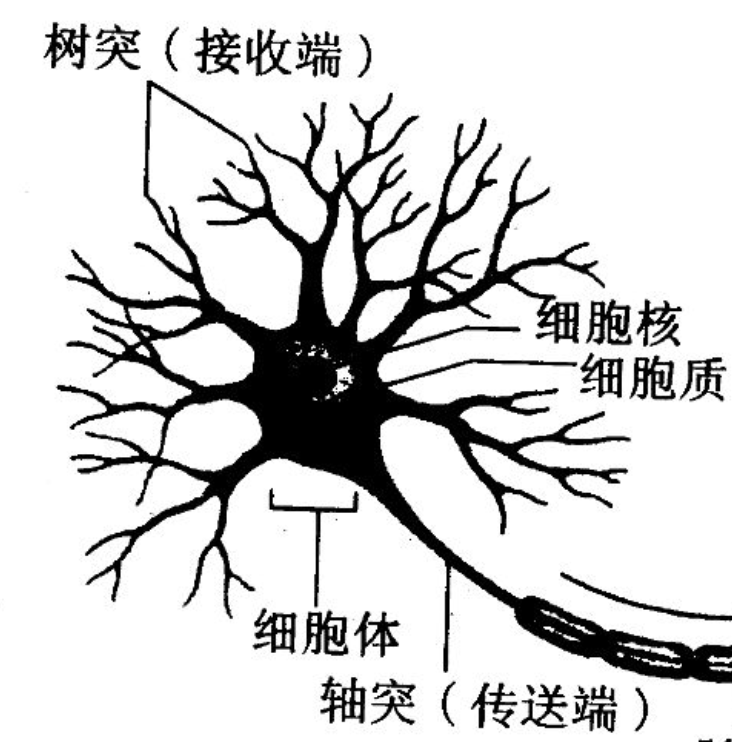
人工神经元是对人或者其他生物的神经元细胞的若干基本特性的抽象和模拟,生物神经元主要由细胞体、树突、轴突组成,树突和轴突负责传入和传出信息,兴奋性的冲动沿着树突抵达细胞体,在细胞膜上累积形成兴奋性电位。
相反,抑制性冲动到达细胞膜则形成抑制性电位,两个电位进行累加,若代数和超过阈值,则神经元产生冲动。
模仿生物神经元产生冲动的过程,可以建立一个人工神经元数学模型,包括输入向量、输出值、激发函数、阈值、权值(神经元与其他神经元的连接强度)。神经元则是一个计算和储存单元,将计算结果暂存并传递给下一个神经元。
(2)BP神经网络是如何学习的?
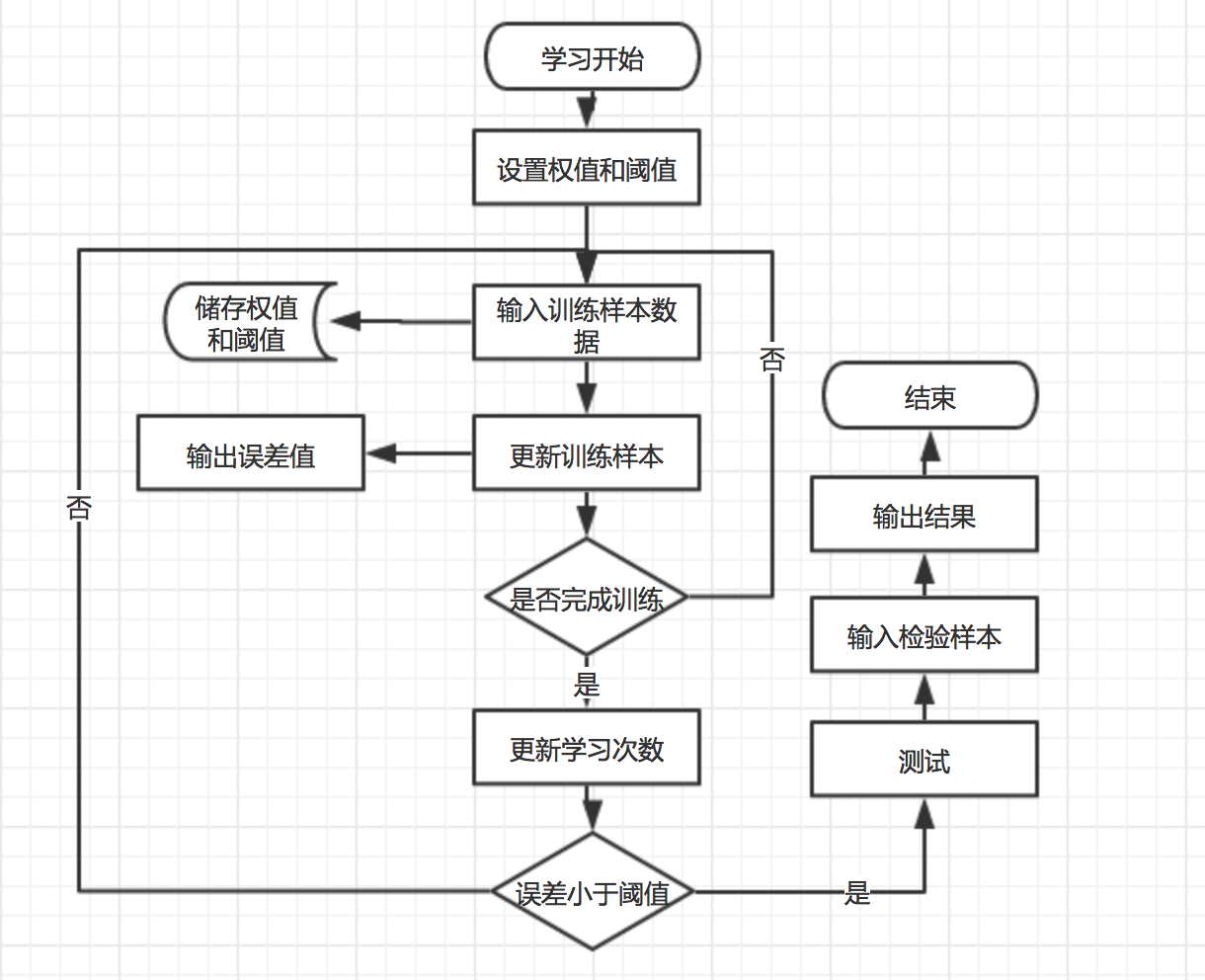
BP神经网络的学习过程由两部分组成,分别是正向传播和反向传播。
- 正向传播时,输入信息从输入层经处理后传向输出层,每一层神经元只对下一层的神经元的状态有影响。如果在输出层得不到期望的输出,则进入反向传播。
- 反向传播时,误差信号从输入层向输入层传播并沿途调整各层间的权值。经过不断的迭代,最后将误差尽可能降低。
如图所示:
人工神经网络通常是针对静态模式设计的,语音信号是一个时变信号,而且它的时变特性也是语音理解的一个重要特征——由于发音快慢节奏不一样,发音时音节长短不会完全相同。
而大多数神经网络输入结构是固定的,采用BP算法,识别率并不是很高,通常需要将人工神经额网络做一些必要的修正。
本文由 @猪不会飞 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议










我们公司也要做一个新的AI产品,可以加您请教一下嘛
app产品想转ai,可以请教您么?
我们公司最近想做个ai产品。可以请教你吗?
可以互相学习哈~