
 起点课堂会员权益
起点课堂会员权益数据和算法的相爱相杀(三):常见的数据分类算法
和上一篇一样,我们不讲各个算法的数学原理和编程方式,作为给PM看的文章,我将各个算法原理讲解清楚,以及算法的应用的场景、优点缺点、注意事项。
以下是数据与算法相爱相杀的第三篇,常见的数据分类算法。
数据分类在业务中应用无处不在,如果我们要开展多元化的服务、差异化的营销,就需要对用户群体进行分类,比如:通过对用户收入的分类,我们找到高净值人群,我们可以直接向他们推荐我们的产品或者VIP服务。
如果我们还有年龄的数据,我们可以向20-50岁之间的高净值人群推荐我们职场的礼包,沿着这样的路径往前走,我们发现我们可以将更多维度的数据加入其中,我们的划分的群体更加具体,我们对他们可以采取的措施也可以更加切合、得当。
如果数据量达到我们肉体难以cover的地步,基于大数据量的分类算法就有了用武之地了。数据分类是一种典型的监督学习,需要我们给出分类结果,然后建立起输入和输出之间的模型。
和上一篇一样,我们不讲各个算法的数学原理和编程方式,作为给PM看的文章,我将各个算法原理讲解清楚,以及算法的应用的场景、优点缺点、注意事项。各位如果想进一步了解可以留言,或者网上找些材料。
数据分类可以用到算法比较多样,比如:决策树、贝叶斯网络、神经网络、遗传算法等,不同的场景下不同的算法有不同的效用。但是分析的过程无外乎训练过程、识别过程两种。
- 训练过程:是从数据库中找到训练集,然后从训练集中进行特征选取,对分类模型进行训练,然后形成分类器。
- 识别过程:是先将待识别的新样本进行特征选取,然后利用分类器进行分类识别。
基于贝叶斯的数据分类
贝叶斯公式想必大家都比较了解,两百年前英国数学家贝叶斯的成果,如今机器学习里很多都是将贝叶斯公式作为基础原理。
朴素的贝叶斯就是揭示了,假如事件A发生的概率已知,事件B发生的概率已知,事件B在事件A发生的情况下发生的概率已知,那我们就知道事件A在事件B发生的情况下概率是多少。
公式如下:
P(A|B)=P(B|A) *P(A) / P(B)
在实际应用过程中,A一般是我们想要预测的概率,A包含的情况我们是清楚地,比如:预测游戏中预测是否有辱骂别人(有 或 无),B即是某一个辱骂词汇的出现的概率,假如给我们一定的语料,我们就可以得出在某名玩家打出某个词汇的时候,他被判定为辱骂的概率,如果我们设定一个阈值,我们就可以对其发出辱骂警告了。
通常我们进行一个企业级的分类流程需要经过数据准备、分类器训练、分类器评估、分类识别。
- 数据准备:一般是语料库或者其他原材料的准备,这个阶段主要需要人工对语料进行分类,分类的清楚,合理对分类器的质量至关重要。
- 分类器训练:这个阶段有计算机完成,主要是计算各个属性(事件包含的集),结果的概率,以及最终该属性下某个结果的概率。
- 分类器评估:我们一般留出语料库中20%的数据量做分类器的评估,常用的评估指标包括正确率、精准度、召回率、错误率,通过人工去验证判断是否准确,并进行调整。
- 分类识别:以上的过程完成后,这个分类器就可以开展实际的工作了。
二、基于adaboost的数据分类
adaboost是一种组合型算法,它会先产生一定数量的弱分类,然后将弱分类按权重组合成强分类,即最终的分类算法。adaboost算法可以用来处理分类问题,回归问题等,分类方法比较精确的算法,是监督学习的一种。
它的基本原理是:先对初始数据进行训练,找到阈值,生成模型(弱分类器),然后对分类对的降低其权重,分类错误的提升其权重。然后再次训练模型,选定权重相加最小的,直到达到预定值。
adaboost在人脸识别、表情识别等场景中有较高的分析准确性,其过程较为复杂,这里不展开讲,有想进一步了解的可以网上查阅资料。
三、基于K邻近算法的分类器
k邻近算法也叫KNN(k-Nearest Neighbor)是一种在互联网领域常用到的,比较简答的一种算法,在我们常看到的内容推荐、歌单推荐、购物推荐中多数都用到了该算法。
它的核心思想是:将每一名用户(其具有大量的信息:身高、体重、兴趣、爱好、购物习惯等,每个信息都有值)作为一个样本点(多维空间的一个点),计算用户两两之间的距离,并根据距离的远近设定权值,然后评估距离某名用户最近的(人工设置阈值)几名用户的行为(购买某件商品、听了某首歌、看了某个电影、叫了某个外卖)并结合权重,向该名用户推荐他有可能想要的产品或服务。
其中用户与用户距离的计算我们一般用欧式记录或者余弦相似性测算,同时KNN也存在两个问题,一个是由于要计算任意两个样本点之间的距离,技术算比较大,每新增一个样本点都会带来一轮计算。
另外一个是当一个没有数据的样本加入时,无法很短的时间内分析出其可能的属性。
四、基于svm的数据分类
svm(support vector machine)也是一种线性的分类器,比较常用。
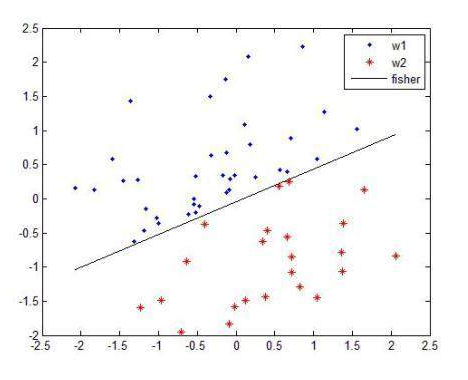
他的基本原理是:建立一个最优决策超平面(多维空间的扭曲平面,即训练得到的模型),保持超平面分开的两个样本距离最大(模型训练过程即是找到距离最大的两个点穿过)。
对于一个多维的样本集,算法随机产生一个超平面并不断移动,对样本进行分类,直到训练样本中属于不同类别的样本点正好位于该超平面的两侧,满足该条件的超平面可能有很多个,多以绥中得到这样一个超平面,使得超平面两侧的空白区域最大化,从而实现对线性可分样本的最优分法。
如下图:
除了以上四种常用的分类算法,都是比较常见的分类方法。 除了以上几种常用的分类算法之外还有其演变出来的算法,或其他实现方式的算法,可以这么说没有万全的算法,只有最合适的算法。
以上,欢迎交流,欢迎拍砖。 以上,欢迎交流,欢迎拍砖。
相关阅读
本文由 @没空儿 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash ,基于 CC0 协议






- 目前还没评论,等你发挥!


