
 起点课堂会员权益
起点课堂会员权益从数据产品经理视角,聊聊事件模型
上一篇文章写了埋点以及基础技术,本篇介绍埋点时常使用的事件模型。

一、事件模型
在传统的web时代,我们经使用pv、uv来统计某个页面/某个按键的使用情况(如:umeng)。
但随着数据精细化,产品迭代&数据分析更期望深度分析用户行为(新老用户的行为差异、各渠道用户转化率、使用app时的行为路径),另一方面推荐也需要用户粒度的行为数据以实现精准化,但这些是“基于页面、按钮的计数统计”无法得到,因而事件模型由此出现。
简单来说,事件模型非常像5w2h,它通过(who、when、where、how、what)记录了谁在某个时间点、某个地方、用某种方式、做了某一件事情(某个行为)。who、when、where、how、what即是事件模型的五个要素。
- Who:即谁参与了这个事件,唯一标识(设备/用户id),可以是 匿名的设备id(idfa\idfv\android_id\imei\cookie)、也可以是后台生成的账户id(user_id,uid)、也可以是其他【唯一标识】。现在很多公司都有自己的唯一设备id(基于某个策略产生的唯一标识),e.g.阿里有OneId。
- When:即这个事件发生的实际时间。该时间点尽可能精确,有利于行为路径分析行为排序,像神策会精确到毫秒。
- Where:即事件发生的地点。可以通过ip地址解析国家、省份、城市;如果期望更细致的数据,如果住宅、商业区等,需要额外地理信息数据库来做匹配。
- How:即用户用某种方式做了这个事件,也可以理解为事件发生时的状态。这个包括的就比较多,可以是进入的渠道、跳转进来的上级页面、网络状态(wifi\4g\3g)、摄像头信息、屏幕信息(长x宽)等。而如使用的浏览器/使用的App,版本、操作系统类型、操作系统版本、进入的渠道等 经常设置为“预设字段”。
- What:即用户做了什么,也是event模型的主题。这里应该尽可能详细的描述清楚行为,如搜索(搜索关键字、搜索类型)、观看(观看类型、观看时长/进度、观看对象(视频id))、购买(商品名称、商品类型、购买数量、购买金额、 付款方式)等等。
二、事件模型对应埋点文档
事件模型反映在埋点上报,即触发一个事件时上报对应日志,记录who、when、where、how、what。对应的统计文档,即埋点文档,在小型创业公司通常是excel来传递,有数据平台部门的公司通常会有专门的维护后台——埋点管理后台,以同步埋点的增删改查看。
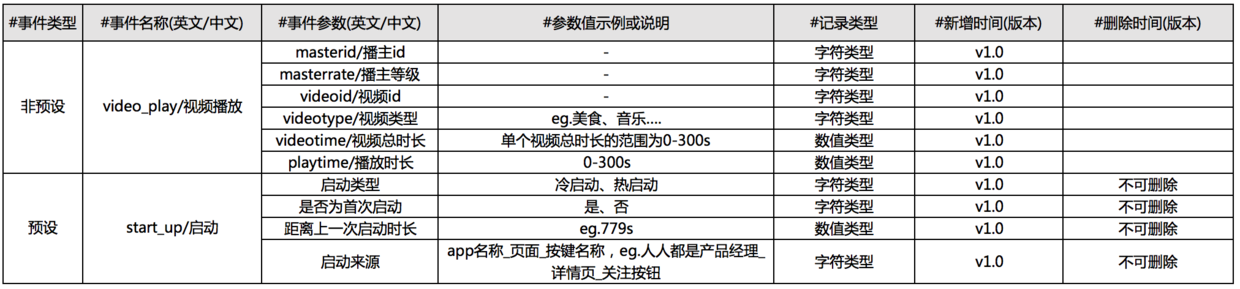
上述所说的事件模型的埋点文档通常会包括:
- 事件类型,像“停/启动”、“退出app”这种常规事件会设置为预设事件,将自动采集,而非预设事件则可以支持各种业务需求。
- 事件名称(英文/中文),能够准确描述事件,区别与其他事件,中文名可以用户数据后台显示。
- 事件参数(英文/中文),能够准确定义参数,区别与其他事件,不同事件的相同参数尽量保持一致,中文名可以用户数据后台显示。
- 参数值,备注合理参数的范围,例举参数的值。
- 类型,参数值记录的类型。由于不同类型支持数据分析后台查询方式不同,比如文本类型可以选择单个值,数值类型使用区间(大于、小于等),定义参数类型时切记考虑通用性、以及分析后台的便利性。
- 新增时间(版本),新增该埋点的时间点。
- 删除时间(版本),删除该埋点的时间点。
三、日志上报
刚有提到“事件模型反映在埋点上报,即触发一个事件时上报对应日志,记录who、when、where、how、what。” 相比行为打包上报(非实时数据),有效减少数据延迟/丢失比例。
非实时的日志上报sdk中,因上报策略不同,即使是同一指标,基于不同的sdk统计到的数据会有差异,常见问题:延迟上报、数据丢失。
上报策略将会影响数据展示,使业务方怀疑数据可信度,如:延迟上报的数据,再次处理后会引起数据回流(e.g.第一天上报90%的行为,相应报表则会基于这90%统计展示;第二天再次上报5%前一天的数据,相应报表则会基于95%统计展示,引起两个时间点看到的数据不一样。)
- 实时:用户行为发生后立即上报;
- 非实时:当一系列的行为都发生后,打包上报、最常见的app退出/下次启动时上报当次/上一次用户行为。
当前的事件模型上报日志示例:
{
“uid”:”1234566″ ##唯一标识
“time”:”1534065122″ ##时间
“type”:”pre” ##预设事件
“event”:”start_up” ##事件名称
parameters:{
“$app_version”:”1.0″ ##预设参数
“$wifi”:”wifi” ##预设参数
“$ip”:”108.66.35.65″ ##预设参数
“masterid”:”12345″ ##事件参数
“masterrate”:”666″ ##事件参数
“videoid”:”987654321″ ##事件参数
“videotype”:”美食” ##事件参数
“videotime”:”100s” ##事件参数
“playtime”:”60s” ##事件参数
}
}
三、事件模型的分析应用
事件模型结合其主体(用户/设备)的属性信息可以支持各种分析模型(漏斗分析模型、留存分析模型、路径分析模型、用户分群模型)。
用户属性常记录年龄、性别、职业、喜好等不易发生变化的。
(1)事件分析&用户分群模型:任一事件可以结合预设字段和用户属性来统计分析,如 18岁以下的女生在这个事件上的表现,反之也可以得到任一时间在 属性维度上的分布,如:这个事件触发用户的年龄分布、地域分布、机型分布等。
(2)漏斗分析模型&用户分群模型:分析一个多步骤过程中每一步的转化与流失情况。结合用户属性,可以分析各维度的漏斗,以找到转化低的瓶颈。例如:不同渠道的注册漏斗,是否存在某个渠道在某个转化过程中表现异常。
(3)留存分析模型&用户分群模型:进行初始行为的用户中,有多少人还会进行该行为。结合用户属性,可以细分群体优化增长、精细化运营活动。
- 新用户留存:第一次访问后继续访问的用户占比。
- xxx行为留存率:进行xxx行为的用户中,有多少人还会进行xxx行为,通常来衡量某个功能的用户粘度
- xxx行为后,做yyy行为:进行xxx行为的用户中,有多少人会进行yyy行为。eg.第一天加入购物车的用户中,在第二天付款的占比。
(4)路径分析模型&用户分群模型:则可以清晰的看到访问当前页面的所有用户中,紧接着有多少进入了详情页、有多大比例使用了xx/yy功能、有多大比例进入了分类页面。结合不同属性的用户在路径分析模型上的差异点、待优化点。
此外,基于“事件模型”采集的数据,也更好的服务于:
- 可视化/报表展示;
- 数据分析;
- 实时推荐;
- ab测试等。
本文由 @ cecil 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pexels,基于 CC0 协议










加个微信可以?
数据产品经理主要做什么呢
“二、事件模型对应埋点文档”中第五条类型中提到的文本类型和表格中提到的字符类型是同一个概念吗?
是相同的
写的非常好,最近读者我,在做公司APP埋点方案、日志格式,事件模型很有启发意义……
埋点文档是数据产品出?
可以加个微信吗?
可以
看到“事件模型非常像5w2h,它通过(who、when、where、how、what)”,百科一下5W2H分别是what why who when where how howmuch,个人认为严谨总是没错的
是的,所以是非常像5w2h~
➡
好像楼主并没有按照5W2H来分析啊,少了why ,howmuch ,楼主可以加上在分析下吗?