
 起点课堂会员权益
起点课堂会员权益AI产品经理必懂算法:k-近邻(KNN)算法
作为想在AI领域长期发展的PM同学来说,对算法有一个初步、通识的了解是非常有必要的。今天我们就从一个最为简单、易懂的“k-近邻(KNN)算法”聊起,KNN属于监督学习算法,即可以用于分类,也可以用于回归,后续还会逐步为大家介绍一些常用的其他算法。

作为想在AI领域长期发展的PM同学来说,对算法有一个初步、通识的了解是非常有必要的。
我们之所以要了解算法,不仅仅有利于和算法同学的沟通,更能深入的理解人工智能为产品赋能的过程,只有将这个过程了解透彻,才能清晰明确的把握产品的方向,挖掘产品的亮点。
那么,今天我们就从一个最为简单、易懂的“k-近邻(KNN)算法”聊起,KNN属于监督学习算法,即可以用于分类,也可以用于回归,后续还会逐步为大家介绍一些常用的其他算法。
KNN的核心思想可以用一句俗语表达:“物以类聚、人以群分”,想了解一个人,可以看他交什么样的朋友。即它的核心思想是:如果一个样本在特征空间中的k个最相邻的样本(距离最近的样本)中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
这里面提及的距离,一般可以选用欧氏距离、曼哈顿距离、闵式距离等等公式进行计算,对于我们初步了解的产品经理来讲,就不上各种公式了。
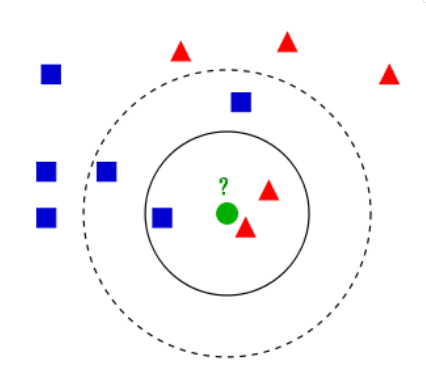
我们用这个图做一个简单的介绍,蓝色方形(用B标识)和红色三角(R)代表两个不同的分类,绿色圆形(C)是待分类样本,根据KNN的思想,如果K=3,则C的最近邻有1B、2R,根据少数服从多数原则,C应该属于“R”的类型。如果k=5呢?C的最近邻有3B、2R,C是不是应该属于“B”类型了呢?
其中判定类别也有两种方法:
- 投票决定:少数服从多数,近邻中哪个类别的点最多就分为哪类。
- 加权投票法:根据距离的远近、对邻近的投票进行加权,距离越近咋权重越大(权重为距离平方的倒数。)
看到这儿,是不是有不少小伙伴产生了疑问,那该如何选择K值呢?K值的大小又将如何影响模型的效果呢?
关于K值的选择,需要注意:
- k值过大,非相似数据被包含较多,造成噪声增加而导致分类结果的降低;
- k值过小,得到的邻近数过少,会降低分类精度,同时也会放大噪声数据的干扰;
经验规则:k一般低于训练样本数的平方根,通常采用交叉检验来确定。
接下来我们简单介绍一下训练过程,有如下几步:
- 准备数据,对数据进行预处理;
- 选用合适的数据结构存储训练数据和测试元组;
- 设定参数,如k;
- 维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列;
- 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
- 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
- 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
- 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。
基本概念和训练过程我们都简单的介绍清楚了,下面来讲讲K近邻的优势及缺陷。
优势:
- 简单,易于理解,易于实现,无需估计参数,无需训练;
- 特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
缺点:
- 计算复杂度高、空间复杂度高;
- 样本严重不平衡时,如果一个类的样本容量很大,而其他类很小,有可能导致输入一个新样本时,被误判为该分类的概率会很大。
了解了算法的优势和局限性,下面就要了解一下它的适用领域了:
- 模式识别,特别是光学字符识别;
- 统计分类;
- 计算机视觉;
- 数据库,如基于内容的图像检索;
- 编码理论(最大似然编码);
- 数据压缩(mpeg-2标准);
- 向导系统;
- 网络营销;
- DNA测序
- 拼写检查,建议正确拼写;
- 剽窃侦查;
- 相似比分算法,用来推动运动员的职业表现。
本文由 @燕然未勒 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash ,基于 CC0 协议。









哈哈哈,作者站在风口啊!AI的PM很吃香嘛!想蹭波流量,我是iot的PM,有这个反向的小伙伴欢迎交流~
请问下,图中各个颜色图形的位置是怎么定下来的
样本的特征,决定了它在特征空间中的位置,不过本图只是个示意而已,比较容易观察,容易理解。
新人报到,望大师们多加耐心指教
能介绍一下必懂算法有哪些吗?谢谢🙏
•分类算法:C4.5,CART,Adaboost,NaiveBayes,KNN,SVM
•聚类算法:KMeans
•统计学习:EM
•关联分析:Apriori
•链接挖掘:PageRank
谢谢aixiaozhu
aipm要懂这么详细的算法吗
以我个人的理解啊,我觉得咱们产品了解算法的目的和了解技术的目的相差不多,第一是为了了解技术边界,举个例子,我们在一个文库产品中设计了一个文章摘要的功能,通过算法针对文章进行摘要,那么我们首先要了解,目前在NLP领域里面,内容摘要的实现程度怎样,算法的结果不好,会不会影响我们的用户体验,看起来驴唇不对马嘴。
第二个目的是开拓思路,只有我们对于这些知识有个大概的理解,在产品的设计过程中,可能会带来一些启发和灵感,知道我们可以做些什么。
第三个目的是为了尽可能少被忽悠一点儿, 😥
当然,我的观点也是了解基本原理和应用场景对我们来说就不容易了,至于里面的算法实现,不必深究,有余力的同学可以学的更深入一点。
谢谢
AI是什么
AI是一款制图软件,你可以是Adobe公司出的
皮
特别好,我也是一个特别喜欢ai的pm,是从吴恩达开始入门的,希望能学习到你更多的文章
把你的文章都看了一遍,立马成为你的粉丝咯。😆 想向你多学习。
初来乍到,感谢捧场