
 起点课堂会员权益
起点课堂会员权益对比分析:AI产品PRD和互联网产品PRD的异同
本文尝试以“智能车载终端语音助理”产品为例,从语音识别、自然语言处理两类AI产品的角度出发,去尽可能的介绍人工智能产品需求与传统互联网产品需求的异同。

一、引言
1. 因技术领域而异的人工智能产品
首先,要说明的是,每个人工智能产品都因其所属的行业不同以及其应用的相关技术不同,有着很大的差异。比如:机器视觉产品和自然语言处理产品从行业数据特征、业务场景以及算法模型等方面都显得大相径庭,虽然同属于人工智能行业,但两个细分领域下产品经理所需的背景和知识完全不同。
2. 人工智能产品分类
通常来说,人们从技术角度,将人工智能产品细分为:语音识别产品、自然语言处理产品、机器视觉产品和机器学习产品(详细内容,可以参考之前团长的文章《AI产品经理的定义和分类》)。
此外,还有一类终端应用产品,它通过各种终端载体形式,综合应用了上述的多项技术。比如:对于车载智能终端上的语音助理,它主要应用了语音识别和自然语言处理两个领域的技术,它的产品需求除了涉及到这两个领域技术的应用策略外,还涉及语音助理客户端上相关的产品设计。
本文尝试以“智能车载终端语音助理”产品为例,从语音识别、自然语言处理两类AI产品的角度出发,去尽可能的介绍人工智能产品需求与传统互联网产品需求的异同,也许无法完整的概括人工智能产品需求的方方面面,还请各位读者见谅。
二、AI产品和互联网产品PRD的异同
既然是PRD,AI产品的PRD也不外乎由文档描述、需求背景、竞品分析、需求范围、需求内容几大部分组成。其中,从文档描述到需求范围的部分,AI产品PRD和传统互联网产品PRD并没有太大的不同,二者的差异主要集中在需求内容的部分。而需求内容这方面的差异又因PM角色的不同而有所不同,因此在展开这一部分之前,先简要介绍一下车载语音助理产品的分工。
一般来说,一个车载语音助理可以由声学前端&ASR、客户端及Bot Framwork三部分组成,分别对应着声学交互PM、客户端PM及技能PM。
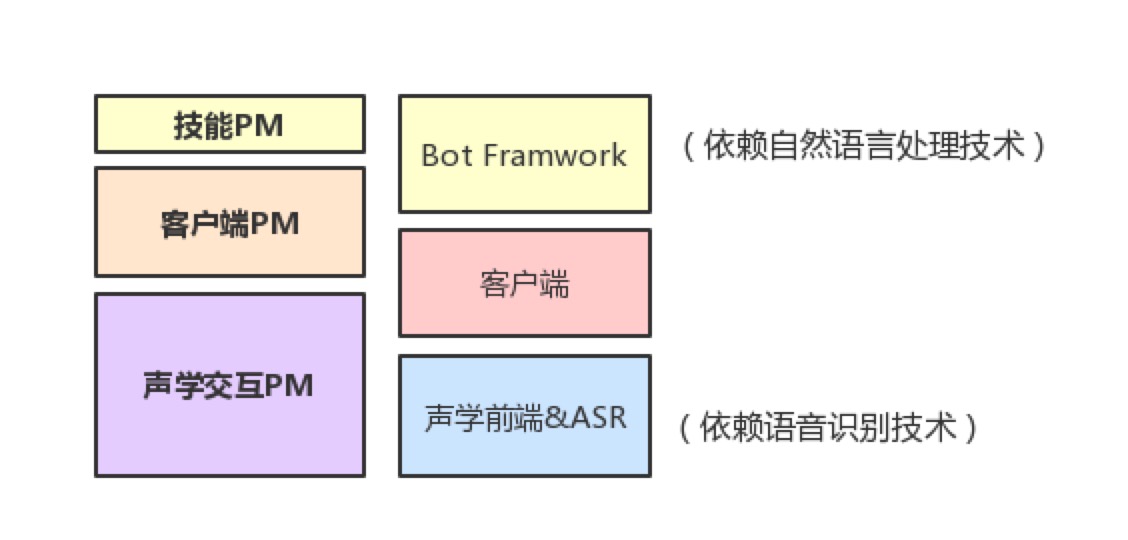
1. 车载语音助理的产品分工
1)声学交互PM
通过制订应用语音识别技术时的一些策略,来实现端上的一些产品特性。声学交互PM有点类似传统互联网的策略PM,但需要PM对语音识别的各项技术及其应用的场景较为了解。
2)客户端PM
主要对语音助理框架性的交互(GUI及CUI)体验负责,过程中,往往需要形成一套交互规范供技能PM参考,保证端体验的一致性。语音客户端PM相比于传统互联网的客户端PM,除了要对GUI交互熟悉之外,更需要对CUI交互有独到的理解。
3)技能PM
基于Bot Framwork,设计各个技能的意图、会话及服务,来实现端上的一些产品特性。技能PM需要对语义技术、语义设计有自己的理解,同时在服务设计上需要对CUI交互有自己的理解。
如果将语音助理比作一座大厦,那声学交互PM就像是负责打地基的,提供了最基础的语音交互能力;而客户端PM,则像是用钢筋搭起了整个建筑的框架;而技能PM,则是用混凝土们将整个建筑填充的更加丰满。
2. 车载语音助理的产品需求
由于声学交互PM、客户端PM和技能PM的分工不同,他们的需求文档在需求内容方面的侧重就有所不同。
1)声学交互类需求
这类需求,首先对技术提出了能力方面的要求,其次选取合适的场景将能力落地,形成一定的语音交互上的产品特性。
一方面,产品需要在需求文档中说明“要运用的技术需要达到的能力”,并将这个能力包装为接口,指定相应的输入和输出,同时规定一些性能指标。另一方面,产品也会结合一些场景,制订一些策略,从而产出一些新的交互特性。这些特性,往往可能不是由一个单一的技术来实现的,可能需要将多种技术综合应用。
例如:语音助理的多音区,其实包含了两种技术能力。首先是声源定位,即分辨车内发音人的来源是在主驾、副驾还是后排,其次是波束成形,即可以只对唤醒人所在方向进行收音,对过程中非唤醒人的声音信号进行抑制。
在这个能力上,产品可以指定将多音区的声源定位能力加入车控指令,从而实现副驾说打开车窗,仅开启副驾侧车窗的特性。也可以指定将多音区的波束成形能力接入语音交互的流程,使得主驾唤醒之后只接收主驾的指令。
2)客户端类需求
一般来说,语音助理是围绕一个bot来运作的,这个bot接收文字输入,输出语义或服务结果,过程中可能会涉及到多轮和应答。而客户端类需求,就是针对bot从输入到输出的整个过程去定义框架性的交互体验,同时,还会涉及到一些端上常规模块的功能设计。
首先,需要定义bot接收文字输入前所有流程的设计,主要是唤醒和识别流程中的GUI和CUI设计,以及过程中的异常流程处理,例如用户不说话时如何处理、超时时如何处理、网络异常时如何处理等。
其次,需要定义在bot运行过程中,包括语义解析、多轮会话及相应多轮应答以及最终输出语义及服务结果时所需的框架性GUI设计,如显示区域定义、显示模板定义、GUI交互定义等。
值得指出的是,这两部分需求的提出,往往伴随着设计规范一起产出。对于GUI而言,类似于传统互联网的客户端PM,需要给出整个界面的原型设计,不同的是,这里往往需要给出模板化的设计,来尽可能的满足各类场景下GUI展示的需要。CUI方面,会给出回复语设计应该遵循的一些原则,例如:合作原则、礼貌原则等,同时,也会根据语音助理的设定提一些语气方面的要求。
最后,是语音助理客户端上一些常规模块设计。例如:用户登录、设置、帮助等,而后者和传统互联网产品基本上是一致的。
3)技能类需求
这类需求侧重于技能相关的语义 、会话及服务设计。
(1)语义设计
语义设计,分为语义表示定义、模板定义和语料定义三个部分。
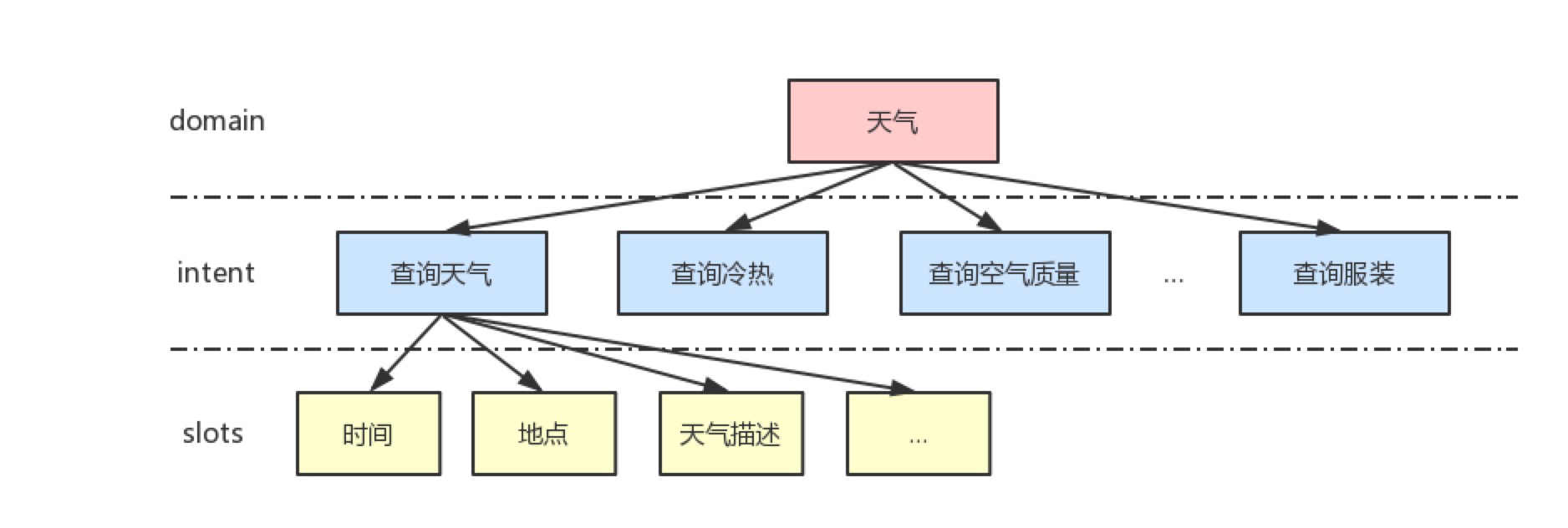
语义表示定义,即定义技能所属领域Domain、领域下的意图Intent、意图内的参数Slot以及参数对应的实体。例如:为了让语音助理听懂并回答“今天天气怎么样?”
这一问题,技能PM需要设计一个天气查询的技能,定义它属于语义所属的领域 – 天气、意图 – 查询天气,定义用户query中可能会出现的参数 – 地点、时间等,同时还要定义参数对应的实体库。
模板的设计,其实就是写一些正则表达式来保证冷启动时的召回。这一部分可能会在专门的语义平台上进行,不一定会在需求文档中体现。
语料的定义,即语料的收集及标注。需要产品在需求中说明语料收集的场景、示意的问法等等给到专门的团队,同时说明标注的规则,供标注人员在语料收集完成后进行标注工作。而标注好的语料,会给到语义模型进行学习,来提升意图的准召率。
模板和语料的定义,直接关系到了语音助理在意图上的泛化能力,也是需求中不容忽视的部分。不论是在语义表达的设计还是在语料定义的时候,都需要尽可能的考虑用户的表达方式,尽可能的去覆盖更多的说法。
(2)会话设计
会话设计,主要是针对多轮对话过程中的CUI及GUI设计,即根据当前所处的对话状态对用户进行引导,从而明确用户的指令。如果用户提供的信息还不足以执行任务,需要设计相应的澄清话术引导用户完成填槽,过程中,可能会配合必要的视觉展示,供用户进行决策。同时,GUI有时候还承担了一定的用户引导作用,提示用户当前可以说些什么指令来继续对话。
(3)服务设计
服务设计,即最终服务结果呈现时的回复话术设计及GUI的设计。还是以天气举例子,用户听到的“深圳今天是晴天,气温21到26摄氏度”就是典型的回复话术设计,而看到的天气卡片就是GUI的设计,上面可能显示了天气、气温、湿度、空气质量指数等。

回复话术的设计,包含成功执行和异常时的回复。由于语音具备输入高效,输出低效的特点,因此在回复语的设计上需要尽可能简洁地给出必要的信息。
在结果的呈现上,需要产品在需求中定义视觉展示时页面的信息如何排布,是否涉及二次交互等等。这一部分的内容类似传统互联网的原型设计,只是在设计的时候需要考虑车载端的交互特性。
三、结语
最后想说,无论是什么领域的需求文档,它都是一份产品需求文档,和传统互联网的需求文档在结构上并没有什么不同,具体的差异因为产品经理角色的不同体现在了需求内容的部分。
说明:如作者所说,由于人工智能产品的分类很多,还有计算机视觉、机器学习等其他领域的PRD特点没有涵盖,如果你是有兴趣来分享输出的AI产品经理,欢迎单独联系我。
作者:星云
本文由 @星云 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Pixabay,基于 CC0 协议






- 目前还没评论,等你发挥!


