
 起点课堂会员权益
起点课堂会员权益假如数据欺骗了你:产品经理如何识破数据谎言?
数据千万条,甄别第一条,数据不规范,老板两行泪。

对产品经理而言,数据无疑是工作中需要常常借鉴的对象,毕竟这是个数据推动发展的时代。数据之所以重要,正是因为数据是记录客观事实的一种符号,因此在统计数据面前,许多人潜意识里的第一反应就是无条件信任它。
但现实是,许多看似靠谱的数据,都是别有用心的机构利用了数据的客观性,为我们输出了一个与现实大相径庭的结论。虽然数据本身不会说谎,但说谎者需要数据。
数据都说了哪些谎?
1. 样本偏差的欺骗性
(1)幸存者偏差
也叫“沉默的数据”。如果要说得更具体点,就是当你在分析某个事物的时候,可能会面对诸多的证据(样本),但是大多数人通常只注意到“显式”的样本和证据,而忽略了“隐式”的样本和证据,从而得出错误的认知、错误的结论。
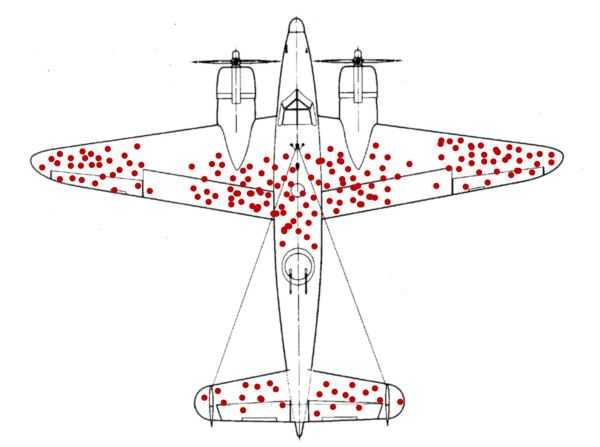
下面举一个最著名的例子:二战期间,英国皇家空军计划在轰炸机上进行改造,以抵抗德军战斗机和陆基高射炮的攻击。
他们统计了联军返航的轰炸机受损情况,作战指挥官认为应该加强机翼的防护,因为分析表明,那里“密密麻麻都是弹孔,最容易被击中”。但是统计学家却有不同观点,他建议加强座舱与机尾部位的装甲,因为那儿发现的弹孔最少,说明大多数被击中飞行员座舱和尾部发动机的飞机,根本没法返航就坠毁了。
上面的例子不是数据说谎,而是你没注意到沉默的数据(缺少了的样本)。当数据样本仅采自“幸存者”、信息不够全面的时候,得出来的结论有可能才是最离谱的,需要分析者有足够广的视角和逻辑,才能从数据里挖掘出隐性的真相。
(2)不充分的样本数据
- “用户反映,使用A品牌牙膏将使蛀牙减少23%。”
- “B品牌洗衣粉能有效减少90%种污渍残留。”
你也许常常能从广告中的某些权威机构、研究人员口中得知这些结论,但如果你仔细观看,或许能看到这样一行小字:此次实验由**(假设30)名用户组成,甚至有些广告还故意抹去这些信息。这些信息意味着,只要你找来多组测试用户,每组30人,持续使用一段时间的该品牌产品,就会得出以下的任意一种结果(以牙膏为例):
- 蛀牙明显增多
- 蛀牙明显减少
- 蛀牙数量无明显变化
事实上,不管用户使用的是哪种牙膏,由于机遇作用,第二种结果是迟早会被试验出来的。由于试验人数只有30人(样本总数不大),所以得到的结论极有可能是牙膏效果极佳(蛀牙减少23%),商家就是利用这样不充分的样本数据,来达到预期的广告效果。现实中,也要警惕在信息不对称的情况下,脱离总量谈现象的流氓思维。
(3)样本本身存在偏差
假设调研一座城市的人均消费水平。如果是在飞机场调研,或许会得出“城市发达、人民收入高”等结论,但如果到贫民窟里调查,结论就会截然相反,因为城市里真正贫穷的人很少会在机场出没。
企业也常常利用这种选择性的误差来为某个现象寻求合理性,比如智能手机领域喜欢用数据“打脸”友商,但是由于大家采用的统计口径不同,所以常常在同一领域遇到数据打架的情况。
还有一种情况就是样本不够真实,比如全社会都在传播“吃饭不光盘是种可耻的行为”这种理念后,这时你再去调研这个话题,绝大多数受访人都会表示自己是个“净坛使者”,因为几乎所有调查都无法避免人们往自己脸上贴金,这种情况下除非采用匿名调查或者直接调查饭后餐桌上的盘子,否则很难获取到完全真实的数据。
这些案例说明即便你找不到任何数据遭到破坏的证据,也很难避免样本本身在说谎,因此只要是样本有存在变量误差的可能,就要保留怀疑的态度。
2. 用平均数掩盖差距
假如把比尔盖茨移民到某个非洲落后国家,该国的人均GDP相应地也会有很大幅度的上涨。但这有意义吗?该国贫民窟里的穷人依然吃不上面包。
类似的,即使某地区人均收入有了提升,但依然存在一种可能性,就是富人财富量的增加远远快于穷人财富量的增加,造成的结果是“数据显示人均收入上升,但贫富差距在拉大”。
比如美国前总统奥巴马在谋求第二任期的竞选活动中提到,“美国经济自09年以来增长了13%”。但他没有说的是,其实美国人只有最富有的那1%的人收入增长了,剩下的99%的人收入反而比以前有轻微的下降。奥巴马虽然赢得了连任,但“整体经济复苏”与“大多数人的可支配收入没有增长”的矛盾却依然无解。
通常情况下,你并不会被告知数据包含了多少观测值,当均值和中位数相差甚远的时候,你就需要注意那些没有标明类型的平均数(均值、中位数、众数),否则你对它的认知依然停留在表面。
3. 数据的视觉欺骗性
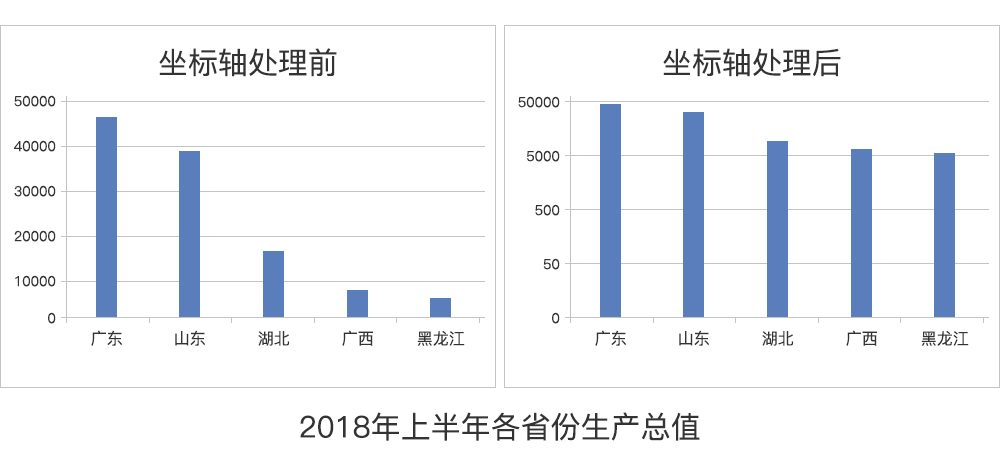
上图是2018年我国各省GDP的统计图像,可以看到,同样的数据在不同的坐标轴里呈现出来的状态截然不同,左图数据取等量递增绘图,右图数据取十进制绘图,呈现出来的视觉效果有相当大的不同,大多数人的第一直觉是:
- 左图直观表达各省GDP差距巨大
- 右图直观表达各省GDP差距不大
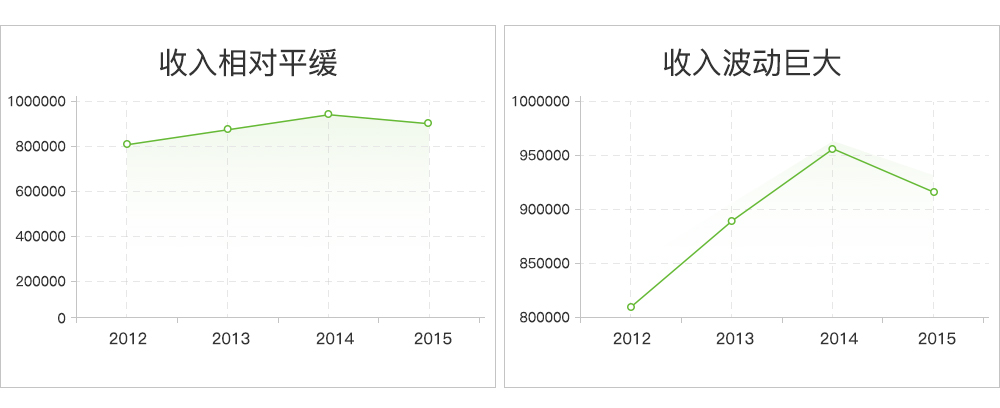
上图是某公司四年间的收入曲线,从视觉上很容易得出以下结论:
- 左图直观表达公司四年间收入稍有波动,但相对平缓;
- 右图直观表达公司四年间收入波动巨大,目前遭遇停滞下滑的危机。
也许大家都发现了,波动是可以被人为操纵的,但数据却是真实的。PPT领域有一句很经典的话:能用图,不用表,能用表,不用字。图表诚然能帮我们更直观的了解事实,但许多报告和演讲就是有心利用数据的视觉误差,误导观众的判断,分辨能力弱的读者就容易被牵着鼻子走。
如果你细心留意的话,就能发现很多产品的发布会和权威机构调查对这招都是屡试不爽的,虽然数据本身没有问题,但这样的呈现方式仅仅是为了好看。现在是信息化时代,一段信息里有价值的文字往往不如一张靓丽的图表更抓人眼球,加强对数据可视化的信息分辨能力会少走很多弯路。
4. 数据不能替你思考
统计学数据表明:在夏天,“冰激凌的销量”和“溺水死亡人数”成正比,二者的趋势高度吻合。
看到这条信息你是选择相信还是陷入沉思?如果我们通过这条数据强行把两者联系起来分析的话,推导出来的结论很有可能是:
- 吃冰激凌会导致人们游泳时更容易溺水
- 游泳溺水时人们喜欢用冰激凌来抢救
很诧异对吧,但如果你跳脱出数据分析的思维,以常识去推理,你就知道两者根本没有联系,唯一的契合点在于“夏天天气热”,冰激凌的销量会因此上升,下水游泳的人也会因此增多,自然会有更多溺水事件发生。
数据是客观的、理智的,但人是经验主义者,更善于用逻辑去认识和判断事物,数据的绝对客观性,往往会把我们被拖入单维思考的沼泽里。
就像电影《流浪地球》的片段:以色列科学家提出点燃木星的想法,被空间站的人工智能莫斯否决。道理很简单,莫斯作为人工智能,是绝对理性的化身,它经过周密的科学计算后得出的结论表明:这个方案成功的概率为零,但它忽略了人类是具有感情的生物(或许是故意忽略),冲动和情感能突破理性的底线,做出人工智能不能理解的行为。
简而言之,用空间站撞击木星这种看上去不合理的感性行为,也许恰恰不在莫斯的数据分析范围内。
电影虽然是电影,但它能映射现实。许多在人类看来再正常不过的逻辑思维,却是冰冷傲慢的数据分析的盲区,这本质其实是单维思考和多维思考、客观事实和主观逻辑的冲突。数据可以辅助你思考,但它不能代替你思考,千万不要患上唯数据论的怪病,在认识事物的时候一定要问问自己:该相信逻辑还是该相信数据?
如何避免数据说谎
通过上面的案例我们可以知道,数据是客观产生的,它只能反映问题,不会主动撒谎,真正说谎的凶手有三个“人”:
- 记录数据的人(数据的真实性)
- 拿数据给你看的人(利用数据的目的)
- 自我的认知错误(解读出现偏差)
1. 数据的真实性
解决的方法,第一件要预防数据生病,就是辨别数据可信度(真实性)。简单来说,通常要遵循两个原则:越接近第一手的数据越真实,采集的样本越全面越可信。
例如互联网产品经理常常更关心数据分析的结论,而忽视了原始数据的来源和真实性,源头如果出现问题,一切的分析都是徒劳的。如果你更关心渠道数据的精准度,可以使用openinstall进行渠道来源归因统计和活动推广效果监测,openinstall在渠道数据精准度上还是比较专业的。
2. 利用数据的目的
我们要明白统计数据的真实价值:数据是用来揭示事物规律,进而解决问题、创造未来的。如果结论本身已经客观存在,你用再多的数据也无法让结论变得更加正确,如果有人想要找到某个证据(数据)来论证观点,方法多的是,早晚能够找到。
让数据来回答问题,然后从这些数据中创造更多的可能,这才是数据存在的现实意义,也是用来辨别哪些人在利用数据说谎的方法。
3. 解读出现偏差
要善用常识性的思维和多个角度去看待客观事物的发展,既认识到数据和统计学的力量,也要了解它的局限性。当然,这也需要我们有基础的数理科统计知识储备。
数据和模型只是人们用来总结改进的方法,实践才是真理,如果想要更深层次的解读数据背后的意义,就要自己多去挖掘和实践。
总结
真实深度的数据在工作中是非常有参考价值的,尤其能帮助我们建立分析框架,弥补思维漏洞。要知道,数据并不能代替分析人员做决定,获取真实数据、善于运用数据、识破数据骗局,是需要长期培养和掌握的技能。
本文由 @大城小事 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议









不错、感谢分享!!!
好文