
 起点课堂会员权益
起点课堂会员权益数据的秘密(下):如何分析数据?

前言
上一篇文章中,我们介绍了为什么要关注数据,在本文中我将分享具体如何做。
关注宏观和细节
大多数人都能做到关注宏观的数据,拿互联网产品来说,日活,月活,流失率,NPS(净推荐值),这些都是宏观的数据。宏观数据能够反映出产品的整体状况,是值得长期关注的。
但是在宏观之外,我们还应该关注一些细节的数据。拿日活来说,我们可以再进一步进行分析,比如:
- 日活中新用户所占的比例
- 日活中 iOS 和 Android 的各自占比
- 日活中大家集中活跃的时间段
- 日活中用户的会话(Session)次数分布,时长分布
- 日活中用户平均使用你的产品核心功能的次数
当你把数据拿放大镜看得更细的时候,你可能就会发现一些问题。带着这些问题,你进一步分析,就可以找到更多信息。
举一个我们创业产品项目的例子,我们发现日活中的用户,有相当一部分用户只是注册了,但是并没有使用我们产品的核心功能,于是我们担心会不会有一些付费推广渠道「刷量」。
所以,我们将新增用户中不活跃的比例按渠道来划分。通过这样的划分,我们很容易找到那些效果差的渠道,从而选择更有效的推广渠道。
关注原始数据
原始数据是什么?就是那些不是通过别的数据计算出来的,不能被分割的数据。这些数据是最最真实的,而其它通过计算出来的数据,因为进行了二次加工,所以不一定能够完全反映出产品的问题。
再举一个项目的例子,我们为了研究 NPS 给我们打零分的用户。把这些用户的搜索数据、操作记录都抽样出来,一个用户一个用户看,然后进行分类整理。最终我们发现这里面小学生用户占比很高,从而调整了产品的策略,在内容和算法上对小学生进行了兼顾。
关注原始数据除了能改进产品外,还能在技术上提高代码的质量。我们曾经遇到过一个很难复杂的 Bug,在我们的测试机中都无法复现,但是我们通过分析相关用户的操作记录,找到了具体崩溃的操作方法。
虽然该操作方法不能在我们自己的机器上复现 Bug,但是我们却能找到相关的关键代码。通过一些针对这些代码的讨论,我们就找到了 Bug 的原因。现在回想起来,如果没有这些原始数据,要修复这个 Bug 就要困难很多了。
关于面试
其实不光做产品要看「原始数据」,面试一个人也是。我在面试的时候,会选一个候选人简历上的事情,进行深入了解。我会让他提供详细相关工作的数据和事例。通过这些「原始数据」,我能够更加方便地「还原他真实的工作场景」,从而对他的工作质量作出尽量客观的评价。
举个例子,有一个产品实习生候选人在简历上写他运营了一个微信公众号,「粉丝逾千,单日粉丝增量 200 以上,数篇文章阅读量超过 3000」。但是在面试中,详细追问这些数字,我们才发现他说的「逾千」是指 1000,而「单日粉丝增量 200 以上」是指的最高的一天,其它信息也都是有夸大的成分。
还有一次,我面试一个技术候选人,这个候选人说他有代码洁癖,觉得前公司的代码「很乱,受不了」。但是我让他具体举几个例子的时候,他却很难说出实际的例子。还有候选人说他喜欢看技术书,但是却无法说出他印象最深的一本技术书以及其中的部分观点。
通过了解细节,我们就可以揭开简历中光鲜描述的外衣,了解到事情背后的细节,这对我们评价候选人至关重要。
数据可视化
数据可视化是指将原本枯燥的数据,用折线图、饼图、柱状图等方式呈现出来,它可以使我们更容易发现数据的规律,也更容易发现数据的异常。
在项目中,数据可视化多次给我们带来巨大的帮助,包括:
- 了解数据的特点:我们将项目的 QPS 按每小时为频率画出成一条折线图,所以我们很容易知道我们服务器高峰期的时间段以及访问量。
- 发现服务异常:我们将服务器搜索的失败率占比画出成一个饼图,有一天,这个饼图中显示出失败率突然变高了。同时,每日的 NPS 分数突然也变低了很多。我们借此发现了新扩容的一台服务器故障。因为那台服务器是新加的,所以运维忘记了增加监控,如果没有数据可视化的帮助,这个故障可能会持续更长时间。
- 监控核心质量:我们将项目的一些核心指标画成折线图,然后大家都努力让核心指标更优。
- 发现恶意攻击:一些重要指标,我们都会可视化出来,这样当这些数据指标变化时,我们就会进一步分析原因,从中我们还发现了一些竞争对手恶意的攻击行为。
数据可视化工具
我们当然不可能所有的数据可视化都是自己手工用 Excel、Numbers 之类的工具来生成。所以,我们开发了一个数据可视化的平台,我们把它叫做 flyboard。
flyboard 提供了各种数据可视化的方式,包括数字,折线图,饼图,环形图,柱状图等。如下图所示:
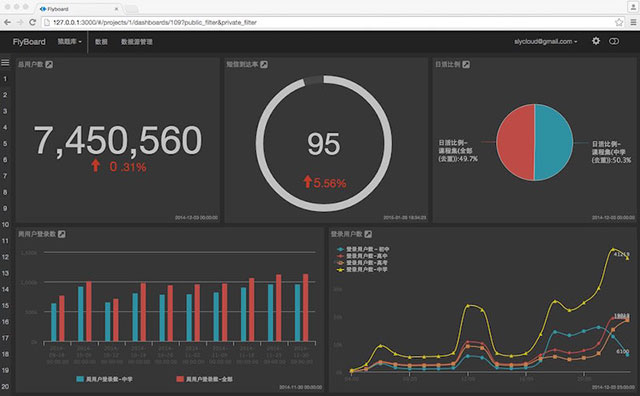
我们将所有的原始数据都归集到分布式存储 Hbase 中,然后通过配置一些定时的计算任务,就可以以几乎实时地方式,看到产品的各项可视化指标。
这些指标,有宏观的,也有一些比较细分的,如果我们对某项指标的数值有疑问,我们就会进一步写一些分析脚本,来从 Hbase 中计算一些数据进行检查。
在我们公司,我们的三个产品的办公区域,都挂着一个巨大的显示器,这个显示器除了用于 Scrum 的每日站会同步进度外,平时都用 flyboard 显示着产品的各项核心数据。
悄悄告诉你一个秘密,我们的 flyboard 可视化平台是开源的,项目地址是:https://github.com/yuantiku/flyboard ,在 Github 上你可以下载到完整的代码,我们也附有完整的安装使用说明文档。如果你还没有使用任何数据可视化工具,欢迎尝试一下 flyboard。
学习写 SQL
由于有 Hadoop、Hbase 、 Hive 的存在,产品经理也可以通过一些简单的 SQL 语句,就可以生成MapReduce 任务,进行分布式的数据分析运算。
所以数据分析最最常用的办法就是写 SQL。在很多公司,产品经理都在这方面能力比较欠缺,这使得产品经理在需要数据时,需要向技术提需求。技术会根据自己的工作排期。这样一来一回,一般一个简单的数据分析都需要一天时间。
这样的低效率的方式,会扼杀产品经理的一些数据分析需求,特别是那种需要探索式发现的数据分析工作。因为这种工作需要不停地根据数据分析的结果,调整各种策略来写尝试的 SQL。
所以在我们团队,我们希望产品经理都能有基本的数据分析能力,一些简单的 SQL 都是需要自己能够写的。当然,一些特别复杂的 SQL,产品经理可能还是需要向技术同事咨询。
具体如何写 SQL,市面上已经有非常多的相关书籍了,我在这里就不再展开介绍了。
数据查看和分析一定要方便
如果你仔细观察就会发现,很多革命性的产品就只是让某件事情更方便了一点点。智能手机其实只是让你上网更方便了一点,但是这种方便使得人们从以前有「离线和在线」的状态,变成了永久在线。于是,移动互联网诞生了,本质上来说,移动互联网就是一种人们永久在线的网络,但是就是这么一点点的方便,使得很多行业被完全颠覆。
而数据分析也是一样,我们应该尽量让数据触手可得,这样我们才能将数据分析的效率最大化,一定程度上的效率提升就会产生质变,使得我们专注于数据做更多事情。
我们之前移动端统计用 Flurry,但是 Flurry 在中国实在太慢了,即使挂上国外的 VPN 也很慢!如果产品经理每次登录 Flurry 要 10 秒钟的话,那么他就可能将注意力临时转移到别的事情上,然后就可能忘记本来要看的数据。
为了让数据触手可得,我们放弃了对 Flurry 的使用,我们自己开发了日志收集平台,然后自己写日志计算程序,将一些核心指标全部自己计算在 flyboard 上,我们也另外开发了一套数据分析平台,实现 Flurry 中的类似功能。现在,我们已经能够非常舒服地分析数据了。
所以,如果你的公司不能很方便的查看和分析数据,那么一定要想办法改进,这些数据就像人的神经系统一样,传递着产品的健康数据,重视这些数据,才能够做好产品。
总结
总结一下本文中的观点:
- 重视宏观数据和细节
- 关注原始数据
- 数据可视化
- 学会用 SQL
- 数据查看和分析一定要方便
作者:唐巧
来源:http://blog.devtang.com/blog/2015/09/03/how-to-monitor-data/









这个分析地很好。简而言之,就是数据分析有利于宏观把握产品的运营状况,微观上察觉产品运营中出现的主观及客观问题,从而帮助人们更好的定位受众,分析受众使用产品的行为规律,觉察产品运营中出现的大小问题。
博主,你的那个flyboard怎么安装啊,难道还要写代码 么?
git bash 下 安装好nodejs 然后按照上面的命令执行,不过npm install时候出现了问题 不知道为啥
能多说些案例就好了 还是比较抽象。。。
..那个flyboard不知道怎么用
oh holy shit…… 简直……
😀 😀 😀 😀 😀 😀
flyboard 怎么跑进来啊?